论文探索了在中型
ImageNet-1k数据集上预训练的普通ViT到更具挑战性的COCO目标检测基准的可迁移性,提出了基于Vision Transformer的You Only Look at One Sequence(YOLOS)目标检测模型。在具有挑战性的COCO目标检测基准上的实验结果表明,2D目标检测可以以纯sequence-to-sequence的方式完成,并且附加的归纳偏置最小来源:晓飞的算法工程笔记 公众号
论文: You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection

- 论文地址:https://arxiv.org/abs/2106.00666
- 论文代码:https://github.com/hustvl/YOLOS
Introduction
Vision Transformer(ViT) 证明,直接继承自NLP的Transformer编码器架构可以在大规模图像识别方面表现出色。以图像块嵌入序列作为输入,仅需少量的Fine-tune数据,ViT即可成功地从纯粹的sequence-to-sequence角度将足量数据预训练的视觉表达迁移到更具体的图像分类任务。
一个自然的问题是:ViT能否直接迁移到更具挑战性的对象和区域级目标任务中,例如图像级识别之外的目标检测?
ViT-FRCNN是第一个使用预先训练的ViT作为Faster R-CNN目标检测器的主干网络,但这种设计无法摆脱对卷积神经网络(CNN)的依赖和2D归纳偏差。因为ViT-FRCNN需要将ViT的输出序列重新排列为2D空间特征图,依赖于区域池化操作(即RoIPool或RoIAlign)以及基于区域的CNN架构来解码ViT特征,用于对象和区域级别的感知。
受现代CNN设计的启发,最近的一些工作将特征金字塔等设计引入到Vision Transformer中,这很大程度上提高了包括目标检测在内的密集预测任务的性能。但这些架构是以性能为导向的,不能反映Vision Transformer的特性。另外的一些如DEtection TRansformer(DETR) 的系列工作,使用随机初始化的Transformer来编码和解码CNN特征用于目标检测,也未揭示预训练Transformer的可迁移性。
直观上,ViT旨在学习远距离依赖关系和全局上下文信息,而不是本地和区域级别的关系。此外,ViT缺乏现代CNN那样的分层架构来处理视觉实体尺寸的巨大变化。根据现有的研究,目前尚不清楚纯ViT是否可以将预训练的通用视觉表达从图像级识别转移到更复杂的2D目标检测任务。
为了回答这个问题,论文提出了基于ViT架构的目标检测模型You Only Look at One Sequence(YOLOS),具有尽可能少的架构修改、区域先验以及目标任务相关归纳偏差。本质上,从预训练ViT到YOLOS检测器的变化非常简单:
- 将
ViT中用于图像分类的 \([\mathrm{CLS}]\) 标记替换为一百个用于目标检测的 \([\mathrm{DET}]\) 标记。 - 按照
DETR用二分匹配损失替换ViT的图像分类损失,以集合预测的方式进行目标检测。这可以避免像ViT-FRCNN那样将ViT的输出序列重新解释为2D特征图,以及防止在标签分配中引入启发式算法和2D空间结构的先验知识。而且,YOLOS的预测头可以摆脱复杂多样的设计,就像分类层一样紧凑。
YOLOS继承自ViT并不是为了成为另一个高性能目标检测器,而是为了揭示预训练的Transformer从图像识别到更具挑战性的目标检测任务的多功能性和可迁移性。具体来说,论文的主要贡献总结如下:
- 使用中型
ImageNet-1k作为唯一的预训练数据集,表明普通ViT可以成功迁移至复杂的目标检测任务,并以尽可能少的修改在COCO基准上达成有竞争力的结果。 - 首次证明通过将一系列固定大小的非重叠图像块作为输入,也可以以纯
sequence-to-sequence的方式完成2D目标检测。在现有的目标检测器中,YOLOS利用最小的2D归纳偏置。 - 对于原始
ViT,目标检测结果对预训练方法非常敏感并且检测性能远未饱和。因此,YOLOS也可以用作具有挑战性的基准任务来评估ViT的不同(标签监督和自监督)预训练策略。
You Only Look at One Sequence
YOLOS遵循原始ViT架构,并与DETR一样针对目标检测进行优化。YOLOS可以轻松适应NLP和计算机视觉中可用的各种Transformer架构,这种简单的设置并不是为了更好的检测性能而设计的,而是为了尽可能公正地准确揭示Transformer系列在目标检测中的特性。
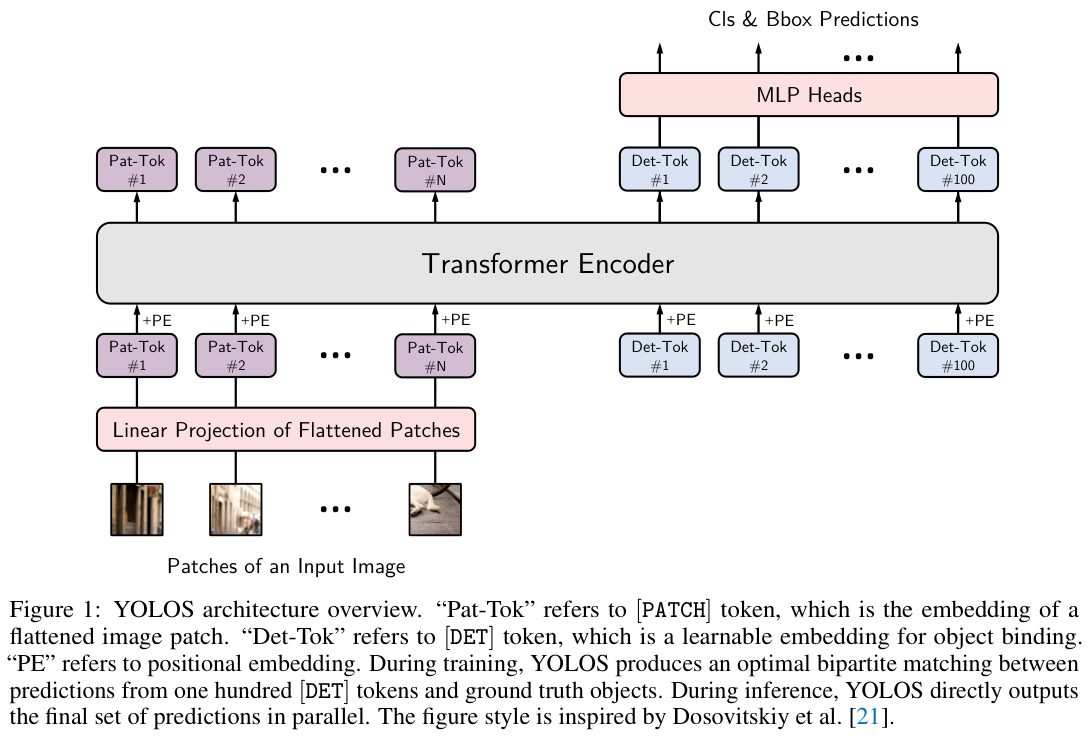
-
Architecture
模型架构如图 1 所示,从ViT分类器到YOLOS检测器的变化很简单:
-
删除用于图像分类的 \([\mathrm{CLS}]\) 标记,附加了一百个随机初始化的可学习检测标记 \([\mathrm{DET}]\) 到输入嵌入 \([\mathrm{PATCH}]\) 以进行目标检测。
-
在训练过程中,将图像分类损失替换为二分匹配损失,以遵循
DETR的设定预测方式进行目标检测。 -
Stem
常规ViT接收1D序列嵌入作为输入,为了处理2D图像输入,将图像 \(\mathbf{x}\in\mathbb{R}^{H\times W\times C}\) 重塑为展平的2D图像块 \(\mathbf{x}_{\mathrm{PATCH}}\in\mathbb{R}^{N\times(P^2 C)}\)。其中,\((H,W)\) 是输入图像的分辨率,\(C\) 是输入的通道数,\((P,P)\) 是每个图像块的分辨率,\(N=\frac{HW}{P^{2}}\) 是得到的图像块数量。
使用可训练的线性投影 \(\mathbf{E}\in\mathbb{R}^{(P^2 C)\times D}\) 将 \(\mathbf{x}_{\mathrm{PATCH}}\) 映射到 \(D\) 维,将投影输出 \(\mathbf{x}_{\mathrm{PATCH}}\mathbf{E}\) 作为 \([\mathrm{PATCH}]\) 标记。同时,一百个随机初始化的可学习 \([\mathrm{DET}]\) 标记 \(\mathbf{x}_{\mathrm{DET}}\in\mathbb{R}^{100\times D}\) 也被附加到 \([\mathrm{PATCH}]\) 标记中。
遵循VIT的做法,将标准的可学习1D位置嵌入 \(\mathbf{P}\in\mathbb{R}^{(N+100)\times D}\) 添加到所有输入标记中以保留位置信息。
最终得到序列 \(\mathbf{z}_{0}\) 作为YOLOS编码器的输入:
-
Body
YOLOS的主体与ViT基本相同,由一堆Transformer编码器层组成。\([{\mathrm{PATCH}}]\) 标记和 \([{\mathrm{DET}}]\) 标记被同等对待,在Transformer编码器层内执行全局交互。
每个Transformer编码器层由一个多头自注意力(MSA)块和一个MLP块组成,每个块前应用LayerNorm(LN)处理并且添加残差连接,其中MLP包含一个中间带有GELU非线性激活函数的隐藏层。形式上,第 \(\ell\) 个YOLOS编码器层的计算如下:
-
Detector Heads
YOLOS的检测头摆脱了复杂而笨重的设计,与ViT的图像分类层一样简洁。分类和边界框回归头各由一个MLP实现,其中包含两个带有ReLu非线性激活函数的隐藏层。
-
Detection Token
论文故意将随机初始化的 \([{\mathrm{DET}}]\) 标记作为对象查询,避免2D结构的归纳偏差以及在标签分配期间引入任务相关的先验知识。
在COCO上进行微调时,每次前向传递都会在 \([\mathrm{DET}]\) 标记生成的预测与GT之间建立最佳二分匹配。该过程与DETR的标签分配的作用相同,不接触输入的2D结构,即YOLOS不需要像ViT-FRCNN那样将ViT的输出序列重新排列为2D特征图以进行标签分配。理论上,YOLOS在不知道确切的空间结构和几何形状的情况下,执行任何维度的目标检测都是可行的,只要每次传递的输入始终以相同的方式扁平化为序列。
-
Fine-tuning at Higher Resolution
在COCO上进行微调时,除了用于分类和边界框回归的MLP头以及随机初始化的一百个 \([\mathrm{DET}]\) 标记之外,所有参数均从ImageNet-1k预训练权重中进行初始化。由于微调过程的图像分辨率比预训练时高得多,保持图像块大小 \(P\times P=16\times 16\) 不变就会导致更大的有效序列长度。虽然ViT可以处理任意输入序列长度,但位置嵌入需要执行2D插值以适应不同长度的输入序列。
-
Inductive Bias
论文精心设计了YOLOS架构,尽可能小地引入额外的归纳偏置,从ViT带来的归纳偏置主来自主干网络部分的图像块提取以及位置嵌入的分辨率调整。
除此之外,YOLOS在ViT上没有添加可能引入归纳偏置的卷积(例如 \(3\times 3\) 或其它非 \(1\times 1\))。从学习对象表达的角度来看,论文选择使用 \([{\mathrm{DET}}]\) 标记来绑定目标进行最终预测,避免额外的2D归纳偏置以及任务特定的启发算法。面向性能的CNN设计,如特征金字塔结构、2D局部空间注意力以及区域池化操作也没有使用。
所有这些设计都是为了在对输入的空间结构和几何形状了解最少的情况下,以纯粹的sequence-to-sequence的方式准确地揭示预训练Transformer从图像识别到目标检测的多功能性和可迁移性。
-
Comparisons with DETR
YOLOS的设计深受DETR的启发:YOLOS跟从DETR使用 \([{\mathrm{DET}}]\) 标记作为目标表达的代理,避免2D结构的归纳偏置和标签分配期间引入任务相关的先验知识,并且YOLOS的训练方式与DETR类似。
同时,两个模型之间存在一些关键区别:
-
DETR采用Transformer编码器-解码器架构,而YOLOS选择仅编码器的Transformer架构。 -
DETR仅在其CNN主干网络上采用预训练,但让Transformer编码器和解码器通过随机初始化进行训练,而YOLOS自然地继承了任何预训练的ViT表达。 -
DETR在编码图像特征和对象查询之间应用交叉注意力,并在每个解码器层添加辅助的解码损失,而YOLOS始终只查看每个编码器层的一个序列,而不区分 \([{\mathrm{PRTCH}}]\) 标记和 \([\mathrm{DET}]\) 标记。 -
Model Variants
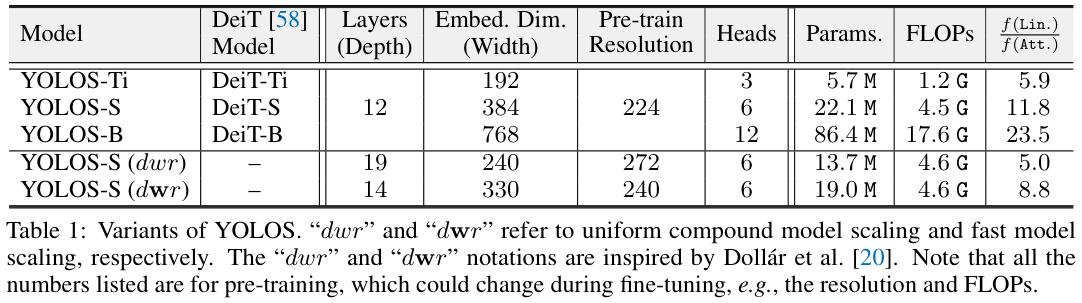
表 1 展示了不同大小的YOLOS变体。
Experiments
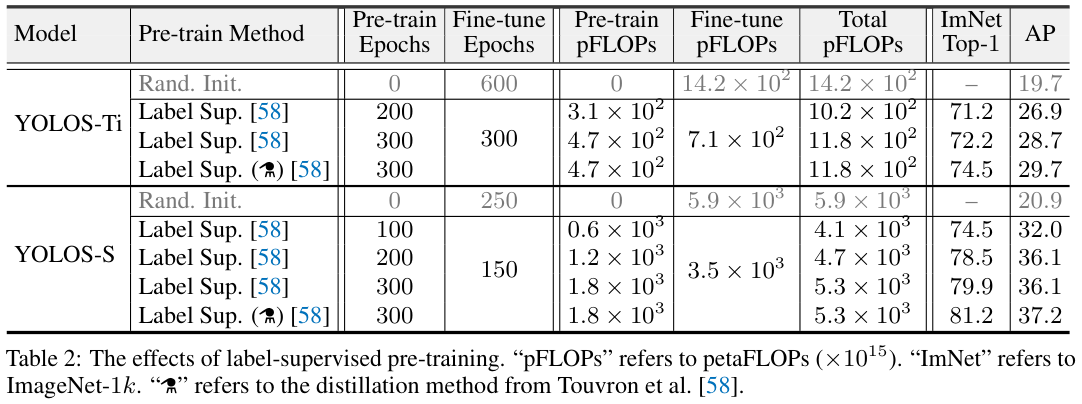

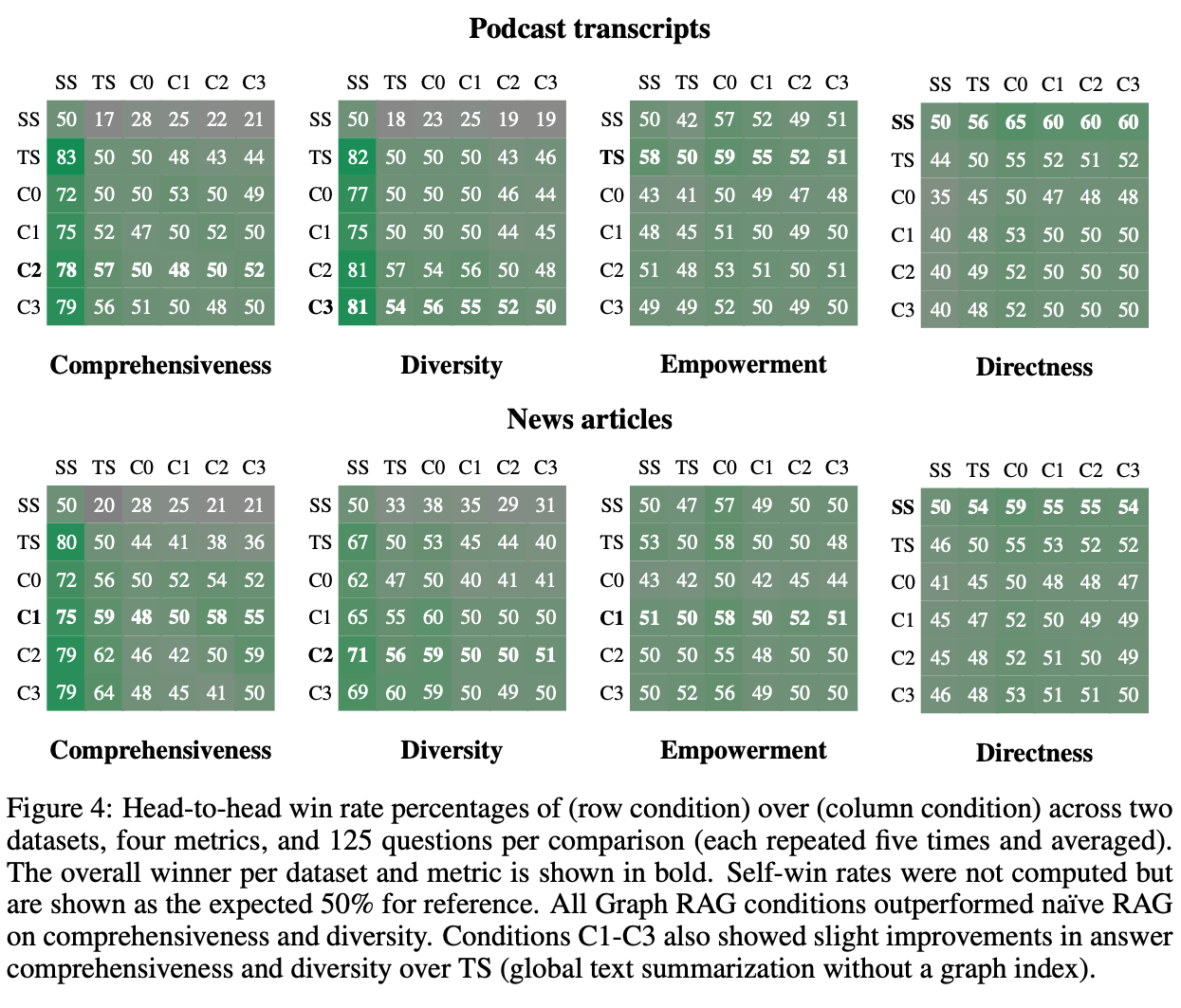
表 2 和 表 3 展示了不同预训练方法对性能的影响。
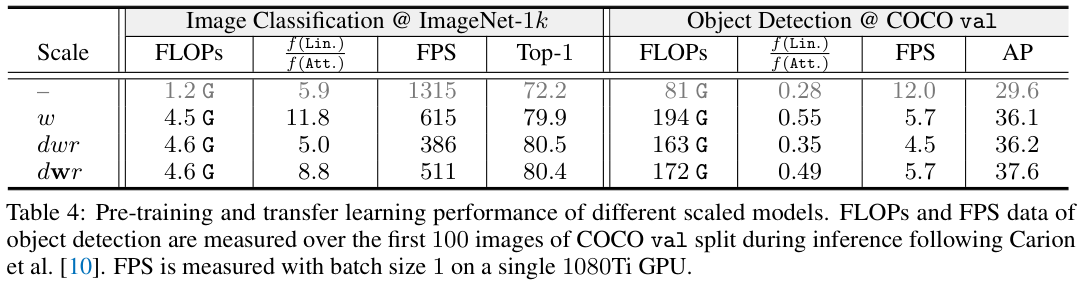
表 4 展示了不同大小模型的预训练性能以及迁移对性能对比。
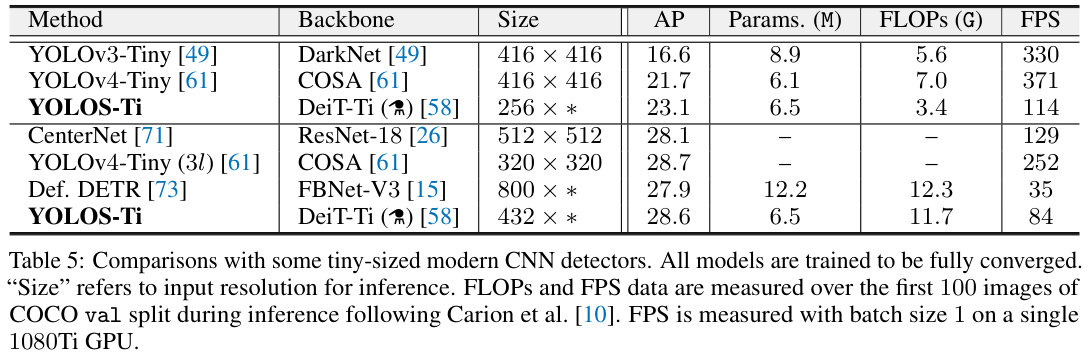
图 5 展示了与轻量级CNN目标检测模型对比。
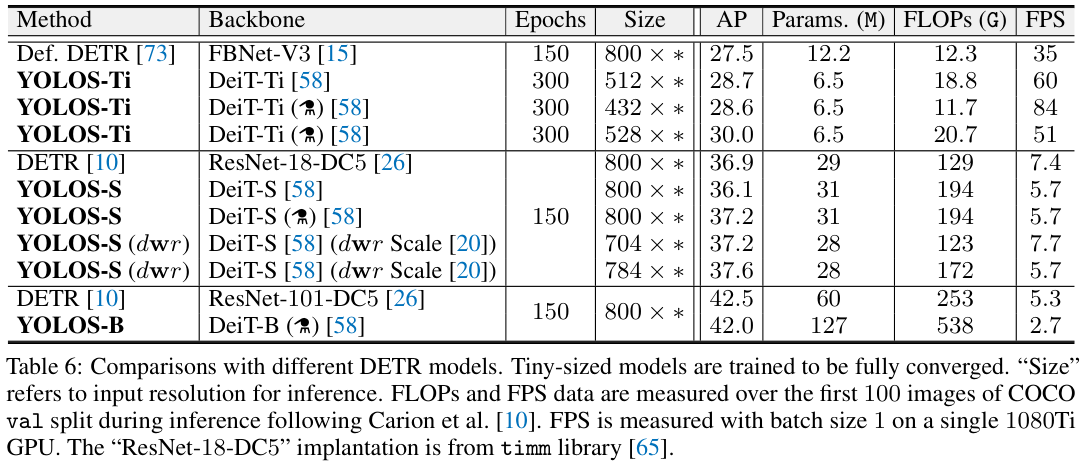
表 6 展示了与轻量级DETR目标检测模型对比。

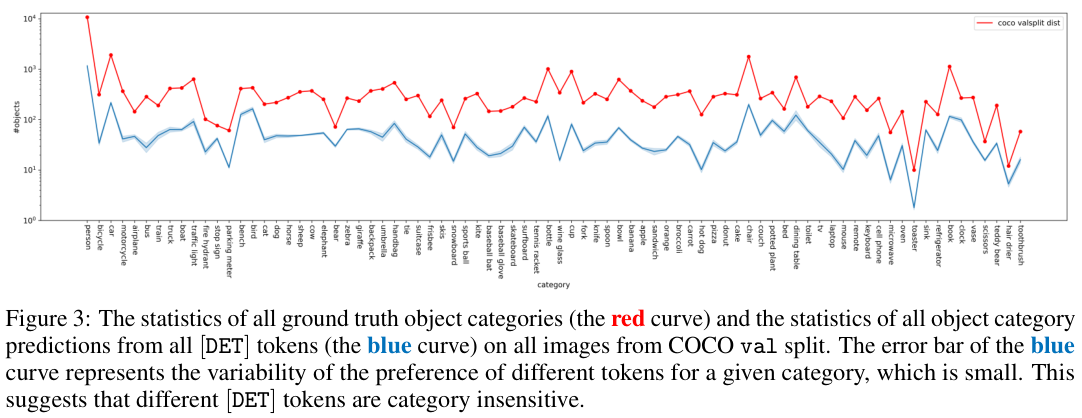
如图 2 和图 3 所示,\([{\mathrm{DET}}]\) 标记对目标位置和大小敏感,而对目标类别不敏感。
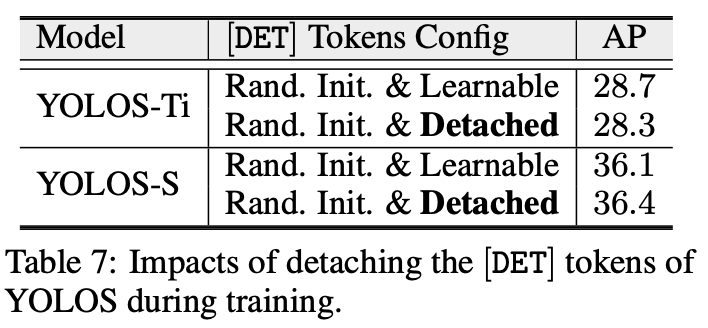
表 7 展示了去掉 \([\mathrm{DET}]\) 标记对性能的影响。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】