一. 介绍
- 很多业务逻辑很简单,主要难点是数据量太大,可使用分布式处理提高速度。
- 传统分布式程序,计算逻辑和分布式任务分发、故障恢复混在一起,原本简单的计算逻辑变得模糊不清,难以处理。
- MapReduce将两者分离,任务分发,容错,恢复等逻辑由模型完成,程序员只需要专注计算逻辑。大大了简化代码架构,减轻开发人员工作难度。
二. 模型概述
- Map/Reduce函数由用户编写
- Map函数负责处理输入的k/v对,生成中间态k/v对
- 之后发送出去,按照Key值进行分组,不同Key值的数据发送到不同的Reduce中
- Reduce函数接收中间态的值并进行聚合,最终输出自己负责的Key值的结果
示例
// key: document name
// value: document contents
map(String key, String value):for each word w in value:EmitIntermediate(word,"1");// key: a word
// values: a list of counts
reduce(String key, Iterator values):int result = 0;for each v in values:result += ParseInt(v);Emit(AsString(result));
- map函数对一行字符串进行分解,生成(word,1)的KV对
- reduce函数累加每一个单词的出现计数,等到所有数据处理完毕,就可以得到结果
三. 实现
将输入的数组分割为M份
通过一个分区函数将中间态的值划分为R组(例如: hash(key) mod R)
1 执行概述
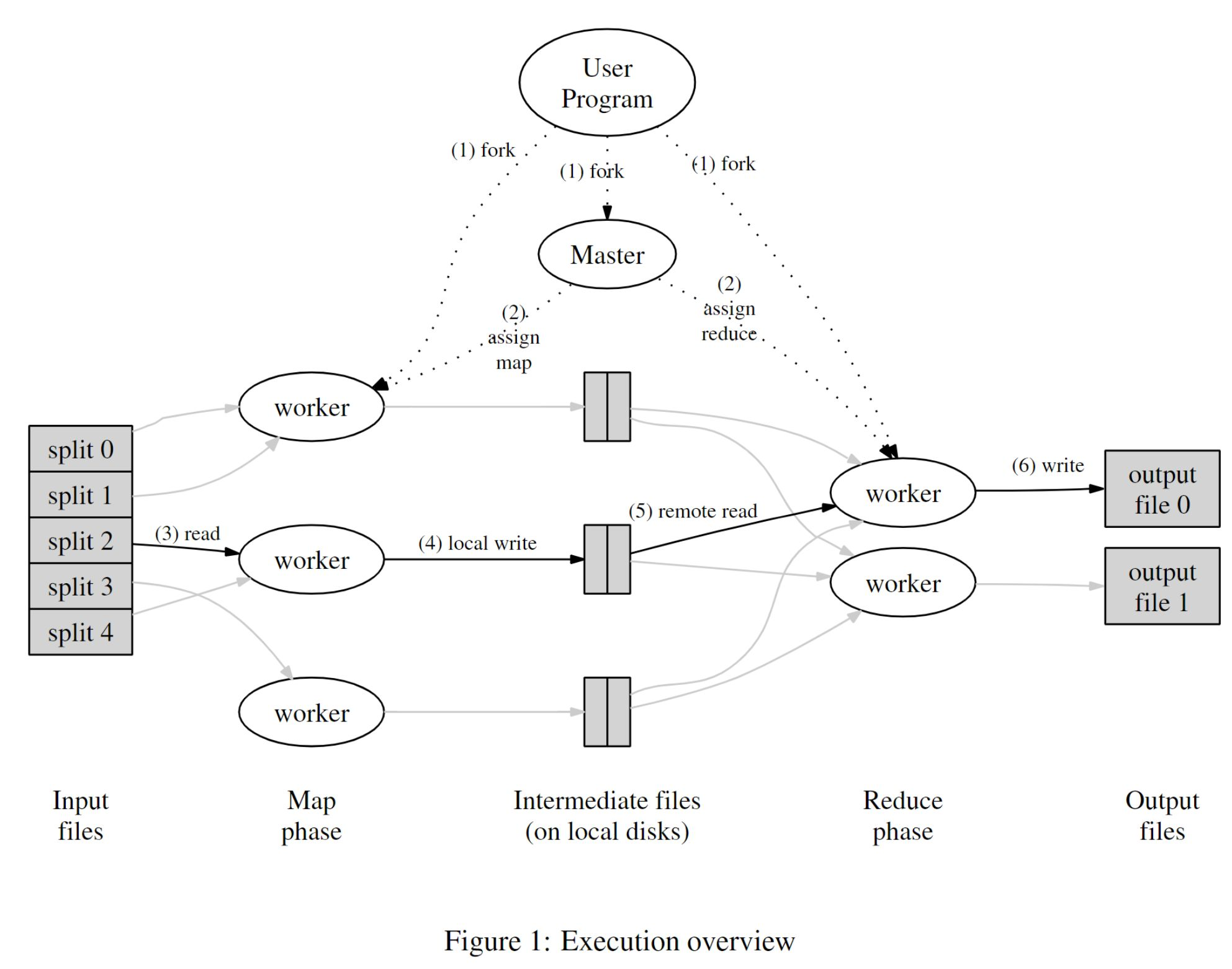
- 将输入文件拆分为M份,通常每份大小为16MB至64MB(可配置)
- 在集群中的一组机器上启动多个程序的副本,只有一个
master。剩下的都是worker,worker由master分配任务 - 现有M个
map任务和R个reduce任务。master选择空闲的worker,分配map或reduce任务 map worker从输入数据中解析K/V对,并将kv对传递给用户自定义的map函数。从而产生中间态K/V对,然后缓存在内存中。- 缓存中的
K\V对会被周期性地写入本地磁盘,通过分区函数将其划分到R个区域中。这些缓存所在的磁盘的位置会被发送给master,master将这些位置信息转发给reduce worker。 reduce worker获得位置信息后,会通过RPC从map worker的本地磁盘读取缓冲数据。当reduce worker读完所有的中间数据后,它会根据key值进行排序,从而将key值相同的数组放在同一组。排序是必需的,因为通常会有很多不同的key映射到同一个reduce任务。如果中间数据量太大,无法放入内存中,则可使用外部排序。reduce worker遍历已排序的中间数据,对于每个Key,它将该Key和与之对应的中间值集合传递给用户的reduce函数。Reduce函数产生结果,写入到这个Reduce的结果输出文件中。- 当所有map和reduce任务都完成后,
master唤醒用户程序。此时,用户程序中对MapReduce调用,就会获得结果。
成功完成后,结果会被存放在R个输出文件中(每个reduce任务对应一个输出文件,文件名由用户指定)。通常不需要将这R个输出文件合并为一个文件 — 通常这些文件会作为输入传递给下一阶段的MapReduce。
2.Master的数据结构
Master中维护一些信息:
- 每个任务的状态
- 所有worker机器的标识
- map生成的R个中间态文件所在的位置和大小
master会将map生成的中间态文件位置和大小信息以增量的方式持续推送给运行中的reduce Worker。
3. 容错
Worker Failure
Master 周期性ping worker,一段时间没有响应:
-
标记此worker失败,该worker负责的任务都会被重置为初始状态,调度去其他worker重新执行
-
已完成的map任务在故障后需重新执行,因为map的输出存储在故障机器的本地磁盘,无法访问。而已完成的reduce任务不需要重复执行,因为它们的输出存储在全局文件系统中
-
通知reduce任务,A断线了,之后从B读取数据
Master Failure
- 重启
4. Locality
网络传输耗时,减少网络传输,优先将map任务分配到距离输入数据主机物理距离较近的地方。
5. Task Granularity(任务粒度)
- M和R的值都应远大于worker机器的数量
6.Backup Tasks(备份执行)
解决掉队者问题,一台机器花费了异常长的时间去完成最后的几个map或reduce任务
当MapReduce只剩最后几个任务时,调度剩余任务到多个节点同时执行,最后无论是主节点还是备份节点执行完成,任务都将被视为完成
四.每个组件的任务
1.Master
1.1 执行需要的参数
- 要处理的任务类型
- 待处理的文件列表
1.2 分发任务
分发任务给可处理对应任务的worker, 记录发给worker对应的文件名
监听
监听worker状态,如果2S没完成,就标记为Dead,重新分发这个文件到其他空闲worker
执行完成
执行完成后,worker将消息传回Master,Master进行接收,然后按Key进行分发,如果是旧Key就发给对应的Reduce worker,反之就采用轮询,将对应任务发给下一个Reduce worker
心跳
worker每10S和Master进行心跳连接
2. Worker
2.1 启动时参数
- Master地址
2.2 心跳
每10S和Master进行一次心跳
2.3 接收Master任务
-
任务类型
-
要处理的文件名
-
输出结果