原创 M09ic ChainReactor
Next Generation HTTP Dir/File Fuzz Tool: https://github.com/chainreactors/spray
Fast passive URL enumeration Tool: https://github.com/chainreactors/urlfounder
为什么我们需要收集URL?
这个问题似乎在最基础的安全岗面试中都不太可能出现,但如果要彻底理解dir/file fuzz,我们需要先搞清楚这个问题。
如果你每次都会拿起自己珍藏的字典对着目标一顿轰炸,那么可能需要好好想想目录里的user.php 真的有用么。如果有用,用爬虫不是更好么?
在红蓝对抗中,资产的最小单位为一个 service,这个 service 可以理解为部署在某一台服务器上的服务。例如一个论坛服务,里面可能有 user.php,forum.php 等等一堆目录。但对攻击者来说,只需要知道指纹,这些目录都可以从源码中直接找到, 并不需要爆破。而如果是不开源的应用, 这些目录可以通过爬虫去发现。这样的一个页面 在红蓝对抗,甚至大部分渗透测试中都不需要通过爆破去发现。
只有闭源的, 且管理页面做了特殊保护的站点, 才需要通过目录爆破去发现admin目录。 user.php, register.php在html与js中就能被爬虫爬到.
那什么样的场景才需要爆破?
URL爆破是一个成本很大, 动静很大的行为, 所以需要带有目的性. 一定需要爆破的场景例如
1、发现配置文件 (git, svn, sbom, config, env等)
2、特定指纹/漏洞的url
3、发现备份文件
4、发现基于url/基于host反代的路由
5、根据站点特征发现敏感api
其中只有1,2 是通用的, 345是需要根据目标去定制字典的.
小结:目录爆破不是为了发现更多的 URL,而是去发现更多有用的 URL。
怎么爆破目录/文件?
当我拿起dirbuster, dirsearch, dirmap, gobuster, fexobuster, ffuf等等一系列似乎是为了解决这个需求的工具时, 第一反应就是字典怎么办?或多或少有些不顺手(ffuf是其中最顺手的). 相信不止我有这个感觉. 当然本文的重点不是对比各种工具的性能, 细节, 用法.
他们解决问题的方式大同小异, 可以理解成手上有一个字典, 然后依次把每个包打过去, 获取一些信息. 然而在多年的实战中, 我发现大部分时候都找不到一个allinone的字典. 有一些开源的项目或者大佬手上的目录字典都到了十几万甚至几十万几百万量级. 解决这个问题的方式似乎就变成了找到一个更全的字典.
不断增长的字典可以解决这个问题么?
经常在国内做渗透服务的朋友们应该都遇到过例如 hzzx, smsbk这样的不知所以然, 但总感觉有规律的目录. 如果成功打进去, 可能就能知道这些字母表示的含义. hzzx 表示的是杭州中心 , smsbk 表示的是市民社保卡. 如果要把这种目录加到字典里, 那么3位小写随机字母有17576, 4位有456976, 5位就有11881376. 如果有大写字母或者数字加入, 就更加夸张了.
而这样的目录在当前网络架构下非常常见, 经常可以遇到某个银行使用一台机器反代了多个服务, 通过url/host区分后端地址.
如果采用传统的基于字典的目录爆破, 这样的目录在所有的工具面前都是隐形的. 我在github上粗略浏览了各种目录字典, 目前还没有发现能涵盖上述常见的. 但就算生成了这样的字典, 一千多万的发包数量本身就不太可被接受.
上面也提到了, 基于字典的目录爆破只能解决1,2场景. 绝大部分场景不是通过字典积累解决的.
那该如何爆破呢?
通过刚才的例子熟悉hashcat的朋友可能会发现, 这种需求与构造密码字典时是非常相似的. 只需要通过hashcat hybrid(https://hashcat.net/wiki/doku.php?id=hybrid_attack), 即可生成字典, 例如已知某个银行的后缀带有b, 那么爆破的空间指数级下降.
而在备份文件爆破中, 例如常见的习惯可能是 sitename.zip, 或者vim的临时文件 ~filename, 也完全对应hashcat中的rule-base(https://hashcat.net/wiki/doku.php?id=rule_based_attack) .
还有没有更多的办法?
答案是肯定, 与我有类似想法的人不少, 有许多先行者也给出了一些字典生成的方案. 例如:
https://github.com/musana/fuzzuli 根据域名生成备份文件字典
https://github.com/tomnomnom/waybackurls 根据已知的url生成新的url
https://github.com/Josue87/gotator 与waybackurls方法类似, 根据关键字去组合子域名
https://github.com/tomnomnom/unfurl 根据部分已知信息生成字典
有一些是用来生成子域名字典的, 不过思路大同小异. 都是通过部分已知数据进行各种方式的组合拼接. 实现派生出一系列相关联的字典.
当然这只是一小部分字典生成的玩法, 还有更加花里胡哨的方式.
小结:
澄清了积累字典的方式解决不了URL爆破问题, 而生成字典能缓解一部分问题, 但不是全部.
如何判断哪些目录/文件是有效的?
这同样是一个基础面试中都很难问出的"简单"问题, 但与"为什么要收集url"一样有非常多的习以为常的误会.
200的目录是有效的吗?
很多扫描器通过状态码去判断URL有效性, 例如dirsearch, dirmap等. 但200页面有非常多的例外. 例如
某个API通过json返回错误信息, 所有接口都是200
某个404页面添加了公益信息, 所有404页面都是200
某个网站通过js调整到404页面, 所有路由都是200
......
显然200页面不一定是有效的.
404页面一定是无效的吗?
当然通常情况下是, 但也有很多例外情况. 例如:
某个页面需要鉴权, 未授权的页面都返回了404
某个api接口做了全局的错误处理, 参数不存在则返回404
命中了某个反代, 返回了后端的某个地址, 但后端服务的首页是404 (在好几次红蓝对抗中, 找到了被友商遗漏的这样的资产)
......
类似的问题还有很多, 400页面, 403页面, 405页面, 500页面等等等等, 每个状态码都有非常多的应用场景与约定俗成的细节.
如何高效判断有效目录?
开源世界是有一些实现的, 例如ffuf的自定义过滤规则(https://github.com/ffuf/ffuf#interactive-mode)与feroxbuster的page similarity(https://epi052.github.io/feroxbuster-docs/docs/examples/filter-similar/).
ffuf可以通过复杂的参数去根据目标网站自定义过滤规则, 实现对有价值目录的过滤. 缺点是配置麻烦, 无法自动化
feroxbuster则通过page similarity(网页相似度)实现了一定程度的自动化过滤, 缺点是相似度需要手动配置, 可以写一个脚本自动化, 但也不够灵活, 并存在较多的误报与漏报.
要做到自动的去判断有效目录, 确实是一件比较困难的事情, 真实时间的特例太多, 就算请来了ChatGPT 也难说能判断每个返回包是否有效.
因此, 我们只能在准确率与效率之间取舍, 得到一个尽可能完美的方案.
我们总结了前人的代码与自身的经验, 采用了通过先获取基准值, 再将后续请求与基准值对比, 并通过大量的经验公式去修正一些特殊的case. 实现了一套非常复杂的判断机制. 现在这套机制经过了半年的测试, 运作良好. 虽不免时不时出现一些例外, 但也能通过良好的debug信息去人工调整.
我们将这一套经验自动化, 写成了下一代目录fuzz工具 --- spray
限于篇幅, 运作机制不在这里缀述. 可以参见wiki中的细节一章: https://chainreactors.github.io/wiki/spray/detail/#_2 .
示例:
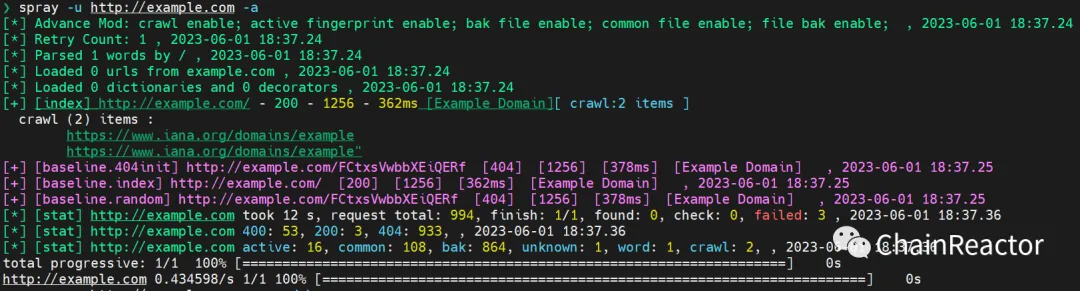
批量自动化爆破
在目录爆破中还有一个问题非常重要. 那就是同时对多个网站的爆破.
限于ffuf/feroxbuster都需要通过手动配置才能实现一定程度的智能过滤. 因此很难哪来同时爆破一批网站. 而更老的工具不是不支持, 就是支持的有限.
要解决批量自动化爆破, 关键点其实在"如何高效判断有效目录"上, 只要能解决这个问题, 并且不需要额外手动配置, 那么批量的自动化爆破问题就迎刃而解了.
除此之外, 多服务器协同的分布式爆破问题也将是关键因素. 因为任何高并发行为, 都特别容易被安全设备ban掉. 为了绕过这个限制, 除了分布式之外没有其他办法.
分布式的方案有很多, 云函数(存在监管, 有可能ban账号), 批量购买vps, 换绑IP等等.
spray自带了被ban判断, 被ban后能收集断点数据停止任务, 然后交给其他服务器断点续传继续任务.
被动收集URL
上面讨论的都是主动爆破URL的问题, 与子域名的收集类似. 除了主动爆破还可以被动收集.
子域名收集的技术已经非常成熟, 主动爆破, api查询都有非常充足的工具可以参考. 但URL目前开源的工具都是主动爆破的, 为了解决这个问题, 我们参考了subfinder的代码, fork并修改了一个通过api被动收集URL的工具.
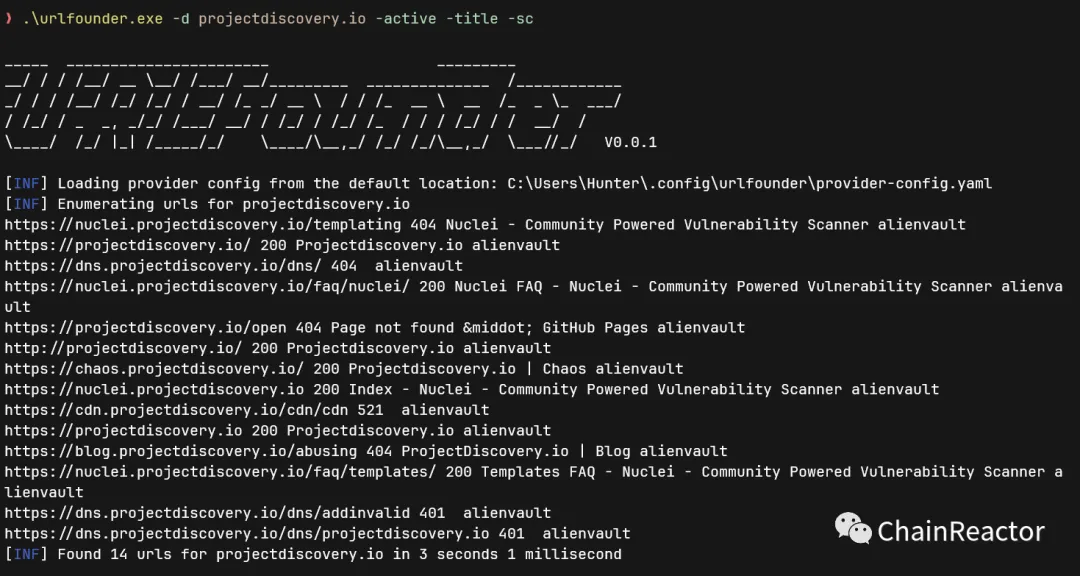
github地址: https://github.com/chainreactors/urlfounder
这个工具的各方面都与subfinder一致. 我们沿用了subfinder的大部分代码, 在一些url与子域名的差异上做了特殊优化.
例如收集完后可以通过-active -title -sc快捷获取状态码与title.
End
我们从主动与被动两个方面构建一套全新的url收集手段. 经过一段时间的测试后成为第二个与第三个开源的工件, 因为测试的人数有限, 有些参数的联动可能不少bug, 如果在使用的过程中遇到了bug, 欢迎提供issue反馈.
因为gogo发布时的介绍文章太过生硬, 因此本文尝试对urlfounder与spray采用问答的方式介绍. 实际上没有完全涵盖它们的能力范围, 特别是spray, 涉及了非常多的功能给用户自行探索, 当然也提供了完整的文档以供参考.
相信两个新的工具能丰富你信息收集的手段.
当初立下雄心壮志要编写出一款最强的ASM工具, 但当写完框架后发现开源的基建细粒度还不足以支撑起这一宏伟构想. 于是花费了一年时间编写了近十款各个细分领域的工件, 以做到对每个细节的把控. 让ASM不止停留在甲方才会购买的空洞的资产表, 而是能协助红队收集到其他任何工具都收集不到的信息.
工件补全工作已经完成了十之八九, 终于可以重新审视最初的需求, 如果我能做到对测绘过程中的每个细节精准把控并将其自动化, 能达到什么样的效果?