为什么主键索引最好是有序递增的
我们在建表的时候,都会默认将主键索引设置为自增的,具体为什么要这样做呢?又什么好处?
InnoDB 创建主键索引默认为聚簇索引,数据被存放在了 B+Tree 的叶子节点上。也就是说,同一个叶子节点内的各个数据是按主键顺序存放的,因此,每当有一条新的数据插入时,数据库会根据主键将其插入到对应的叶子节点中。
如果我们使用自增主键,那么每次插入的新数据就会按顺序添加到当前索引节点的位置,不需要移动已有的数据,当页面写满,就会自动开辟一个新页面。因为每次插入一条新记录,都是追加操作,不需要重新移动数据,因此这种插入数据的方法效率非常高。
如果我们使用非自增主键,由于每次插入主键的索引值都是随机的,因此每次插入新的数据时,就可能会插入到现有数据页中间的某个位置,这将不得不移动其它数据来满足新数据的插入,甚至需要从一个页面复制数据到另外一个页面,我们通常将这种情况称为页分裂。页分裂还有可能会造成大量的内存碎片,导致索引结构不紧凑,从而影响查询效率。
举个例子,假设某个数据页中的数据是1、3、5、9,且数据页满了,现在准备插入一个数据7,则需要把数据页分割为两个数据页:
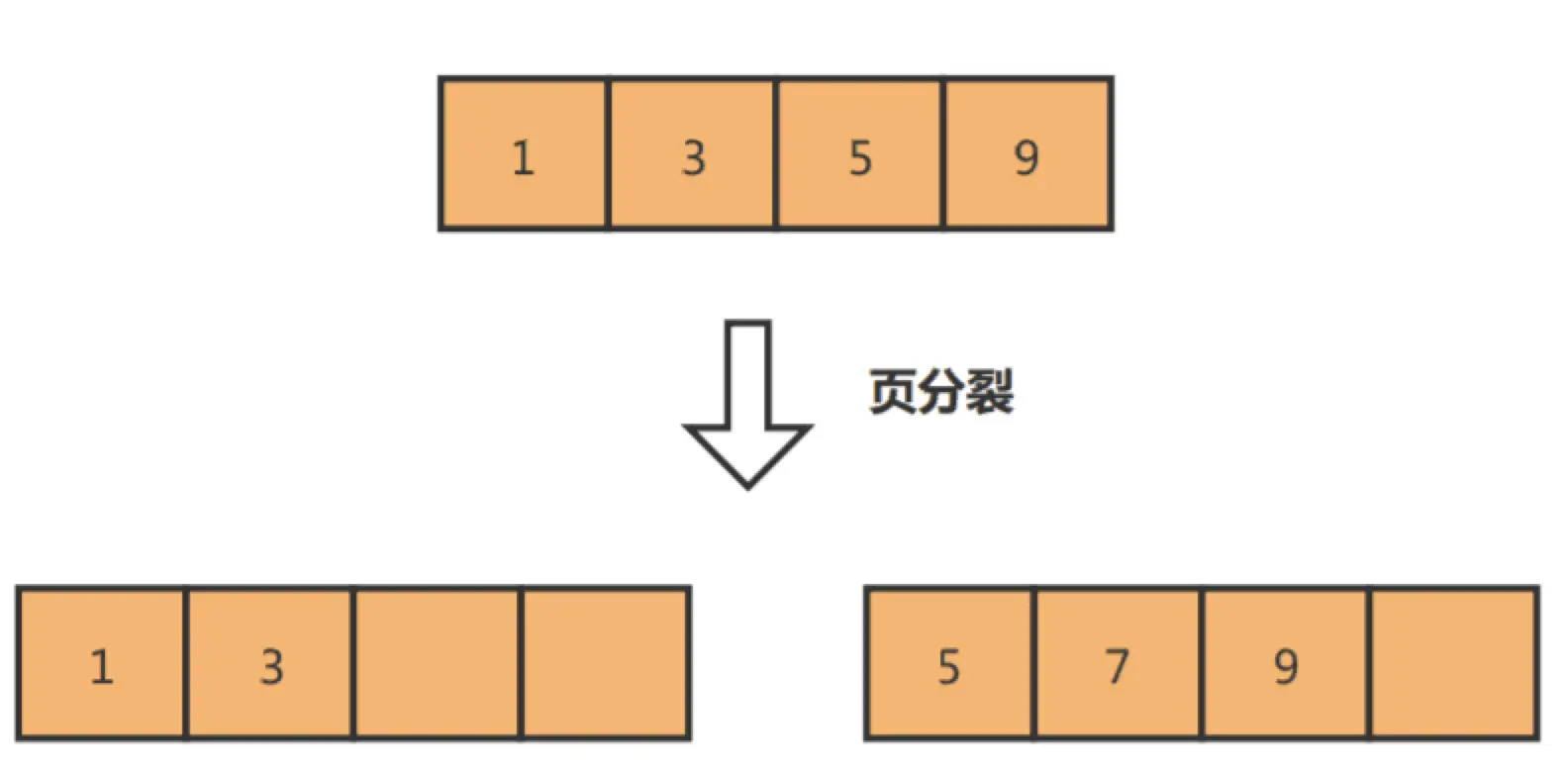
出现页分裂时,需要将一个页的记录移动到另外一个页,性能会受到影响,同时页空间的利用率下降,造成存储空间的浪费。
而如果记录是顺序插入的,例如插入数据11,则只需开辟新的数据页,也就不会发生页分裂:
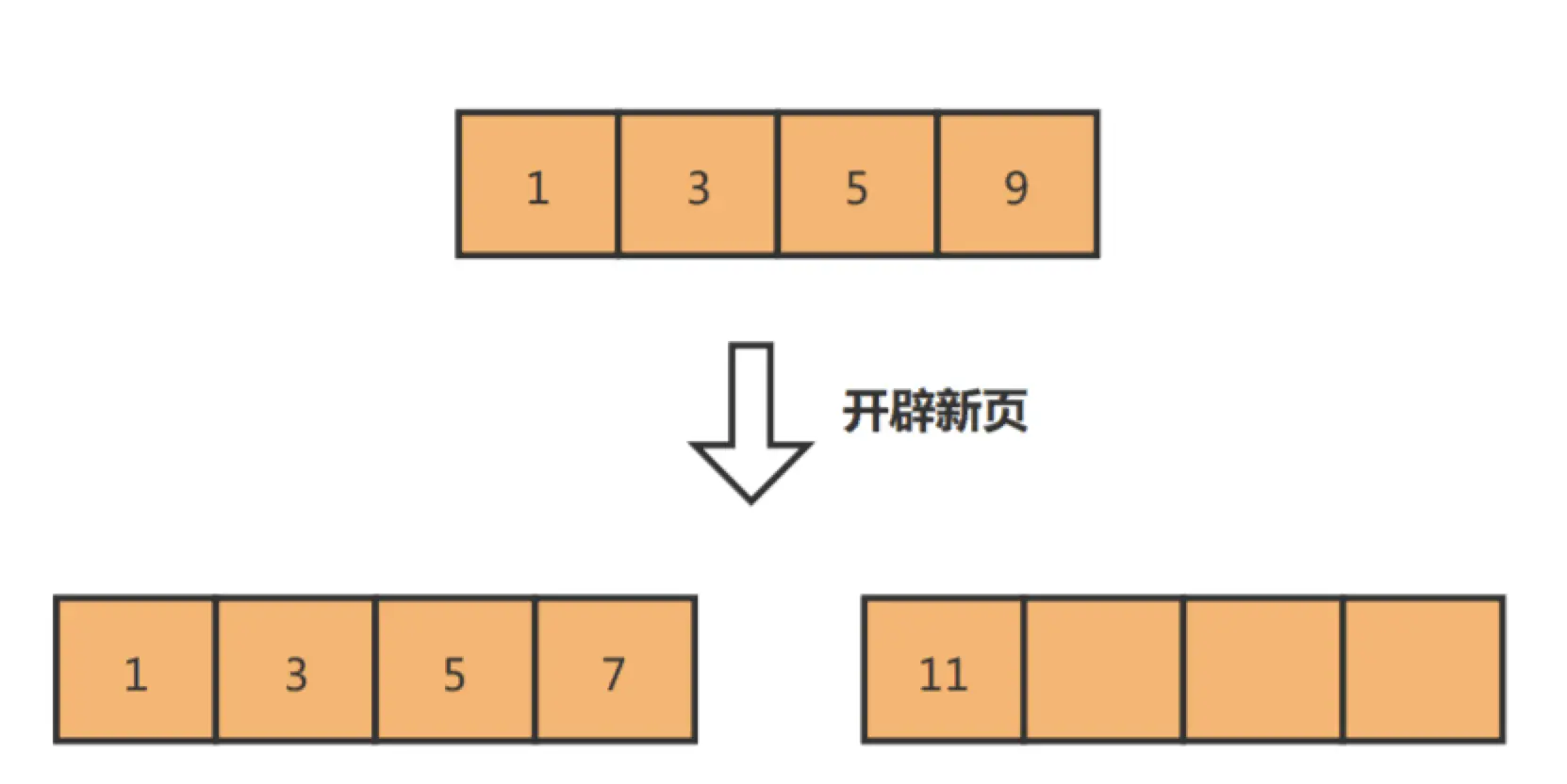
因此,在使用 InnoDB 存储引擎时,如果没有特别的业务需求,建议使用自增字段作为主键。
另外,主键字段的长度不要太大,因为主键字段长度越小,意味着二级索引的叶子节点越小(二级索引的叶子节点存放的数据是主键值),这样二级索引占用的空间也就越小。
a、所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
b、不可能在非叶子结点命中;
c、非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层。
1、如果我们定义了主键(PRIMARY KEY)
那么InnoDB会选择主键作为聚集索引、如果没有显式定义主键,则InnoDB会选择第一个不包含有NULL值的唯一索引作为主键索引、如果也没有这样的唯一索引,则InnoDB会选择内置6字节长的ROWID作为隐含的聚集索引(ROWID随着行记录的写入而主键递增,这个ROWID不像ORACLE的ROWID那样可引用,是隐含的)。
2、数据记录本身被存于主索引(一颗B+Tree)的叶子节点上
这就要求同一个叶子节点内(大小为一个内存页或磁盘页)的各条数据记录按主键顺序存放,因此每当有一条新的记录插入时,MySQL会根据其主键将其插入适当的节点和位置,如果页面达到装载因子(InnoDB默认为15/16),则开辟一个新的页(节点)
3、如果表使用自增主键
那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页
4、如果使用非自增主键(如果身份证号或学号等)
由于每次插入主键的值近似于随机,因此每次新纪录都要被插到现有索引页得中间某个位置,此时MySQL不得不为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销,同时频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE来重建表并优化填充页面。
总结:如果InnoDB表的数据写入顺序能和B+树索引的叶子节点顺序一致的话,这时候存取效率是最高的,也就是下面这几种情况的存取效率最高:
a、使用自增列(INT/BIGINT类型)做主键,这时候写入顺序是自增的,和B+数叶子节点分裂顺序一致;
b、该表不指定自增列做主键,同时也没有可以被选为主键的唯一索引(上面的条件),这时候InnoDB会选择内置的ROWID作为主键,写入顺序和ROWID增长顺序一致;
c、如果一个InnoDB表又没有显示主键,又有可以被选择为主键的唯一索引,但该唯一索引可能不是递增关系时(例如字符串、UUID、多字段联合唯一索引的情况),该表的存取效率就会比较差。





![P7230 [COCI2015-2016#3] NEKAMELEONI](https://img2024.cnblogs.com/blog/2790881/202409/2790881-20240909194630524-1953990165.png)