Kafka 如何保证消息的消费顺序?
我们在使用消息队列的过程中经常有业务场景需要严格保证消息的消费顺序,比如我们同时发了 2 个消息,这 2 个消息对应的操作分别对应的数据库操作是:
更改用户会员等级。
根据会员等级计算订单价格。
假如这两条消息的消费顺序不一样造成的最终结果就会截然不同。
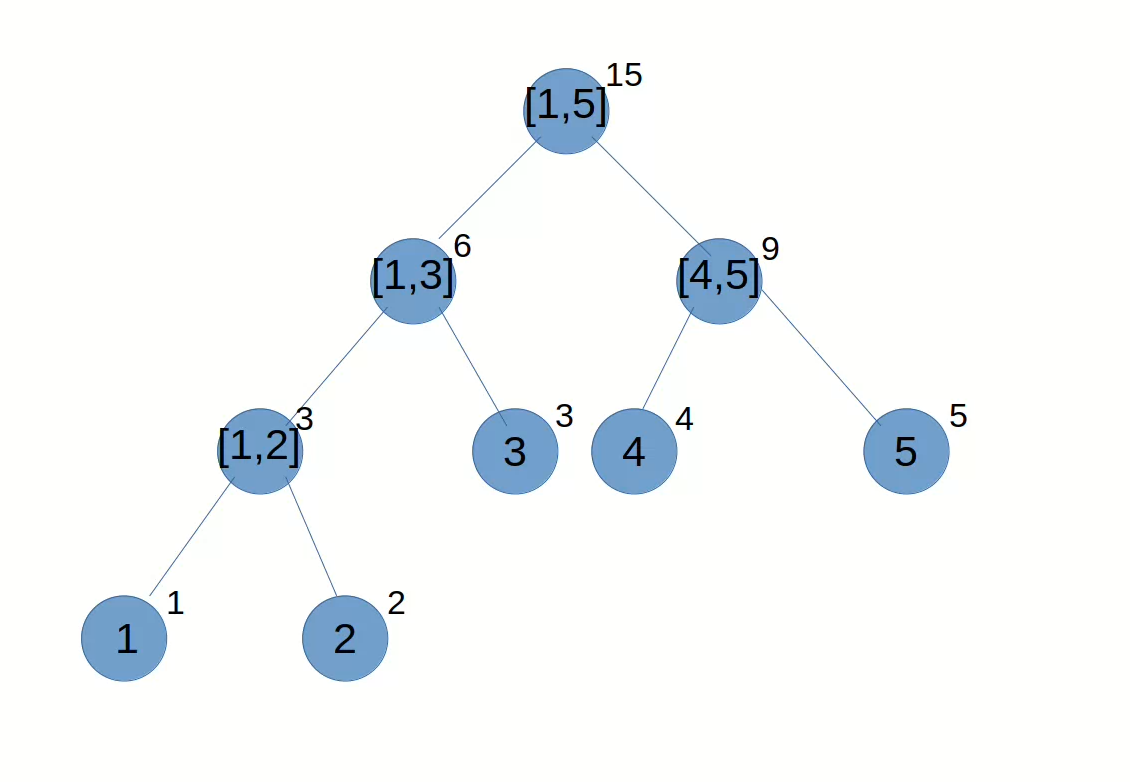
我们知道 Kafka 中 Partition(分区)是真正保存消息的地方,我们发送的消息都被放在了这里。而我们的 Partition(分区) 又存在于 Topic(主题) 这个概念中,并且我们可以给特定 Topic 指定多个 Partition。
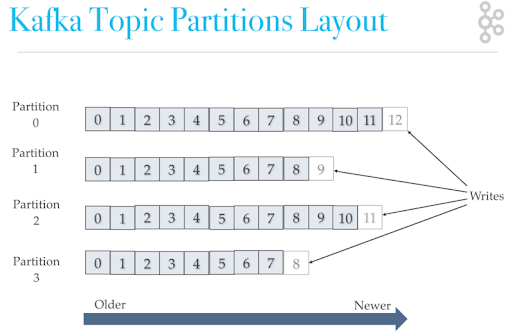
每次添加消息到 Partition(分区) 的时候都会采用尾加法,如上图所示。 Kafka 只能为我们保证 Partition(分区) 中的消息有序。
消息在被追加到 Partition(分区)的时候都会分配一个特定的偏移量(offset)。Kafka 通过偏移量(offset)来保证消息在分区内的顺序性。
所以,我们就有一种很简单的保证消息消费顺序的方法:1 个 Topic 只对应一个 Partition。这样当然可以解决问题,但是破坏了 Kafka 的设计初衷。
Kafka 中发送 1 条消息的时候,可以指定 topic, partition, key,data(数据) 4 个参数。如果你发送消息的时候指定了 Partition 的话,所有消息都会被发送到指定的 Partition。并且,同一个 key 的消息可以保证只发送到同一个 partition,这个我们可以采用表/对象的 id 来作为 key 。
总结一下,对于如何保证 Kafka 中消息消费的顺序,有了下面两种方法:
1 个 Topic 只对应一个 Partition。
(推荐)发送消息的时候指定 key/Partition。
当然不仅仅只有上面两种方法,上面两种方法是我觉得比较好理解的,
Kafka 如何保证消息不丢失?
生产者丢失消息的情况
生产者(Producer) 调用send方法发送消息之后,消息可能因为网络问题并没有发送过去。
所以,我们不能默认在调用send方法发送消息之后消息发送成功了。为了确定消息是发送成功,我们要判断消息发送的结果。但是要注意的是 Kafka 生产者(Producer) 使用 send 方法发送消息实际上是异步的操作,我们可以通过 get()方法获取调用结果,但是这样也让它变为了同步操作,示例代码如下:
详细代码见我的这篇文章:Kafka 系列第三篇!10 分钟学会如何在 Spring Boot 程序中使用 Kafka 作为消息队列?
SendResult<String, Object> sendResult = kafkaTemplate.send(topic, o).get();
if (sendResult.getRecordMetadata() != null) {logger.info("生产者成功发送消息到" + sendResult.getProducerRecord().topic() + "-> " + sendResult.getProducerRecord().value().toString());
}
但是一般不推荐这么做!可以采用为其添加回调函数的形式,示例代码如下:
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(topic, o);
future.addCallback(result -> logger.info("生产者成功发送消息到topic:{} partition:{}的消息", result.getRecordMetadata().topic(), result.getRecordMetadata().partition()),ex -> logger.error("生产者发送消失败,原因:{}", ex.getMessage()));
如果消息发送失败的话,我们检查失败的原因之后重新发送即可!
另外,这里推荐为 Producer 的retries(重试次数)设置一个比较合理的值,一般是 3 ,但是为了保证消息不丢失的话一般会设置比较大一点。设置完成之后,当出现网络问题之后能够自动重试消息发送,避免消息丢失。另外,建议还要设置重试间隔,因为间隔太小的话重试的效果就不明显了,网络波动一次你 3 次一下子就重试完了。
消费者丢失消息的情况
我们知道消息在被追加到 Partition(分区)的时候都会分配一个特定的偏移量(offset)。偏移量(offset)表示 Consumer 当前消费到的 Partition(分区)的所在的位置。Kafka 通过偏移量(offset)可以保证消息在分区内的顺序性。
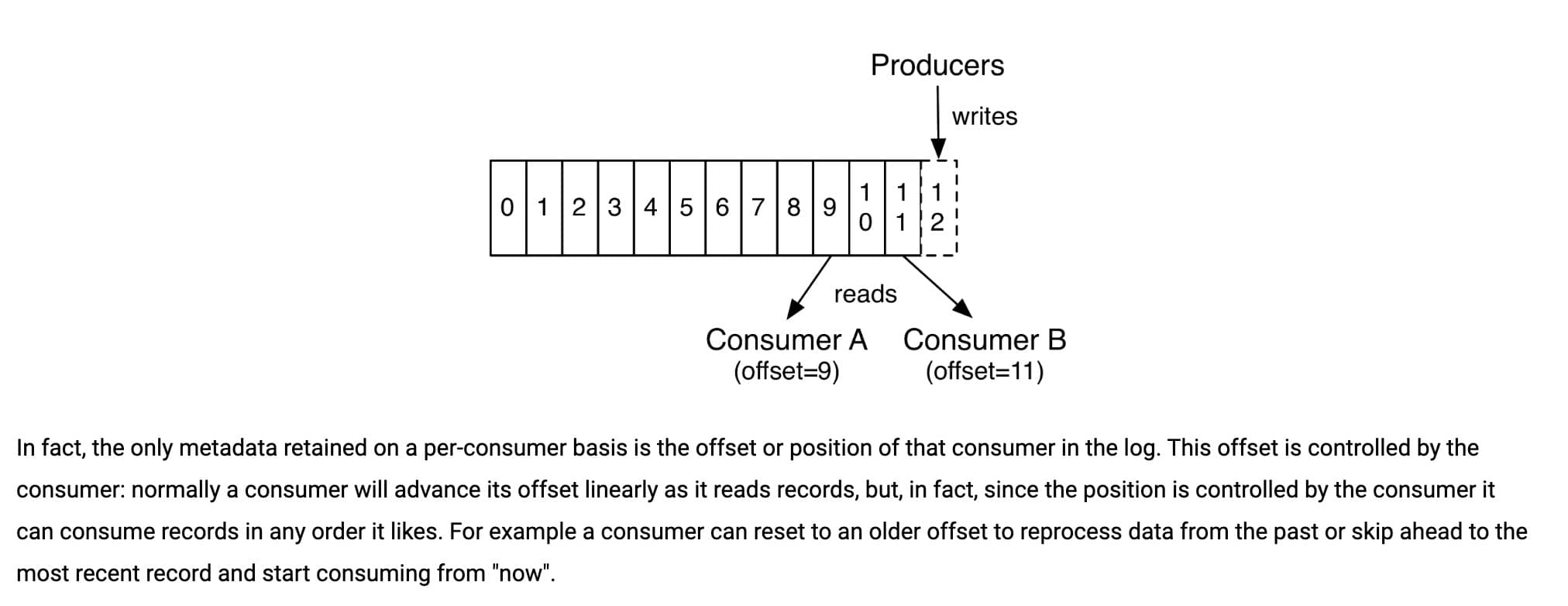
当消费者拉取到了分区的某个消息之后,消费者会自动提交了 offset。自动提交的话会有一个问题,试想一下,当消费者刚拿到这个消息准备进行真正消费的时候,突然挂掉了,消息实际上并没有被消费,但是 offset 却被自动提交了。
解决办法也比较粗暴,我们手动关闭自动提交 offset,每次在真正消费完消息之后再自己手动提交 offset 。 但是,细心的朋友一定会发现,这样会带来消息被重新消费的问题。比如你刚刚消费完消息之后,还没提交 offset,结果自己挂掉了,那么这个消息理论上就会被消费两次。
Kafka 弄丢了消息
我们知道 Kafka 为分区(Partition)引入了多副本(Replica)机制。分区(Partition)中的多个副本之间会有一个叫做 leader 的家伙,其他副本称为 follower。我们发送的消息会被发送到 leader 副本,然后 follower 副本才能从 leader 副本中拉取消息进行同步。生产者和消费者只与 leader 副本交互。你可以理解为其他副本只是 leader 副本的拷贝,它们的存在只是为了保证消息存储的安全性。
试想一种情况:假如 leader 副本所在的 broker 突然挂掉,那么就要从 follower 副本重新选出一个 leader ,但是 leader 的数据还有一些没有被 follower 副本的同步的话,就会造成消息丢失。
设置 acks = all
解决办法就是我们设置 acks = all。acks 是 Kafka 生产者(Producer) 很重要的一个参数。
acks 的默认值即为 1,代表我们的消息被 leader 副本接收之后就算被成功发送。当我们配置 acks = all 表示只有所有 ISR 列表的副本全部收到消息时,生产者才会接收到来自服务器的响应. 这种模式是最高级别的,也是最安全的,可以确保不止一个 Broker 接收到了消息. 该模式的延迟会很高.
设置 replication.factor >= 3
为了保证 leader 副本能有 follower 副本能同步消息,我们一般会为 topic 设置 replication.factor >= 3。这样就可以保证每个 分区(partition) 至少有 3 个副本。虽然造成了数据冗余,但是带来了数据的安全性。
设置 min.insync.replicas > 1
一般情况下我们还需要设置 min.insync.replicas> 1 ,这样配置代表消息至少要被写入到 2 个副本才算是被成功发送。min.insync.replicas 的默认值为 1 ,在实际生产中应尽量避免默认值 1。
但是,为了保证整个 Kafka 服务的高可用性,你需要确保 replication.factor > min.insync.replicas 。为什么呢?设想一下假如两者相等的话,只要是有一个副本挂掉,整个分区就无法正常工作了。这明显违反高可用性!一般推荐设置成 replication.factor = min.insync.replicas + 1。
设置 unclean.leader.election.enable = false
Kafka 0.11.0.0 版本开始 unclean.leader.election.enable 参数的默认值由原来的 true 改为 false
我们最开始也说了我们发送的消息会被发送到 leader 副本,然后 follower 副本才能从 leader 副本中拉取消息进行同步。多个 follower 副本之间的消息同步情况不一样,当我们配置了 unclean.leader.election.enable = false 的话,当 leader 副本发生故障时就不会从 follower 副本中和 leader 同步程度达不到要求的副本中选择出 leader ,这样降低了消息丢失的可能性。
Kafka 如何保证消息不重复消费?
kafka 出现消息重复消费的原因:
服务端侧已经消费的数据没有成功提交 offset(根本原因)。
Kafka 侧 由于服务端处理业务时间长或者网络链接等等原因让 Kafka 认为服务假死,触发了分区 rebalance。
解决方案:
消费消息服务做幂等校验,比如 Redis 的 set、MySQL 的主键等天然的幂等功能。这种方法最有效。
将 enable.auto.commit 参数设置为 false,关闭自动提交,开发者在代码中手动提交 offset。那么这里会有个问题:什么时候提交 offset 合适?
处理完消息再提交:依旧有消息重复消费的风险,和自动提交一样
拉取到消息即提交:会有消息丢失的风险。允许消息延时的场景,一般会采用这种方式。然后,通过定时任务在业务不繁忙(比如凌晨)的时候做数据兜底。
Kafka 重试机制
在 Kafka 如何保证消息不丢失这里,我们提到了 Kafka 的重试机制。由于这部分内容较为重要,我们这里再来详细介绍一下。
网上关于 Spring Kafka 的默认重试机制文章很多,但大多都是过时的,和实际运行结果完全不一样。以下是根据 spring-kafka-2.9.3 源码重新梳理一下。
消费失败会怎么样?
在消费过程中,当其中一个消息消费异常时,会不会卡住后续队列消息的消费?这样业务岂不是卡住了?
生产者代码:
for (int i = 0; i < 10; i++) {
kafkaTemplate.send(KafkaConst.TEST_TOPIC, String.valueOf(i))
}
消费者消代码:
@KafkaListener(topics = {KafkaConst.TEST_TOPIC},groupId = "apple")
private void customer(String message) throws InterruptedException {
log.info("kafka customer:{}",message);
Integer n = Integer.parseInt(message);
if (n%5==0){
throw new RuntimeException();
}
}
在默认配置下,当消费异常会进行重试,重试多次后会跳过当前消息,继续进行后续消息的消费,不会一直卡在当前消息。下面是一段消费的日志,可以看出当 test-0@95 重试多次后会被跳过。
2023-08-10 12:03:32.918 DEBUG 9700 --- [ntainer#0-0-C-1] o.s.kafka.listener.DefaultErrorHandler : Skipping seek of: test-0@95
2023-08-10 12:03:32.918 TRACE 9700 --- [ntainer#0-0-C-1] o.s.kafka.listener.DefaultErrorHandler : Seeking: test-0 to: 96
2023-08-10 12:03:32.918 INFO 9700 --- [ntainer#0-0-C-1] o.a.k.clients.consumer.KafkaConsumer : [Consumer clientId=consumer-apple-1, groupId=apple] Seeking to offset 96 for partition test-0
因此,即使某个消息消费异常,Kafka 消费者仍然能够继续消费后续的消息,不会一直卡在当前消息,保证了业务的正常进行。
默认会重试多少次?
默认配置下,消费异常会进行重试,重试次数是多少, 重试是否有时间间隔?
看源码 FailedRecordTracker 类有个 recovered 函数,返回 Boolean 值判断是否要进行重试,下面是这个函数中判断是否重试的逻辑:
@Override
public boolean recovered(ConsumerRecord << ? , ? > record, Exception exception,@Nullable MessageListenerContainer container,@Nullable Consumer << ? , ? > consumer) throws InterruptedException {if (this.noRetries) {// 不支持重试attemptRecovery(record, exception, null, consumer);return true;}// 取已经失败的消费记录集合Map < TopicPartition, FailedRecord > map = this.failures.get();if (map == null) {this.failures.set(new HashMap < > ());map = this.failures.get();}// 获取消费记录所在的Topic和PartitionTopicPartition topicPartition = new TopicPartition(record.topic(), record.partition());FailedRecord failedRecord = getFailedRecordInstance(record, exception, map, topicPartition);// 通知注册的重试监听器,消息投递失败this.retryListeners.forEach(rl - >rl.failedDelivery(record, exception, failedRecord.getDeliveryAttempts().get()));// 获取下一次重试的时间间隔
long nextBackOff = failedRecord.getBackOffExecution().nextBackOff();if (nextBackOff != BackOffExecution.STOP) {this.backOffHandler.onNextBackOff(container, exception, nextBackOff);return false;} else {attemptRecovery(record, exception, topicPartition, consumer);map.remove(topicPartition);if (map.isEmpty()) {this.failures.remove();}return true;}
}
其中, BackOffExecution.STOP 的值为 -1。
@FunctionalInterface
public interface BackOffExecution {
long STOP = -1;
long nextBackOff();
}
nextBackOff 的值调用 BackOff 类的 nextBackOff() 函数。如果当前执行次数大于最大执行次数则返回 STOP,既超过这个最大执行次数后才会停止重试。
public long nextBackOff() {
this.currentAttempts++;
if (this.currentAttempts <= getMaxAttempts()) {
return getInterval();
}
else {
return STOP;
}
}
那么这个 getMaxAttempts 的值又是多少呢?回到最开始,当执行出错会进入 DefaultErrorHandler 。DefaultErrorHandler 默认的构造函数是:
public DefaultErrorHandler() {
this(null, SeekUtils.DEFAULT_BACK_OFF);
}
SeekUtils.DEFAULT_BACK_OFF 定义的是:
public static final int DEFAULT_MAX_FAILURES = 10;
public static final FixedBackOff DEFAULT_BACK_OFF = new FixedBackOff(0, DEFAULT_MAX_FAILURES - 1);
DEFAULT_MAX_FAILURES 的值是 10,currentAttempts 从 0 到 9,所以总共会执行 10 次,每次重试的时间间隔为 0。
最后,简单总结一下:Kafka 消费者在默认配置下会进行最多 10 次 的重试,每次重试的时间间隔为 0,即立即进行重试。如果在 10 次重试后仍然无法成功消费消息,则不再进行重试,消息将被视为消费失败。
如何自定义重试次数以及时间间隔?
从上面的代码可以知道,默认错误处理器的重试次数以及时间间隔是由 FixedBackOff 控制的,FixedBackOff 是 DefaultErrorHandler 初始化时默认的。所以自定义重试次数以及时间间隔,只需要在 DefaultErrorHandler 初始化的时候传入自定义的 FixedBackOff 即可。重新实现一个 KafkaListenerContainerFactory ,调用 setCommonErrorHandler 设置新的自定义的错误处理器就可以实现。
@Bean
public KafkaListenerContainerFactory kafkaListenerContainerFactory(ConsumerFactory<String, String> consumerFactory) {
ConcurrentKafkaListenerContainerFactory factory = new ConcurrentKafkaListenerContainerFactory();
// 自定义重试时间间隔以及次数
FixedBackOff fixedBackOff = new FixedBackOff(1000, 5);
factory.setCommonErrorHandler(new DefaultErrorHandler(fixedBackOff));
factory.setConsumerFactory(consumerFactory);
return factory;
}
如何在重试失败后进行告警?
自定义重试失败后逻辑,需要手动实现,以下是一个简单的例子,重写 DefaultErrorHandler 的 handleRemaining 函数,加上自定义的告警等操作。
@Slf4j
public class DelErrorHandler extends DefaultErrorHandler {
public DelErrorHandler(FixedBackOff backOff) {super(null,backOff);
}@Override
public void handleRemaining(Exception thrownException, List<ConsumerRecord<?, ?>> records, Consumer<?, ?> consumer, MessageListenerContainer container) {super.handleRemaining(thrownException, records, consumer, container);log.info("重试多次失败");// 自定义操作
}
}
DefaultErrorHandler 只是默认的一个错误处理器,Spring Kafka 还提供了 CommonErrorHandler 接口。手动实现 CommonErrorHandler 就可以实现更多的自定义操作,有很高的灵活性。例如根据不同的错误类型,实现不同的重试逻辑以及业务逻辑等。
重试失败后的数据如何再次处理?
当达到最大重试次数后,数据会直接被跳过,继续向后进行。当代码修复后,如何重新消费这些重试失败的数据呢?
死信队列(Dead Letter Queue,简称 DLQ) 是消息中间件中的一种特殊队列。它主要用于处理无法被消费者正确处理的消息,通常是因为消息格式错误、处理失败、消费超时等情况导致的消息被"丢弃"或"死亡"的情况。当消息进入队列后,消费者会尝试处理它。如果处理失败,或者超过一定的重试次数仍无法被成功处理,消息可以发送到死信队列中,而不是被永久性地丢弃。在死信队列中,可以进一步分析、处理这些无法正常消费的消息,以便定位问题、修复错误,并采取适当的措施。
@RetryableTopic 是 Spring Kafka 中的一个注解,它用于配置某个 Topic 支持消息重试,更推荐使用这个注解来完成重试。
// 重试 5 次,重试间隔 100 毫秒,最大间隔 1 秒
@RetryableTopic(
attempts = "5",
backoff = @Backoff(delay = 100, maxDelay = 1000)
)
@KafkaListener(topics = {KafkaConst.TEST_TOPIC}, groupId = "apple")
private void customer(String message) {
log.info("kafka customer:{}", message);
Integer n = Integer.parseInt(message);
if (n % 5 == 0) {
throw new RuntimeException();
}
System.out.println(n);
}
当达到最大重试次数后,如果仍然无法成功处理消息,消息会被发送到对应的死信队列中。对于死信队列的处理,既可以用 @DltHandler 处理,也可以使用 @KafkaListener 重新消费。

![[ARC177F] Two Airlines](https://s2.loli.net/2024/08/23/8cn96l3V7LRhGbd.png)
![[思考] Diffusion Model](https://img2024.cnblogs.com/blog/1067530/202403/1067530-20240314213314299-2097711653.png)
