| 这个作业属于哪个课程 | 计科22级34班 |
|---|---|
| 这个作业要求在哪里 | 个人项目 |
| 这个作业的目标 | 1.设计一个查重算法。 2. 了解并学习项目的PSP表格 3. 学习如何运用github进行代码管理 4. 学习使用性能分析工具,分析代码性能 5. 学习如何进行单元测试 |
我的github仓库链接:https://github.com/zfirejs/3122004631
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 20 | 30 |
| Development | 开发 | 900 | 990 |
| · Analysis | · 需求分析 (包括学习新技术) | 280 | 310 |
| · Design Spec | · 生成设计文档 | 30 | 30 |
| · Design Review | · 设计复审 | 50 | 55 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 25 |
| · Design | · 具体设计 | 70 | 75 |
| · Coding | · 具体编码 | 350 | 365 |
| · Code Review | · 代码复审 | 40 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 80 |
| Reporting | 报告 | 85 | 90 |
| · Test Repor | · 测试报告 | 60 | 50 |
| · Size Measurement | · 计算工作量 | 15 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 20 |
| · 合计 | 1005 | 1110 |
计算模块接口设计与实现过程
过程描述:
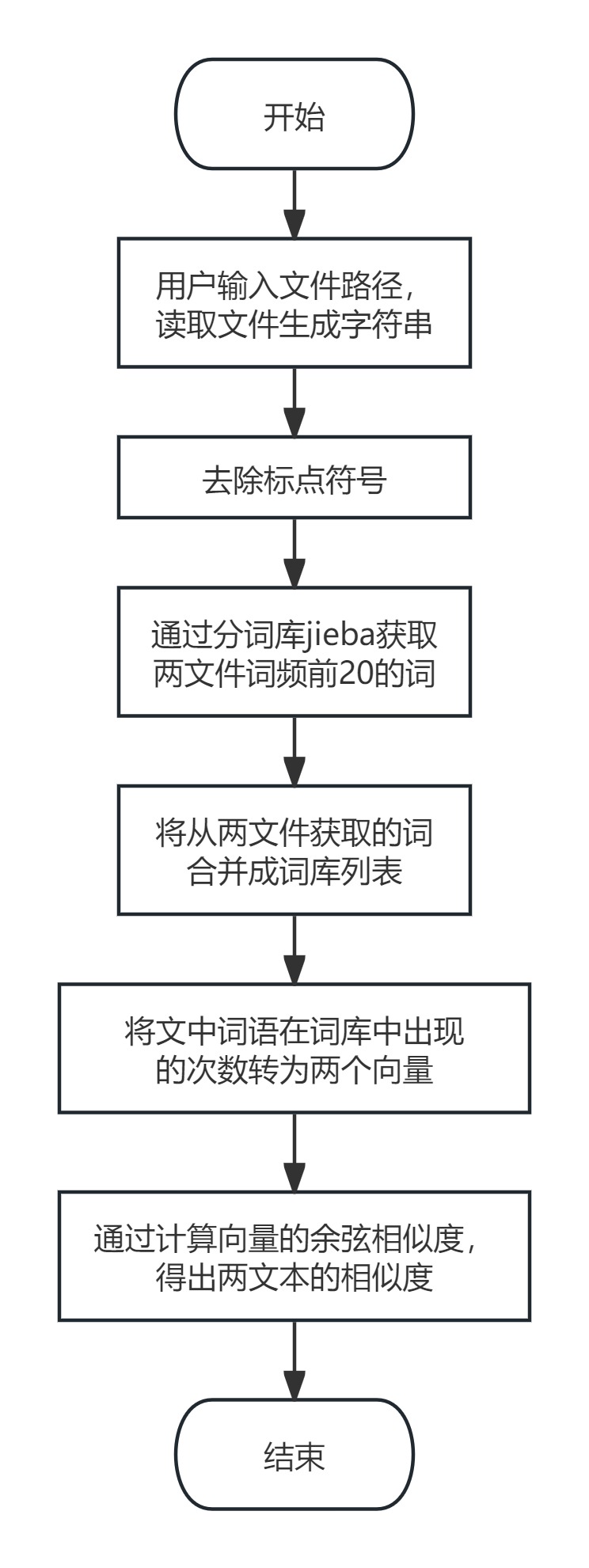
代码实现了一个基于文本相似度的查重功能,用于比较两篇中文文本的相似度,并将相似度结果输出到文件中。程序中使用了jieba库进行中文分词处理,再利用余弦相似度计算两篇文本的相似程度。
代码组成:
代码中只有一个类:DuplicateChecking
该类包含以下几个函数:
1.init:类的构造函数,初始化类变量,用于保存原始文本和待查重文本的内容及分词列表。
2.read_file:读取原始文件和待查重文件的内容,并将其保存为类变量 original_text 和 compare_text。。
3.long_text_preprocess:文本的预处理函数,去除标点符号后使用 jieba.analyse.extract_tags 提取文本中的关键词(20 个),并将关键词存储在 original_list 和 compare_list 中。
4.text_checking:核心查重函数,分别调用文件读取(read_file)、文本预处理(long_text_preprocess),然后构建词频向量并计算余弦相似度。最后输出相似度结果到指定文件。
算法核心
将文本去除标点符号后使用,提取文本中的关键词(20 个),然后构建词频向量并计算余弦相似度,从而得出文本相似度。
流程图
计算模块接口部分的性能改进
改进思路
本程序的计算模块的主要性能瓶颈为文本的输入,其中短文本可以使用python文件IO类的read()方法,但是对于较长文本的输入,则需要使用readlines()方法实现逐行输入,避免因内存容量导致的IO速率过慢
改进部分代码
try:with open(original_text_address, "r", encoding="utf-8") as file1:self.original_list = file1.readlines()# 将读取的行拼接成单个字符串存储self.original_text = self.original_text.join(self.original_list)
except FileNotFoundError:print("未找到原始文本文件 " + original_text_address + " 请重试")original_text_address = ""
性能分析图
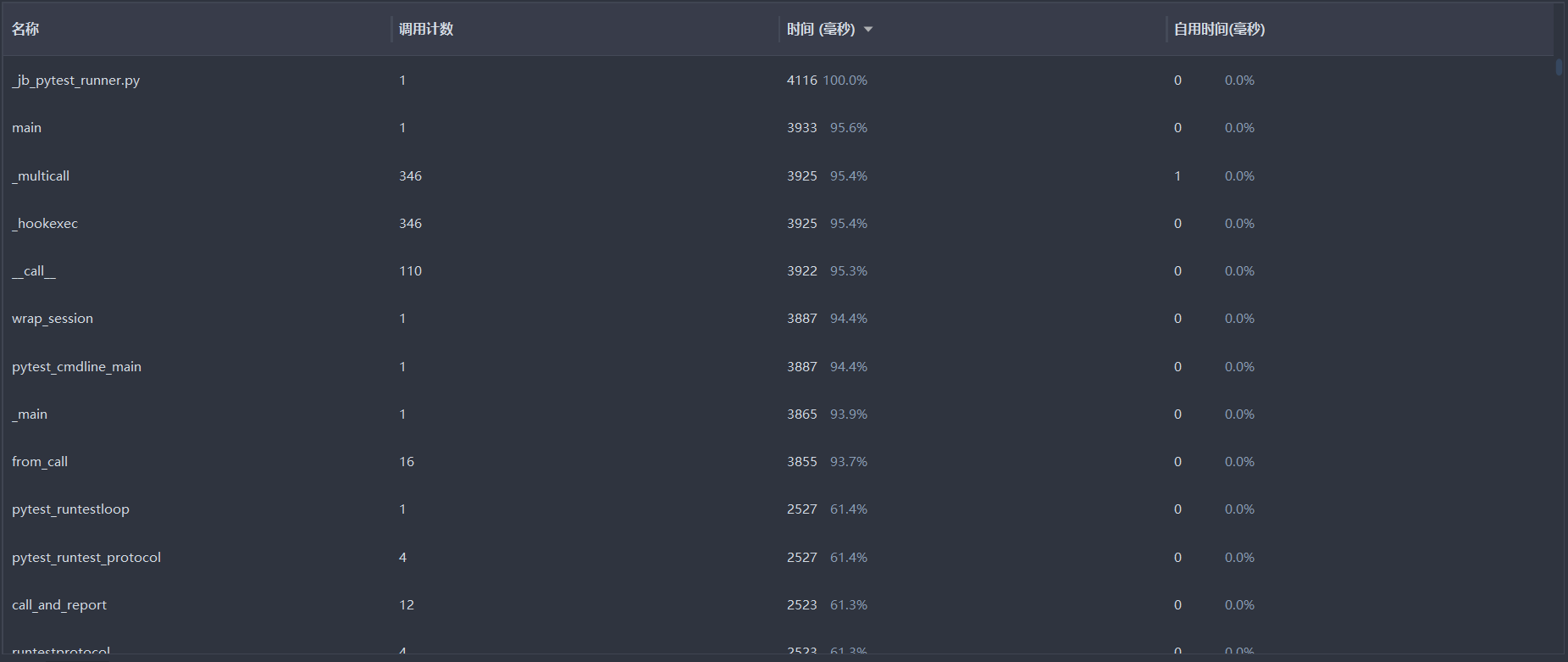
消耗最大的函数(text_checking)
def text_checking(self):"""主功能方法,负责根据文本长度选择适合的预处理方法。长文本(超过1000字符)会调用 `long_text_preprocess` 方法,短文本会调用 `short_text_preprocess` 方法。最终使用余弦相似度计算两个文本之间的相似度。"""original_vector = []compare_vector = []# 读取文件,检查读取是否成功if not self.read_file():return False# 根据文本长度判断选择预处理方法,超过1000字符的文本被视为长文本if len(self.original_text) > 1000 or len(self.compare_text) > 1000:self.long_text_preprocess()else:self.short_text_preprocess()# 合并分词列表并去重,创建词汇表self.word_store = list(set(self.original_list + self.compare_list))# 构建词频向量for word in self.word_store:original_vector.append(self.original_list.count(word))compare_vector.append(self.compare_list.count(word))original_vector = numpy.array(original_vector)compare_vector = numpy.array(compare_vector)# 使用 scipy 库的余弦相似度函数计算相似度cos_sim = 1 - spatial.distance.cosine(original_vector, compare_vector)# 将相似度写入文件并提示用户print("请输入查重结果文件输出的地址:")duplicate_data_address = input("请输入抄袭文本的绝对路径")#"C:\\Users\\周晨佳\\Desktop\\ceshi\\shuchu.txt"try:with open(duplicate_data_address, "w", encoding="utf-8") as file:file.write("待查文本与原文本的相似度为:" + str(round(cos_sim, 2)))print("查重结果已输出到文件!")except IOError:print("查重结果文件创建失败,请检查路径并重试。")return True计算模块部分单元测试展示:
测试思路
单元测试使用pycharm自带的unittest测试框架,运用unittest框架的TestCase类,在类中实例化测试函数,运行测试python文件,实现main程序的测试。
对于项目中的输入模块,引入unittest测试框架中的patch类模拟用户的输入,实现输入模块的测试。
单元测试通过模拟用户的行为,以及对于main.py中DuplicateChecking查重类中的每个函数运行流程进行模拟,使用框架自带的断言函数assertEqual(),实现对项目中的类及其方法的测试。
测试代码(test.py)
import unittest
import random
from src.main import DuplicateChecking
from unittest.mock import patch # 用于模拟输入
# 记录测试文本地址
original_text = [r'C:\Users\周晨佳\Desktop\ceshi\orig.txt', '666', '777','888', '999']
test_text = [r'C:\Users\周晨佳\Desktop\ceshi\orig_0.8_add.txt',r'C:\Users\周晨佳\Desktop\ceshi\orig_0.8_del.txt',r'C:\Users\周晨佳\Desktop\ceshi\orig_0.8_dis_1.txt',r'C:\Users\周晨佳\Desktop\ceshi\orig_0.8_dis_10.txt',r'C:\Users\周晨佳\Desktop\ceshi\orig_0.8_dis_15.txt','666', '777', '888', '999']class MyTestCase(unittest.TestCase):@patch('builtins.input')def test_IO(self, mock_input):result = DuplicateChecking()# 实例化测试对象mock_input.side_effect = [original_text[0], test_text[random.randint(0, 4)]] # 正确的输入self.assertEqual(result.read_file(), True)# 断言测试判断mock_input.side_effect = [original_text[random.randint(1, 4)], test_text[random.randint(5, 8)]] # 错误的输入self.assertEqual(result.read_file(), False)@patch('builtins.input')def test_long_text_preprocess(self, mock_input):result = DuplicateChecking()mock_input.side_effect = [original_text[0], test_text[random.randint(0, 4)]] # 正确的输入result.read_file()self.assertEqual(result.long_text_preprocess(), True)def test_short_text_preprocess(self):result = DuplicateChecking()result.original_text = "废话覅哦说不定v哦i被释冯绍峰放北京库房不玩"result.compare_text = "我IC呢嫩IC那我可浪放放瑟夫费钱农村"self.assertEqual(result.short_text_preprocess(), True)@patch('builtins.input')def test_text_checking(self, mock_input):result = DuplicateChecking()mock_input.side_effect = [original_text[0], test_text[random.randint(0, 4)],r'C:\Users\周晨佳\Desktop\ceshi\output.txt'] # 正确的输入self.assertEqual(result.text_checking(), True)mock_input.side_effect = [original_text[random.randint(1, 4)], test_text[random.randint(5, 8)],r'C:\Users\周晨佳\Desktop\ceshi\output.txt'] # 错误的输入self.assertEqual(result.text_checking(), False)if __name__ == '__main__':unittest.main()
测试覆盖率:

计算模块部分异常处理说明
1.输入异常(文件不存在):
try:with open(original_text_address, "r", encoding="utf-8") as file1:self.original_list = file1.readlines()# 将读取的行拼接成单个字符串存储self.original_text = self.original_text.join(self.original_list)
except FileNotFoundError:print("未找到原始文本文件 " + original_text_address + " 请重试")original_text_address = ""
输入异常对应的单元测试
@patch('builtins.input')
def test_IO(self, mock_input):result = DuplicateChecking()# 实例化测试对象mock_input.side_effect = [original_text[0], test_text[random.randint(0, 4)]] # 正确的输入self.assertEqual(result.read_file(), True)# 断言测试判断mock_input.side_effect = [original_text[random.randint(1, 4)], test_text[random.randint(5, 8)]] # 错误的输入self.assertEqual(result.read_file(), False)
2.输出异常(文件不存在):
try:with open(duplicate_data_address, "w", encoding="utf-8") as file:file.write("待查文本与原文本的相似度为:" + str(round(cos_sim, 2)))print("查重结果已输出到文件!")
except IOError:print("查重结果文件创建失败,请检查路径并重试。")
输出异常对应的单元测试
@patch('builtins.input')
def test_text_checking(self, mock_input):result = DuplicateChecking()mock_input.side_effect = [original_text[0], test_text[random.randint(0, 4)],r'C:\Users\周晨佳\Desktop\ceshi\output.txt'] # 正确的输入self.assertEqual(result.text_checking(), True)mock_input.side_effect = [original_text[random.randint(1, 4)], test_text[random.randint(5, 8)],r'C:\Users\周晨佳\Desktop\ceshi\output.txt'] # 错误的输入self.assertEqual(result.text_checking(), False)
心得
本次作业使用到了一些专业的关于测试项目的工具,让我学会了如何进行代码覆盖率的测试。最大的收获就是学习了如何进行项目的单元测试,学会了如何编写测试代码,怎么样才能尽可能提高代码覆盖率。总的来说,这次作业让我对软件工程中的测试有了更深的理解,让我受益匪浅。