- 名词缩写
- ASID:Address Space ID 地址空间标识符
- CD:Context Descriptor; 上下文描述符;
- CTP:Context-table pointer 上下文表指针
- EPT:Extended Page Table 扩展页表
- GPA:Guest Phyical Address 客人的实际地址
- GVA:Guest Virtual Address 访客虚拟地址
- HPA:Host Phyical Address 主机物理地址
- NPT:Nested Page Table 嵌套页表
- PCID:Process context identifier 进程上下文标识符
- PMCG:Performance Monitor Counter Groups 性能监控计数器组
- S2TTB:Stage 2 Translate Table Base 第二阶段翻译表库
- SMMU:System MMU 系统MMU
- VT-d:Virtualization Technology for Direct I/O 直接I/O虚拟化技术
- SMMU:System MMU 系统MMU
- VT-d:Virtualization Technology for Direct I/O 直接I/O虚拟化技术
关键要点
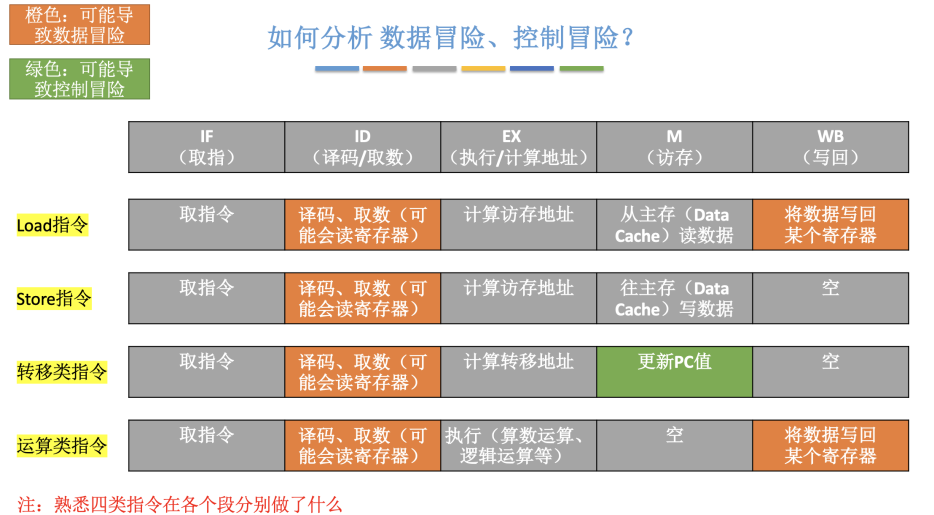
- MMU地址翻译是将进程的虚拟地址(HVA)翻译成物理地址(HPA);
- IOMMU地址翻译则是将虚拟机物理地址空间内的GPA翻译成HPA;
- IOMMU页表和MMU页表一样,都采用了多级页表的方式来进行翻译;
- 专门转换I/O地址的MMU在x86的阵营里就是IOMMU;
- Intel把IOMMU技术叫做VT-d(Virtualization Technology for Direct I/O);
- EPT/NPT MMU作为传统MMU的扩展,也是有TLB;
- ARM公司主要是依靠出售core的license来赚钱的;
- 能够有能力完成设备iova 到 pa转换的有很多,例如有intel iommu, amd的iommu ,arm的smmu等等;
VT-d DMA Remapping
https://kernelgo.org/dma-remapping.html
《搞懂Linux零拷贝,DMA》https://rtoax.blog.csdn.net/article/details/108825666
本文主要探讨一下VT-d DMA Remapping机制。在分析DMA Remapping之前回顾下什么是DMA,DMA是指在不经过CPU干预的情况下外设直接访问(Read/Write)主存(System Memroy)的能力。 DMA带来的最大好处是:CPU不再需要干预外设对内存的访问过程,而是可以去做其他的事情,这样就大大提高了CPU的利用率。
在设备直通(Device Passthough)的虚拟化场景下,直通设备在工作的时候同样要使用DMA技术来访问虚拟机的主存以提升IO性能。那么问题来了,直接分配给某个特定的虚拟机的,我们必须要保证直通设备DMA的安全性,一个VM的直通设备不能通过DMA访问到其他VM的内存,同时也不能直接访问Host的内存,否则会造成极其严重的后果。因此,必须对直通设备进行“DMA隔离”和“DMA地址翻译”,隔离将直通设备的DMA访问限制在其所在VM的物理地址空间内保证不发生访问越界,地址翻译则保证了直通设备的DMA能够被正确重定向到虚拟机的物理地址空间内。
为什么直通设备会存在DMA访问的安全性问题呢?
原因也很简单:由于直通设备进行DMA操作的时候guest驱动直接使用gpa来访问内存的,这就导致如果不加以隔离和地址翻译必然会访问到其他VM的物理内存或者破坏Host内存,因此必须有一套机制能够将gpa转换为对应的hpa这样直通设备的DMA操作才能够顺利完成。
VT-d DMA Remapping的引入就是为了解决直通设备DMA隔离和DMA地址翻译的问题,下面我们将对其原理进行分析,主要参考资料是Intel VT-d SPEC Chapter 3。
1 DMA Remapping 简介
VT-d DMA Remapping的硬件能力主要是由IOMMU来提供,通过引入根Context Entry和IOMMU Domain Page Table等机制来实现直通设备*隔离和DMA地址转换的目的。那么具体是怎样实现的呢?下面将对其进行介绍。
根据DMA Request是否包含地址空间标志(address-space-identifier)我们将DMA Request分为2类:
-
Requests without address-space-identifier: 不含地址空间标志的DMA Request,这种一般是endpoint devices的普通请求,请求内容仅包含请求的类型(read/write/atomics),DMA请求的address/size以及请求设备的标志符等。
-
Requests with address-space-identifier: 包含地址空间描述标志的DMA Request,此类请求需要包含额外信息以提供目标进程的地址空间标志符(PASID),以及Execute-Requested (ER) flag和 Privileged-mode-Requested 等细节信息。
在DMA(直接内存访问)请求中,包含地址空间描述标志与不包括地址空间描述标志的请求之间的区别主要涉及到内存访问的管理和数据传输的方式。
1. 包含地址空间描述标志的DMA Request
这种DMA请求通常包含明确的地址空间信息,用于标识数据在内存中的具体位置。地址空间描述标志(如IOMMU标志)在请求中指定了内存访问权限和内存的虚拟到物理地址的映射。这种情况下:
- 地址映射:内存地址可能是虚拟地址或I/O地址,需要通过地址空间描述标志进行转换才能找到实际的物理内存位置。
- 安全性和隔离:包含地址空间描述标志的DMA请求通常用于系统需要保证内存访问的安全性,防止恶意或错误的内存访问。
- 复杂性:由于需要进行地址转换和权限检查,这种请求的处理可能较为复杂,但提供了更强的内存管理能力。
2. 不包括地址空间描述标志的DMA Request
这种请求直接使用物理地址,不涉及复杂的地址映射或权限管理。这种情况下:
- 地址直接访问:DMA控制器直接访问指定的物理内存地址,不需要任何地址转换。
- 性能:由于没有地址转换的开销,数据传输可能更快,延迟更低。
- 安全性和隔离较低:这种请求通常用于信任的内存区域,因为它没有额外的安全检查,可能会导致内存访问的风险。
为了简单,通常称上面两类DMA请求简称为:Requests-without-PASID和Requests-with-PASID。本节我们只讨论Requests-without-PASID,后面我们会在讨论Shared Virtual Memory的文中单独讨论Requests-with-PASID。
首先要明确的是DMA Isolation是以Domain为单位进行隔离的,在虚拟化环境下可以认为每个VM的地址空间为一个Domain,直通给这个VM的设备只能访问这个VM的地址空间这就称之为“隔离”。根据软件的使用模型不同,直通设备的DMA Address Space可能是某个VM的Guest Physical Address Space或某个进程的虚拟地址空间(由分配给进程的PASID定义)或是由软件定义的一段抽象的IO Virtual Address space (IOVA),总之DMA Remapping就是要能够将设备发起的DMA Request进行DMA Translation重映射到对应的HPA上。
下面的图描述了DMA Translation的原理,这和MMU将虚拟地址翻译成物理地址的过程非常的类似。

值得一提的是,Host平台上可能会存在一个或者多个DMA Remapping硬件单元,而每个硬件单元支持在它管理的设备范围内的所有设备的DMA Remapping。例如,你的台式机CPU Core i7 7700k在MCH中只集成一个DMA Remapping硬件单元(IOMMU),但在多路服务器上可能集成有多个DMA Remapping硬件单元。每个硬件单元负责管理挂载到它所在的PCIe Root Port下所有设备的DMA请求。BIOS会将平台上的DMA Remapping硬件信息通过ACPI协议报告给操作系统,再由操作系统来初始化和管理这些硬件设备。
为了实现DMA隔离,我们需要对直通设备进行标志,而这是通过PCIe的Request ID来完成的。根据PCIe的SPEC,每个PCIe设备的请求都包含了PCI Bus/Device/Function信息,通过BDF号我们可以唯一确定一个PCIe设备。

同时为了能够记录直通设备和每个Domain的关系,VT-d引入了root-entry/context-entry的概念,通过查询root-entry/context-entry表就可以获得直通设备和Domain之间的映射关系。

Root-table是一个4K页,共包含了256项root-entry,分别覆盖了PCI的Bus0-255,每个root-entry占16-Byte,记录了当前PCI Bus上的设备映射关系,通过PCI Bus Number进行索引。
Root-table的基地址存放在Root Table Address Register当中。Root-entry中记录的关键信息有:
- Present Flag:代表着该Bus号对应的Root-Entry是否呈现,CTP域是否初始化;
- Context-table pointer (CTP):CTP记录了当前Bus号对应点Context Table的地址。
同样每个context-table也是一个4K页,记录一个特定的PCI设备和它被分配的Domain的映射关系,即对应Domain的DMA地址翻译结构信息的地址。个root-entry包含了该Bus号对应的context-table指针,指向一个context-table,而每张context-table包又含256个context-entry, 其中每个entry对应了一个Device Function号所确认的设备的信息。通过2级表项的查询我们就能够获得指定PCI被分配的Domain的地址翻译结构信息。Context-entry中记录的信息有:
-
Present Flag:表示该设备对应的context-entry是否被初始化,如果当前平台上没有该设备Preset域为0,索引到该设备的请求也会被block掉。
-
Translation Type:表示哪种请求将被允许;
-
Address Width:表示该设备被分配的Domain的地址宽度;
-
Second-level Page-table Pointer:二阶页表指针提供了DMA地址翻译结构的HPA地址(这里仅针对Requests-without-PASID而言);
-
Domain Identifier: Domain标志符表示当前设备的被分配到的Domain的标志,硬件会利用此域来标记context-entry cache,这里有点类似VPID的意思;
-
Fault Processing Disable Flag:此域表示是否需要选择性的disable此entry相关的remapping faults reporting。
因为多个设备有可能被分配到同一个Domain,这时只需要将其中每个设备context-entry项的 Second-level Page-table Pointer 设置为对同一个Domain的引用, 并将Domain ID赋值为同一个Domian的就行了。
2 DMA隔离和地址翻译
VT-d中引入root-table和context-table的目的比较明显,这些额外的table的存在就是为了记录每个直通设备和其被分配的Domain之间的映射关系。 有了这个映射关系后,DMA隔离的实现就变得非常简单。
IOMMU硬件会截获直通设备发出的请求,然后根据其Request ID查表找到对应的Address Translation Structure即该Domain的IOMMU页表基地址,这样一来该设备的DMA地址翻译就只会按这个Domain的IOMMU页表的方式进行翻译,翻译后的HPA必然落在此Domain的地址空间内(这个过程由IOMMU硬件中自动完成), 而不会访问到其他Domain的地址空间,这样就达到了DMA隔离的目的。
DMA地址翻译的过程和虚拟地址翻译的过程是完全一致的,唯一不同的地方在于MMU地址翻译是将进程的虚拟地址(HVA)翻译成物理地址(HPA),而IOMMU地址翻译则是将虚拟机物理地址空间内的GPA翻译成HPA。IOMMU页表和MMU页表一样,都采用了多级页表的方式来进行翻译。例如,对于一个48bit的GPA地址空间的Domain而言,其IOMMU Page Table共分4级,每一级都是一个4KB页含有512个8-Byte的目录项。和MMU页表一样,IOMMU页表页支持2M/1G大页内存,同时硬件上还提供了IO-TLB来缓存最近翻译过的地址来提升地址翻译的速度。
IOVA:IO Virtual Address space IO虚拟地址空间
CTP:Context-table pointer 上下文表指针
GPA:Guest Phyical Address 客人的实际地址
GVA:Guest Virtual Address 访客虚拟地址
HPA:Host Phyical Address 主机物理地址
IPA:Intermediate Phyical Address 中间物理地址

Related Posts
- VT-d Interrupt Remapping
- VT-d Posted Interrupt
- VFIO Introduction
- VT-d Interrupt Remapping Code Analysis
- VIM8 Customized Configuration
- Article Archive 2019 Reading Plan
- Virtio Spec Overview
虚拟化技术 - I/O虚拟化
https://zhuanlan.zhihu.com/p/69627614

在虚拟化系统中,I/O外设只有一套,需要被多个guest VMs共享。VMM/hypervisor提供了两种机制来实现对I/O设备的访问,一种是透传(passthrough),一种是模拟(emulation)。
透传 - Device Passthrough
所谓passthrough,就是指guest VM可以透过VMM,直接访问I/O硬件,这样guest VM的I/O操作路径几乎和无虚拟化环境下的I/O路径相同,性能自然是非常高的。

在虚拟化环境下,guest VM使用的物理地址是GPA(参考这篇文章《[虚拟化技术 - 内存虚拟化 一]》),如果直接用guest OS中的驱动程序去操作I/O设备的话(这里的I/O限定于和内存统一编址的MMIO),那么设备使用的地址也是GPA。这倒不难办,使用CPU的EPT/NPT MMU查询对应guest VM的nPT页表,进行一下GPA->HPA的转换就可以了。
注释
-
IOVA:IO Virtual Address space IO虚拟地址空间
-
CTP:Context-table pointer 上下文表指针
-
GPA:Guest Phyical Address 客人的实际地址
-
GVA:Guest Virtual Address 访客虚拟地址
-
HPA:Host Phyical Address 主机物理地址
-
IPA:Intermediate Phyical Address 中间物理地址
可是别忘了,有一些I/O设备是具备DMA(Direct Memory Access)功能的。由于DMA是直接在设备和物理内存之间传输数据,必须使用实际的物理地址(也就是HPA),但DMA本身是为了减轻CPU的处理负担而存在的,其传输过程并不经过CPU。对于一个支持DMA传输的设备,当它拿着GPA去发起DMA操作时,由于没有真实的物理内存地址,传输势必会失败。
那如何实现对进行DMA传输的设备的GPA->HPA转换呢?再来一个类似于EPT/NPT的MMU?没错,这种专门转换I/O地址的MMU在x86的阵营里就是IOMMU。
然而,不和AMD使用相同的名字是Intel一贯的路数,所以Intel通常更愿意把这种硬件辅助的I/O虚拟化技术叫做VT-d(Virtualization Technology for Direct I/O)。作为后起之秀的ARM自然也不甘示弱,推出了对应的SMMU(System MMU)。

IOMMU查找的页表通常是专门的I/O page tables。既然都是进行GPA->HPA的转换,为什么不和EPT/NPT MMU共享nPT页表呢?这个问题将在接下来的文章中给出解答。为了加速查找过程,IOMMU中也有类似于EPT/NPT TLB的IOTLB硬件单元。
以Intel的VT-d为例,它规定了一个domain对应一个IO页表。在具体的实现中,通常是一个guest VM作为一个domain,因此分配给同一个guest VM的设备将共享同一个IO页表。
这里为了支持device passthrough(透传)模式下的DMA传输,IOMMU进行的是GPA->HPA的转换。既然EPT/NPT MMU都可以同时支持GVA->GPA和GPA->HPA的转换,那IOMMU是否也可以呢?这个问题也将留在后续的文章中讨论。
Device passthrough(透传)机制要求VMM为guest VM分配好设备,并提供隔离。假设系统中现在有三个guest VMs,编号分别是0, 1, 2,如果VM 0分配到了网卡A,就要阻止VM 1和VM 2对网卡A的访问。
可以采用的方法是在拥有设备的guest VM加载驱动程序前,先给要分配出去的设备加载一个伪驱动作为占位符,由于没有真正的驱动程序,这个设备对于其他的guest VM来说就相当于是“隐藏”了。
这同时也暴露了使用device passthrough存在的一个问题,就是同一个I/O设备通常无法在不同的guest VM之间实现共享和动态迁移(比如PCI设备的热插拔)。下文将介绍的device emulation机制将可以解决设备共享和迁移的问题。
虚拟化技术 - 内存虚拟化
https://zhuanlan.zhihu.com/p/69828213
-
IOVA:IO Virtual Address space IO虚拟地址空间
-
CTP:Context-table pointer 上下文表指针
-
GPA:Guest Phyical Address 客人的实际地址
-
GVA:Guest Virtual Address 访客虚拟地址
-
HPA:Host Phyical Address 主机物理地址
-
IPA:Intermediate Phyical Address 中间物理地址
-
VT-d:Virtualization Technology for Direct I/O
-
SMMU:System MMU
大型操作系统(比如Linux)的内存管理的内容是很丰富的,而内存的虚拟化技术在OS内存管理的基础上又叠加了一层复杂性,比如我们常说的虚拟内存(virtual memory),如果使用虚拟内存的OS是运行在虚拟机中的,那么需要对虚拟内存再进行虚拟化,也就是vitualizing virtualized memory。本文将仅从“内存地址转换”和“内存回收”两个方面探讨内存虚拟化技术。
【虚拟机内存地址转换】
在Linux这种使用虚拟地址的OS中,虚拟地址经过page table转换可得到物理地址(参考这篇文章,当然,我们可以在用空间完成这种在转化《Linux用户空间将虚拟地址转化为物理地址》):

如果这个操作系统是运行在虚拟机上的,那么这只是一个中间的物理地址(Intermediate Phyical Address - IPA),需要经过VMM/hypervisor的转换,才能得到最终的物理地址(Host Phyical Address - HPA)。。从VMM的角度,guest VM中的虚拟地址就成了GVA(Guest Virtual Address),IPA就成了GPA(Guest Phyical Address)。

可见,如果使用VMM,并且guest VM中的程序使用虚拟地址(如果guest VM中运行的是不支持虚拟地址的RTOS,则在虚拟机层面不需要地址转换),那么就需要两次地址转换。

但是传统的IA32架构从硬件上只支持一次地址转换,即由CR3寄存器指向进程第一级页表的首地址,通过MMU查询进程的各级页表,获得物理地址。
软件实现 - 影子页表
为了支持GVA->GPA->HPA的两次转换,可以计算出GVA->HPA的映射关系,将其写入一个单独的影子页表(sPT - shadow Page Table)。在一个运行Linux的guest VM中,每个进程有一个由内核维护的页表,用于GVA->GPA的转换,这里我们把它称作gPT(guest Page Table)。
VMM层的软件会将gPT本身使用的物理页面设为write protected的,那么每当gPT有变动的时候(比如添加或删除了一个页表项),就会产生被VMM截获的page fault异常,之后VMM需要重新计算GVA->HPA的映射,更改sPT中对应的页表项。
可见,这种纯软件的方法虽然能够解决问题,但是其存在两个缺点:
- 实现较为复杂,需要为每个guest VM中的每个进程的gPT都维护一个对应的sPT,增加了内存的开销。
- VMM使用的截获方法增多了page fault和trap/vm-exit的数量,加重了CPU的负担。
在一些场景下,这种影子页表机制造成的开销可以占到整个VMM软件负载的75%。

硬件辅助 - EPT/NPT
为此,各大CPU厂商相继推出了硬件辅助的内存虚拟化技术,比如Intel的EPT(Extended Page Table)和AMD的NPT(Nested Page Table),它们都能够从硬件上同时支持GVA->GPA和GPA->HPA的地址转换的技术。
GVA->GPA的转换依然是通过查找gPT页表完成的,而GPA->HPA的转换则通过查找nPT页表来实现,每个guest VM有一个由VMM维护的nPT。其实,EPT/NPT就是一种扩展的MMU(以下称EPT/NPT MMU),它可以交叉地查找gPT和nPT两个页表:

假设gPT和nPT都是4级页表,那么EPT/NPT MMU完成一次地址转换的过程是这样的(不考虑TLB):
首先它会查找guest VM中CR3寄存器(gCR3)指向的PML4页表,由于gCR3中存储的地址是GPA,因此CPU需要查找nPT来获取gCR3的GPA对应的HPA。nPT的查找和前面文章讲的页表查找方法是一样的,这里我们称一次nPT的查找过程为一次nested walk。
-
IOVA:IO Virtual Address space IO虚拟地址空间
-
CTP:Context-table pointer 上下文表指针
-
GPA:Guest Phyical Address 客人的实际地址
-
GVA:Guest Virtual Address 访客虚拟地址
-
HPA:Host Phyical Address 主机物理地址
-
IPA:Intermediate Phyical Address 中间物理地址

如果在nPT中没有找到,则产生EPT violation异常(可理解为VMM层的page fault)。如果找到了,也就是获得了PML4页表的物理地址后,就可以用GVA中的bit位子集作为PML4页表的索引,得到PDPE页表的GPA。接下来又是通过一次nested walk进行PDPE页表的GPA->HPA转换,然后重复上述过程,依次查找PD和PE页表,最终获得该GVA对应的HPA。

不同于影子页表是一个进程需要一个sPT,EPT/NPT MMU解耦了GVA->GPA转换和GPA->HPA转换之间的依赖关系,一个VM只需要一个nPT,减少了内存开销。如果guest VM中发生了page fault,可直接由guest OS处理,不会产生vm-exit,减少了CPU的开销。可以说,EPT/NPT MMU这种硬件辅助的内存虚拟化技术解决了纯软件实现存在的两个问题。
EPT/NPT MMU优化
事实上,EPT/NPT MMU作为传统MMU的扩展,自然也是有TLB(《Linux内存管理:转换后备缓冲区(TLB)原理》)的,它在查找gPT和nPT之前,会先去查找自己的TLB(前面为了描述的方便省略了这一步)。但这里的TLB存储的并不是一个GVA->GPA的映射关系,也不是一个GPA->HPA的映射关系,而是最终的转换结果,也就是GVA->HPA的映射。
不同的进程可能会有相同的虚拟地址,为了避免进程切换的时候flush所有的TLB,可通过给TLB entry加上一个标识进程的PCID/ASID(ASID(Address Space ID))的tag来区分(参考这篇文章,或者这篇《Linux内存管理:转换后备缓冲区(TLB)原理》如何管理ASID小节)。同样地,不同的guest VM也会有相同的GVA,为了flush的时候有所区分,需要再加上一个标识虚拟机的tag,这个tag在ARM体系中被叫做VMID,在Intel体系中则被叫做VPID。
PS:
ASID:Address Space ID 地址空间标识符
PCID:Process context identifier 进程上下文标识符PCID(进程上下文标识符)是在Westmere架构引入的新特性。简单来说,在此之前,TLB是单纯的VA到PA的转换表,进程1和进程2的VA对应的PA不同,不能放在一起。加上PCID后,转换变成VA + 进程上下文ID到PA的转换表,放在一起完全没有问题了。这样进程1和进程2的页表可以和谐的在TLB中共处,进程在它们之前切换完全不需要预热了!

在最坏的情况下(也就是TLB完全没有命中),gPT中的每一级转换都需要一次nested walk【1】,而每次nested walk需要4次内存访问,因此5次nested walk总共需要 (4+1)*5-1=24 次内存访问(就像一个5x5的二维矩阵一样):

虽然这24次内存访问都是由硬件自动完成的,不需要软件的参与,但是内存访问的速度毕竟不能与CPU的运行速度同日而语,而且内存访问还涉及到对总线的争夺,次数自然是越少越好。
要想减少内存访问次数,要么是增大EPT/NPT TLB的容量,增加TLB的命中率,要么是减少gPT和nPT的级数。gPT是为guest VM中的进程服务的,通常采用4KB粒度的页,那么在64位系统下使用4级页表是非常合适的(参考这篇文章)。
而nPT是为guset VM服务的,对于划分给一个VM的内存,粒度不用太小。64位的x86_64支持2MB和1GB的large page,假设创建一个VM的时候申请的是2G物理内存,那么只需要给这个VM分配2个1G的large pages就可以了(这2个large pages不用相邻,但large page内部的物理内存是连续的),这样nPT只需要2级(nPML4和nPDPE)。
如果现在物理内存中确实找不到2个连续的1G内存区域,那么就退而求其次,使用2MB的large page,这样nPT就是3级(nPML4, nPDPE和nPD)。
下文将介绍从guest VM回收内存的技术。
注【1】:这里区分一个英文表达,stage和level,查找gPT的转换过程被称作stage 1,查找nPT的转换过程被称作stage 2,而gPT和nPT自身都是由multi-level的页表组成。
SMMU和IOMMU技术
https://zhuanlan.zhihu.com/p/75978422
https://zhuanlan.zhihu.com/p/76643300

前面的文章讲到了为支持I/O透传机制中的DMA设备传输而引入的IOMMU/SMMU技术,同时留了一个问题:IOMMU/SMMU是否可以同时支持GVA->GPA和GPA->HPA的转换?答案是Yes。
既然在虚拟化的环境中,DMA设备可以借助GPA->HPA的转换,绕过VMM,实现与guest VM中OS的直接数据传递。那在非虚拟化的环境中,DMA设备也可以借助GVA->GPA的转换,绕过OS kernel,实现与userspace(用户空间)的进程的直接交互,这种用法就是用户空间的DMA传输。
两者其实是统一的,不管是GVA还是GPA,说到底都是虚拟地址,有了IOMMU/SMMU之后,DMA就可以使用虚拟地址作为传输的目标地址了。

ARM的SMMU
那IOMMU/SMMU具体应该如何使用呢?本文将主要以ARM的SMMU为例,讲解其转换地址的过程。
- MMU地址翻译是将进程的虚拟地址(HVA)翻译成物理地址(HPA);
- IOMMU地址翻译则是将虚拟机物理地址空间内的GPA翻译成HPA;
- IOMMU页表和MMU页表一样,都采用了多级页表的方式来进行翻译;
- 专门转换I/O地址的MMU在x86的阵营里就是IOMMU;
- Intel把IOMMU技术叫做VT-d(Virtualization Technology for Direct I/O);
- EPT/NPT MMU作为传统MMU的扩展,也是有TLB;
在Linux的实现中,一个进程有一个对应的页表,而SMMU是为设备服务的,几个设备可能同属于一个guest VM,因此多个设备可能会共用一个GPA->HPA的转换页表。同一个guest VM的设备可能属于或者不属于某一个特定的进程,因此也可能共用或者不共用GVA->GPA的转换页表。
在SMMU中,一个发起DMA传输(transaction)的设备的信息由一个Stream Table Entry(STE)来描述。所有的STEs共同构成了Stream Table,可由StreamID作为Stream Table数组的索引,查找得到对应的STE,因此StreamID也就成了设备唯一性的标识。Stream table可以是1-level的:

也可以是2-level的,比如一个10位的StreamID使用[9:8]的2个bits作为第一级Stream table的索引,[7:0]的8个bits作为第二级Stream table的索引,这和使用虚拟地址作为索引查找页表是一样的(参考这篇文章)。

大家应该都知道,ARM公司主要是依靠出售core的license来赚钱的,它给予了具体的芯片厂商一些自由发挥的空间,比如SMMUv3只规定了StreamID的大小是0-32个bits,但具体采用多少个bits,以及StreamID是怎样构成的,则都属于implementation defined。但SMMUv3同时也做出了限制:如果StreamID的数目超过了64(也就是超过了6个bits),那么必须使用2-level的Stream table。
如果一个STE对应的设备要进行的是GPA->HPA的stage 2转换(关于stage请参考这篇文章的注[1]),那么该STE包含的S2TTB(Stage 2 Translate Table Base)将直接指向设备所属的guest VM对应的stage 2页表(下图中的D)。设备所属的VM由STE中的VMID标识,属于同一个VM的设备对应的STEs将指向同一个stage 2页表。
在同一个VM内,一个设备可能被VM内的多个进程共享,而这些进程会有不同的页表,因此一个设备在和不同进程交互时,也会使用不同的页表。为了区分,需要一个设备对应进程的描述信息,这个描述信息被称为CD(Context Descriptor)。
如果该设备需要进行的是GVA->GPA的stage 1转换(比如前面提到的用户空间的DMA传输),那么描述该设备的STE将指向当前进程对应的这个CD(下图中的B)。和同一个进程交互的不同设备将共用这个进程的stage 1页表,因此这些设备的STEs将指向同一个CD。

每个CD包含了一个标识进程的ASID,由TTB0和TTB1指向进程对应的stage 1页表(上图中的C)。熟悉ARM架构的同学应该知道,TTBR0和TTBR1是ARM中分别用来存储进程页表和内核页表的基地址的寄存器,由于这里不再是Register,而是内存中的Descriptor,但用途类似,所以就叫TTB0和TTB1。
同一个设备对应的所有CDs构成了一个CD table。CD table使用的查找索引被称为SubstreamID。SubstreamID最多占20个bits,这个规定是有出处的。PCIe中有个PASID,而PASID最大就是20个bits。SubstreamID基本就是和PASID对等的概念,虽然SMMU并不限于只支持PCIe的设备,但这里SubstreamID还是和PASID保持了统一的步调。

同Stream table一样,CD table可以是1-level的(下图中的D),也可以是2-level的(下图中的E和F)。

如果是熟悉x86的segmentation机制或者是看过这个系列的文章的同学,会不会发现SMMU中的这个Stream table/CD table,其实和x86中的GDT/LDT是很相似的。都是通过索引查找得到对应的entry,每一个entry都是记录的一些描述信息,而且后面还都是跟的page tables。
为什么IOMMU要使用专门的I/O页表?
以AMD的IOMMU为例,它和内置在一个CPU内的MMU(以下称作CPU MMU,ARM的CoreLink MMU,还有前面介绍的EPT/NPT,都属于CPU MMU)是存在一些区别的:
- 64位的x86_64系列的CPU MMU只支持4KB, 2MB和1GB的页大小(参考这篇文章),而AMD的IOMMU除了支持这些默认的页大小,还支持8KB, 16KB, 1MB, 4MB, 4GB的页大小。

- CPU MMU需要按照页表结构一级一级的遍历,而当虚拟地址包含一长串的0的时候,AMD的IOMMU在查找时可以跳过其中的一级页表。
正因为有了IOMMU设计上的这些差异,使用专门的I/O页表可以获得更快的查找速度。如果非要用普通的页表也不是不可以,但需要舍弃IOMMU的一些特性,以适配普通页表的查找规则。然而,ARM的SMMU的设计就不是这样的,它使用普通的页表依然可以工作的很好,不需要专门的I/O页表。