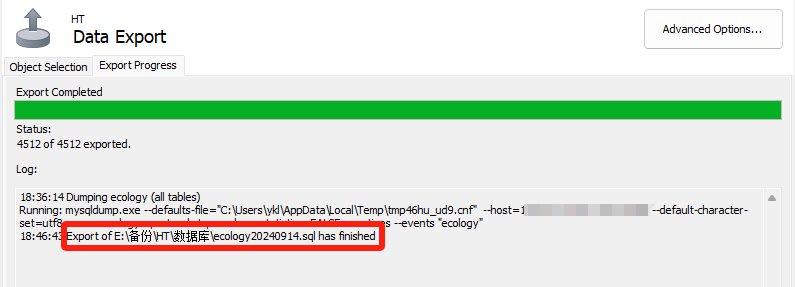
Linkedin SRE 中文教程(二)
原文:School of SRE
协议:CC BY-NC-SA 4.0
一些 Python 概念
原文:https://linkedin.github.io/school-of-sre/level101/python_web/python-concepts/
虽然期望您了解 python 及其基本语法,但是让我们讨论一些基本概念,这将帮助您更好地理解 python 语言。
Python 中的一切都是对象。
这包括函数、列表、字典、类、模块、运行函数(函数定义的实例),一切。在 CPython 中,这意味着每个对象都有一个底层结构变量。
在 python 当前的执行上下文中,所有变量都存储在一个 dict 中。这将是一个字符串到对象的映射。如果您在当前上下文中定义了一个函数和一个浮点变量,下面是它在内部的处理方式。
>>> float_number=42.0
>>> def foo_func():
... pass
...# NOTICE HOW VARIABLE NAMES ARE STRINGS, stored in a dict
>>> locals()
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, 'float_number': 42.0, 'foo_func': <function foo_func at 0x1055847a0>}
Python 函数
因为函数也是对象,我们可以看到函数包含的所有属性如下
>>> def hello(name):
... print(f"Hello, {name}!")
...
>>> dir(hello)
['__annotations__', '__call__', '__class__', '__closure__', '__code__', '__defaults__', '__delattr__', '__dict__',
'__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__get__', '__getattribute__', '__globals__', '__gt__',
'__hash__', '__init__', '__init_subclass__', '__kwdefaults__', '__le__', '__lt__', '__module__', '__name__',
'__ne__', '__new__', '__qualname__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__',
'__subclasshook__']
虽然有很多,让我们来看看一些有趣的
globals
顾名思义,这个属性引用了全局变量。如果你需要知道在这个函数的范围内所有的全局变量是什么,这将告诉你。看看函数是如何在全局变量中发现新变量的
>>> hello.__globals__
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, 'hello': <function hello at 0x7fe4e82554c0>}# adding new global variable
>>> GLOBAL="g_val"
>>> hello.__globals__
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, 'hello': <function hello at 0x7fe4e82554c0>, 'GLOBAL': 'g_val'}
代码
这个很有意思!因为 python 中的一切都是对象,这也包括字节码。编译后的 python 字节码是一个 python 代码对象。这可以通过这里的__code__属性访问。一个函数有一个相关的代码对象,它携带一些有趣的信息。
# the file in which function is defined
# stdin here since this is run in an interpreter
>>> hello.__code__.co_filename
'<stdin>'# number of arguments the function takes
>>> hello.__code__.co_argcount
1# local variable names
>>> hello.__code__.co_varnames
('name',)# the function code's compiled bytecode
>>> hello.__code__.co_code
b't\x00d\x01|\x00\x9b\x00d\x02\x9d\x03\x83\x01\x01\x00d\x00S\x00'
您可以通过>>> dir(hello.__code__)登记更多的代码属性
装修工
与函数相关,python 还有一个特性叫做 decorators。让我们看看这是如何工作的,记住everything is an object。
下面是一个装饰示例:
>>> def deco(func):
... def inner():
... print("before")
... func()
... print("after")
... return inner
...
>>> @deco
... def hello_world():
... print("hello world")
...
>>>
>>> hello_world()
before
hello world
after
这里使用了@deco语法来修饰hello_world函数。本质上和做是一样的
>>> def hello_world():
... print("hello world")
...
>>> hello_world = deco(hello_world)
deco函数内部的内容可能看起来很复杂。让我们试着揭开它。
- 功能
hello_world已创建 - 它被传递给
deco功能 deco创建新功能- 这个新功能就是调用
hello_world功能 - 还做了一些其他的事情
- 这个新功能就是调用
deco返回新创建的函数hello_world替换为上述功能
为了更好的理解,让我们把它形象化
BEFORE function_object (ID: 100)"hello_world" +--------------------++ |print("hello_world")|| | |+--------------> | || |+--------------------+WHAT DECORATOR DOEScreates a new function (ID: 101)+---------------------------------+|input arg: function with id: 100 || ||print("before") ||call function object with id 100 ||print("after") || |+---------------------------------+^|AFTER |||"hello_world" +-------------+
注意hello_world名称是如何指向一个新的函数对象的,但是这个新的函数对象知道原始函数的引用(ID)。
一些问题
- 虽然用 python 构建原型非常快,并且有大量可用的库,但是随着代码库复杂性的增加,类型错误变得更加常见,并且变得难以处理。(这个问题有解决方案,比如 python 中的类型注释。结帐 mypy 。)
- 因为 python 是动态类型语言,这意味着所有类型都是在运行时确定的。这使得 python 与其他静态类型语言相比运行速度非常慢。
- Python 有一种叫做 GIL (全局解释器锁)的东西,这是利用多个 CPU 内核进行并行计算的一个限制因素。
- python 做的一些奇怪的事情:https://github.com/satwikkansal/wtfpython
Python、Web 和 Flask
原文:https://linkedin.github.io/school-of-sre/level101/python_web/python-web-flask/
过去,网站很简单。它们是简单的静态 html 内容。一个 web 服务器将监听一个定义的端口,根据收到的 HTTP 请求,它将从磁盘读取文件并返回它们作为响应。但从那以后,复杂性发生了变化,网站现在是动态的。根据请求的不同,需要执行多个操作,比如从数据库读取数据或调用其他 API,最后返回一些响应(HTML 数据、JSON 内容等。)
由于服务 web 请求不再是像从磁盘读取文件并返回内容那样简单的任务,我们需要处理每个 http 请求,以编程方式执行一些操作并构造一个响应。
套接字
尽管我们有 flask 这样的框架,HTTP 仍然是一个基于 TCP 协议的协议。因此,让我们设置一个 TCP 服务器,发送一个 HTTP 请求,并检查请求的有效负载。请注意,这不是一个关于套接字编程的教程,但我们在这里所做的是在底层检查 HTTP 协议,看看它的内容是什么样子的。(Ref:real Python 上的 Python 套接字编程(指南)
import socketHOST = '127.0.0.1' # Standard loopback interface address (localhost)
PORT = 65432 # Port to listen on (non-privileged ports are > 1023)with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:s.bind((HOST, PORT))s.listen()conn, addr = s.accept()with conn:print('Connected by', addr)while True:data = conn.recv(1024)if not data:breakprint(data)
然后,我们在网络浏览器中打开localhost:65432,输出如下:
Connected by ('127.0.0.1', 54719)
b'GET / HTTP/1.1\r\nHost: localhost:65432\r\nConnection: keep-alive\r\nDNT: 1\r\nUpgrade-Insecure-Requests: 1\r\nUser-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36 Edg/85.0.564.44\r\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9\r\nSec-Fetch-Site: none\r\nSec-Fetch-Mode: navigate\r\nSec-Fetch-User: ?1\r\nSec-Fetch-Dest: document\r\nAccept-Encoding: gzip, deflate, br\r\nAccept-Language: en-US,en;q=0.9\r\n\r\n'
仔细检查,内容看起来会像 HTTP 协议的格式。即:
HTTP_METHOD URI_PATH HTTP_VERSION
HEADERS_SEPARATED_BY_SEPARATOR
因此,尽管它是一个字节块,知道 http 协议规范,你可以解析这个字符串(即:被\r\n分割)并从中获得有意义的信息。
瓶
Flask 和其他类似的框架做的和我们在上一节讨论的差不多(增加了更多的复杂性)。它们监听 TCP 套接字上的端口,接收 HTTP 请求,根据协议格式解析数据,并以方便的方式提供给你。
ie:你可以通过request.headers访问 flask 中的头,通过/r/n分割上面的有效载荷,就可以得到这个头,正如 http 协议中定义的。
另一个例子:我们通过@app.route("/hello")在 flask 中注册路径。flask 要做的是在内部维护一个注册表,它将把/hello映射到你所修饰的函数。现在,每当一个请求通过/hello路径(第一行的第二个组件,由空格分隔)到来时,flask 调用注册的函数并返回函数返回的任何内容。
其他语言的所有其他 web 框架也是如此。它们都基于相似的原理工作。他们主要做的是理解 HTTP 协议,解析 HTTP 请求数据,给我们程序员一个很好的接口来处理 HTTP 请求。
没有那么多魔法,不是吗?
短网址应用
原文:https://linkedin.github.io/school-of-sre/level101/python_web/url-shorten-app/
让我们使用 flask 构建一个非常简单的 URL 缩短应用,并尝试整合开发过程的所有方面,包括可靠性方面。我们将不会建立用户界面,我们将拿出一个最小的 API 集,这将足以让应用运行良好。
设计
我们不直接跳到编码。我们做的第一件事是收集需求。想出一个办法。让同行评审方法/设计。演进、迭代、记录决策和权衡。然后最终实现。虽然我们不会在这里完成完整的设计文档,但我们会在这里提出一些对设计很重要的问题。
1.高级操作和 API 端点
由于这是一个 URL 缩短应用,我们将需要一个 API 来生成缩短链接给定一个原始链接。以及接受缩短链接并重定向到原始 URL 的 API/端点。我们不包括应用的用户方面,以保持事情最少。这两个 API 应该使任何人都可以使用应用。
2.怎么缩短?
给定一个 url,我们将需要生成它的一个缩短版本。一种方法是为每个链接使用随机字符。另一件可以做的事情是使用某种散列算法。这里的好处是,我们将对相同的链接重用相同的散列。例如:如果很多人都在缩短https://www.linkedin.com,那么他们都将有相同的值,相比之下,如果选择随机字符,数据库中会有多个条目。
哈希冲突怎么办?即使在随机字符方法中,尽管概率较小,哈希冲突也可能发生。我们需要留意它们。在这种情况下,我们可能希望在字符串前/后添加一些随机值以避免冲突。
此外,哈希算法的选择也很重要。我们需要分析算法。它们的 CPU 需求和特性。选一个最适合的。
3.URL 有效吗?
给定一个要缩短的 URL,我们如何验证该 URL 是否有效?我们甚至验证或确认了吗?可以完成的一个基本检查是查看 URL 是否匹配 URL 的正则表达式。为了更进一步,我们可以尝试打开/访问网址。但是这里有一些问题。
- 我们需要定义成功的标准。即:HTTP 200 表示有效。
- 私有网络中的 URL 是什么?
- URL 暂时宕机怎么办?
4.储存;储备
最后是存储。随着时间的推移,我们将在哪里存储我们将生成的数据?有多种数据库解决方案可供选择,我们需要选择最适合该应用的解决方案。像 MySQL 这样的关系数据库将是一个公平的选择,但一定要检查 SRE 学院的 SQL 数据库部分和 NoSQL 数据库部分,以获得更深入的见解,做出更明智的决定。
5.其他的
我们不考虑用户进入我们的应用和其他可能的功能,如速率限制,自定义链接等,但它最终会随着时间的推移。根据需求,它们也可能需要被合并。
下面给出了最少的工作代码供参考,但我鼓励你提出自己的代码。
from flask import Flask, redirect, requestfrom hashlib import md5app = Flask("url_shortener")mapping = {}@app.route("/shorten", methods=["POST"])
def shorten():global mappingpayload = request.jsonif "url" not in payload:return "Missing URL Parameter", 400# TODO: check if URL is validhash_ = md5()hash_.update(payload["url"].encode())digest = hash_.hexdigest()[:5] # limiting to 5 chars. Less the limit more the chances of collissionif digest not in mapping:mapping[digest] = payload["url"]return f"Shortened: r/{digest}\n"else:# TODO: check for hash collissionreturn f"Already exists: r/{digest}\n"@app.route("/r/<hash_>")
def redirect_(hash_):if hash_ not in mapping:return "URL Not Found", 404return redirect(mapping[hash_])if __name__ == "__main__":app.run(debug=True)"""
OUTPUT:===> SHORTENING$ curl localhost:5000/shorten -H "content-type: application/json" --data '{"url":"https://linkedin.com"}'
Shortened: r/a62a4===> REDIRECTING, notice the response code 302 and the location header$ curl localhost:5000/r/a62a4 -v
* Uses proxy env variable NO_PROXY == '127.0.0.1'
* Trying ::1...
* TCP_NODELAY set
* Connection failed
* connect to ::1 port 5000 failed: Connection refused
* Trying 127.0.0.1...
* TCP_NODELAY set
* Connected to localhost (127.0.0.1) port 5000 (#0)
> GET /r/a62a4 HTTP/1.1
> Host: localhost:5000
> User-Agent: curl/7.64.1
> Accept: */*
>
* HTTP 1.0, assume close after body
< HTTP/1.0 302 FOUND
< Content-Type: text/html; charset=utf-8
< Content-Length: 247
< Location: https://linkedin.com
< Server: Werkzeug/0.15.4 Python/3.7.7
< Date: Tue, 27 Oct 2020 09:37:12 GMT
<
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN">
<title>Redirecting...</title>
<h1>Redirecting...</h1>
* Closing connection 0
<p>You should be redirected automatically to target URL: <a href="https://linkedin.com">https://linkedin.com</a>. If not click the link.
"""
总结
原文:https://linkedin.github.io/school-of-sre/level101/python_web/sre-conclusion/
扩展应用
设计和开发只是旅程的一部分。我们迟早需要建立持续集成和持续交付管道。我们必须在某个地方部署这个应用。
最初,我们可以在任何云提供商的一台虚拟机上部署这款应用。但这是一个Single point of failure我们作为一个 SRE 人(甚至作为一个工程师)绝不允许的事情。因此,这方面的改进可以是在负载平衡器后面部署多个应用实例。这当然可以防止一台机器停机的问题。
这里的扩展意味着在负载均衡器后面添加更多的实例。但是这只能扩展到某一点。之后,系统中的其他瓶颈将开始出现。ie: DB 会成为瓶颈,或者可能是负载均衡器本身。你怎么知道瓶颈是什么?您需要能够观察到应用架构的每个方面。
只有在你有了度量标准之后,你才能知道哪里出了问题。可以测量的,就可以固定!
从 SRE 学院的可扩展性模块中获得关于可扩展性的更深入的见解,并在浏览该模块后,将您的学习和收获应用到该应用中。想想我们将如何使这个应用在地理上分布,高度可用和可扩展。
监控策略
一旦我们部署了应用。它会正常工作的。但不会永远。可靠性是我们工作的主题,我们通过以某种方式进行设计来使系统可靠。但是事情还是会有转机。机器会失灵。磁盘的行为会很奇怪。有问题的代码将被推向生产。所有这些可能的情况都会降低系统的可靠性。那我们该怎么办?我们班长!
我们密切关注系统的健康状况,如果有任何事情不按预期进行,我们希望自己得到提醒。
现在让我们考虑一下给定的 url 缩短应用。我们需要监控它。我们希望在出现问题时得到通知。但是我们首先需要决定什么是我们想要关注的东西。
- 因为它是一个服务于 HTTP 请求的 web 应用,所以我们希望关注 HTTP 状态代码和延迟
- 请求量也是一个很好的候选,如果应用接收到不寻常的流量,可能是出了什么问题。
- 我们还希望密切关注数据库,这取决于所选择的数据库解决方案。查询时间、容量、磁盘使用情况等。
- 最后,还需要一些外部监控,从数据中心之外的设备运行定期测试。这模拟了客户,并确保从客户的角度来看,系统按预期工作。
SRE 角色中的应用
在 SRE 的世界里,python 是一种广泛使用的语言。用于为各种目的开发的小脚本和工具。由于 SRE 开发的工具可以处理基础设施的关键部分,并且具有强大的功能(使事情变得简单),所以在使用编程语言及其特性时,知道自己在做什么是很重要的。在调试问题时,了解语言及其特征也同样重要。作为一名对 python 语言有着更深理解的 SRE,它对我调试非常隐蔽的 bug 有很大帮助,并且在做出某些设计决策时通常更加了解和见多识广。
虽然开发工具可能是也可能不是 SRE 工作的一部分,但支持工具或服务更可能是日常职责。构建应用或工具只是生产化的一小部分。虽然应用本身的设计肯定会使其更加健壮,但作为一名 SRE,一旦部署并运行,您就要对其可靠性和稳定性负责。为了确保这一点,您需要首先了解应用,然后想出一个策略来适当地监控它,并为各种故障场景做好准备。
可选练习
- 制作一个装饰器,根据输入参数缓存函数返回值。
- 在任何云提供商上托管 URL 缩短应用。
- 使用许多可用的工具,如 catchpoint、datadog 等,设置监控。
- 在 TCP 套接字上创建一个最小的类似烧瓶的框架。
总结
在第一部分,本模块旨在让您更加了解当您选择 python 作为编程语言时会发生什么,以及当您运行 python 程序时会发生什么。有了 python 如何在内部处理对象的知识,python 中许多看似神奇的东西将开始变得更有意义。
第二部分将首先解释像 flask 这样的框架如何使用 TCP 和 HTTP 这样的协议的现有知识来工作。然后,它触及应用开发生命周期的整个生命周期,包括它的 SRE 部分。虽然考虑的设计和建筑领域不会详尽无遗,但它将很好地概述作为 SRE 也很重要的事情以及它们为什么重要。
数据
关系数据库
关系数据库
原文:https://linkedin.github.io/school-of-sre/level101/databases_sql/intro/
先决条件
- 完成 Linux 课程
- 安装 Docker(用于实验室部分)
从本课程中可以期待什么
您将了解什么是关系数据库,它们的优势,以及一些 MySQL 特有的概念。
本课程不包括哪些内容
-
深入实施细节
-
标准化、分片等高级主题
-
管理的特定工具
介绍
数据库系统的主要目的是管理数据。这包括存储、添加新数据、删除未使用的数据、更新现有数据、在合理的响应时间内检索数据、保持系统运行的其他维护任务等。
预读
RDBMS 概念
课程内容
- 关键概念
- MySQL 架构
- InnoDB
- 备份和恢复
- MySQL 复制
- 操作概念
- 选择查询
- 查询性能
- 实验室
- 延伸阅读
关键概念
原文:https://linkedin.github.io/school-of-sre/level101/databases_sql/concepts/
-
关系数据库用于数据存储。即使是文件也可以用来存储数据,但是关系数据库的设计有特定的目标:
- 效率
- 易于访问和管理
- 组织
- 处理数据之间的关系(表示为表格)
-
事务:一个工作单元,可以包含多个一起执行的语句
-
酸性
保证数据库事务数据完整性的一组属性
- 原子性:每个事务都是原子性的(成功或完全失败)
- 一致性:事务只产生有效状态(包括规则、约束、触发器等)。)
- 隔离:在并发系统中,每个事务都独立于其他事务安全地执行
- 持久性:已完成的事务不会因为任何后来的失败而丢失
下面举几个例子来说明上述性质。
- 账户 a 的余额为₹200,账户 b 的余额为₹400.账户 a 将₹100 转移到账户 b。该交易从发送方扣除,并在接收方的余额中增加。如果第一个操作成功通过,而第二个失败,a 的余额将是₹100,而 b 将拥有₹400 而不是₹500.DB 中的原子性确保部分失败的事务被回滚。
- 如果上面的第二个操作失败,它会使 DB 不一致(操作前后的帐户余额总和不相同)。一致性确保这种情况不会发生。
- 有三个操作,一个是为 a 的账户计算利息,另一个是将利息加到 a 的账户,然后将₹100 从 b 转移到 a。在没有隔离保证的情况下,同时执行这三个操作每次都可能导致不同的结果。
- 如果系统在事务写入磁盘之前崩溃,会发生什么情况?耐久性确保在恢复期间正确应用更改。
- 关系数据
- 表格代表关系
- 列(字段)代表属性
- 行是单独的记录
- 模式描述了数据库的结构
- 结构化查询语言
一种用于交互和管理数据的查询语言。
CRUD 操作 -创建、读取、更新、删除查询
管理操作-创建数据库/表/索引等,备份,导入/导出,用户,访问控制
练习:将以下查询分为四种类型- DDL(定义)、DML(操作)、DCL(控制)和 TCL(事务),并详细解释。
insert, create, drop, delete, update, commit, rollback, truncate, alter, grant, revoke您可以在实验室部分练习这些。
-
限制
可以存储的数据的规则。如果违反表中定义的任何一项,查询将失败。
主键:包含唯一值的一列或多列,不能包含空值。一个表只能有一个主键。默认情况下会创建一个索引。
外键:将两个表链接在一起。其值与另一个表中的主键匹配\ Not null:不允许空值\ Unique:列的值在所有行中必须是唯一的\ Default:如果在插入期间没有指定任何值,则为列提供默认值
检查:仅允许特定值(如余额> = 0)
-
指标
大多数索引使用 B+树结构。
为什么使用它们:加速查询(在只获取几行的大型表中,最小/最大查询,通过排除考虑行等)
索引类型:唯一、主键、全文、次要
写负载繁重,主要是全表扫描或访问大量行等。不从索引中受益
-
加入
允许您从多个表中获取相关数据,用一些公共字段将它们链接在一起。功能强大,但也是资源密集型的,并使数据库难以扩展。这是大规模运行时许多查询执行缓慢的原因,解决方案几乎总是寻找减少连接的方法。
-
访问控制
数据库拥有用于管理任务的特权帐户,以及用于客户端的普通帐户。对哪些操作(DDL、DML 等)有细粒度的控制。前面讨论过的)被允许用于这些帐户。
DB 首先验证用户凭证(身份验证),然后通过在一些内部表中查找这些信息来检查是否允许该用户执行请求(授权)。
其他控制包括允许检查用户操作历史的活动审计,以及定义查询、连接等数量的资源限制。允许。
流行数据库
商业、封闭源代码——Oracle、Microsoft SQL Server、IBM DB2
带有可选付费支持的开源软件——MySQL、MariaDB、PostgreSQL
由于商业软件的巨大成本,个人和小公司总是更喜欢开源数据库。
最近,即使是大型组织也已经从商业软件转向开源软件,因为它具有灵活性和成本节约。
缺少支持不再是一个问题,因为开发者和第三方可以提供付费支持。
MySQL 是使用最广泛的开源数据库,它得到了主机提供商的广泛支持,任何人都可以轻松使用。它是流行的 Linux-Apache-MySQL-PHP(LAMP)栈的一部分,该栈在 21 世纪开始流行。对于编程语言,我们有更多的选择,但是堆栈的其余部分仍然被广泛使用。
关系型数据库
原文:https://linkedin.github.io/school-of-sre/level101/databases_sql/mysql/
MySQL 架构

MySQL 架构使您能够根据自己的需求选择合适的存储引擎,并从最终用户(应用工程师和 DBA)那里抽象出所有的实现细节,他们只需要知道一个一致稳定的 API。
应用层:
- 连接处理-每个客户端获得其自己的连接,该连接在访问期间被缓存)
- 认证-服务器检查客户端的信息(用户名、密码、主机)并允许/拒绝连接
- 安全性:服务器确定客户机是否有权限执行每个查询(用 show privileges 命令检查)
服务器层:
- 服务和实用程序-备份/恢复、复制、集群等
- SQL 接口——客户端运行查询进行数据访问和操作
- SQL 解析器——根据查询创建解析树(词汇/语法/语义分析和代码生成)
- optimizer——使用各种算法和可用数据(表级统计数据)优化查询,修改查询、扫描顺序、要使用的索引等。(使用解释命令检查)
- 缓存和缓冲区——缓存存储查询结果,缓冲池(InnoDB)以 LRU 的方式存储表和索引数据
存储引擎选项:
- InnoDB:使用最广泛,事务支持,符合 ACID,支持行级锁定,崩溃恢复和多版本并发控制。MySQL 5.5+以后默认。
- MyISAM:速度快,不支持事务,提供表级锁定,非常适合读取繁重的工作负载,主要是在 web 和数据仓库中。默认升级到 MySQL 5.1。
- 存档:针对高速插入进行了优化,在插入时压缩数据,不支持事务,非常适合存储和检索大量很少引用的历史存档数据
- 内存:内存中的表。最快的引擎,支持表级锁定,不支持事务,非常适合创建临时表或快速查找,关闭后数据会丢失
- CSV:将数据存储在 CSV 文件中,非常适合集成到使用这种格式的其他应用中
- …等等。
可以从一个存储引擎迁移到另一个存储引擎。但是这种迁移锁定了所有操作的表,并且不是在线的,因为它改变了数据的物理布局。耗时较长,一般不推荐。因此,在开始时选择正确的存储引擎非常重要。
一般原则是使用 InnoDB,除非您对其他存储引擎有特殊需求。
运行mysql> SHOW ENGINES;会显示 MySQL 服务器上支持的引擎。
InnoDB
原文:https://linkedin.github.io/school-of-sre/level101/databases_sql/innodb/
为什么要用这个?
通用、行级锁定、ACID 支持、事务、崩溃恢复和多版本并发控制等。
体系结构

关键组件:
-
内存:
-
缓冲池:直接从内存中处理频繁使用的数据(表和索引)的 LRU 缓存,这加快了处理速度。这对调优性能很重要。
-
Change buffer:当二级索引页不在缓冲池中时,缓存对这些页的更改,并在获取这些页时将其合并。合并可能需要很长时间,并且会影响实时查询。它还会占用部分缓冲池。避免读取辅助索引的额外 I/O。
-
自适应散列索引:用像缓存一样的快速散列查找表补充 InnoDB 的 B 树索引。未命中的轻微性能损失,也增加了更新它的维护开销。哈希冲突会导致大型数据库的 AHI 重建。
-
日志缓冲区:在刷新到磁盘之前保存日志数据。
上述每个内存的大小都是可配置的,并且对性能有很大影响。需要仔细分析工作负载、可用资源、基准测试和优化以获得最佳性能。
-
-
磁盘:
- 表格:在行和列中存储数据。
- 索引:帮助快速查找具有特定列值的行,避免全表扫描。
- 重做日志:所有事务都被写入其中,在崩溃后,恢复过程会更正由未完成的事务写入的数据,并重放任何未完成的事务。
- 撤消日志:与单个事务相关的记录,包含有关如何撤消事务的最新更改的信息。
备份和恢复
原文:https://linkedin.github.io/school-of-sre/level101/databases_sql/backup_recovery/
备份和恢复
备份是任何数据库设置中非常重要的一部分。它们通常是数据的副本,可用于在数据库出现任何重大或轻微危机时重建数据。一般来说,备份有两种类型:-
- 物理备份 -磁盘上的数据目录
- 逻辑备份 -表格结构和其中的记录
MySQL 使用不同的工具支持以上两种备份。SRE 的工作是确定什么时候应该使用哪一个。
Mysqldump
MySQL 安装中提供了该实用程序。它有助于获得数据库的逻辑备份。它输出一组 SQL 语句来重建数据。不建议对大型表使用 mysqldump,因为这可能会花费很多时间,并且文件会很大。然而,对于小桌子来说,这是最好和最快的选择。
mysqldump [options] > dump_output.sql
mysqldump 可以使用某些选项来获得适当的数据库转储。
转储所有数据库
mysqldump -u<user> -p<pwd> --all-databases > all_dbs.sql
转储特定数据库
mysqldump -u<user> -p<pwd> --databases db1 db2 db3 > dbs.sql
转储单个数据库mysqldump -u<user> -p<pwd> --databases db1 > db1.sql
运筹学
mysqldump -u<user> -p<pwd> db1 > db1.sql
以上两个命令的区别在于,后一个命令在备份输出中不包含 CREATE DATABASE 命令。
转储数据库中的特定表
mysqldump -u<user> -p<pwd> db1 table1 table2 > db1_tables.sql
只转储表结构而不转储数据
mysqldump -u<user> -p<pwd> --no-data db1 > db1_structure.sql
只转储表数据而不转储 CREATE 语句
mysqldump -u<user> -p<pwd> --no-create-info db1 > db1_data.sql
仅转储表中的特定记录
mysqldump -u<user> -p<pwd> --no-create-info db1 table1 --where=”salary>80000” > db1_table1_80000.sql
Mysqldump 还可以提供 CSV、其他带分隔符的文本或 XML 格式的输出,以支持任何用例。mysqldump 实用程序的备份是离线的,即当备份完成时,它将不会对数据库进行备份时所做的更改。例如,如果备份在下午 3 点开始,在下午 4 点结束,则在下午 3 点到 4 点之间不会对数据库进行更改。
从 mysqldump 恢复可以通过以下两种方式完成:-
来自 shell
mysql -u<user> -p<pwd> < all_dbs.sql
运筹学
如果已经创建了数据库,则从 shell
mysql -u<user> -p<pwd> db1 < db1.sql
从 MySQL shell 内部
mysql> source all_dbs.sql
Percona Xtrabackup
这个工具与 MySQL 服务器分开安装,并且是开源的,由 Percona 提供。它有助于获得数据库的完整或部分物理备份。它提供了数据库的在线备份,也就是说,如前一节末尾所述,在备份过程中会对数据库进行更改。
- 完整备份 -数据库的完整备份。
- 部分备份 -增量备份
- 累积 -一次完整备份后,下一次备份将在完整备份后发生更改。例如,我们在周日进行了一次完整备份,从周一开始,每次备份在周日之后都会有变化;因此,星期二的备份也会有星期一的更改,星期三的备份也会有星期一和星期二的更改,依此类推。
- 差异 -在一次完整备份之后,下一次备份将在之前的增量备份之后发生更改。例如,我们在周日进行了完整备份,在周日之后对周一进行了更改,在周一之后对周二进行了更改,依此类推。

Percona xtrabackup 允许我们根据需要进行完整备份和增量备份。但是,增量备份占用的空间比完整备份少(如果每天进行一次),但是增量备份的恢复时间比完整备份长。
创建完整备份
xtrabackup --defaults-file=<location to my.cnf> --user=<mysql user> --password=<mysql password> --backup --target-dir=<location of target directory>
例子
xtrabackup --defaults-file=/etc/my.cnf --user=some_user --password=XXXX --backup --target-dir=/mnt/data/backup/
一些其他选项
--stream-可用于将备份文件以指定格式流式输出到标准输出。xbstream 是目前唯一的选择。--tmp-dir-将此设置为备份时用于临时文件的 tmp 目录。--parallel-将此设置为可用于将数据文件并行复制到目标目录的线程数量。--compress-默认情况下-使用 quicklz。设定此项以压缩格式备份。每个文件都是一个. qp 压缩文件,可以由 qpress 文件归档程序提取。--decompress-解压缩所有使用。qp 扩展。它不会删除。解压缩后的 qp 文件。为此,使用--remove-original和这个。请注意,解压缩选项应该与使用压缩选项的 xtrabackup 命令分开运行。
准备备份
使用- backup 选项完成备份后,我们需要准备它以便恢复它。这样做是为了使数据文件与时间点一致。在执行备份时,可能有一些事务正在进行,这些事务已经更改了数据文件。当我们准备备份时,所有这些事务都应用于数据文件。
xtrabackup --prepare --target-dir=<where backup is taken>
例子
xtrabackup --prepare --target-dir=/mnt/data/backup/
不建议暂停正在准备备份的进程,因为这可能会导致数据文件损坏,并且备份无法进一步使用。必须再次进行备份。
恢复完整备份
要恢复通过上述命令创建和准备的备份,只需将所有内容从备份目标目录复制到 mysql 服务器的数据目录,将所有文件的所有权更改为 mysql 用户(MySQL 服务器使用的 linux 用户)并启动 MySQL。
或者也可以使用下面的命令,
xtrabackup --defaults-file=/etc/my.cnf --copy-back --target-dir=/mnt/data/backups/
注意 -为了恢复备份,必须准备好备份。
创建增量备份
Percona Xtrabackup 有助于创建增量备份,即只能备份自上次备份以来的更改。每个 InnoDB 页面都包含一个日志序列号或 LSN,它也是备份和准备命令的最后一行。
xtrabackup: Transaction log of lsn <LSN> to <LSN> was copied.
运筹学
InnoDB: Shutdown completed; log sequence number <LSN>
<timestamp> completed OK!
这表明在提到日志序列号之前,已经进行了备份。这是理解增量备份和实现自动化备份的关键信息。增量备份不会比较数据文件的变化,而是浏览 InnoDB 页面,并将它们的 LSN 与上次备份的 LSN 进行比较。因此,如果没有一次完整备份,增量备份将毫无用处。
xtrabackup 命令创建 xtrabackup_checkpoint 文件,该文件包含有关备份 LSN 的信息。以下是该文件的主要内容
backup_type = full-backuped | incremental
from_lsn = 0 (full backup) | to_lsn of last backup <LSN>
to_lsn = <LSN>
last_lsn = <LSN>
to_lsn 和 last_lsn 是有区别的。当的 last_lsn 大于 to_lsn 时,这意味着有在我们进行备份时运行的事务尚未应用。这就是- prepare 的用途。
要进行增量备份,首先,我们需要一个完整备份。
xtrabackup --defaults-file=/etc/my.cnf --user=some_user --password=XXXX --backup --target-dir=/mnt/data/backup/full/
让我们假设 xtrabackup_checkpoint 文件的内容如下。
backup_type = full-backuped
from_lsn = 0
to_lsn = 1000
last_lsn = 1000
现在我们有了一个完整备份,我们可以有一个增量备份来进行更改。我们将采用差异增量备份。
xtrabackup --defaults-file=/etc/my.cnf --user=some_user --password=XXXX --backup --target-dir=/mnt/data/backup/incr1/ --incremental-basedir=/mnt/data/backup/full/
在 incr1 目录中创建了 delta 文件,如, ibdata1.delta , db1/tbl1.ibd.delta 与完整目录的变化。xtrabackup_checkpoint 文件将包含以下内容。
backup_type = incremental
from_lsn = 1000
to_lsn = 1500
last_lsn = 1500
因此,这里的 from_lsn 等于最后一次备份的 to_lsn 或者为增量备份提供的 basedir。对于下一次增量备份,我们可以将该增量备份用作基本目录。
xtrabackup --defaults-file=/etc/my.cnf --user=some_user --password=XXXX --backup --target-dir=/mnt/data/backup/incr2/ --incremental-basedir=/mnt/data/backup/incr1/
xtrabackup_checkpoint 文件将包含以下内容。
backup_type = incremental
from_lsn = 1500
to_lsn = 2000
last_lsn = 2200
准备增量备份
准备增量备份不同于准备完整备份。当准备运行时,执行两个操作- 提交的事务应用于数据文件和未提交的事务回滚。在准备增量备份时,我们必须跳过未提交事务的回滚,因为它们可能会在下一次增量备份中提交。如果我们回滚未提交的事务,则无法应用进一步的增量备份。
我们使用 - apply-log-only 选项和 - prepare 来避免回滚阶段。
在上一节中,我们有了以下带有完整备份的目录
/mnt/data/backup/full
/mnt/data/backup/incr1
/mnt/data/backup/incr2
首先,我们准备完整备份,但仅使用- apply-log-only 选项。
xtrabackup --prepare --apply-log-only --target-dir=/mnt/data/backup/full
该命令的输出将在末尾包含以下内容。
InnoDB: Shutdown complete; log sequence number 1000
<timestamp> Completed OK!
注意:结尾提到的 LSN 与为完整备份创建的 xtrabackup_checkpoint 中的 to_lsn 相同。
接下来,我们将第一次增量备份中的更改应用于完整备份。
xtrabackup --prepare --apply-log-only --target-dir=/mnt/data/backup/full --incremental-dir=/mnt/data/backup/incr1
这会将增量目录中的增量文件应用到完整备份目录。它将完整备份目录中的数据文件前滚到增量备份时,并照常应用重做日志。
最后,我们应用最后一次增量备份,与前一次备份相同,只是做了一点小小的更改。
xtrabackup --prepare --target-dir=/mnt/data/backup/full --incremental-dir=/mnt/data/backup/incr1
我们不必使用 - apply-log-only 选项。它将 incr2 delta 文件应用于完整备份数据文件,将它们向前推进,对它们应用重做日志,最后回滚未提交的事务以产生最终结果。现在,完整备份目录中的数据可用于恢复。
注意 -要创建累积增量备份,增量 basedir 应该始终是每个增量备份的完整备份目录。在准备过程中,我们可以使用- apply-log-only 选项从完整备份开始,并将最后一次增量备份用于最终准备,因为它包含自完整备份以来的所有更改。
恢复增量备份
完成上述所有步骤后,恢复与完整备份相同。
进一步阅读
- MySQL 时间点恢复
- 另一款 MySQL 备份工具——MySQL pump
- 另一款 MySQL 备份工具——my dumper
- 【mysqldump、mysqlpump 和 mydumper 的比较
- 备份最佳实践
MySQL 复制
原文:https://linkedin.github.io/school-of-sre/level101/databases_sql/replication/
MySQL 复制
复制使数据能够从一台 MySQL 主机(称为主主机)复制到另一台 MySQL 主机(称为副本主机)。默认情况下,MySQL 复制本质上是异步的,但在某些配置下,可以将其更改为半同步。
MySQL 复制的一些常见应用有:-
- 读取扩展 -由于多个主机可以从单个主要主机复制数据,我们可以根据需要设置尽可能多的副本,并通过它们扩展读取,即应用写入将进入单个主要主机,读取可以在那里的所有副本之间平衡。这种设置还可以提高写入性能,因为主节点仅用于更新,而不用于读取。
- 使用副本进行备份 -备份过程有时会有点繁重。但是,如果我们配置了副本,那么我们可以使用其中一个副本来获得备份,而完全不会影响主数据。
- 灾难恢复 -其他地理区域中的副本为配置灾难恢复铺平了道路。
MySQL 也支持不同类型的同步
- 异步 -这是默认的同步方法。它是单向的,即一台主机作为主主机,一台或多台主机作为副本主机。我们将在整个复制主题中讨论这种方法。

- 半同步 -在这种类型的同步中,在主要主机上执行的提交将被阻止,直到至少有一个副本主机对其进行确认。在任何一个复制副本发出确认后,控制权将返回到执行该事务的会话。这确保了很强的一致性,但是复制比异步慢。
- 延迟——我们可以在典型的 MySQL 复制中故意将副本延迟用例所需的秒数。这种类型的复制可以防止在主服务器上删除或损坏数据的严重人为错误,例如,在上面的延迟复制图表中,如果在主服务器上错误地执行了删除数据库,我们仍然有 30 分钟的时间从 R2 恢复数据,因为该命令尚未在 R2 上复制。
先决条件
在我们开始设置复制之前,我们应该了解二进制日志。二进制日志在 MySQL 复制中起着非常重要的作用。二进制日志,或者通常称为二进制日志包含关于对数据库所做的更改的事件,比如表结构更改、通过 DML 操作的数据更改等。它们不用于记录 SELECT 语句。对于复制,主服务器使用其二进制日志向副本服务器发送有关数据库更改的信息,副本服务器进行相同的数据更改。
关于 MySQL 复制,二进制日志格式可以是两种类型,这两种类型决定了主要的复制类型:?基于语句的复制或 SBR?基于行的复制或 RBR
基于语句的 Binlog 格式
最初,MySQL 中的复制基于从主服务器复制 SQL 语句并在副本服务器上执行。这称为基于语句的日志记录。binlog 包含会话运行的确切 SQL 语句。

因此,如果我们运行上述语句,在一个 update 语句中插入 3 条记录和 update 3,它们将被记录为与我们执行它们时完全相同的日志。

基于行的 Binlog 格式
在最新的 MySQL 版本中,基于行是默认的。这与语句格式有很大不同,因为这里记录的是行事件,而不是语句。我们的意思是,在上面的例子中,一条 update 语句影响了 3 条记录,但是 binlog 只有一条 update 语句;如果是基于行的格式,binlog 将为每个更新的记录生成一个事件。


基于语句的 v/s 基于行的二进制日志
让我们看看基于语句和基于行的二进制日志之间的操作差异。
| 基于语句 | 基于行 |
|---|---|
| 记录执行的 SQL 语句 | 基于执行的 SQL 语句记录行事件 |
| 占用较少的磁盘空间 | 占用更多磁盘空间 |
| 使用二进制日志恢复速度更快 | 使用二进制日志恢复速度较慢 |
| 当用于复制时,如果任何语句有一个预定义的函数,该函数有自己的值,如 sysdate()、uuid()等,则副本上的输出可能会不同,从而导致不一致。 | 无论执行什么都会变成一个带有值的行事件,所以如果在 SQL 语句中使用这样的函数就不会有问题。 |
| 只记录语句,因此不会生成其他行事件。 | 当使用 INSERT INTO SELECT 将一个表复制到另一个表中时,会生成许多事件。 |
注意——还有一种叫做混合的 binlog 格式。对于混合日志记录,默认情况下使用基于语句,但在某些情况下会切换到基于行。如果 MySQL 不能保证基于语句的日志记录对于执行的语句是安全的,它会发出警告,并切换到基于行的日志记录。
我们将使用二进制日志格式作为整个复制主题的行。
运动中的复制

上图显示了典型的 MySQL 复制是如何工作的。
- Replica_IO_Thread 负责将二进制日志事件从主二进制日志提取到副本
- 在副本主机上,创建的中继日志是二进制日志的精确副本。如果主服务器上的二进制日志是行格式,则中继日志将是相同的。
- Replica_SQL_Thread 在副本 MySQL 服务器上应用中继日志。
- 如果在副本服务器上启用了 log-bin,那么副本服务器也将拥有自己的二进制日志。如果启用了 log-slave-updates,那么它也会将主服务器的更新记录到二进制日志中。
设置复制
在本节中,我们将设置一个简单的异步复制。二进制日志将采用基于行的格式。复制将在两个没有先前数据的新主机上设置。有两种不同的方法可以设置复制。
- 基于二进制日志的 -每个副本都记录了主二进制日志上的二进制日志坐标和二进制日志中的位置,直到它被读取和处理。因此,在同一时间,不同的副本可能会读取同一个 binlog 的不同部分。
- 基于 GTID 的 -每个交易都有一个标识符,称为全局交易标识符或 GTID。不需要保留 binlog 坐标的记录,只要副本拥有在主服务器上执行的所有 GTIDs,它就与主服务器保持一致。典型的 GTID 是 server_uuid:#正整数。
我们将在下一节中设置一个基于 GTID 的复制,但也将讨论基于 binlog 的复制设置。
主要主机配置
在设置基于 GTID 的复制时,主要 my.cnf 文件中应该包含以下配置参数。
server-id - a unique ID for the mysql server
log-bin - the binlog location
binlog-format - ROW | STATEMENT (we will use ROW)
gtid-mode - ON
enforce-gtid-consistency - ON (allows execution of only those statements which can be logged using GTIDs)
副本主机配置
设置复制时,副本 my.cnf 文件中应包含以下配置参数。
server-id - different than the primary host
log-bin - (optional, if you want replica to log its own changes as well)
binlog-format - depends on the above
gtid-mode - ON
enforce-gtid-consistency - ON
log-slave-updates - ON (if binlog is enabled, then we can enable this. This enables the replica to log the changes coming from the primary along with its own changes. Helps in setting up chain replication)
复制用户
每个副本都使用 mysql 用户连接到主服务器进行复制。因此在主要主机上必须有一个相同的 mysql 用户帐户。只要拥有复制从属权限,任何用户都可以用于此目的。如果唯一的目的是复制,那么我们可以让用户只拥有所需的权限。
在主要主机上
mysql> create user repl_user@<replica_IP> identified by 'xxxxx';mysql> grant replication slave on *.* to repl_user@'<replica_IP>';
从主节点获取起始位置
在主要主机上运行以下命令
mysql> show master status\G
*************************** 1\. row ***************************File: mysql-bin.000001Position: 73Binlog_Do_DB:Binlog_Ignore_DB:
Executed_Gtid_Set: e17d0920-d00e-11eb-a3e6-000d3aa00f87:1-3
1 row in set (0.00 sec)
如果我们使用基于二进制日志的复制,最上面的两行输出是最重要的。它告诉主主机上的当前二进制日志,以及它已经写入的位置。对于新主机,我们知道没有数据写入,因此我们可以使用第一个 binlog 文件和位置 4 直接设置复制。如果我们从备份中设置复制,那么这将改变我们获取起始位置的方式。对于 gtid,executed_gtid_set 是 primary 当前所在的值。同样,对于新的设置,我们不必指定任何关于起始点的内容,它将从事务 id 1 开始,但是当我们从备份设置时,备份将包含 GTID 位置,直到进行备份的位置。
设置副本
复制设置必须知道主要主机、要连接的用户和密码、binlog 坐标(对于基于 binlog 的复制)或 GTID 自动定位参数。以下命令用于设置
change master to
master_host = '<primary host IP>',
master_port = <primary host port - default=3306>,
master_user = 'repl_user',
master_password = 'xxxxx',
master_auto_position = 1;
注意 -从 Mysql 8.0.23 开始,将主服务器更改为命令已被替换为将复制源更改为,所有主服务器和从服务器关键字也被替换为源和副本。
如果是基于二进制日志的复制,那么我们需要指定二进制日志坐标,而不是 master_auto_position。
master_log_file = 'mysql-bin.000001',
master_log_pos = 4
开始复制并检查状态
现在一切都配置好了,我们只需要通过以下命令在副本上启动复制
start slave;
或者从 MySQL 8.0.23 开始,
start replica;
复制是否成功运行,我们可以通过运行以下命令来确定
show slave status\G
或者从 MySQL 8.0.23 开始,
show replica status\G
mysql> show replica status\G
*************************** 1\. row ***************************Replica_IO_State: Waiting for master to send eventSource_Host: <primary IP>Source_User: repl_userSource_Port: <primary port>Connect_Retry: 60Source_Log_File: mysql-bin.000001Read_Source_Log_Pos: 852Relay_Log_File: mysql-relay-bin.000002Relay_Log_Pos: 1067Relay_Source_Log_File: mysql-bin.000001Replica_IO_Running: YesReplica_SQL_Running: YesReplicate_Do_DB:Replicate_Ignore_DB:Replicate_Do_Table:Replicate_Ignore_Table:Replicate_Wild_Do_Table:Replicate_Wild_Ignore_Table:Last_Errno: 0Last_Error:Skip_Counter: 0Exec_Source_Log_Pos: 852Relay_Log_Space: 1283Until_Condition: NoneUntil_Log_File:Until_Log_Pos: 0Source_SSL_Allowed: NoSource_SSL_CA_File:Source_SSL_CA_Path:Source_SSL_Cert:Source_SSL_Cipher:Source_SSL_Key:Seconds_Behind_Source: 0
Source_SSL_Verify_Server_Cert: NoLast_IO_Errno: 0Last_IO_Error:Last_SQL_Errno: 0Last_SQL_Error:Replicate_Ignore_Server_Ids:Source_Server_Id: 1Source_UUID: e17d0920-d00e-11eb-a3e6-000d3aa00f87Source_Info_File: mysql.slave_master_infoSQL_Delay: 0SQL_Remaining_Delay: NULLReplica_SQL_Running_State: Slave has read all relay log; waiting for more updatesSource_Retry_Count: 86400Source_Bind:Last_IO_Error_Timestamp:Last_SQL_Error_Timestamp:Source_SSL_Crl:Source_SSL_Crlpath:Retrieved_Gtid_Set: e17d0920-d00e-11eb-a3e6-000d3aa00f87:1-3Executed_Gtid_Set: e17d0920-d00e-11eb-a3e6-000d3aa00f87:1-3Auto_Position: 1Replicate_Rewrite_DB:Channel_Name:Source_TLS_Version:Source_public_key_path:Get_Source_public_key: 0Network_Namespace:
1 row in set (0.00 sec)
一些参数解释如下
- Relay_Source_Log_File -副本当前正在读取的主服务器的文件
- Execute_Source_Log_Pos -对于上述文件,副本当前从哪个位置读取。当使用基于 binlog 的复制时,这两个参数至关重要。
- 副本 IO 运行 -副本 IO 线程是否运行
- 副本 _SQL_Running -副本的 SQL 线程是否正在运行
- Seconds_Behind_Source -在主服务器上执行语句和在副本服务器上执行语句的时间差。这表明有多少复制延迟。
- 源 _UUID -主要主机的 UUID
- Retrieved_Gtid_Set -要执行的副本从主要主机获取的 Gtid。
- Executed_Gtid_Set -在副本上执行的 Gtid。如果副本同步,则该设置在整个集群中保持不变。
- Auto_Position -它指示复制品自动获取下一个 GTID
为已经设置好的集群创建一个副本
上一节中讨论的步骤讨论了在两台新主机上设置复制。当我们必须为已经在为应用提供服务的主机设置复制副本时,将使用主主机的备份,或者为复制副本创建新的备份(仅当它提供的流量较少时才应这样做),或者使用最近创建的备份。
如果 MySQL 主服务器上的数据库很小,建议小于 100G,那么可以使用 mysqldump 和以下选项进行备份。
mysqldump -uroot -p -hhost_ip -P3306 --all-databases --single-transaction --master-data=1 > primary_host.bkp
--single-transaction-该选项在进行备份之前启动事务,以确保事务的一致性。由于事务相互隔离,因此不会有其他写入影响备份。--master-data-如果希望设置基于 binlog 的复制,则需要此选项。它包括二进制日志文件和日志文件在备份文件中的位置。
当 GTID 模式被启用并且 mysqldump 被执行时,它包括被执行用于在备份位置之后启动副本的 GTID。mysqldump 输出文件的内容如下

建议在恢复之前对这些进行注释,否则它们可能会引发错误。此外,使用 master-data=2 将自动注释 master_log_file 行。
同样,当使用 xtrabackup 对主机进行备份时,文件 xtrabckup_info file 包含 binlog 文件和文件位置的信息,以及 GTID 执行集。
server_version = 8.0.25
start_time = 2021-06-22 03:45:17
end_time = 2021-06-22 03:45:20
lock_time = 0
binlog_pos = filename 'mysql-bin.000007', position '196', GTID of the last change 'e17d0920-d00e-11eb-a3e6-000d3aa00f87:1-5'
innodb_from_lsn = 0
innodb_to_lsn = 18153149
partial = N
incremental = N
format = file
compressed = N
encrypted = N
现在,在所需的主机上设置 MySQL 服务器后,恢复从上述任何一种方法获得的备份。如果计划的方式是基于二进制日志的复制,则在以下命令中使用二进制日志文件和位置信息
change Replication Source to
source_host = ‘primary_ip’,
source_port = 3306,
source_user = ‘repl_user’,
source_password = ‘xxxxx’,
source_log_file = ‘mysql-bin.000007’,
source_log_pos = ‘196’;
如果需要通过 GITDs 设置复制,那么运行下面的命令告诉副本关于已经执行的 GTIDs。在副本主机上,运行以下命令
reset master;set global gtid_purged = ‘e17d0920-d00e-11eb-a3e6-000d3aa00f87:1-5’change replication source to
source_host = ‘primary_ip’,
source_port = 3306,
source_user = ‘repl_user’,
source_password = ‘xxxxx’,
source_auto_position = 1
reset master 命令将二进制日志的位置重置为初始位置。如果主机是新安装的 MySQL,可以跳过它,但我们恢复了一个备份,所以它是必要的。gtid_purged 全局变量让副本知道已经执行的 gtid,以便复制可以在那之后开始。然后在 change source 命令中,我们将 auto-position 设置为 1,这将自动获取下一个 GTID 以继续。
进一步阅读
- 复制的更多应用
- 使用 MySQL Orchestrator 实现自动故障转移
操作概念
原文:https://linkedin.github.io/school-of-sre/level101/databases_sql/operations/
-
解释解释+分析
解释
分析来自优化器的查询计划,包括如何连接表,扫描哪些表/行等。 Explain analyze 显示上述信息和附加信息,如执行成本、返回的行数、花费的时间等。
这些知识对于调整查询和添加索引非常有用。
看这个性能调音教程视频。
查看实验室部分,获得关于索引的实际操作。
-
慢速查询日志
用于识别慢速查询(可配置阈值),在配置中启用或随查询动态启用
查看关于识别慢速查询的实验部分。
-
用户管理
这包括创建和更改用户,如管理权限、更改密码等。
-
备份和恢复策略,优点和缺点
使用 mysqldump 的逻辑备份-较慢,但可以在线完成
物理备份(复制数据目录或使用 xtrabackup) -快速备份/恢复。复制数据目录需要锁定或关闭。xtrabackup 是一个改进,因为它支持不关机的备份(热备份)。
其他- PITR,快照等。
-
使用重做日志的故障恢复过程
崩溃后,当您重新启动服务器时,它会读取重做日志并重放修改以进行恢复
-
监控 MySQL
关键 MySQL 指标:读取、写入、查询运行时间、错误、慢速查询、连接、运行线程、InnoDB 指标
关键操作系统指标:CPU、负载、内存、磁盘 I/O、网络
-
分身术
将数据从一个实例复制到一个或多个实例。有助于横向扩展、数据保护、分析和性能。Binlog 主服务器上的转储线程,辅助服务器上的复制 I/O 和 SQL 线程。策略包括标准异步、半异步或组复制。
-
高可用性
处理软件、硬件和网络故障的能力。对于需要 99.9%以上正常运行时间的任何人来说都是必不可少的。可以通过 MySQL、Percona、Oracle 等的复制或集群解决方案实施。需要专业知识来设置和维护。故障转移可以是手动的、脚本化的或使用 Orchestrator 等工具。
-
数据目录
数据存储在特定的目录中,每个数据库中包含嵌套的数据目录。还有 MySQL 日志文件、InnoDB 日志文件、服务器进程 ID 文件和其他一些配置。数据目录是可配置的。
-
MySQL 配置
这可以通过在启动时传递参数来完成,或者在文件中完成。MySQL 查找配置文件有几个标准路径,
/etc/my.cnf是常用路径之一。这些选项被组织在标题下(mysqld 用于服务器,mysql 用于客户端),您可以在接下来的实验中更深入地了解它们。 -
日志
MySQL 有各种用途的日志——一般查询日志、错误、二进制日志(用于复制)、慢速查询日志。默认情况下只启用错误日志(以减少 I/O 和存储需求),其他日志可以在需要时启用——通过在启动时指定配置参数或在运行时运行命令。日志目的地也可以通过配置参数进行调整。
选择查询
原文:https://linkedin.github.io/school-of-sre/level101/databases_sql/select_query/
选择查询
使用 MySQL 时最常用的命令是 SELECT。它用于从一个或多个表中获取结果集。典型的选择查询的一般形式如下
SELECT expr
FROM table1
[WHERE condition]
[GROUP BY column_list HAVING condition]
[ORDER BY column_list ASC|DESC]
[LIMIT #]
上面的一般形式包含了 SELECT 查询的一些常用子句:-
- expr -逗号分隔的列列表或*(针对所有列)
- 其中 -提供了一个条件,如果为真,则指示查询只选择那些记录。
- GROUP BY -根据提供的列列表对整个结果集进行分组。建议在查询的选择表达式中使用聚合函数。 HAVING 通过在所选函数或任何其他集合函数上设置条件来支持分组。
- ORDER BY -根据列列表以升序或降序对结果集进行排序。
- 限制 -常用来限制记录的数量。
为了更好地理解上述内容,我们来看一些例子。以下示例中使用的数据集可从这里获得,并可免费使用。
选择所有记录
mysql> select * from employees limit 5;
+--------+------------+------------+-----------+--------+------------+
| emp_no | birth_date | first_name | last_name | gender | hire_date |
+--------+------------+------------+-----------+--------+------------+
| 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 |
| 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 |
| 10003 | 1959-12-03 | Parto | Bamford | M | 1986-08-28 |
| 10004 | 1954-05-01 | Chirstian | Koblick | M | 1986-12-01 |
| 10005 | 1955-01-21 | Kyoichi | Maliniak | M | 1989-09-12 |
+--------+------------+------------+-----------+--------+------------+
5 rows in set (0.00 sec)
为所有记录选择特定字段
mysql> select first_name, last_name, gender from employees limit 5;
+------------+-----------+--------+
| first_name | last_name | gender |
+------------+-----------+--------+
| Georgi | Facello | M |
| Bezalel | Simmel | F |
| Parto | Bamford | M |
| Chirstian | Koblick | M |
| Kyoichi | Maliniak | M |
+------------+-----------+--------+
5 rows in set (0.00 sec)
选择所有雇佣日期>= 1990 年 1 月 1 日的记录
mysql> select * from employees where hire_date >= '1990-01-01' limit 5;
+--------+------------+------------+-------------+--------+------------+
| emp_no | birth_date | first_name | last_name | gender | hire_date |
+--------+------------+------------+-------------+--------+------------+
| 10008 | 1958-02-19 | Saniya | Kalloufi | M | 1994-09-15 |
| 10011 | 1953-11-07 | Mary | Sluis | F | 1990-01-22 |
| 10012 | 1960-10-04 | Patricio | Bridgland | M | 1992-12-18 |
| 10016 | 1961-05-02 | Kazuhito | Cappelletti | M | 1995-01-27 |
| 10017 | 1958-07-06 | Cristinel | Bouloucos | F | 1993-08-03 |
+--------+------------+------------+-------------+--------+------------+
5 rows in set (0.01 sec)
从出生日期> = 1960 且性别= 'F' 的所有记录中选择名字和姓氏
mysql> select first_name, last_name from employees where year(birth_date) >= 1960 and gender='F' limit 5;
+------------+-----------+
| first_name | last_name |
+------------+-----------+
| Bezalel | Simmel |
| Duangkaew | Piveteau |
| Divier | Reistad |
| Jeong | Reistad |
| Mingsen | Casley |
+------------+-----------+
5 rows in set (0.00 sec)
显示记录总数
mysql> select count(*) from employees;
+----------+
| count(*) |
+----------+
| 300024 |
+----------+
1 row in set (0.05 sec)
显示所有记录的性别计数
mysql> select gender, count(*) from employees group by gender;
+--------+----------+
| gender | count(*) |
+--------+----------+
| M | 179973 |
| F | 120051 |
+--------+----------+
2 rows in set (0.14 sec)
显示雇佣年份 _ 日期和该年雇佣的员工数量,并且只显示雇佣员工超过 2 万人的年份
mysql> select year(hire_date), count(*) from employees group by year(hire_date) having count(*) > 20000;
+-----------------+----------+
| year(hire_date) | count(*) |
+-----------------+----------+
| 1985 | 35316 |
| 1986 | 36150 |
| 1987 | 33501 |
| 1988 | 31436 |
| 1989 | 28394 |
| 1990 | 25610 |
| 1991 | 22568 |
| 1992 | 20402 |
+-----------------+----------+
8 rows in set (0.14 sec)
按雇佣日期降序显示所有记录。如果雇佣日期相同,则按出生日期升序排列
mysql> select * from employees order by hire_date desc, birth_date asc limit 5;
+--------+------------+------------+-----------+--------+------------+
| emp_no | birth_date | first_name | last_name | gender | hire_date |
+--------+------------+------------+-----------+--------+------------+
| 463807 | 1964-06-12 | Bikash | Covnot | M | 2000-01-28 |
| 428377 | 1957-05-09 | Yucai | Gerlach | M | 2000-01-23 |
| 499553 | 1954-05-06 | Hideyuki | Delgrande | F | 2000-01-22 |
| 222965 | 1959-08-07 | Volkmar | Perko | F | 2000-01-13 |
| 47291 | 1960-09-09 | Ulf | Flexer | M | 2000-01-12 |
+--------+------------+------------+-----------+--------+------------+
5 rows in set (0.12 sec)
选择-连接
JOIN 语句用于根据某些条件从两个或多个表中产生一个组合结果集。它也可以与 Update 和 Delete 语句一起使用,但是我们将集中讨论 select 查询。以下是连接的基本通用形式
SELECT table1.col1, table2.col1, ... (any combination)
FROM
table1 <join_type> table2
ON (or USING depends on join_type) table1.column_for_joining = table2.column_for_joining
WHERE …
可以选择任意数量的列,但是建议只选择那些与增加结果集可读性相关的列。所有其他子句,如 where、group by 都不是强制性的。让我们讨论一下 MySQL 语法支持的连接类型。
内部连接
这在一个条件下连接表 A 和表 B。在结果集中,只选择条件为真的记录。
显示员工的一些详细信息以及他们的工资
mysql> select e.emp_no,e.first_name,e.last_name,s.salary from employees e join salaries s on e.emp_no=s.emp_no limit 5;
+--------+------------+-----------+--------+
| emp_no | first_name | last_name | salary |
+--------+------------+-----------+--------+
| 10001 | Georgi | Facello | 60117 |
| 10001 | Georgi | Facello | 62102 |
| 10001 | Georgi | Facello | 66074 |
| 10001 | Georgi | Facello | 66596 |
| 10001 | Georgi | Facello | 66961 |
+--------+------------+-----------+--------+
5 rows in set (0.00 sec)
类似结果可以通过以下方式实现
mysql> select e.emp_no,e.first_name,e.last_name,s.salary from employees e join salaries s using (emp_no) limit 5;
+--------+------------+-----------+--------+
| emp_no | first_name | last_name | salary |
+--------+------------+-----------+--------+
| 10001 | Georgi | Facello | 60117 |
| 10001 | Georgi | Facello | 62102 |
| 10001 | Georgi | Facello | 66074 |
| 10001 | Georgi | Facello | 66596 |
| 10001 | Georgi | Facello | 66961 |
+--------+------------+-----------+--------+
5 rows in set (0.00 sec)
也是由
mysql> select e.emp_no,e.first_name,e.last_name,s.salary from employees e natural join salaries s limit 5;
+--------+------------+-----------+--------+
| emp_no | first_name | last_name | salary |
+--------+------------+-----------+--------+
| 10001 | Georgi | Facello | 60117 |
| 10001 | Georgi | Facello | 62102 |
| 10001 | Georgi | Facello | 66074 |
| 10001 | Georgi | Facello | 66596 |
| 10001 | Georgi | Facello | 66961 |
+--------+------------+-----------+--------+
5 rows in set (0.00 sec)
外部连接
主要有两种类型:- - 左 -在一个条件下连接完整的表 A 和表 B。选择表 A 中的所有记录,但是在表 B 中,只选择条件为真的那些记录。- 右 -与左接合完全相反。
为了更好地理解左连接,让我们假设下表。
mysql> select * from dummy1;
+----------+------------+
| same_col | diff_col_1 |
+----------+------------+
| 1 | A |
| 2 | B |
| 3 | C |
+----------+------------+mysql> select * from dummy2;
+----------+------------+
| same_col | diff_col_2 |
+----------+------------+
| 1 | X |
| 3 | Y |
+----------+------------+
一个简单的选择连接如下所示。
mysql> select * from dummy1 d1 left join dummy2 d2 on d1.same_col=d2.same_col;
+----------+------------+----------+------------+
| same_col | diff_col_1 | same_col | diff_col_2 |
+----------+------------+----------+------------+
| 1 | A | 1 | X |
| 3 | C | 3 | Y |
| 2 | B | NULL | NULL |
+----------+------------+----------+------------+
3 rows in set (0.00 sec)
也可以写成
mysql> select * from dummy1 d1 left join dummy2 d2 using(same_col);
+----------+------------+------------+
| same_col | diff_col_1 | diff_col_2 |
+----------+------------+------------+
| 1 | A | X |
| 3 | C | Y |
| 2 | B | NULL |
+----------+------------+------------+
3 rows in set (0.00 sec)
同时也是
mysql> select * from dummy1 d1 natural left join dummy2 d2;
+----------+------------+------------+
| same_col | diff_col_1 | diff_col_2 |
+----------+------------+------------+
| 1 | A | X |
| 3 | C | Y |
| 2 | B | NULL |
+----------+------------+------------+
3 rows in set (0.00 sec)
交叉连接
这是表 A 和表 B 的叉积,没有任何条件。它在现实世界中没有太多的应用。
一个简单的交叉连接如下所示
mysql> select * from dummy1 cross join dummy2;
+----------+------------+----------+------------+
| same_col | diff_col_1 | same_col | diff_col_2 |
+----------+------------+----------+------------+
| 1 | A | 3 | Y |
| 1 | A | 1 | X |
| 2 | B | 3 | Y |
| 2 | B | 1 | X |
| 3 | C | 3 | Y |
| 3 | C | 1 | X |
+----------+------------+----------+------------+
6 rows in set (0.01 sec)
一个可以派上用场的用例是当您必须填充一些缺失的条目时。例如,dummy1 中的所有条目必须插入到一个类似的表 dummy3 中,每个记录必须有 3 个状态为 1、5 和 7 的条目。
mysql> desc dummy3;
+----------+----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+----------+------+-----+---------+-------+
| same_col | int | YES | | NULL | |
| value | char(15) | YES | | NULL | |
| status | smallint | YES | | NULL | |
+----------+----------+------+-----+---------+-------+
3 rows in set (0.02 sec)
要么创建一个与 dummy1 中条目一样多的插入查询脚本,要么使用交叉连接生成所需的结果集。
mysql> select * from dummy1
cross join
(select 1 union select 5 union select 7) T2
order by same_col;
+----------+------------+---+
| same_col | diff_col_1 | 1 |
+----------+------------+---+
| 1 | A | 1 |
| 1 | A | 5 |
| 1 | A | 7 |
| 2 | B | 1 |
| 2 | B | 5 |
| 2 | B | 7 |
| 3 | C | 1 |
| 3 | C | 5 |
| 3 | C | 7 |
+----------+------------+---+
9 rows in set (0.00 sec)
上述查询中的 T2 部分被称为子查询。我们将在下一节讨论同样的问题。
自然连接
这隐式地从表 A 和表 B 中选择公共列,并执行内部连接。
mysql> select e.emp_no,e.first_name,e.last_name,s.salary from employees e natural join salaries s limit 5;
+--------+------------+-----------+--------+
| emp_no | first_name | last_name | salary |
+--------+------------+-----------+--------+
| 10001 | Georgi | Facello | 60117 |
| 10001 | Georgi | Facello | 62102 |
| 10001 | Georgi | Facello | 66074 |
| 10001 | Georgi | Facello | 66596 |
| 10001 | Georgi | Facello | 66961 |
+--------+------------+-----------+--------+
5 rows in set (0.00 sec)
请注意,如果没有为查询显式选择列,自然连接和使用会注意到公共列只显示一次。
更多的例子
显示薪资> 80000 的员工的员工编号、薪资、职称和部门
mysql> select e.emp_no, s.salary, t.title, d.dept_no
from
employees e
join salaries s using (emp_no)
join titles t using (emp_no)
join dept_emp d using (emp_no)
where s.salary > 80000
limit 5;
+--------+--------+--------------+---------+
| emp_no | salary | title | dept_no |
+--------+--------+--------------+---------+
| 10017 | 82163 | Senior Staff | d001 |
| 10017 | 86157 | Senior Staff | d001 |
| 10017 | 89619 | Senior Staff | d001 |
| 10017 | 91985 | Senior Staff | d001 |
| 10017 | 96122 | Senior Staff | d001 |
+--------+--------+--------------+---------+
5 rows in set (0.00 sec)
按部门编号显示每个部门中按职位排序的员工数
mysql> select d.dept_no, t.title, count(*)
from titles t
left join dept_emp d using (emp_no)
group by d.dept_no, t.title
order by d.dept_no
limit 10;
+---------+--------------------+----------+
| dept_no | title | count(*) |
+---------+--------------------+----------+
| d001 | Manager | 2 |
| d001 | Senior Staff | 13940 |
| d001 | Staff | 16196 |
| d002 | Manager | 2 |
| d002 | Senior Staff | 12139 |
| d002 | Staff | 13929 |
| d003 | Manager | 2 |
| d003 | Senior Staff | 12274 |
| d003 | Staff | 14342 |
| d004 | Assistant Engineer | 6445 |
+---------+--------------------+----------+
10 rows in set (1.32 sec)
选择子查询
子查询通常是一个较小的结果集,可以用多种方式来支持选择查询。它可以用在“where”条件中,可以用来代替 join,大多数情况下,join 可能是多余的。这些子查询也称为派生表。它们在选择查询中必须有一个表别名。
让我们看一些子查询的例子。
这里,我们通过使用 dept_emp 表中的 dept_no 的子查询从 departments 表中获得了部门名称。
mysql> select e.emp_no,
(select dept_name from departments where dept_no=d.dept_no) dept_name from employees e
join dept_emp d using (emp_no)
limit 5;
+--------+-----------------+
| emp_no | dept_name |
+--------+-----------------+
| 10001 | Development |
| 10002 | Sales |
| 10003 | Production |
| 10004 | Production |
| 10005 | Human Resources |
+--------+-----------------+
5 rows in set (0.01 sec)
这里,我们使用上面的‘avg’查询(它获得了 avg salary)作为子查询,列出了最新薪金高于平均值的雇员。
mysql> select avg(salary) from salaries;
+-------------+
| avg(salary) |
+-------------+
| 63810.7448 |
+-------------+
1 row in set (0.80 sec)mysql> select e.emp_no, max(s.salary)
from employees e
natural join salaries s
group by e.emp_no
having max(s.salary) > (select avg(salary) from salaries)
limit 10;
+--------+---------------+
| emp_no | max(s.salary) |
+--------+---------------+
| 10001 | 88958 |
| 10002 | 72527 |
| 10004 | 74057 |
| 10005 | 94692 |
| 10007 | 88070 |
| 10009 | 94443 |
| 10010 | 80324 |
| 10013 | 68901 |
| 10016 | 77935 |
| 10017 | 99651 |
+--------+---------------+
10 rows in set (0.56 sec)
查询性能
原文:https://linkedin.github.io/school-of-sre/level101/databases_sql/query_performance/
查询性能调优
查询性能是关系数据库的一个非常重要的方面。如果没有正确调优,select 查询对于应用和 MySQL 服务器来说会变得缓慢而痛苦。重要的任务是识别速度慢的查询,并通过重写它们或在相关表上创建适当的索引来提高它们的性能。
慢速查询日志
慢速查询日志包含执行时间比配置参数 long_query_time 中设置的时间长的 SQL 语句。这些查询是优化的候选对象。有一些很好的工具可以总结慢速查询日志,如 mysqldumpslow(由 MySQL 自己提供)、pt-query-digest(由 Percona 提供)等。以下是用于启用和有效捕获慢速查询的配置参数
| 可变的 | 说明 | 示例值 |
|---|---|---|
| 慢速查询日志 | 启用或禁用慢速查询日志 | 在…上 |
| 慢速查询日志文件 | 慢速查询日志的位置 | /var/lib/mysql/mysql-slow.log |
| 长查询时间 | 阈值时间。耗时超过此时间的查询会记录在慢速查询日志中 | five |
| 日志查询未使用索引 | 当启用慢速查询日志时,不使用任何索引的查询也会记录在慢速查询日志中,即使它们花费的时间比 long_query_time 少。 | 在…上 |
因此,对于这一部分,我们将启用 slow_query_log , long_query_time 将保持为 0.3 (300 ms) ,并且 log_queries_not_using 索引也将启用。
下面是我们将在 employees 数据库上执行的查询。
- select * from employees where last _ name = ' Koblick ';
- select * from salaries,其中薪金> = 100000;
- select * from titles where title = ' Manager ';
- select * from employees where year(hire _ date)= 1995;
- select year(e.hire_date),max(s . salary from employees e join salary s on e . EMP _ no = s . EMP _ no group by year(e . hire _ date);
现在,查询 1 、 3 和 4 在 300 毫秒内执行,但是如果我们检查缓慢的查询日志,我们会发现这些查询被记录下来,因为它们没有使用任何索引。查询 2 和 5 耗时超过 300 毫秒,并且不使用任何索引。
使用以下命令获取慢速查询日志的摘要
mysqldumpslow /var/lib/mysql/mysql-slow.log

除了提到的查询之外,快照中还有其他一些查询。Mysqldumpslow 替换 N(对于数字)和 S(对于字符串)使用的实际值。这可以被-a选项覆盖,但是如果在类似的查询中使用不同的值,这将增加输出行。
解释计划
EXPLAIN 命令用于我们想要分析的任何查询。它描述了查询执行计划,MySQL 如何查看和执行查询。EXPLAIN 使用 Select、Insert、Update 和 Delete 语句。它讲述了查询的不同方面,例如,如何连接表,是否使用索引等。这里重要的是理解查询的基本解释计划输出,以确定其性能。
让我们以下面的查询为例,
mysql> explain select * from salaries where salary = 100000;
+----+-------------+----------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| 1 | SIMPLE | salaries | NULL | ALL | NULL | NULL | NULL | NULL | 2838426 | 10.00 | Using where |
+----+-------------+----------+------------+------+---------------+------+---------+------+---------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
以上输出中需要理解的关键方面是:-
- 分区 -执行查询时考虑的分区数量。只有当表被分区时,它才有效。
- Possible_keys -创建执行计划时考虑的索引列表。
- Key -执行查询时将使用的索引。
- Rows -执行过程中检查的行数。
- Filtered -被检查的行中被过滤掉的行的百分比。最大和最优化的结果在该字段中将有 100。
- Extra——这告诉我们一些关于 MySQL 如何评估的额外信息,查询是否只使用 where 子句来匹配目标行、任何索引或临时表等。
因此,对于上面的查询,我们可以确定没有分区,没有要使用的候选索引,因此根本没有使用索引,检查了超过 2M 的行,只有 10%的行包含在结果中,最后,只有 where 子句用于匹配目标行。
创建索引
索引用于加快为给定的列值选择相关行的速度。如果没有索引,MySQL 从第一行开始,遍历整个表来查找匹配的行。如果表中有太多的行,操作会变得很昂贵。有了索引,MySQL 就可以在不读取整个表的情况下确定开始查找数据的位置。
主键也是最快的索引,与表数据一起存储。辅助索引存储在表数据之外,用于进一步提高 SQL 语句的性能。索引大多存储为 B 树,但也有一些例外,比如空间索引使用 R 树,内存表使用散列索引。
创建索引有两种方法:-
- 当创建一个表时——如果我们预先知道在 select 查询中驱动 where 子句最多的列,那么我们可以在创建一个表时在它们上面放一个索引。
- 修改表——为了提高一个麻烦的查询的性能,我们使用 ALTER 或 CREATE INDEX 命令在一个已经有数据的表上创建一个索引。此操作不会阻塞表,但可能需要一些时间来完成,具体取决于表的大小。
让我们看一下我们在上一节中讨论的查询。很明显,扫描 2M 记录并不是一个好主意,因为只有 10%的记录在结果集中。
因此,我们在 sales 表的 salary 列上创建了一个索引。
create index idx_salary on salaries(salary)
运筹学
alter table salaries add index idx_salary(salary)
同样的解释计划现在看起来像这样
mysql> explain select * from salaries where salary = 100000;
+----+-------------+----------+------------+------+---------------+------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | salaries | NULL | ref | idx_salary | idx_salary | 4 | const | 13 | 100.00 | NULL |
+----+-------------+----------+------------+------+---------------+------------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
现在使用的索引是 idx_salary,我们最近创建的那个。该索引实际上只帮助检查了 13 条记录,并且它们都在结果集中。此外,查询执行时间也从 700 毫秒以上减少到几乎可以忽略不计。
让我们看另一个例子。我们在这里搜索名和姓的特定组合。但是,我们也可以只根据姓氏进行搜索。
mysql> explain select * from employees where last_name = 'Dredge' and first_name = 'Yinghua';
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | employees | NULL | ALL | NULL | NULL | NULL | NULL | 299468 | 1.00 | Using where |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
现在,在近 30 万条记录中,只有 1%是结果集。虽然查询时间特别快,因为我们只有 30 万条记录,但如果记录的数量超过数百万,这将是一个痛苦。在这种情况下,我们在 last_name 和 first_name 上创建一个索引,不是单独创建,而是创建一个包含这两个列的复合索引。
create index idx_last_first on employees(last_name, first_name)
mysql> explain select * from employees where last_name = 'Dredge' and first_name = 'Yinghua';
+----+-------------+-----------+------------+------+----------------+----------------+---------+-------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+----------------+----------------+---------+-------------+------+----------+-------+
| 1 | SIMPLE | employees | NULL | ref | idx_last_first | idx_last_first | 124 | const,const | 1 | 100.00 | NULL |
+----+-------------+-----------+------------+------+----------------+----------------+---------+-------------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
我们选择在创建索引时将姓氏放在名字之前,因为优化器在评估查询时从索引最左边的前缀开始。例如,如果我们有一个像 idx(c1,c2,c3)这样的 3 列索引,那么该索引的搜索能力如下- (c1),(c1,c2)或(c1,c2,c3),也就是说,如果 where 子句只有 first_name,则该索引不起作用。
mysql> explain select * from employees where first_name = 'Yinghua';
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | employees | NULL | ALL | NULL | NULL | NULL | NULL | 299468 | 10.00 | Using where |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
但是,如果 where 子句中只有 last_name,它将按预期工作。
mysql> explain select * from employees where last_name = 'Dredge';
+----+-------------+-----------+------------+------+----------------+----------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+----------------+----------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | employees | NULL | ref | idx_last_first | idx_last_first | 66 | const | 200 | 100.00 | NULL |
+----+-------------+-----------+------------+------+----------------+----------------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
再举一个例子,使用以下查询:-
create table employees_2 like employees;
create table salaries_2 like salaries;
alter table salaries_2 drop primary key;
为了理解 Select with Join 的示例,我们复制了 employees 和 salary 表,但没有 salary 表的主键。
当您有类似下面的查询时,识别查询的难点就变得很棘手。
mysql> select e.first_name, e.last_name, s.salary, e.hire_date from employees_2 e join salaries_2 s on e.emp_no=s.emp_no where e.last_name='Dredge';
1860 rows in set (4.44 sec)
这个查询大约需要 4.5 秒来完成,结果集中有 1860 行。让我们看看解释计划。解释计划中将有 2 条记录,因为查询中使用了 2 个表。
mysql> explain select e.first_name, e.last_name, s.salary, e.hire_date from employees_2 e join salaries_2 s on e.emp_no=s.emp_no where e.last_name='Dredge';
+----+-------------+-------+------------+--------+------------------------+---------+---------+--------------------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+--------+------------------------+---------+---------+--------------------+---------+----------+-------------+
| 1 | SIMPLE | s | NULL | ALL | NULL | NULL | NULL | NULL | 2837194 | 100.00 | NULL |
| 1 | SIMPLE | e | NULL | eq_ref | PRIMARY,idx_last_first | PRIMARY | 4 | employees.s.emp_no | 1 | 5.00 | Using where |
+----+-------------+-------+------------+--------+------------------------+---------+---------+--------------------+---------+----------+-------------+
2 rows in set, 1 warning (0.00 sec)
这些是按评估顺序进行的,即首先评估 salaries _ 2,然后将 employees_2 加入其中。看起来,它扫描了 salaries _ 2 表中几乎所有的行,并尝试按照连接条件匹配 employees_2 行。虽然在获取最终结果集时使用了 where 子句,但是对应于 where 子句的索引没有用于 employees_2 表。
如果连接是在两个具有相同数据类型的索引上完成的,那么它总是更快。因此,让我们在 salaries _ 2 表的 emp_no 列上创建一个索引,并再次分析该查询。
create index idx_empno on salaries_2(emp_no);
mysql> explain select e.first_name, e.last_name, s.salary, e.hire_date from employees_2 e join salaries_2 s on e.emp_no=s.emp_no where e.last_name='Dredge';
+----+-------------+-------+------------+------+------------------------+----------------+---------+--------------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+------------------------+----------------+---------+--------------------+------+----------+-------+
| 1 | SIMPLE | e | NULL | ref | PRIMARY,idx_last_first | idx_last_first | 66 | const | 200 | 100.00 | NULL |
| 1 | SIMPLE | s | NULL | ref | idx_empno | idx_empno | 4 | employees.e.emp_no | 9 | 100.00 | NULL |
+----+-------------+-------+------------+------+------------------------+----------------+---------+--------------------+------+----------+-------+
2 rows in set, 1 warning (0.00 sec)
现在,索引不仅帮助优化器只检查两个表中的几行,还颠倒了评估中表的顺序。首先计算 employees_2 表,并根据 where 子句的索引选择行。然后根据连接条件使用的索引将记录连接到 salaries _ 2 表。查询的执行时间从 4.5 秒下降到 0.02 秒。
mysql> select e.first_name, e.last_name, s.salary, e.hire_date from employees_2 e join salaries_2 s on e.emp_no=s.emp_no where e.last_name='Dredge'\G
1860 rows in set (0.02 sec)
并集
原文:https://linkedin.github.io/school-of-sre/level101/databases_sql/lab/
先决条件
安装 Docker
设置
创建一个名为 sos 或类似名称的工作目录,并放入 cd。
在 custom 目录下的 my.cnf 文件中输入以下内容。
sos $ cat custom/my.cnf
[mysqld]
# These settings apply to MySQL server
# You can set port, socket path, buffer size etc.
# Below, we are configuring slow query settings
slow_query_log=1
slow_query_log_file=/var/log/mysqlslow.log
long_query_time=1
使用以下命令启动容器并启用慢速查询日志:
sos $ docker run --name db -v custom:/etc/mysql/conf.d -e MYSQL_ROOT_PASSWORD=realsecret -d mysql:8
sos $ docker cp custom/my.cnf $(docker ps -qf "name=db"):/etc/mysql/conf.d/custom.cnf
sos $ docker restart $(docker ps -qf "name=db")
导入示例数据库
sos $ git clone git@github.com:datacharmer/test_db.git
sos $ docker cp test_db $(docker ps -qf "name=db"):/home/test_db/
sos $ docker exec -it $(docker ps -qf "name=db") bash
root@3ab5b18b0c7d:/# cd /home/test_db/
root@3ab5b18b0c7d:/# mysql -uroot -prealsecret mysql < employees.sql
root@3ab5b18b0c7d:/etc# touch /var/log/mysqlslow.log
root@3ab5b18b0c7d:/etc# chown mysql:mysql /var/log/mysqlslow.log
研讨会 1:运行一些示例查询运行以下内容
$ mysql -uroot -prealsecret mysql
mysql># inspect DBs and tables
# the last 4 are MySQL internal DBsmysql> show databases;
+--------------------+
| Database |
+--------------------+
| employees |
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+> use employees;
mysql> show tables;
+----------------------+
| Tables_in_employees |
+----------------------+
| current_dept_emp |
| departments |
| dept_emp |
| dept_emp_latest_date |
| dept_manager |
| employees |
| salaries |
| titles |
+----------------------+# read a few rows
mysql> select * from employees limit 5;# filter data by conditions
mysql> select count(*) from employees where gender = 'M' limit 5;# find count of particular data
mysql> select count(*) from employees where first_name = 'Sachin';
研讨会 2:使用解释和解释分析来分析查询,确定并添加提高性能所需的索引
# View all indexes on table
#(\G is to output horizontally, replace it with a ; to get table output)
mysql> show index from employees from employees\G
*************************** 1\. row ***************************Table: employeesNon_unique: 0Key_name: PRIMARYSeq_in_index: 1Column_name: emp_noCollation: ACardinality: 299113Sub_part: NULLPacked: NULLNull:Index_type: BTREEComment:
Index_comment:Visible: YESExpression: NULL# This query uses an index, idenitfied by 'key' field
# By prefixing explain keyword to the command,
# we get query plan (including key used)
mysql> explain select * from employees where emp_no < 10005\G
*************************** 1\. row ***************************id: 1select_type: SIMPLEtable: employeespartitions: NULLtype: range
possible_keys: PRIMARYkey: PRIMARYkey_len: 4ref: NULLrows: 4filtered: 100.00Extra: Using where# Compare that to the next query which does not utilize any index
mysql> explain select first_name, last_name from employees where first_name = 'Sachin'\G
*************************** 1\. row ***************************id: 1select_type: SIMPLEtable: employeespartitions: NULLtype: ALL
possible_keys: NULLkey: NULLkey_len: NULLref: NULLrows: 299113filtered: 10.00Extra: Using where# Let's see how much time this query takes
mysql> explain analyze select first_name, last_name from employees where first_name = 'Sachin'\G
*************************** 1\. row ***************************
EXPLAIN: -> Filter: (employees.first_name = 'Sachin') (cost=30143.55 rows=29911) (actual time=28.284..3952.428 rows=232 loops=1)-> Table scan on employees (cost=30143.55 rows=299113) (actual time=0.095..1996.092 rows=300024 loops=1)# Cost(estimated by query planner) is 30143.55
# actual time=28.284ms for first row, 3952.428 for all rows
# Now lets try adding an index and running the query again
mysql> create index idx_firstname on employees(first_name);
Query OK, 0 rows affected (1.25 sec)
Records: 0 Duplicates: 0 Warnings: 0mysql> explain analyze select first_name, last_name from employees where first_name = 'Sachin';
+--------------------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+--------------------------------------------------------------------------------------------------------------------------------------------+
| -> Index lookup on employees using idx_firstname (first_name='Sachin') (cost=81.20 rows=232) (actual time=0.551..2.934 rows=232 loops=1)|
+--------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.01 sec)# Actual time=0.551ms for first row
# 2.934ms for all rows. A huge improvement!
# Also notice that the query involves only an index lookup,
# and no table scan (reading all rows of table)
# ..which vastly reduces load on the DB.
研讨会 3:识别 MySQL 服务器上的慢速查询
# Run the command below in two terminal tabs to open two shells into the container.
docker exec -it $(docker ps -qf "name=db") bash# Open a mysql prompt in one of them and execute this command
# We have configured to log queries that take longer than 1s,
# so this sleep(3) will be logged
mysql -uroot -prealsecret mysql
mysql> select sleep(3);# Now, in the other terminal, tail the slow log to find details about the query
root@62c92c89234d:/etc# tail -f /var/log/mysqlslow.log
/usr/sbin/mysqld, Version: 8.0.21 (MySQL Community Server - GPL). started with:
Tcp port: 3306 Unix socket: /var/run/mysqld/mysqld.sock
Time Id Command Argument
# Time: 2020-11-26T14:53:44.822348Z
# User@Host: root[root] @ localhost [] Id: 9
# Query_time: 5.404938 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 1
use employees;
# Time: 2020-11-26T14:53:58.015736Z
# User@Host: root[root] @ localhost [] Id: 9
# Query_time: 10.000225 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 1
SET timestamp=1606402428;
select sleep(3);
这些是最简单的模拟例子。在现实生活中,查询会更加复杂,解释/分析和慢速查询日志会有更多的细节。