上次的baseline方案,训练的模型,获得分数并不高,DataWhale提供了两个上分的思路
- 增加训练数据集
- 切换不同模型预训练权重
增加训练集的大小通常可以提高模型的泛化能力,因为更多的数据可以帮助模型学习到更多的特征和模式。但是,越大的数据集,就意味着需要更多的计算资源和时间来训练模型,以及可能出现的过拟合问题。
增加训练数据集
增大数据集的一些方法:
-
数据增强: 通过对现有数据进行变换(如旋转、缩放、裁剪、颜色调整等)来增加数据集的多样性。
-
合成数据: 使用数据合成技术生成新的训练样本,尤其是在数据稀缺的情况下。
-
数据挖掘: 从互联网或公共数据集中收集更多相关数据。
-
众包: 利用众包平台收集和标注数据。
-
迁移学习: 使用预训练模型作为起点,然后在较小的数据集上进行微调。
-
分层抽样: 确保数据集中的每个类别都有足够数量的样本。
-
交叉验证: 使用交叉验证来更有效地利用有限的数据,同时评估模型的稳定性。
-
正则化技术: 如L1或L2正则化,以减少过拟合的风险。
-
早停法: 在验证集上的性能不再提升时停止训练,以避免过拟合。
-
调整模型复杂度: 根据数据集的大小调整模型的复杂度,以找到最佳的模型容量。
这里,我们直接从数据集中划分更多的数据作为训练数据,同时,验证集也增大
训练集增大到30
for anno_path, video_path in zip(train_annos[:30], train_videos[:30]):print(video_path)anno_df = pd.read_json(anno_path)cap = cv2.VideoCapture(video_path)frame_idx = 0 while True:ret, frame = cap.read()if not ret:breakimg_height, img_width = frame.shape[:2]frame_anno = anno_df[anno_df['frame_id'] == frame_idx]cv2.imwrite('./yolo-dataset/train/' + anno_path.split('/')[-1][:-5] + '_' + str(frame_idx) + '.jpg', frame)if len(frame_anno) != 0:with open('./yolo-dataset/train/' + anno_path.split('/')[-1][:-5] + '_' + str(frame_idx) + '.txt', 'w') as up:for category, bbox in zip(frame_anno['category'].values, frame_anno['bbox'].values):category_idx = category_labels.index(category)x_min, y_min, x_max, y_max = bboxx_center = (x_min + x_max) / 2 / img_widthy_center = (y_min + y_max) / 2 / img_heightwidth = (x_max - x_min) / img_widthheight = (y_max - y_min) / img_heightif x_center > 1:print(bbox)up.write(f'{category_idx} {x_center} {y_center} {width} {height}\n')frame_idx += 1
验证集
for anno_path, video_path in zip(train_annos[-10:], train_videos[-10:]):print(video_path)anno_df = pd.read_json(anno_path)cap = cv2.VideoCapture(video_path)frame_idx = 0 while True:ret, frame = cap.read()if not ret:breakimg_height, img_width = frame.shape[:2]frame_anno = anno_df[anno_df['frame_id'] == frame_idx]cv2.imwrite('./yolo-dataset/val/' + anno_path.split('/')[-1][:-5] + '_' + str(frame_idx) + '.jpg', frame)if len(frame_anno) != 0:with open('./yolo-dataset/val/' + anno_path.split('/')[-1][:-5] + '_' + str(frame_idx) + '.txt', 'w') as up:for category, bbox in zip(frame_anno['category'].values, frame_anno['bbox'].values):category_idx = category_labels.index(category)x_min, y_min, x_max, y_max = bboxx_center = (x_min + x_max) / 2 / img_widthy_center = (y_min + y_max) / 2 / img_heightwidth = (x_max - x_min) / img_widthheight = (y_max - y_min) / img_heightup.write(f'{category_idx} {x_center} {y_center} {width} {height}\n')frame_idx += 1
切换不同模型预训练权重
先了解一下YOLO系列中常见的不同版本(s, m, l, x)的区别:
-
YOLO-S (Small): 这是YOLO系列中的小型版本,通常具有较少的参数和较低的计算需求。它适用于资源受限的环境,如移动设备或嵌入式系统,但可能在检测精度上有所牺牲。
-
YOLO-M (Medium): 中型版本提供了一个平衡点,它比小型版本有更多的参数和更高的计算需求,同时保持了较好的检测精度和速度。
-
YOLO-L (Large): 大型版本拥有最多的参数和最高的计算需求。它提供了更高的检测精度,但速度可能会慢于小型和中型版本。
-
YOLO-X (Extra Large): 这是YOLO系列中的超大型版本,它具有最多的参数和最高的计算需求。YOLO-X通常用于需要最高精度的场景,尽管它的速度可能不如其他版本快。
这里选择了YOLOv8s的预训练模型
同时增加训练回合
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"import warnings
warnings.filterwarnings('ignore')from ultralytics import YOLO
# model = YOLO("yolov8n.pt")
model = YOLO("yolov8s.pt")
results = model.train(data="yolo-dataset/yolo.yaml", epochs=30, imgsz=1080, batch=16)
这是baseline的训练日志

这是优化以后的训练日志
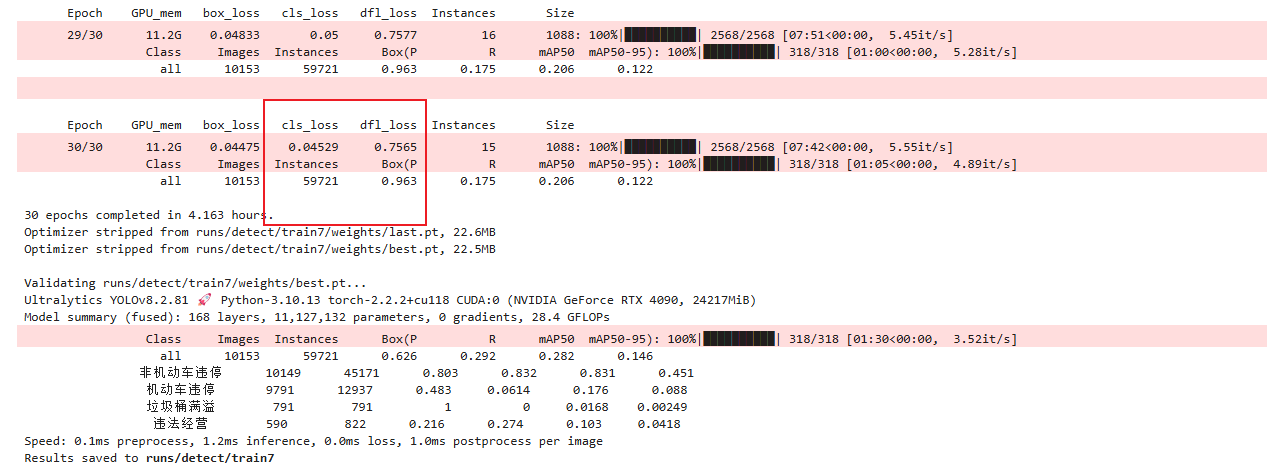
可以看到:
泛化能力(dfl_loss)和准确性(cls_loss)都有提高
![luoguP5369 [PKUSC2018] 最大前缀和](https://img2024.cnblogs.com/blog/1785205/202408/1785205-20240829222508682-974503557.png)