\({\tt FlexAttention}\) 是一种旨在增强大型视觉语言模型的方法,通过利用动态高分辨率特征选择和分层自注意机制,使其能够有效地处理并从高分辨率图像输入中获得优势, \({\tt FlexAttention}\) 在性能和效率方面超越了现有的高分辨率方法。
来源:晓飞的算法工程笔记 公众号
论文: FlexAttention for Efficient High-Resolution Vision-Language Models

- 论文地址:https://arxiv.org/abs/2407.20228
- 论文代码:https://vis-www.cs.umass.edu/flexattention
Introduction

大型视觉语言模型(VLMs)在包括图像描述、视觉问答、图像文本匹配等多模态任务中展示出显著的能力,但这些模型通常在相对低分辨率(例如 \(224 \times 224\) 或 \(336 \times 336\))下处理图像,因此在需要仔细检查小区域(例如细微的文本或小物体)的场景中表现不佳。例如,在图1(a)中,这些模型由于低分辨率输入的限制而无法识别印刷标志上的文字,这一局限性变得显而易见。
为了解决这一问题,已经有几种高分辨率视觉语言模型(例如LLaVA-1.5-HD和CogAgent),它们可以接受高分辨率图像作为输入并将其编码为高分辨率标记。尽管这些模型能够更仔细地检查小区域,但需要耗费大量计算资源来全面处理所有高分辨率标记以计算注意力。这些模型与人类进行视觉推理的方式有所不同,与其完美地记忆所有像素的细节,论文倾向于首先保持粗略的表示,并仅在接收到外部刺激时才关注相关区域以检索更多细节。因此,高分辨率视觉语言模型能够灵活动态地基于低分辨率特征,关注感兴趣的区域进行高分辨率细节的检索,这一点至关重要。
为此,论文提出了 \({\tt {{FlexAttention}}}\) ,一种新颖的注意力机制,可以无缝地插入大多数视觉语言模型中,以有效地增强它们感知高分辨率图像的能力。具体来说,如图1(c) 所示, \({\tt {{FlexAttention}}}\) 接受高分辨率图像作为输入,并将图像编码为高分辨率图像标记和低分辨率图像标记。为了提高计算效率,仅将低分辨率图像标记和文本标记输入到前几层,以粗略理解整个图像。在后续层中,仅使用低分辨率图像标记和一小部分高分辨率图像标记来计算注意力,从而显著减少计算成本。每个带有 \({\tt {{FlexAttention}}}\) 的解码器层包含一个高分辨率特征选择模块和一个分层自注意力模块。高分辨率特征选择模块根据输入的注意力图检索相关区域的高分辨率图像标记,所选的高分辨率图像标记与低分辨率图像标记和文本标记串联,并输入到分层自注意力模块。分层自注意力模块生成一个注意力图用于选择高分辨率图像标记,这些标记被输入到下一层分层自注意力模块。这两个模块被迭代处理直到最后一层,通过投影器产生最终的答案。
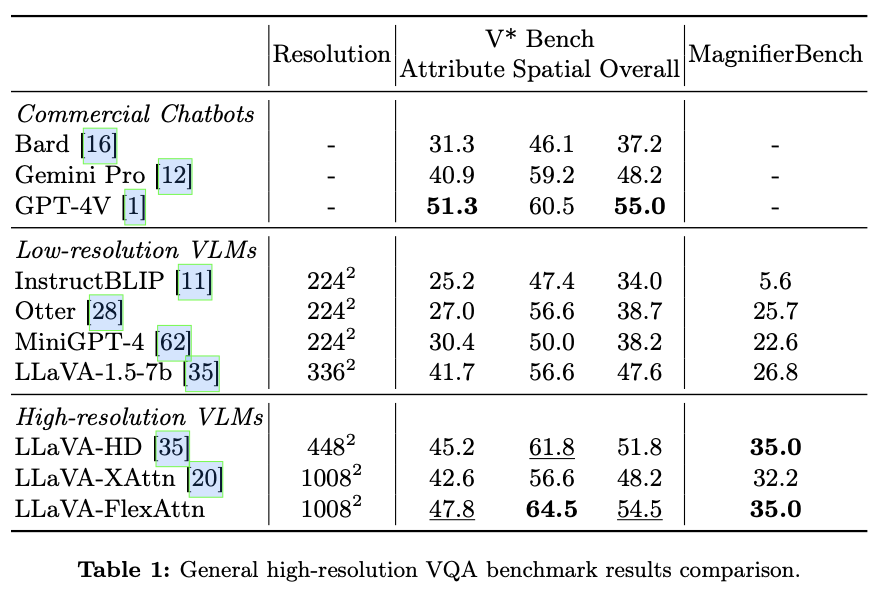
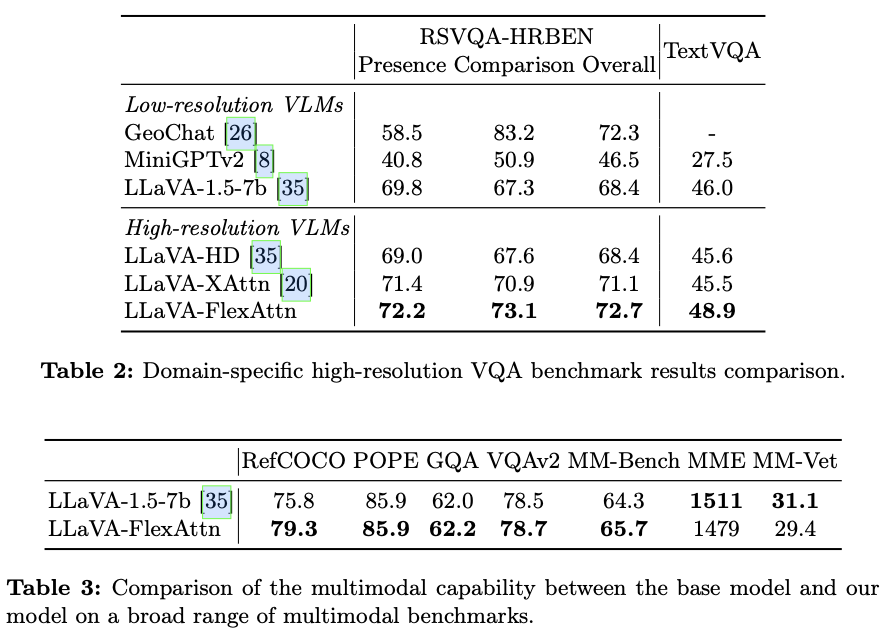
在几个高分辨率多模态基准测试上评估了 \({\tt {{FlexAttention}}}\) ,包括一般基准测试如V* Bench和Magnifierbench,以及领域特定的基准测试如TextVQA(文本理解)和RSVQA(遥感)。实验结果展示了与其他高分辨率方法相比表现更好,并且几乎减少了40%的计算成本。此外,在V* Bench上, \({\tt {{FlexAttention}}}\) 相比于商业聊天机器人如GPT-4V,获得了更高的分数。
Preliminary
-
Notation
对于高分辨率视觉语言模型,将其高分辨率图像输入定义为 \(I_{HR}\) ,文本输入定义为 \(T\) 。此外,定义低分辨率图像标记为 \(f_{LR}\) ,高分辨率图像标记为 \(f_{HR}\) ,文本标记为 \(f_{T}\) 。VLM的隐藏状态用 \(H \in \mathbb{R}^{N \times D}\) 表示,其中 \(N\) 为序列长度, \(D\) 为隐藏状态大小。隐藏状态 \(H\) 包含 \(N_i\) 个低分辨率图像标记,后跟 \(N_t\) 个文本标记。定义 \(f_{SHR}\) 为从 \(M\) 个高分辨率图像标记 \(f_{HR}\) 中选取的子集。
-
Autoregressive Large Language Models
自回归的大型语言模型(LLMs),如LLaMA,在大多数视觉语言模型中发挥关键作用,因为它们负责接收图像和文本标记作为输入并生成答案序列。自回归LLM由多个堆叠的解码器层构成。每个解码器层包含两个子层。第一个是自注意力模块,第二个是前馈(FFN)层。在每两个子层周围使用skip连接,接着是层归一化(LN)。简而言之,每个子层的输出为 \(\text{LN}(x+\text{SubLayer}(x))\) 。
-
Self-attention and Attention Map
自注意力是解码器层的基本模块。对于自注意力,给定输入的隐藏状态 \(H \in \mathbb{R}^{N\times D}\) ,首先会利用线性投影层将 \(H\) 投影为 \(Q\) 、 \(K\) 和 \(V\) ,即查询、键和值矩阵,并执行以下计算:
其中, \(Q=HW_{Q}\) , \(K=HW_{K}\) , \(V=HW_{V}\) ,且 \(W_{Q}\) / \(W_{K}\) / \(W_{V} \in \mathbb{R}^{D\times d}\) 是可学习的线性投影矩阵。具体来说,注意力映射 \(Map\) 在执行softmax操作后得到:
注意力映射 \(Map\) 是一个 \(N \times N\) 的矩阵,用于衡量标记之间的重要性:注意力映射中的(i, j)位置的值表示第j个标记对第i个标记的重要性,数值越高意味着第j个标记对第i个标记的重要性越大。
-
Limitation of Self-attention
自注意力机制的计算成本相对于隐藏状态 \(H\) 的序列长度 \(N\) 呈平方级增加。当结合高分辨率图像时,这种计算复杂性会进一步加大,因为这会显著增加图像标记的数量,进而延长隐藏状态的长度。因此,自注意力机制的计算需求大幅上升,使得处理高分辨率图像输入变得不切实际,因为其计算开销过于庞大。
Vision-language Model with FlexAttention
Overall Architecture
为了解决自注意力在处理高分辨率图像时的局限性,论文提出了 \({\tt {{FlexAttention}}}\) ,该方法通过动态关注高分辨率图像的重要区域,来有效分析高分辨率图像。 \({\tt {{FlexAttention}}}\) 可以通过用我们提出的 \({\tt {{FlexAttention}}}\) 模块替换大多数视觉语言模型中的自注意力模块,从而方便地集成到这些模型中。
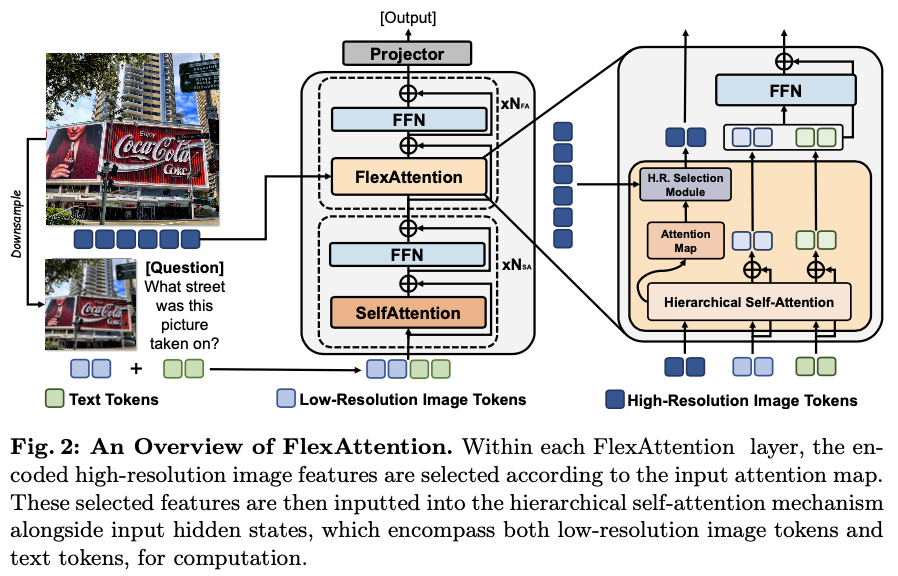
如图2所示,修改后的视觉-语言模型包括 \(N_{SA}+N_{FA}\) 个解码器层,其中前 \(N_{SA}\) 层采用标准自注意力模块,而后 \(N_{FA}\) 层采用论文提出的 \({\tt {{FlexAttention}}}\) 模块。
给定一个高分辨率图像,首先将其降采样为低分辨率图像,然后将这两种图像分别输入图像编码器,以获得高分辨率和低分辨率的图像标记。为了提高计算效率,仅将低分辨率图像标记和文本标记输入前 \(N_{SA}\) 层,用于对整体图像进行粗略理解。在接下来的 \(N_{FA}\) 个带有 \({\tt {{FlexAttention}}}\) 的解码器层中,为了有效感知更多图像细节,额外将选定的高分辨率图像标记输入其中。
具体而言, \({\tt {{FlexAttention}}}\) 包括两个模块:高分辨率特征选择模块和分层自注意力模块。高分辨率特征选择模块根据注意力图灵活选择重要的标记传递给下一层,而不是直接传递所有高分辨率标记。分层自注意力模块旨在将选定的高分辨率信息融合到原始隐藏状态中。最后,使用一个投影线性层生成文本输出。
High-resolution Feature Selection Module
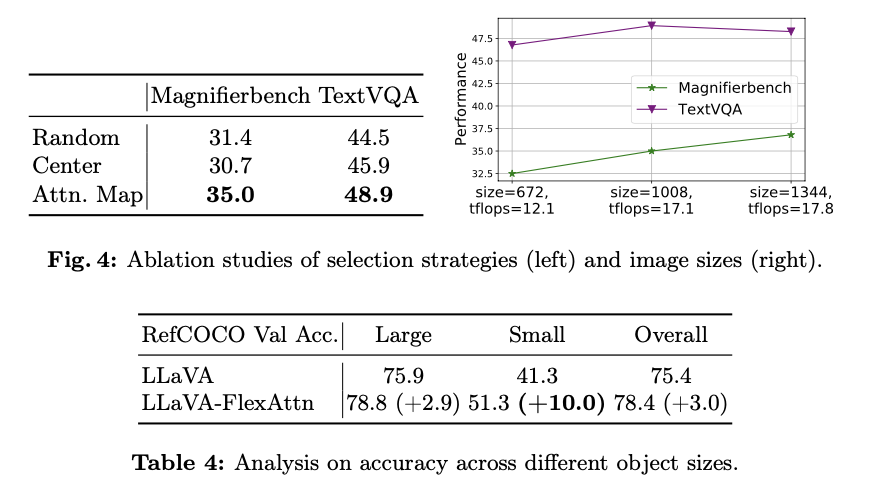
对于自回归语言模型,下一词由最后一个标记的最后隐藏状态预测。通过检查在公式2中的注意力图中与最后一个标记对应的所有其他标记的注意力值,可以找出在生成下一个预测标记时模型关注了哪些标记。在视觉-语言模型中,这同样适用于图像标记 \(f_{LR}\) 。那些具有高注意力值的图像标记可以被视为与重要图像区域相关的标记,用于生成下一个标记。尽管低分辨率图像标记中包含的细节有限,但仍然能够检索到已被关注的相同图像区域的高分辨率细节。因此,不将所有高分辨率标记输入到注意力模块中,因为这将导致过高的计算成本,而是动态选择一小部分(大约10%)高分辨率标记,即 \(f_{SHR}\) ,并仅将这部分传递给注意力模块。
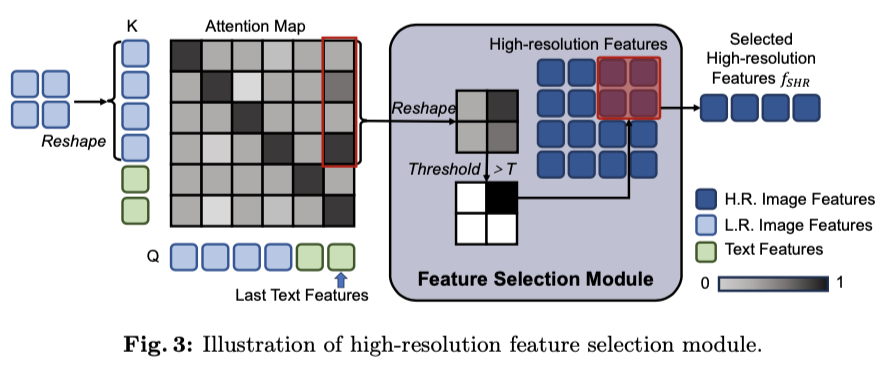
如图3所示,从注意力图的最后一列中提取前 \(N_i\) 个值,这些值对应于低分辨率图像标记对最后一个文本标记的重要性,并将该1维向量重新形状为2维图,称为注意力掩码。该掩码中的每个值均与低分辨率图像 \(I_{LR}\) 中的一个patch相关联,表示该patch的重要性。掩码经过归一化、二值化,并调整为与高分辨率特征patch标记相同的大小,从而形成高分辨率选择掩码,作为是否选择某个patch标记的选择决策。最后,将此掩码应用于高分辨率图像标记,以获取选定的高分辨率特征 \(f_{SHR}\) 。
Hierarchical Self-attention Module
分层自注意力是将选定的高分辨率标记 \(f_{SHR}\) 融合到包含低分辨率标记和文本标记的隐藏状态 \(H\) 中的核心机制。以选定的高分辨率标记 \(f_{SHR}\in\mathbb{R}^{M\times D}\) 和隐藏状态 \(H\in\mathbb{R}^{N\times D}\) 作为输入,输出注意力图 \(Map'\) 和更新后的隐藏状态 \(H'\) ,计算如下:
其中 \(W_{Q}\) / \(W_{K}\) / \(W_{V}\) / \(W_{K}'\) / \(W_{V}'\) \(\in\mathbb{R}^{D\times d}\) 是可学习的线性投影矩阵。 \(K_{all}\in\mathbb{R}^{(N+M)\times d}\) 和 \(V_{all}\in\mathbb{R}^{(N+M)\times d}\) 是融合了来自高分辨率特征的信息的键和值矩阵。与自注意力类似,在经过softmax操作后,可以获得一个注意力图:
与自注意力不同,此注意力图 \(Map'\) 的形状为 \(N\times(N+M)\) ,因为它额外包含了对应于其他标记的高分辨率标记的注意力值。仅保留矩阵中前 \(N \times N\) 的注意力值,以此作为用于选择将用于下一层的高分辨率特征的注意力图 \(Map\) 。

算法1描述了具有 \({\tt {{FlexAttention}}}\) 的视觉语言模型的工作流程。
Complexity Analysis
\({\tt {{FlexAttention}}}\) 的优势在于可以执行与传统自我关注类似的计算,从而最大限度地减少对模型结构的改动,同时促进多粒度特征的高效融合。假设所选高分辨率特征的长度为 \(M\),原始隐藏状态的长度为 \(N\),隐藏状态的大小为 \(D\)。分层自注意力的计算复杂度为:
如果不使用分层自注意力,而是直接将高分辨率图像与低分辨率图像相加,则计算复杂度将为
对于普通自注意力,额外高分辨率特征的添加将导致计算时间呈二次增长,因为需要处理显著更大的矩阵,序列中的每一个额外元素都会按元素增加计算负担。然而, \({\tt {{FlexAttention}}}\) 所采用的分层自注意力机制巧妙地通过保持额外高分辨率特征的线性关系来缓解这一问题,从而显著减少了计算负担。
Experiments
Implementation
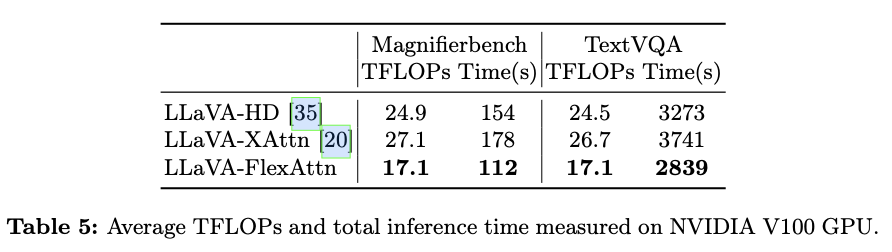
为了评估 \({\tt {{FlexAttention}}}\) 的性能和效率,将其集成到LLaVA-1.5-7b中,形成了一个变体,称为LLaVA-FlexAttn。输入分辨率设置为1008x1008,是原始输入图像分辨率的三倍。然后,将这个变体与原始的LLaVA-1.5-7b模型进行比较,以展示利用高分辨率图像输入的优势。此外,还将 \({\tt {{FlexAttention}}}\) 与允许高分辨率图像输入的LLaVA-1.5-HD和CogAgent进行比较,以展示其效率。
-
LLaVA-1.5-HD
在这个模型中,高分辨率图像标记像普通标记一样工作。它们与低分辨率图像令牌连接,并一起输入到大型语言模型中。由于这个模型尚未公开发布,论文在LLaVA-1.5的代码库上重新实现了它。使用LLaVA-1.5-7b模型作为基础模型,高分辨率图像的输入分辨率设为448x448,将此基线称为LLaVA-HD。
-
CogAgent
在这个模型中,高分辨率特征使用交叉注意力模块来感知。在交叉注意力模块中,高分辨率特征充当键(key)和值(value),而包括低分辨率图像令牌和文本令牌的隐藏状态则充当查询(query)。由于CogAgent是在文档和GUI样式数据上训练的,并且其数据处理和训练代码尚未公开,为了公平比较CogAgent中使用的高分辨率操作的有效性,将CogAgent推理代码中的交叉注意力模块转移到LLaVA-1.5上,并重新实现训练代码。使用LLaVA-1.5-7b模型作为基础模型,高分辨率图像的输入分辨率设置为1008x1008,将这个基线称为LLaVA-XAttn。
Training Settings
为了进行公平比较,高分辨率的基线模型(LLaVA-HD和LLaVA-XAttn)以及论文的LLaVA-FlexAttn都加载LLaVA-1.5-7b的预训练权重作为初始化,并在LLaVA-1.5-7b的微调数据集上进行一轮微调。使用批量大小为1152和学习率为2e-5,并使用余弦学习率调度器,所有评估都以zero-shot方式进行。
Evaluation on High-resolution Multimodal Benchmarks
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】





![P4655 [CEOI2017] Building Bridges](https://img2024.cnblogs.com/blog/2940791/202408/2940791-20240828090719589-2096778297.png)