Ch3-K均值聚类算法 【9月4日】
学号:102102156 姓名:高涛
1. make_circles方法生成数据
1.1 源代码
from sklearn.cluster import KMeans
from sklearn.datasets import make_circles, make_moons, make_blobs
import matplotlib.pyplot as plt
from utils.clustering_performance import clusteringMetrics
import matplotlibmatplotlib.use('TkAgg')
fig = plt.figure(1)
X1, y1 = make_circles(n_samples=400, factor=0.5, noise=0.1)
plt.subplot(321)
plt.title('original')
plt.scatter(X1[:, 0], X1[:, 1], c=y1)
plt.subplot(322)
plt.title('K-means')
kms = KMeans(n_clusters=2, max_iter=400) # n_cluster聚类中心数 max_iter迭代次数
y1_sample = kms.fit_predict(X1, y1) # 计算并预测样本类别
centroids = kms.cluster_centers_
plt.scatter(X1[:, 0], X1[:, 1], c=y1_sample)
plt.scatter(centroids[:, 0], centroids[:, 1], marker='*', c='b')
print(clusteringMetrics(y1, y1_sample))plt.show()
1.2 绘制结果

2. make_blobs方法生成数据
2.1 源代码
from sklearn.cluster import KMeans
from sklearn.datasets import make_circles, make_moons, make_blobs
import matplotlib.pyplot as plt
from utils.clustering_performance import clusteringMetrics
import matplotlibmatplotlib.use('TkAgg')
fig = plt.figure(1)
X2, y2 = make_moons(n_samples=400, noise=0.1)
plt.subplot(323)
plt.title('original')
plt.scatter(X2[:, 0], X2[:, 1], c=y2)
plt.subplot(324)
plt.title('K-means')
kms = KMeans(n_clusters=2, max_iter=400)
y2_sample = kms.fit_predict(X2, y2)
centroids = kms.cluster_centers_
plt.scatter(X2[:, 0], X2[:, 1], c=y2_sample)
plt.scatter(centroids[:, 0], centroids[:, 1], marker='*', c='b')
print(clusteringMetrics(y2, y2_sample))plt.show()
2.2绘制结果

3.make_blobs方法生成数据
3.1 源代码
from sklearn.cluster import KMeans
from sklearn.datasets import make_circles, make_moons, make_blobs
import matplotlib.pyplot as plt
from utils.clustering_performance import clusteringMetrics
import matplotlibmatplotlib.use('TkAgg')
fig = plt.figure(1)
X3, y3 = make_blobs(n_samples=1000, random_state=9) #
plt.subplot(325)
plt.title('original3')
plt.scatter(X3[:, 0], X3[:, 1], c=y3)
plt.subplot(326)
plt.title('K-means3')
kms = KMeans(n_clusters=3, max_iter=1000)
y3_sample = kms.fit_predict(X3, y3)
centroids = kms.cluster_centers_
# label = kms.labels_
plt.scatter(X3[:, 0], X3[:, 1], c=y3_sample)
plt.scatter(centroids[:, 0], centroids[:, 1], marker='*', c='b')
print(clusteringMetrics(y3, y3_sample))plt.show()
3.2 绘制结果

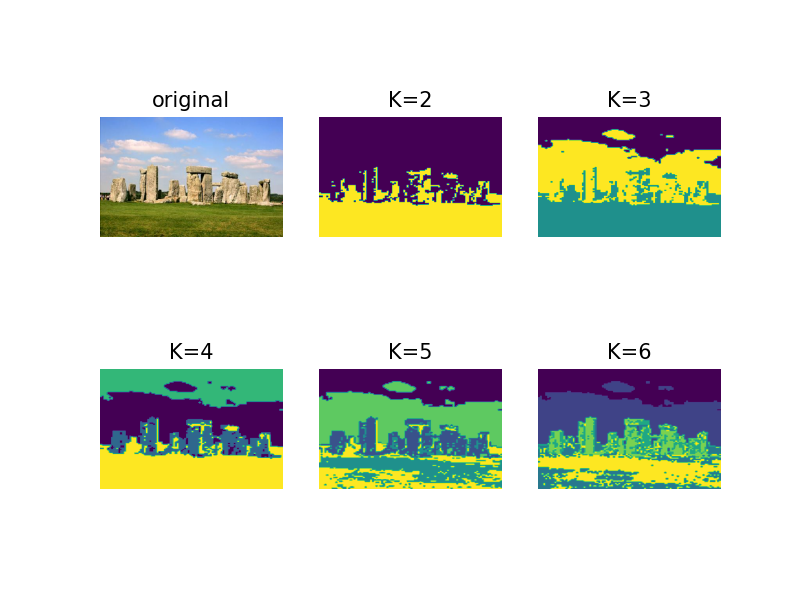
4.对像素进行聚类并可视化
4.1 源代码
from scipy.cluster.vq import *
from pylab import *
from PIL import Imageimport matplotlibmatplotlib.use('TkAgg')def clusterpixels(infile, k, steps):im = array(Image.open(infile))dx = im.shape[0] / stepsdy = im.shape[1] / stepsfeatures = []for x in range(steps): # RGB三色通道for y in range(steps):R = mean(im[int(x * dx):int((x + 1) * dx), int(y * dy):int((y + 1) * dy), 0])G = mean(im[int(x * dx):int((x + 1) * dx), int(y * dy):int((y + 1) * dy), 1])B = mean(im[int(x * dx):int((x + 1) * dx), int(y * dy):int((y + 1) * dy), 2])features.append([R, G, B])features = array(features, 'f') # make into array# 聚类, k是聚类数目centroids, variance = kmeans(features, k)code, distance = vq(features, centroids)codeim = code.reshape(steps, steps)codeim = np.array(Image.fromarray(codeim).resize((im.shape[1], im.shape[0])))return codeim# k = 5
infile_Stones = 'stones.png'
im_Stones = array(Image.open(infile_Stones))
steps = (50, 100) # image is divided in steps*steps region# 显示原图
figure()
subplot(231)
title('original')
axis('off')
imshow(im_Stones)for k in range(2, 7):codeim = clusterpixels(infile_Stones, k, steps[-1])subplot(2, 3, k)title('K=' + str(k))axis('off')imshow(codeim)show()
4.2 绘制结果
5.将给定数据集可视化并输出聚类性能
5.1 源代码 + 绘制结果
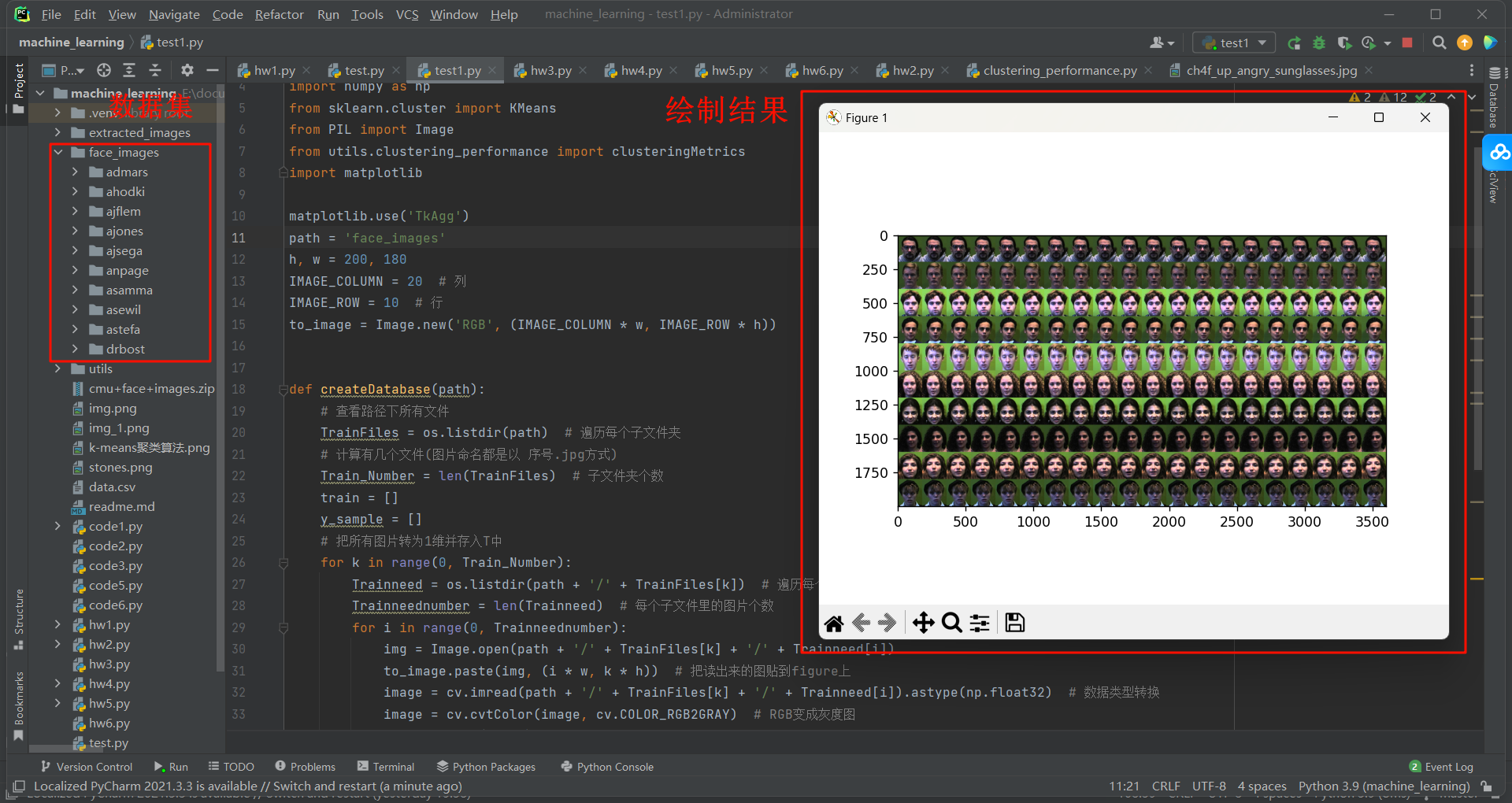
5.2 源代码
import matplotlib.pyplot as plt
import os
import cv2 as cv
import numpy as np
from sklearn.cluster import KMeans
from PIL import Image
from utils.clustering_performance import clusteringMetrics
import matplotlibmatplotlib.use('TkAgg')
path = 'face_images'
h, w = 200, 180
IMAGE_COLUMN = 20 # 列
IMAGE_ROW = 10 # 行
to_image = Image.new('RGB', (IMAGE_COLUMN * w, IMAGE_ROW * h))def createDatabase(path):# 查看路径下所有文件TrainFiles = os.listdir(path) # 遍历每个子文件夹# 计算有几个文件(图片命名都是以 序号.jpg方式)Train_Number = len(TrainFiles) # 子文件夹个数train = []y_sample = []# 把所有图片转为1维并存入T中for k in range(0, Train_Number):Trainneed = os.listdir(path + '/' + TrainFiles[k]) # 遍历每个子文件夹里的每张图片Trainneednumber = len(Trainneed) # 每个子文件里的图片个数for i in range(0, Trainneednumber):img = Image.open(path + '/' + TrainFiles[k] + '/' + Trainneed[i])to_image.paste(img, (i * w, k * h)) # 把读出来的图贴到figure上image = cv.imread(path + '/' + TrainFiles[k] + '/' + Trainneed[i]).astype(np.float32) # 数据类型转换image = cv.cvtColor(image, cv.COLOR_RGB2GRAY) # RGB变成灰度图train.append(image)y_sample.append(k)train = np.array(train)y_sample = np.array(y_sample)return train, y_sample# n_samples, h, w = 200, 200, 180
X, y = createDatabase(path)
# print(X.shape)
X_ = X.reshape(X.shape[0], h*w)kms = KMeans(n_clusters=10)
y_sample = kms.fit_predict(X_, y)
print(clusteringMetrics(y, y_sample))plt.imshow(to_image)
plt.show()