 继requests篇和selenium篇,本文是爬取图片的最后一个案例,利用了python第三方库DrissionPage来自动化爬取图片。当然,爬取图片肯定不止这三种方法,还有基于python的scrapy框架,基于node.js的express框架以及基于Java的webmagic框架等等。
DrissionPage和selenium相似,都是基于python的网页自动化工具。不过Drission库的结合了requests和Selenium的优势,既能控制浏览器交互,又能高效地收发数据包。它的主要特点是可以监听网络数据,它可以拦截并解析请求和响应数据包,方便用户进行调试和分析。
继requests篇和selenium篇,本文是爬取图片的最后一个案例,利用了python第三方库DrissionPage来自动化爬取图片。当然,爬取图片肯定不止这三种方法,还有基于python的scrapy框架,基于node.js的express框架以及基于Java的webmagic框架等等。
DrissionPage和selenium相似,都是基于python的网页自动化工具。不过Drission库的结合了requests和Selenium的优势,既能控制浏览器交互,又能高效地收发数据包。它的主要特点是可以监听网络数据,它可以拦截并解析请求和响应数据包,方便用户进行调试和分析。@
目录
- 前言
- DrissionPage介绍
- 实战
- 共勉
- 博客
前言
继requests篇和selenium篇,本文是爬取图片的最后一个案例,利用了python第三方库DrissionPage来自动化爬取图片。当然,爬取图片肯定不止这三种方法,还有基于python的scrapy框架,基于node.js的express框架以及基于Java的webmagic框架等等。
DrissionPage介绍
DrissionPage和selenium相似,都是基于python的网页自动化工具。不过Drission库的结合了requests和Selenium的优势,既能控制浏览器交互,又能高效地收发数据包。它的主要特点是可以监听网络数据,它可以拦截并解析请求和响应数据包,方便用户进行调试和分析。
实战
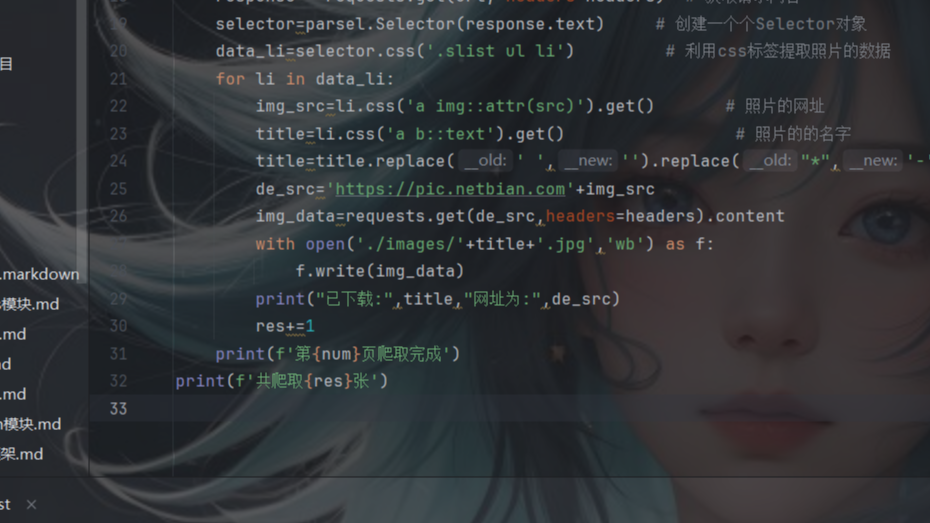
话不多说,直接上源码
from DrissionPage import ChromiumPage # chromium内核浏览器
from time import sleep # 时间模块
from DrissionPage import SessionPage # 和requests库相似,用于html解析browser = ChromiumPage() # 打开浏览器
browser.get('https://pic.netbian.com/e/search/result/?searchid=147') # 请求网址
img_list=browser.eles('css:.slist ul li') # 定位所有照片元素
for li in img_list:try:img_src=li.ele("css:a img").attr('src') # 获取图片的地址# img_src=li.ele("css:a img").link # 获取图片的地址img_name=li.ele('css:a b').text # 获取照片名字img_name=img_src.split('/')[-1] # 以/为分割符分隔,取列表最后一个元素(照片命名)save_path=r'./image1' # 照片保存地址page = SessionPage()res=page.download(img_src,save_path) # 图片下载print(res,img_name,img_src)except Exception as e:print(e)多页爬取只需要再加个点击事件和for循环即可,可以私信d我获取多页爬取的源码
共勉
- 先完成 后完美
博客
- 本人是一个渗透爱好者,不时会在微信公众号(laity的渗透测试之路)更新一些实战渗透的实战案例,感兴趣的同学可以关注一下,大家一起进步。
- 之前在公众号发布了一个kali破解WiFi的文章,感兴趣的同学可以去看一下,在b站(up主:laity1717)也发布了相应的教学视频。