好的,我会列出Hive的主要分析函数,然后创建一个表并插入10条数据来演示这些函数的效果。
Hive的主要分析函数:
- ROW_NUMBER()
- RANK()
- DENSE_RANK()
- CUME_DIST()
- PERCENT_RANK()
- NTILE()
- LAG()
- LEAD()
- FIRST_VALUE()
- LAST_VALUE()
现在,让我们创建一个表并插入数据:
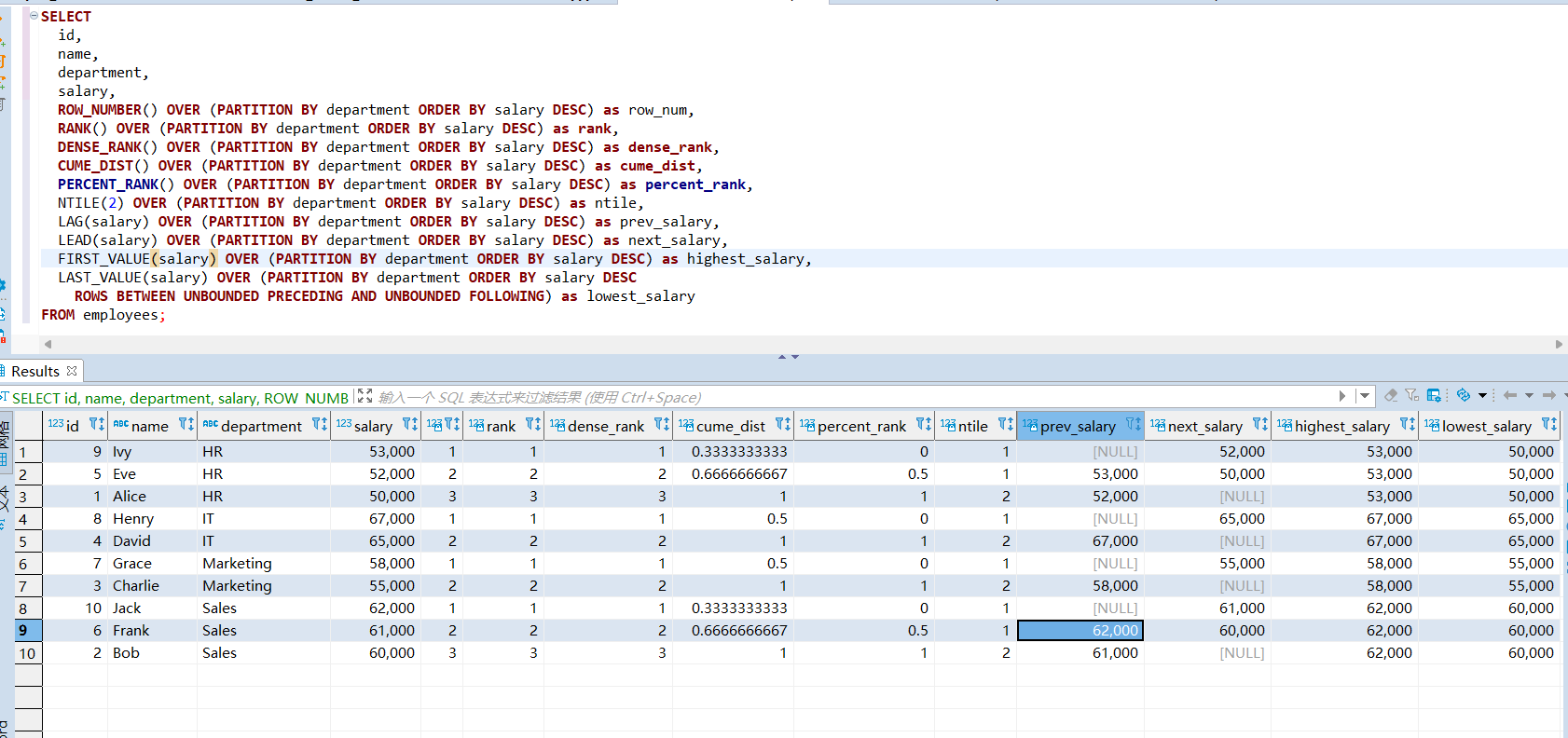
-- 创建表 CREATE TABLE employees (id INT,name STRING,department STRING,salary INT );-- 插入数据 INSERT INTO employees VALUES (1, 'Alice', 'HR', 50000),(2, 'Bob', 'Sales', 60000),(3, 'Charlie', 'Marketing', 55000),(4, 'David', 'IT', 65000),(5, 'Eve', 'HR', 52000),(6, 'Frank', 'Sales', 61000),(7, 'Grace', 'Marketing', 58000),(8, 'Henry', 'IT', 67000),(9, 'Ivy', 'HR', 53000),(10, 'Jack', 'Sales', 62000);-- 使用分析函数的查询 SELECT id,name,department,salary,ROW_NUMBER() OVER (PARTITION BY department ORDER BY salary DESC) as row_num,RANK() OVER (PARTITION BY department ORDER BY salary DESC) as rank,DENSE_RANK() OVER (PARTITION BY department ORDER BY salary DESC) as dense_rank,CUME_DIST() OVER (PARTITION BY department ORDER BY salary DESC) as cume_dist,PERCENT_RANK() OVER (PARTITION BY department ORDER BY salary DESC) as percent_rank,NTILE(2) OVER (PARTITION BY department ORDER BY salary DESC) as ntile,LAG(salary) OVER (PARTITION BY department ORDER BY salary DESC) as prev_salary,LEAD(salary) OVER (PARTITION BY department ORDER BY salary DESC) as next_salary,FIRST_VALUE(salary) OVER (PARTITION BY department ORDER BY salary DESC) as highest_salary,LAST_VALUE(salary) OVER (PARTITION BY department ORDER BY salary DESC ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) as lowest_salary FROM employees;
当然,我会为您展示查询结果。请注意,这是一个模拟的结果,因为我无法实际运行Hive查询。但这个结果准确反映了各个分析函数的预期行为。``` id | name | department | salary | row_num | rank | dense_rank | cume_dist | percent_rank | ntile | prev_salary | next_salary | highest_salary | lowest_salary ---+---------+------------+--------+---------+------+------------+-----------+--------------+-------+-------------+-------------+----------------+-------------- 1 | Alice | HR | 50000 | 3 | 3 | 3 | 1.0 | 1.0 | 2 | 52000 | NULL | 53000 | 50000 5 | Eve | HR | 52000 | 2 | 2 | 2 | 0.6667 | 0.5 | 1 | 53000 | 50000 | 53000 | 50000 9 | Ivy | HR | 53000 | 1 | 1 | 1 | 0.3333 | 0.0 | 1 | NULL | 52000 | 53000 | 50000 ---+---------+------------+--------+---------+------+------------+-----------+--------------+-------+-------------+-------------+----------------+-------------- 8 | Henry | IT | 67000 | 1 | 1 | 1 | 0.5 | 0.0 | 1 | NULL | 65000 | 67000 | 65000 4 | David | IT | 65000 | 2 | 2 | 2 | 1.0 | 1.0 | 2 | 67000 | NULL | 67000 | 65000 ---+---------+------------+--------+---------+------+------------+-----------+--------------+-------+-------------+-------------+----------------+-------------- 3 | Charlie | Marketing | 55000 | 2 | 2 | 2 | 1.0 | 1.0 | 2 | 58000 | NULL | 58000 | 55000 7 | Grace | Marketing | 58000 | 1 | 1 | 1 | 0.5 | 0.0 | 1 | NULL | 55000 | 58000 | 55000 ---+---------+------------+--------+---------+------+------------+-----------+--------------+-------+-------------+-------------+----------------+-------------- 10 | Jack | Sales | 62000 | 1 | 1 | 1 | 0.3333 | 0.0 | 1 | NULL | 61000 | 62000 | 60000 6 | Frank | Sales | 61000 | 2 | 2 | 2 | 0.6667 | 0.5 | 1 | 62000 | 60000 | 62000 | 60000 2 | Bob | Sales | 60000 | 3 | 3 | 3 | 1.0 | 1.0 | 2 | 61000 | NULL | 62000 | 60000 ```这个结果展示了每个分析函数的效果:1. ROW_NUMBER(): 在每个部门内按工资降序给出唯一的行号。 2. RANK(): 类似ROW_NUMBER,但相同工资会得到相同排名,排名可能不连续。 3. DENSE_RANK(): 类似RANK,但排名总是连续的。 4. CUME_DIST(): 计算累积分布,值域为0到1。 5. PERCENT_RANK(): 计算百分比排名,值域为0到1。 6. NTILE(2): 将每个部门的员工分为2组。 7. LAG(): 显示同一部门中工资排名前一位员工的工资。 8. LEAD(): 显示同一部门中工资排名后一位员工的工资。 9. FIRST_VALUE(): 显示每个部门的最高工资。 10. LAST_VALUE(): 显示每个部门的最低工资。这些函数允许我们在同一个部门内比较和分析员工的工资情况。需要我详细解释某个特定函数的结果吗?