# 创建一个配置对象
options = webdriver.ChromeOptions()# 代理设置
options.add_argument('--proxy-server=http://221.131.165.71:27208')# 携带本地用户信息启动,注意:在使用的时候要将运行的谷歌浏览器全部关闭
# --user-data-dir 携带的谷歌的本地信息,默认路径
options.add_argument("--user-data-dir=C:/Users/Administrator/AppData/Local/Google/Chrome/User Data/")# 去除网站的一些自动化检测
# 此步骤很重要,设置为开发者模式,防止被各大网站识别出来使用了Selenium
options.add_experimental_option('excludeSwitches', ['enable-automation'])# 就是这一行告诉chrome去掉了webdriver痕迹,令navigator.webdriver=false,极其关键
options.add_argument("--disable-blink-features=AutomationControlled")# 修改为无界面模式
# 把chrome设置成无头模式,不论windows还是linux都可以,自动适配对应参数
options.set_headless()# 封禁图片提高访问速度
prefs = {"profile.managed_default_content_settings.images": 2}
options.add_experimental_option("prefs", prefs)
options.add_argument('--headless')
options.add_argument('--disable-gpu')# 实例化带有配置的driver对象
driver = webdriver.Chrome(options=options)# 正常的使用selenium.....# 优化等待页面
# selenium等待的三种方式:强制等待 隐式等待 显式等待driver.implicitly_wait(10) # 隐式等待
driver.get("https://www.baidu.com")# 自己动手写显式等待
def find_element_by_xpath(xpath):n = 0# 等待优化while n < 30:try:time.sleep(0.5)goods_list = driver.find_elements_by_xpath(xpath)if len(goods_list) < 需要的数据量,如果不到这个数据量就继续访问,如果到就返回数据:print("继续加载...")return goods_listexcept:print("节点还没有加载完成...")selenium相关配置
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.hqwc.cn/news/795044.html
如若内容造成侵权/违法违规/事实不符,请联系编程知识网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

易百纳ss928开发板移植自训练模型跑通yolov5算法
ss928平台移植官方yolov5s算法参考文章:https://www.ebaina.com/articles/140000017418,这位大佬也开源了代码,gitee链接:https://gitee.com/apchy_ll/ss928_yolov5s
本文在参考上述文章的基础上,将官方yolov5s模型跑通,验证推理图片正确,然后移植自训练的推理模型,在移…
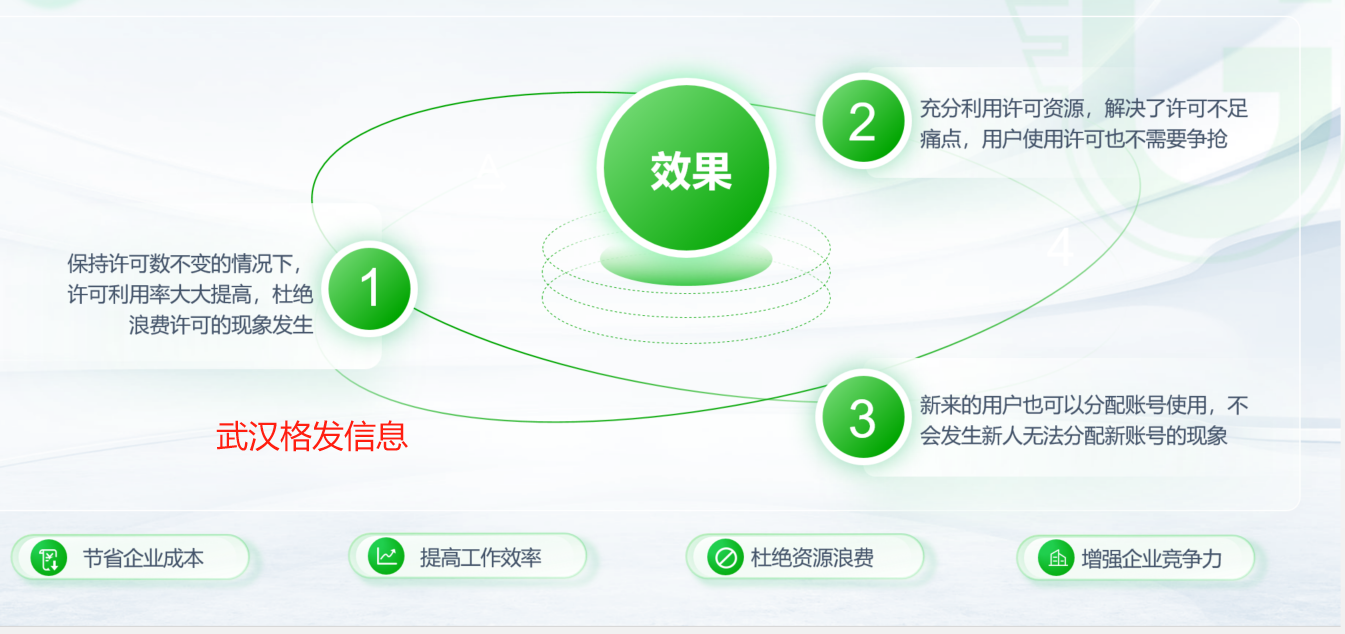
hyperworks软件许可优化解决方案
Hyperworks软件介绍
Altair 仿真驱动设计改变了产品开发,使工程师能够减少设计迭代和原型测试。提升科学计算能力扩大了应用分析的机会,使大型设计研究能够在限定的项目时间完成。现在,人工智能在工程领域的应用再次改变了产品开发。基于物理场的仿真驱动设计与机器学习相结…

Xcode 16 RC (16A242) 发布下载,正式版下周公布
Xcode 16 RC (16A242) 发布下载,正式版下周公布Xcode 16 RC (16A242) - Apple 平台 IDE
IDE for iOS/iPadOS/macOS/watchOS/tvOS/visonOS
请访问原文链接:https://sysin.org/blog/apple-xcode-16/,查看最新版。原创作品,转载请保留出处。
作者主页:sysin.orgXcode 16 的新…

JAVA+VUE实现动态表单配置
功能描述:
资产管理系统中,在资产分类中,给同一种类型的资产配置定制化的表单项,并实现不同类型显示不同的数据,如图所示:数据库设计部分:
1.表单项表CREATE TABLE `dct_smp`.`t_asset_product_definitions` (`id` bigint NOT NULL,`product_id` bigint NOT NULL COMMEN…
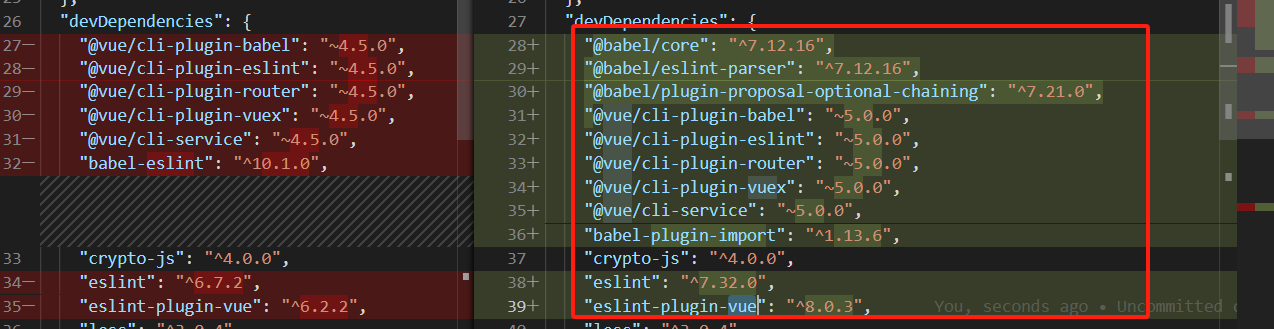
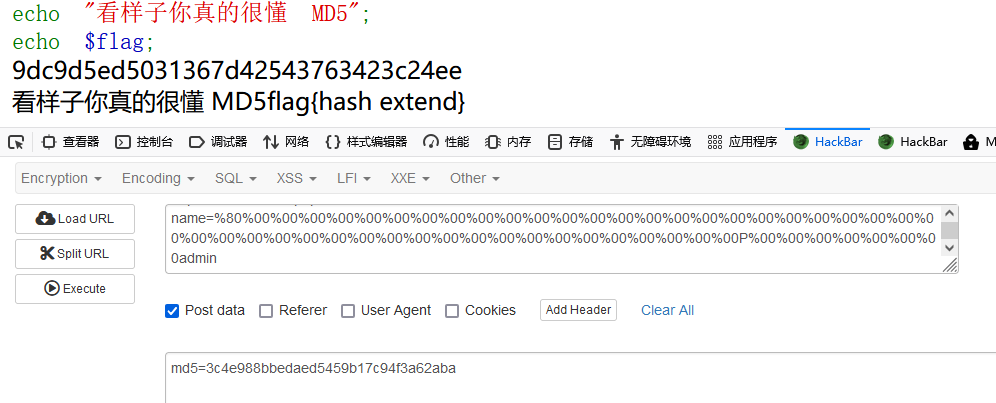
vue 可选链操作符(?.)报错
一直用的好好的这个运算符,换了个项目,用不了了
首先交代一下,vue版本是2.6.11,node版本是v14.17.4 ,vue-template-compiler也是2.6.11
首先哈,我们升级一下vue到2.7.xx版本npm i vue@2.7.0 vue-template-compiler@2.7.0然后安装这个插件npm install @babel/plugin-propo…

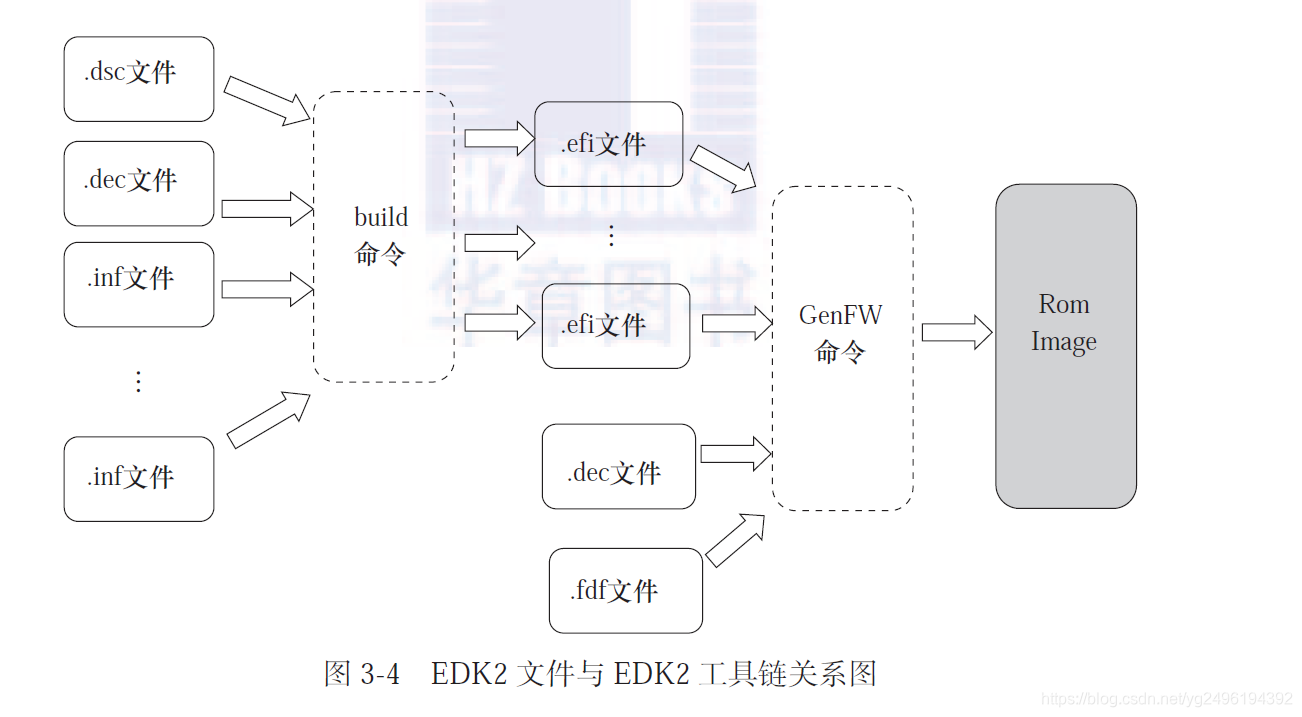
UEFI原理与编程(一)
第一章 UEFI概述(Unified Extensible Firmware Interface 统一的可扩展固件接口)
常见缩写及描述:缩略词
全名
描述UEFI
Unified Extensible Firmware Interface
统一的可扩展固件接口BS
Boot Services
启动服务RT
Runtime Service
运行时服务BIOS
Basic Input Output System
…

SparkSQL练习:对学生选课成绩进行分析计算
题目内容:
对学生选课成绩进行分析计算题目要求:
(1)该系总共有多少学生;
(2)该系共开设来多少门课程;
(3)每个学生的总成绩多少;
(4)每门课程选修的同学人数;
(5)每位同学选修的课程门数;
(6)该系DataBase课程共有多少人选修;
(7)每位同学平均成绩;数据…
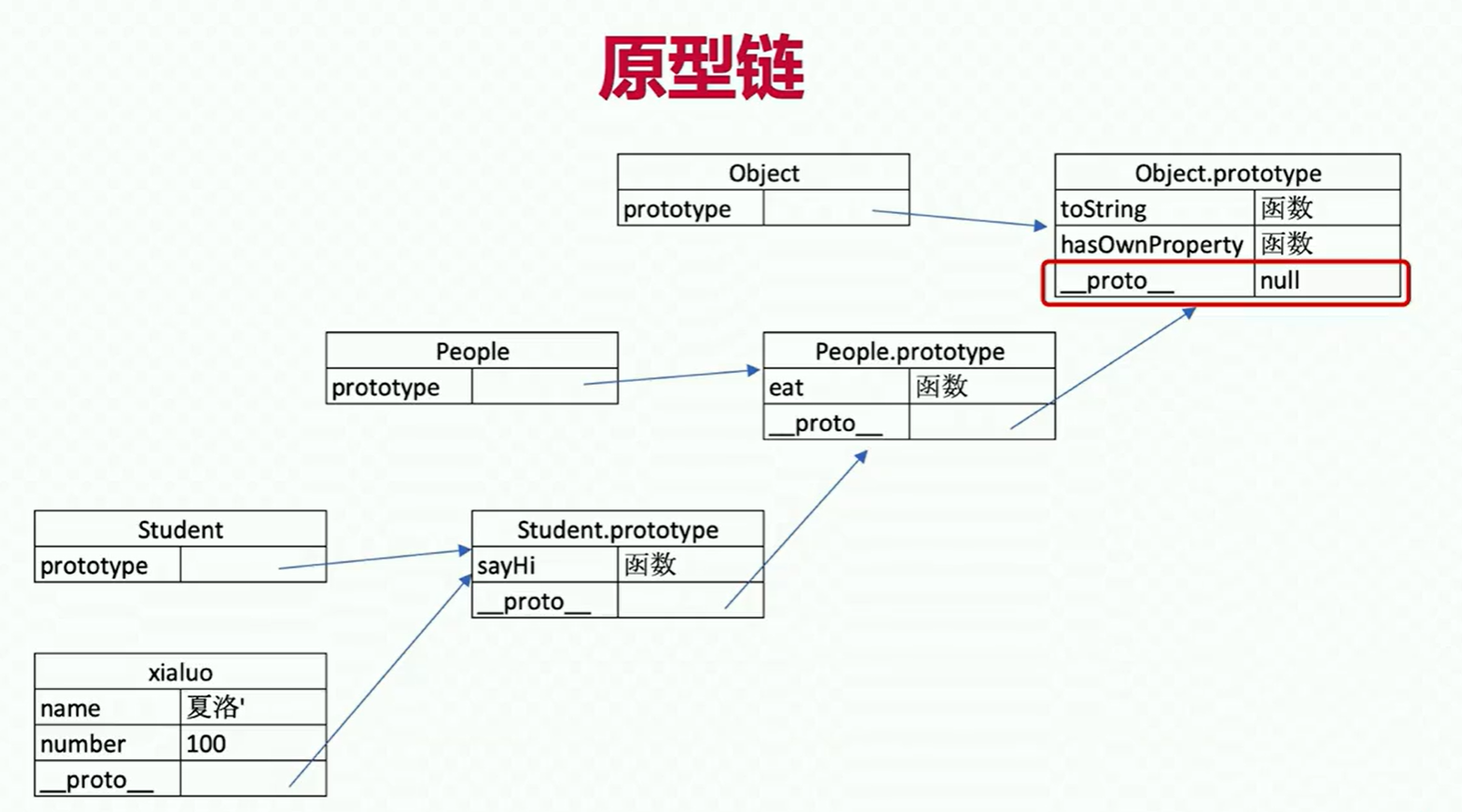
面试-JS基础知识-原型和原型链
JS本身是基于原型来继承的语言。
问题引出:如何判断一个变量是不是数组?
手写一个简易的jQuery,考虑插件和扩展性
class的原型本质,怎么理解?知识点class和继承
类型判断 instanceof
原型和原型链class
class相当于一个模版,可以用来构建(constructor)东西。
class Stu…
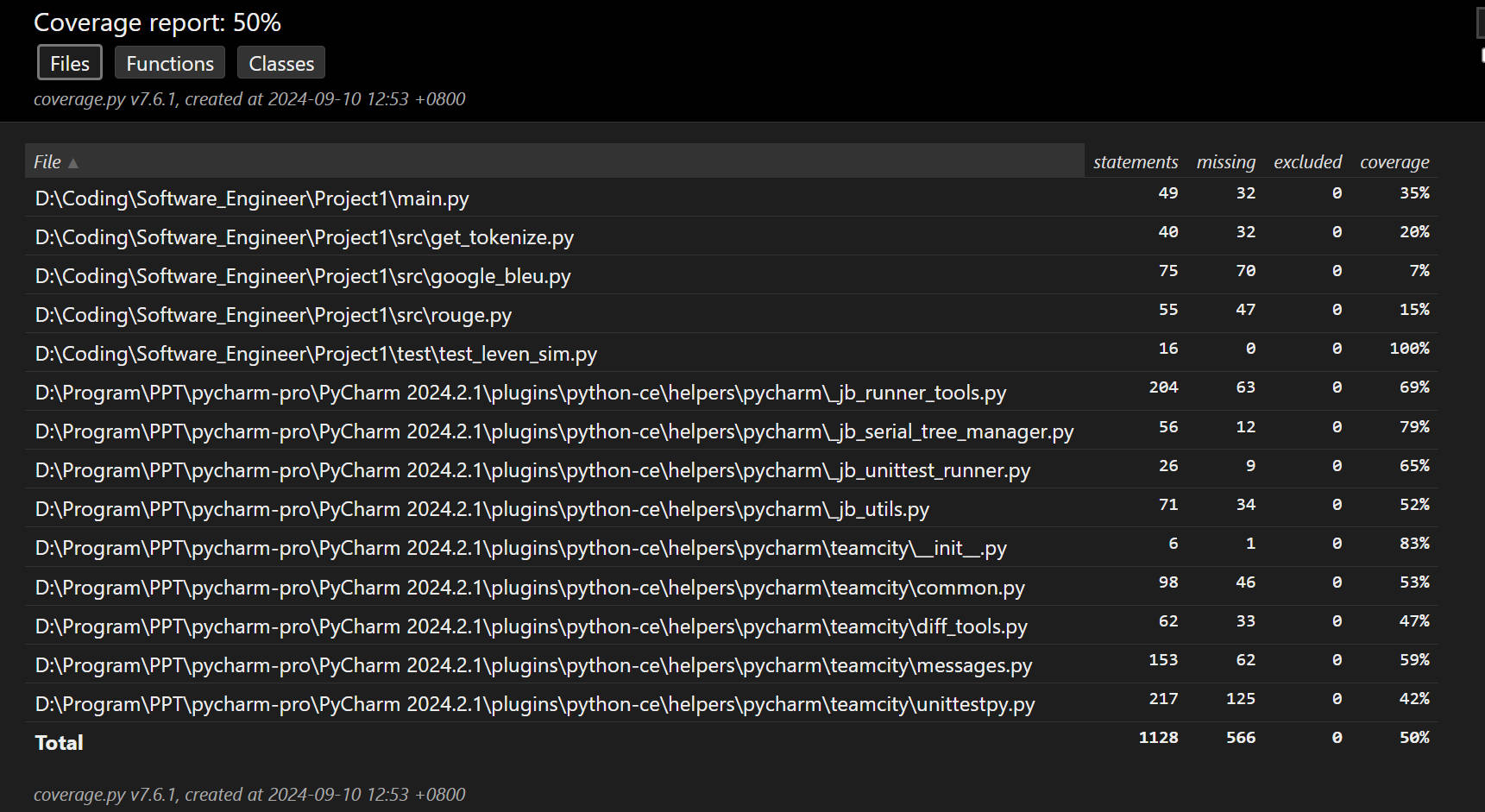
作业9.2:论文查重
这个作业属于哪个课程
班级链接这个作业要求在哪里
作业要求链接这个作业的目标
设计论文查重算法;学会 Git 版本控制。Github 链接:博客正文首行 github 链接
目录一、整体设计开发环境整体设计项目结构二、模块接口的设计与实现核心的类与方法类与函数的调用关系核心算法三…

搭建企业内部的大语言模型系统
大纲开源大语言模型
大语言模型管理
私有大语言模型服务部署方案开源大语言模型
担心安全与隐私?可私有部署的开源大模型商业大模型,不支持私有部署ChatGPT
Claude
Google Gemini
百度问心一言开源大模型,支持私有部署Mistral
Meta Llama
ChatGLM
阿里通义千问常用开源大模型…