0 前言
- 为了便于学习决策树信息熵相关知识,笔者编写了一个专门用于计算变量信息熵、条件熵、信息增益、信息增益比的程序,方便提升学习效率。
- 程序中包含了计算过程的数据和详细信息以及最终计算结果。
- 编程语言为Python,搭配CSV数据格式使用。
1 数据集
1.1 游玩数据集
根据天气状况判断是否出去玩。
- 属性id表示每个样本的编号。
- 属性outlook表示户外天气。sunny晴天,overcast阴天,rainy雨天。
- 属性temperature表示温度,hot热,mild温暖,cool冷。
- 属性humidity表示湿度。high高,normal正常。
- 属性windy表示是否有风。not没有,yes有。
- 属性play表示是否出去玩。yes出去玩,no不出去玩。
数据集如下图(1-1)所示。
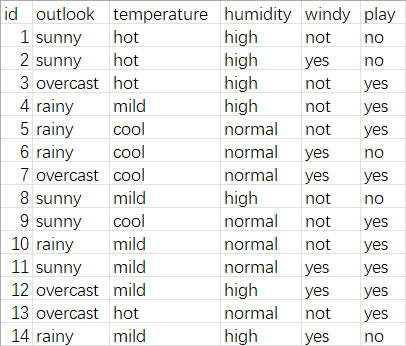
点击查看游玩.CSV
id,outlook,temperature,humidity,windy,play
1,sunny,hot,high,not,no
2,sunny,hot,high,yes,no
3,overcast,hot,high,not,yes
4,rainy,mild,high,not,yes
5,rainy,cool,normal,not,yes
6,rainy,cool,normal,yes,no
7,overcast,cool,normal,yes,yes
8,sunny,mild,high,not,no
9,sunny,cool,normal,not,yes
10,rainy,mild,normal,not,yes
11,sunny,mild,normal,yes,yes
12,overcast,mild,high,yes,yes
13,overcast,hot,normal,not,yes
14,rainy,mild,high,yes,no1.2 西瓜数据集
该数据集来源于西瓜书上,如下图(1-2)所示。
根据西瓜的特征等判断是否是好瓜。
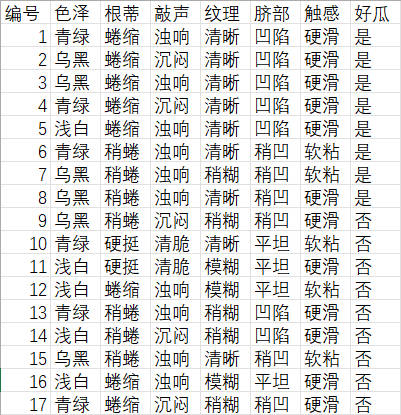
点击查看西瓜.CSV
编号,色泽,根蒂,敲声,纹理,脐部,触感,好瓜
1,青绿,蜷缩,浊响,清晰,凹陷,硬滑,是
2,乌黑,蜷缩,沉闷,清晰,凹陷,硬滑,是
3,乌黑,蜷缩,浊响,清晰,凹陷,硬滑,是
4,青绿,蜷缩,沉闷,清晰,凹陷,硬滑,是
5,浅白,蜷缩,浊响,清晰,凹陷,硬滑,是
6,青绿,稍蜷,浊响,清晰,稍凹,软粘,是
7,乌黑,稍蜷,浊响,稍糊,稍凹,软粘,是
8,乌黑,稍蜷,浊响,清晰,稍凹,硬滑,是
9,乌黑,稍蜷,沉闷,稍糊,稍凹,硬滑,否
10,青绿,硬挺,清脆,清晰,平坦,软粘,否
11,浅白,硬挺,清脆,模糊,平坦,硬滑,否
12,浅白,蜷缩,浊响,模糊,平坦,软粘,否
13,青绿,稍蜷,浊响,稍糊,凹陷,硬滑,否
14,浅白,稍蜷,沉闷,稍糊,凹陷,硬滑,否
15,乌黑,稍蜷,浊响,清晰,稍凹,软粘,否
16,浅白,蜷缩,浊响,模糊,平坦,硬滑,否
17,青绿,蜷缩,沉闷,稍糊,稍凹,硬滑,否
1.3 贷款数据集
该数据集来源于统计学习方法,数据如下图(1-3)所示。
根据一个人的家庭经济等条件判断是否要贷款给这个人,类别为是表示同意给此人贷款。反之不同意给此人贷款。
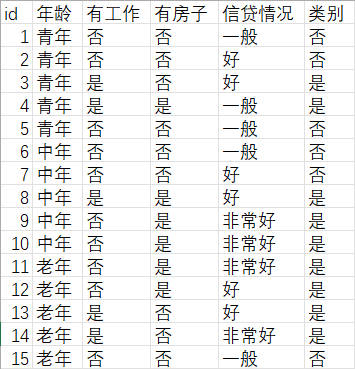
点击查看贷款.CSV
id,年龄,有工作,有房子,信贷情况,类别
1,青年,否,否,一般,否
2,青年,否,否,好,否
3,青年,是,否,好,是
4,青年,是,是,一般,是
5,青年,否,否,一般,否
6,中年,否,否,一般,否
7,中年,否,否,好,否
8,中年,是,是,好,是
9,中年,否,是,非常好,是
10,中年,否,是,非常好,是
11,老年,否,是,非常好,是
12,老年,否,是,好,是
13,老年,是,否,好,是
14,老年,是,否,非常好,是
15,老年,否,否,一般,否
2 程序解读
程序函数解读如下图(2-1)所示,从上至下浏览。
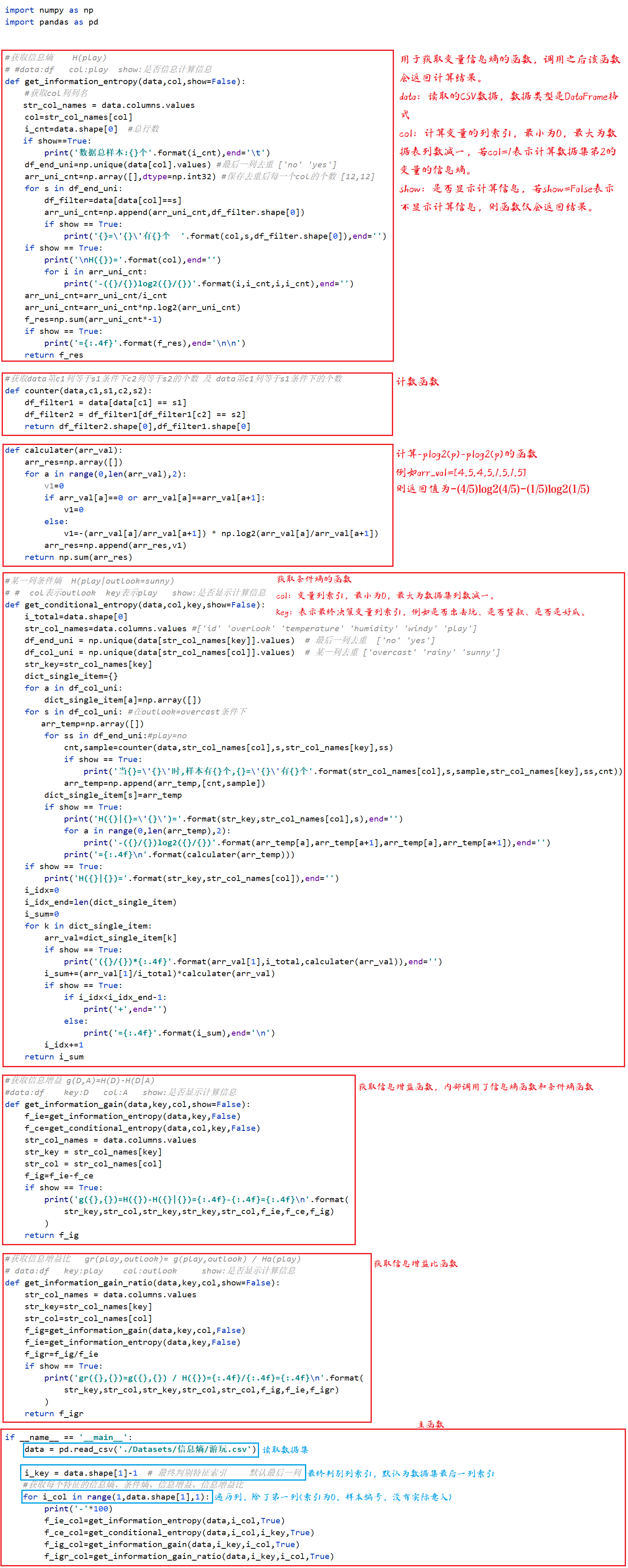
3 运行结果解读
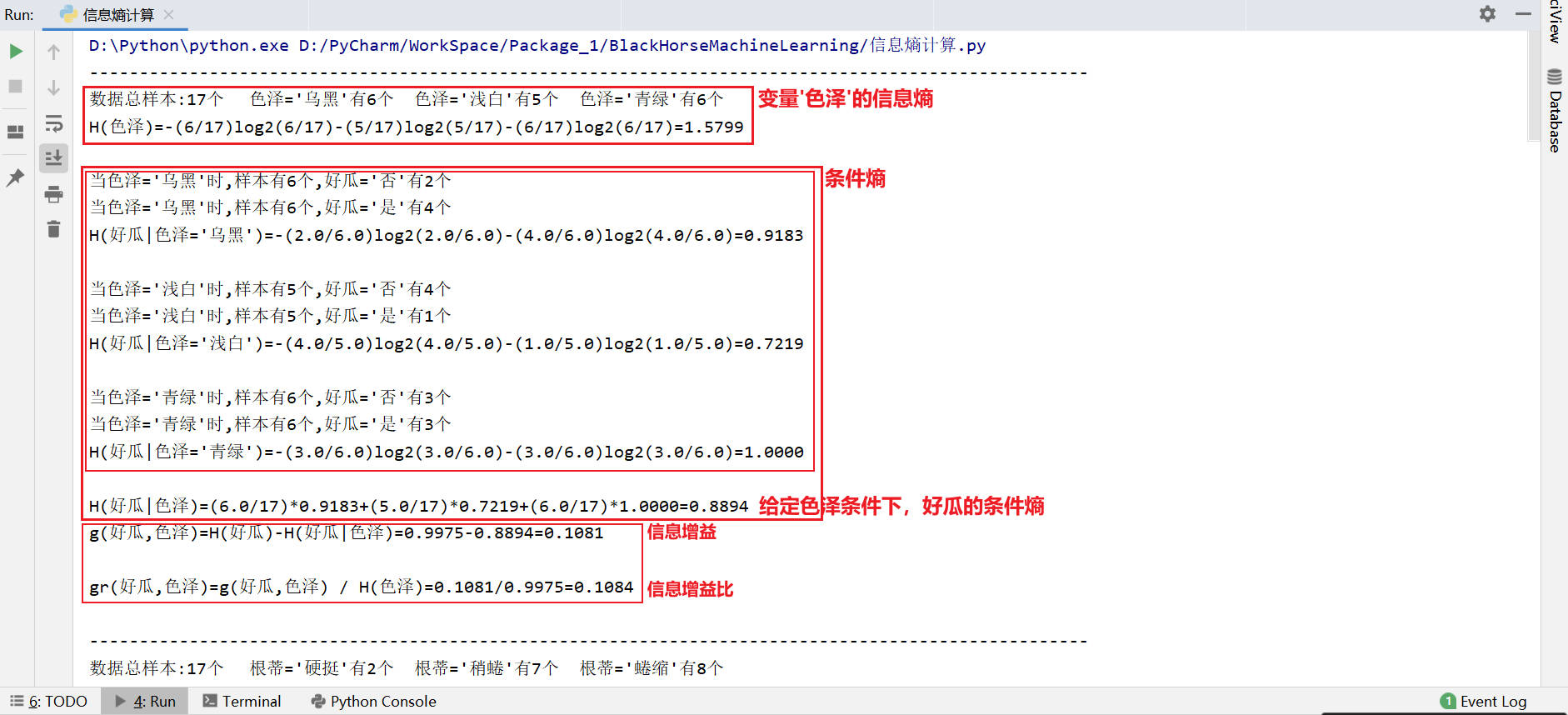
此处笔者使用了西瓜数据集。
data = pd.read_csv('./Datasets/信息熵/西瓜.csv')
运行结果如下图(2-2)所示。
4 程序源代码
点击查看代码
import numpy as np
import pandas as pd#获取信息熵 H(play)
# #data:df col:play show:是否信息计算信息
def get_information_entropy(data,col,show=False):#获取col列列名str_col_names = data.columns.valuescol=str_col_names[col]i_cnt=data.shape[0] #总行数if show==True:print('数据总样本:{}个'.format(i_cnt),end='\t')df_end_uni=np.unique(data[col].values) #最后一列去重 ['no' 'yes']arr_uni_cnt=np.array([],dtype=np.int32) #保存去重后每一个col的个数 [12,12]for s in df_end_uni:df_filter=data[data[col]==s]arr_uni_cnt=np.append(arr_uni_cnt,df_filter.shape[0])if show == True:print('{}=\'{}\'有{}个 '.format(col,s,df_filter.shape[0]),end='')if show == True:print('\nH({})='.format(col),end='')for i in arr_uni_cnt:print('-({}/{})log2({}/{})'.format(i,i_cnt,i,i_cnt),end='')arr_uni_cnt=arr_uni_cnt/i_cntarr_uni_cnt=arr_uni_cnt*np.log2(arr_uni_cnt)f_res=np.sum(arr_uni_cnt*-1)if show == True:print('={:.4f}'.format(f_res),end='\n\n')return f_res#获取data第c1列等于s1条件下c2列等于s2的个数 及 data第c1列等于s1条件下的个数
def counter(data,c1,s1,c2,s2):df_filter1 = data[data[c1] == s1]df_filter2 = df_filter1[df_filter1[c2] == s2]return df_filter2.shape[0],df_filter1.shape[0]def calculater(arr_val):arr_res=np.array([])for a in range(0,len(arr_val),2):v1=0if arr_val[a]==0 or arr_val[a]==arr_val[a+1]:v1=0else:v1=-(arr_val[a]/arr_val[a+1]) * np.log2(arr_val[a]/arr_val[a+1])arr_res=np.append(arr_res,v1)return np.sum(arr_res)#某一列条件熵 H(play|outlook=sunny)
# # col表示outlook key表示play show:是否显示计算信息
def get_conditional_entropy(data,col,key,show=False):i_total=data.shape[0]str_col_names=data.columns.values #['id' 'overlook' 'temperature' 'humidity' 'windy' 'play']df_end_uni = np.unique(data[str_col_names[key]].values) # 最后一列去重 ['no' 'yes']df_col_uni = np.unique(data[str_col_names[col]].values) # 某一列去重 ['overcast' 'rainy' 'sunny']str_key=str_col_names[key]dict_single_item={}for a in df_col_uni:dict_single_item[a]=np.array([])for s in df_col_uni: #在outlook=overcast条件下arr_temp=np.array([])for ss in df_end_uni:#play=nocnt,sample=counter(data,str_col_names[col],s,str_col_names[key],ss)if show == True:print('当{}=\'{}\'时,样本有{}个,{}=\'{}\'有{}个'.format(str_col_names[col],s,sample,str_col_names[key],ss,cnt))arr_temp=np.append(arr_temp,[cnt,sample])dict_single_item[s]=arr_tempif show == True:print('H({}|{}=\'{}\')='.format(str_key,str_col_names[col],s),end='')for a in range(0,len(arr_temp),2):print('-({}/{})log2({}/{})'.format(arr_temp[a],arr_temp[a+1],arr_temp[a],arr_temp[a+1]),end='')print('={:.4f}\n'.format(calculater(arr_temp)))if show == True:print('H({}|{})='.format(str_key,str_col_names[col]),end='')i_idx=0i_idx_end=len(dict_single_item)i_sum=0for k in dict_single_item:arr_val=dict_single_item[k]if show == True:print('({}/{})*{:.4f}'.format(arr_val[1],i_total,calculater(arr_val)),end='')i_sum+=(arr_val[1]/i_total)*calculater(arr_val)if show == True:if i_idx<i_idx_end-1:print('+',end='')else:print('={:.4f}'.format(i_sum),end='\n')i_idx+=1return i_sum#获取信息增益 g(D,A)=H(D)-H(D|A)
#data:df key:D col:A show:是否显示计算信息
def get_information_gain(data,key,col,show=False):f_ie=get_information_entropy(data,key,False)f_ce=get_conditional_entropy(data,col,key,False)str_col_names = data.columns.valuesstr_key = str_col_names[key]str_col = str_col_names[col]f_ig=f_ie-f_ceif show == True:print('g({},{})=H({})-H({}|{})={:.4f}-{:.4f}={:.4f}\n'.format(str_key,str_col,str_key,str_key,str_col,f_ie,f_ce,f_ig))return f_ig#获取信息增益比 gr(play,outlook)= g(play,outlook) / Ha(play)
# data:df key:play col:outlook show:是否显示计算信息
def get_information_gain_ratio(data,key,col,show=False):str_col_names = data.columns.valuesstr_key=str_col_names[key]str_col=str_col_names[col]f_ig=get_information_gain(data,key,col,False)f_ie=get_information_entropy(data,key,False)f_igr=f_ig/f_ieif show == True:print('gr({},{})=g({},{}) / H({})={:.4f}/{:.4f}={:.4f}\n'.format(str_key,str_col,str_key,str_col,str_col,f_ig,f_ie,f_igr))return f_igrif __name__ == '__main__':data = pd.read_csv('./Datasets/信息熵/西瓜.csv')i_key = data.shape[1]-1 # 最终判别特征索引 默认最后一列#获取每个特征的信息熵、条件熵、信息增益、信息增益比for i_col in range(1,data.shape[1],1):print('-'*100)f_ie_col=get_information_entropy(data,i_col,True)f_ce_col=get_conditional_entropy(data,i_col,i_key,True)f_ig_col=get_information_gain(data,i_key,i_col,True)f_igr_col=get_information_gain_ratio(data,i_key,i_col,True)5 结语
如有错误请指正,禁止商用。




![题解:P11000 [蓝桥杯 2024 省 Python B] 数字串个数](https://cdn.luogu.com.cn/upload/image_hosting/abt5u2io.png?x-oss-process=image/resize,m_lfit,h_1700,w_2250)



![机器学习之——决策树信息熵计算[附加计算程序]](https://img2024.cnblogs.com/blog/3436794/202408/3436794-20240828120342024-734918946.jpg)
