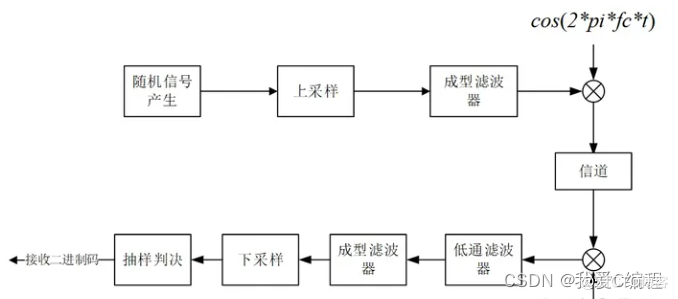
现在很多语音助手比如小爱同学、小度等都有支持方言语音识别,开源模型也有不少中文的ASR(自动语音识别)预训练模型可做到开箱即用。方言的ASR模型比较少特别是海南话ASR模型更是没有。这几篇文章主要是基于Transformer从0开始训练一个海南话语音识别模型,当然效果可能不会特别好,这也是方言语音识别的通病最主要的问题还是语料的缺乏,高质量的数据集更是难找,海南话的更是没有。
ASR(自动语音识别)除了算法最底层的原料就是海南话语料,这语料的质量也最终决定了训练出来海南话语音识别模型的质量如何。海南话数据集目前公开就不存在,所以语料数据集的搜刮主要来自两种来源互联网和自制。互联网上的海南话主要来源于视频与音频,还要经过数据清洗预处理,处理出来的语料质量也是参差不齐。自制相对来说会比互联网上的音视频数据预处理简单很多,自己录制即可,但又没有足够规模的数据。
数据预处理
在ASR数据集语料中基本都采用了WAV作为其音频格式,WAV由于其的无损音频、遵循RIFF规范、PCM编码、与工具库的兼容性、数据完整性这些对于ASR训练可提供更准确声学特征以及更准确完整的数据。

数据预处理通常由这些步骤:音频格式转换、重采样、降噪、声音增强、特征提取(FBank)、静音切除、归一化、音频对齐等,目前我们这里采用的音频格式统一为WAV所以就无需进行音频格式转换了。
在对音频文件进行预处理前我们先对一个WAV文件进行可视化从中可以发现该音频一些比较明显的特征。
fileDir="data/100.wav"
plt.figure(figsize=(6,4))
y,sr=librosa.load(fileDir)
librosa.display.waveshow(y)
plt.title(f'100.wav(Sampling rate: {sr}Hz)')
plt.xlabel("Time(seconds)")
plt.ylabel("Amplitude")
plt.show()
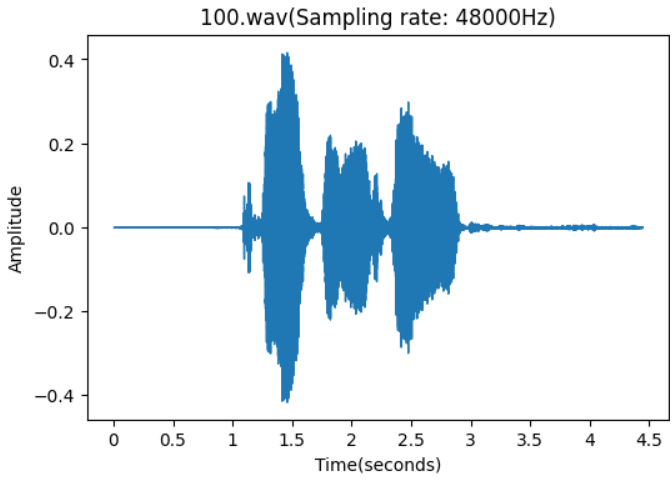
WAV文件可视化如上图X轴位时间Y轴位振幅,从该波形图可可看到该音频文件如下信息:
振幅:较高的波峰对应较大的振幅,即更响的声音
频率: 音频信号的频率,波形的周期越短,表示频率越高,即音高越高;周期越长,表示频率越低,即音高越低
时长:水平轴代表时间,因此你可以通过波形图的长度来估计音频的持续时间
静音和无声部分:波形图中的平坦线段表示音频中的静音或无声部分。
音频质量:波形图中的噪声和失真可以揭示音频的质量。例如,不规则的波形可能表明音频中存在噪声或压缩失真。
剪辑和编辑点:在编辑音频时,波形图可以帮助识别剪辑和编辑的点,例如在两个不同音频片段之间进行平滑过渡的地方。
从该音频波形图中我们明显发现该文件需要进行处理,当前采样频率为48000Hz需进行重采样为16000Hz,静音部分占了三分之一左右需进行静音切除,如该音频文件噪声过多还需进行降噪处理等。
重采样
采样率越高音质越好能够捕获更准确的原始声音信号,但文件会越大处理所需的资源会更多会增加计算量,我们这里主要用于ASR训练所以48kHz(数字音频广播)采样率对我们来说已经很高了,在16kHz就能够捕捉到人类语音细微差别又能够保持相对低的数据率与存储效率。ASR数据集通常采样率也就是16kHz。
import librosa
import os
import soundfile as sffile="data/100.wav"
# 重采样的音频采样率
output_sample = 16000
outputDir="data/output"
fileName= os.path.basename(file)y,sr=librosa.load(file,sr=None)
print(sr)
# 处理音频进行重采样
y_16k = librosa.resample(y, orig_sr=sr, target_sr=output_sample)
# 输出文件路径
outputFileName = os.path.join(outputDir, fileName)
# 保存重采样音频
sf.write(outputFileName, y_16k, output_sample)
# 验证保存后的文件采样率
info = sf.info(outputFileName)
print(f"重采样后 sample rate: {info.samplerate}")
静音切除
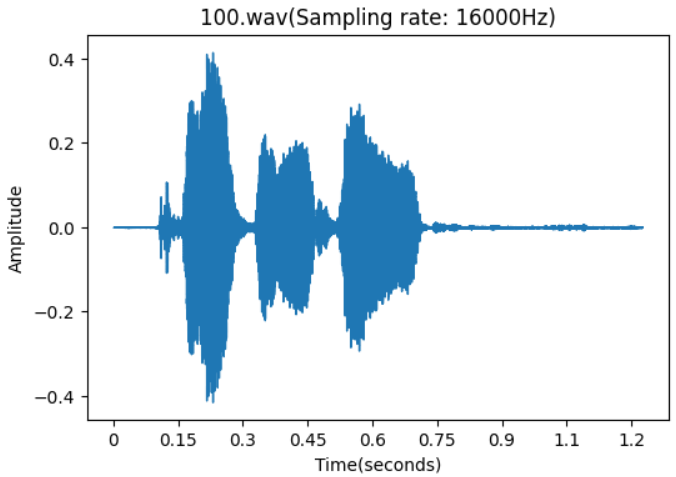
在音频文件静音部分并不会对语音识别做什么贡献因为其不包含语音信息还会增加训练的计算量,有时候语料质量不高切除静音后可能会减少客观的数据量。静音切除也是语音识别中比较常见的一个步骤。这里使用librosa配合soundfile对WAV文件进行静音切除。如下图进行静音切除后文件时长明显变短了。
import librosa
import soundfile as sffile="data/output/100.wav"outputFile="data/output/100_trimmed.wav"# 加载音频文件
y, sr = librosa.load(file, sr=None) # sr=None 保持原始采样率# 切除静音 top_db:分贝 frame_length:每一帧的样本数 hop_length:相邻帧之间的样本数
y_trimmed, index = librosa.effects.trim(y, top_db=60, frame_length=2048, hop_length=512)# 保存切除静音后的音频
sf.write(outputFile, y_trimmed,sr)
降噪
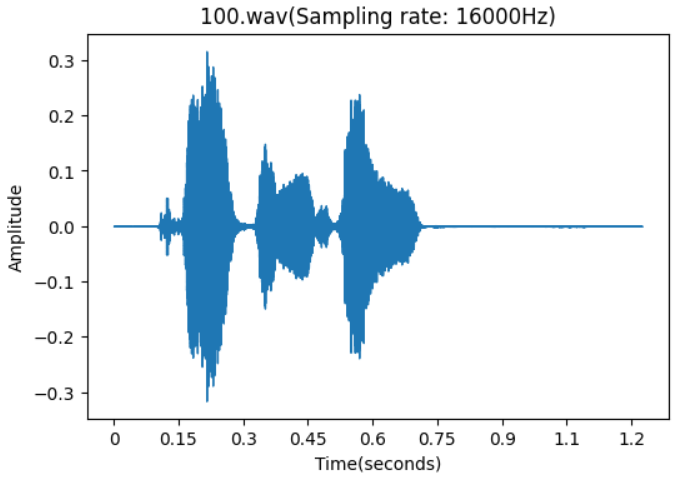
在音频文件中如果噪音过多会影响到语音识别的训练效果,在进行语音识别模型训练时通常还需要进行音频语料进行降噪处理去除不必要的噪音避免其对人声进行干扰;从下图的波形图可看出对比上面只经过静音切除的波形图经过降噪后会更加干净,没有那么多连续的低幅噪声,语音的波峰和波谷更容易区分。对比上面波形图还是能够肉眼可见的区别;
import librosa
import noisereduce as nr
import soundfile as sffileDir="data/output/100_trimmed.wav"
outputFile="data/output/100_noise.wav"#加载您WAV文件
data, rate = librosa.load(fileDir, sr=None)#prop_decrease:降噪比例,1.0表示100%
#y_noise:噪声信号,用于非平稳噪声降低的统计计算
#stationary:布尔值,指定是否执行平稳噪声降低,默认为False
#n_std_thresh_stationary:在平稳噪声降低中,信号与噪声之间阈值的标准差数#应用降噪
noise_reduced = nr.reduce_noise(y=data, y_noise=None, sr=rate,use_tqdm=True)# 保存降噪后的音频
sf.write(outputFile, noise_reduced,rate)
特征提取
在语音识别中特征提取时非常重要的一个环节,特征提取是从原始音频信号中提取有助于识别和理解语音的关键信息的过程。主要有如下常用的特征提取方法:MFCC(Mel频率倒谱系数)、FBank(滤波器组特征)、深度学习特征提取、谱图特征提取等。深度学习特征提取能够自动学习复杂的特征表示,FBank与MFCC是比较常见的特征提取方法。
FBank特征提取:
预加重:增强高频部分,使频谱更加均衡。
分帧:将连续的语音信号分割成短时帧。
加窗:对每一帧信号进行窗函数处理,常用的窗函数有汉明窗。
快速傅里叶变换(FFT):将时域信号转换为频域信号。
应用Mel滤波器组: 使用一系列三角形滤波器模拟人耳的听觉特性,提取滤波器组的能量。
MFCC特征提取:
MFCC特征提取在FBank的基础上增加了以下步骤:
对数压缩:对滤波器组的能量进行对数变换,模拟人耳对声音强度的非线性感知。
离散余弦变换(DCT):对对数滤波器组能量进行DCT变换,以去除特征间的相关性,并保留最重要的信息。通常只保留DCT的前13个系数。
MFCC的计算量比FBank大,FBank特征包含了比MFCC更多的信息,因为它没有经过DCT压缩,FBank特征的相关性较高。下图为FBank的特征可视化;
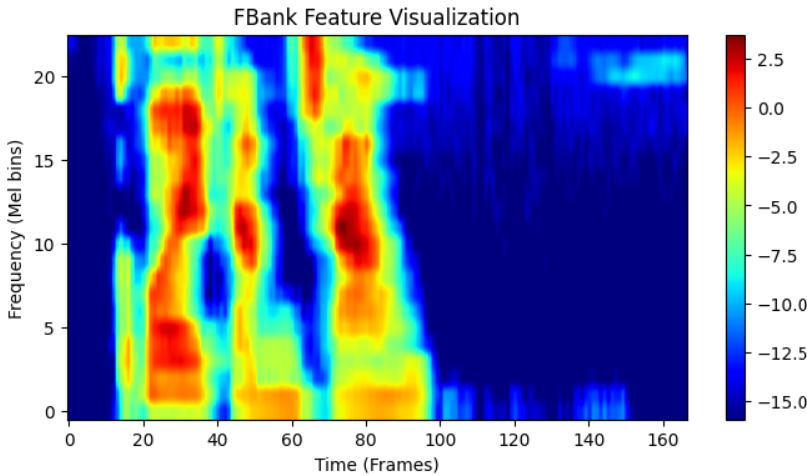
较亮的区域表示较高的能量,较暗的区域表示较低的能量。
y轴:表示Mel滤波器组,它反映了不同频率范围内的能量。较低的Mel值对应于较低的频率,较高的Mel值对应于较高的频率。
x轴:表示时间,每一帧对应于音频中的一个短时间窗口。音频的动态变化在x轴上呈现。
FBank_features是提取的FBank特征,其形状为[滤波器组数, 帧数]
import torchaudio
import torchaudio.compliance.kaldi as kaldifileDir="data/output/100_noise.wav"
waveform, sample_rate = torchaudio.load(fileDir)
# 使用torchaudio.compliance.kaldi.fbank函数提取FBank特征。你可以设置各种参数,如帧长、帧移、滤波器组的数量等。fbank_features = kaldi.fbank(waveform, sample_frequency=sample_rate, frame_length=25, frame_shift=10, num_mel_bins=23, dither=0.0, use_log_fbank=True)
#查看其形状来了解特征的维度。
print(fbank_features.shape)import matplotlib.pyplot as plt
plt.figure()
plt.imshow(fbank_features.T, aspect='auto', origin='lower')
plt.colorbar()
plt.title('FBank Features')
plt.show()
这里使用FBank进行原始音频特征处理,在进行语料数据预处理后就可以进行海南话语音识别模型的训练的,数据预处理可以说是模型训练的基石如果预处理没做好再模型训练时可能训练处的模型会不够好,数据预处理足够好还能够节省模型训练的时间。数据集大规模多样性也决定了最终模型的可靠性。
参考资料:
Audio Feature Extractions Tutorial
mfcc
Automatic-Speech-Recognition-from-Scratch