公司最近要进行多品牌合一,原来五个品牌的app要合并为一个。品牌立项、审批、方案确定,历史数据迁移、前期的基础工程搭建,兼容以及涉及三方的交互以及改造,需求梳理等也都基本完成,原来计划9月中旬进行上线,但是上线后服务端的压测一直通不过-首页抗不过太高的并发。
app首页里面是一个信息流,里面包含运营以及用户发布的各种视频、动态以及问答之类的帖子,广告位、运营后台配置的推荐帖以及会在信息流指定位置放置一些banner位等,还包括智能推荐、三方推荐以及一部分自研的推荐数据(服务端有开关配置走那种推荐系统),服务端这块统一由一个接口组装各种数据后返回给app端。组装的数据大部分是存在redis缓存里面,比如广告位、banner位以及一些运营自己在后台配置的一些配置,这些因为变化不大或者基本不怎么变化,从缓存读取耗时也都很快的,耗时比较慢的点主要集中在 内部的feign调用以及查询es信息流时候要进行组装信息,这些在压测时候基本占用了整个应用耗时的90%以上。使用hutool的StopWatch统计耗时大概如下这种:(单位 ms)
000000201 08% 组装es数据
000000599 25% feign调用uc获取黑名单数据
000000495 21% feign调用社区查询置顶数据
000000603 25% 查询帖子列表
000000394 16% 修改意向车型
000000002 00% 获取内容标签数据
000000000 00% 获取热门话题数据
000000002 00% 获取专题组件数据
000000090 04% 获取信息流广告位数据
000000001 00% 获取快速入口数据
000000002 00% 获取轮播广告数据
在单台机器 2核4G,压测100并发的情况下,平均耗时能达到2s左右,p90 能在3s多,整体性能很差。
在压测时候,使用arthas的监控工具,在耗时比较严重的地方进行监控,首先是feign调用的地方,发现有个奇怪的线程,使用trace命令 监控超过30ms的请求,发现很少
trace com.gwm.marketing.service.impl.HomeRecommendServiceImpl addSuperStreams '#cost > 30' -n 50 --skipJDKMethod false
但是在调用方的耗时 能达到惊人的1s以上,如果是并发量比较少的情况,比如50并发左右,这个耗时不超过200ms,但是一旦并发过高立马耗时就上来了。服务端内部是通过feign调用来进行rpc调用的,而且被调用方的耗时也很快,初步怀疑是 不是 调用方 存在gc的问题,或者是调用方 线程池阻塞 以及 feign调用在高并发下的默认的链接存在阻塞导致的。另外还有发现es以及部分日志也陆续存在耗时比较久的情况,总体上这些加起来 ,导致整个耗时比较严重。
首先看了下服务器的gc,单机2核4g 配置的gc信息如下:
-Djava.net.preferIPv4Stack=true -Djava.util.Arrays.useLegacyMergeSort=true -Dfile.encoding=UTF-8 -server -Xms512m -Xmx512m -XX:NewSize=128m -XX:MaxNewSize=128m -Xss256k -Drocketmq.client.logUseSlf4j=true -XX:+UseG1GC -XX:+PrintGCTimeStamps -Xloggc:log/gc-%t.log -XX:+UseGCLogFileRotation -XX:GCLogFileSize=10M
这个配置还使用的是G1,首页的这个场景,首页是服务器的内存过小,使用g1的话,对于我们想要的是吞吐量更大的其实有些差距,我们的目的是为了吞吐量更大,响应时间更快,那么使用cms的方式其实更好。然后让运维改了一下 gc的回收方式为cms:
-Djava.net.preferIPv4Stack=true -Djava.util.Arrays.useLegacyMergeSort=true -Dfile.encoding=UTF-8 -server -Xms512m -Xmx512m -XX:NewSize=128m -XX:MaxNewSize=128m -Xss256k -Drocketmq.client.logUseSlf4j=true -XX:+UseConcMarkSweepGC -XX:+CMSIncrementalMode -XX:CMSInitiatingOccupancyFraction=75 -Xloggc:log/gc-%t.log -XX:+UseGCLogFileRotation -XX:GCLogFileSize=10M
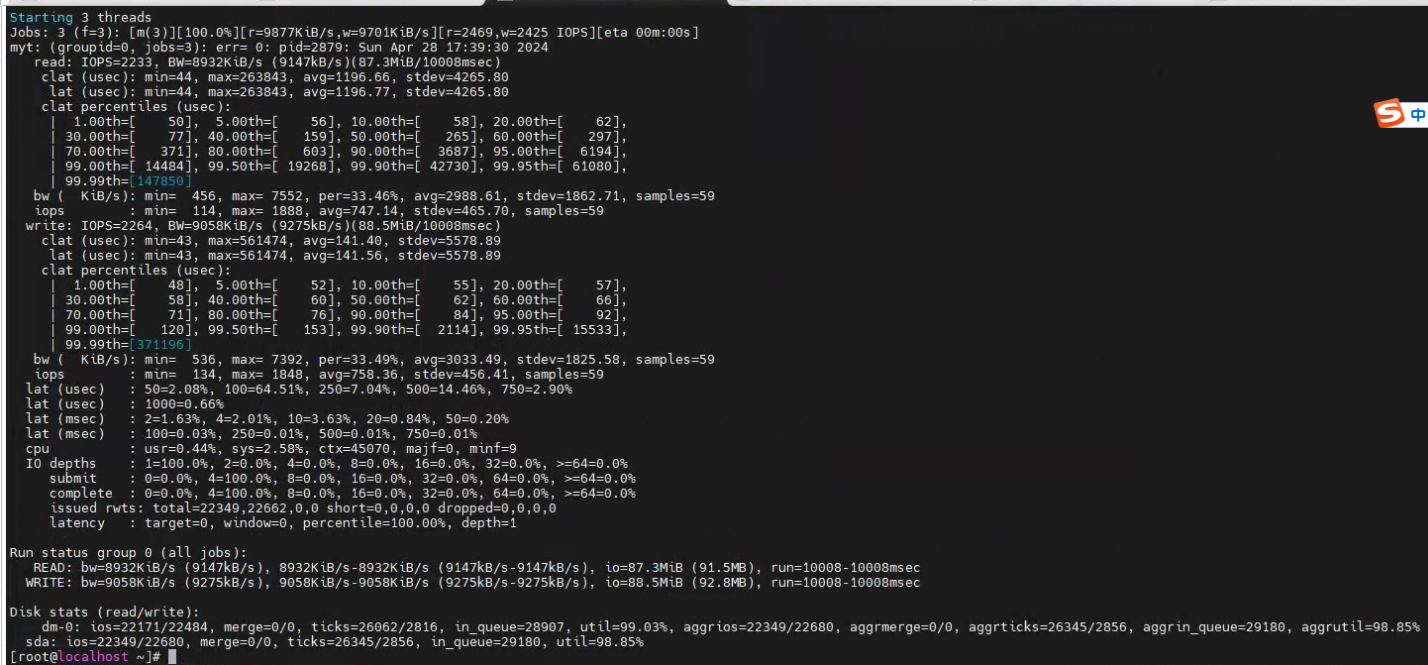
实测后发现有一定的提升,比如使用g1的话,压测5分钟的耗时 和使用cms的压测耗时
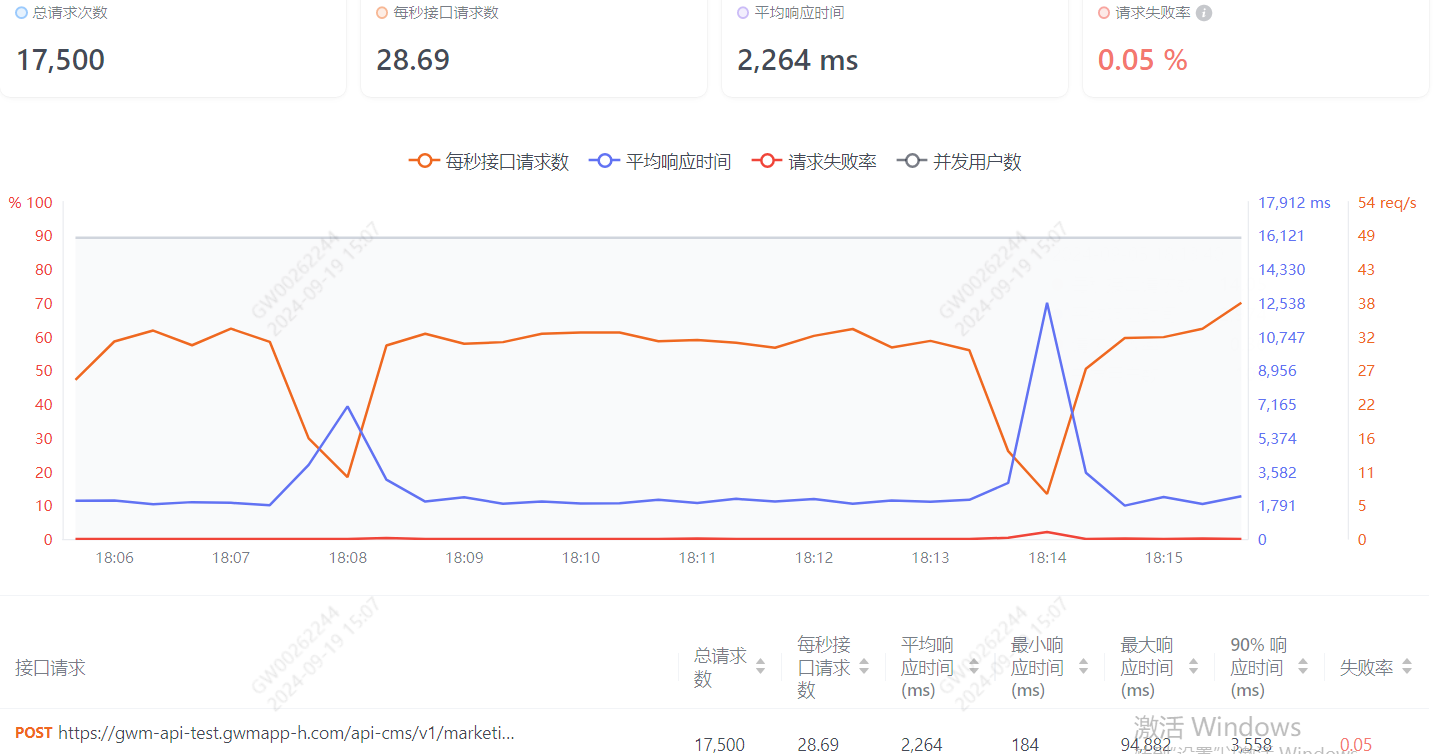
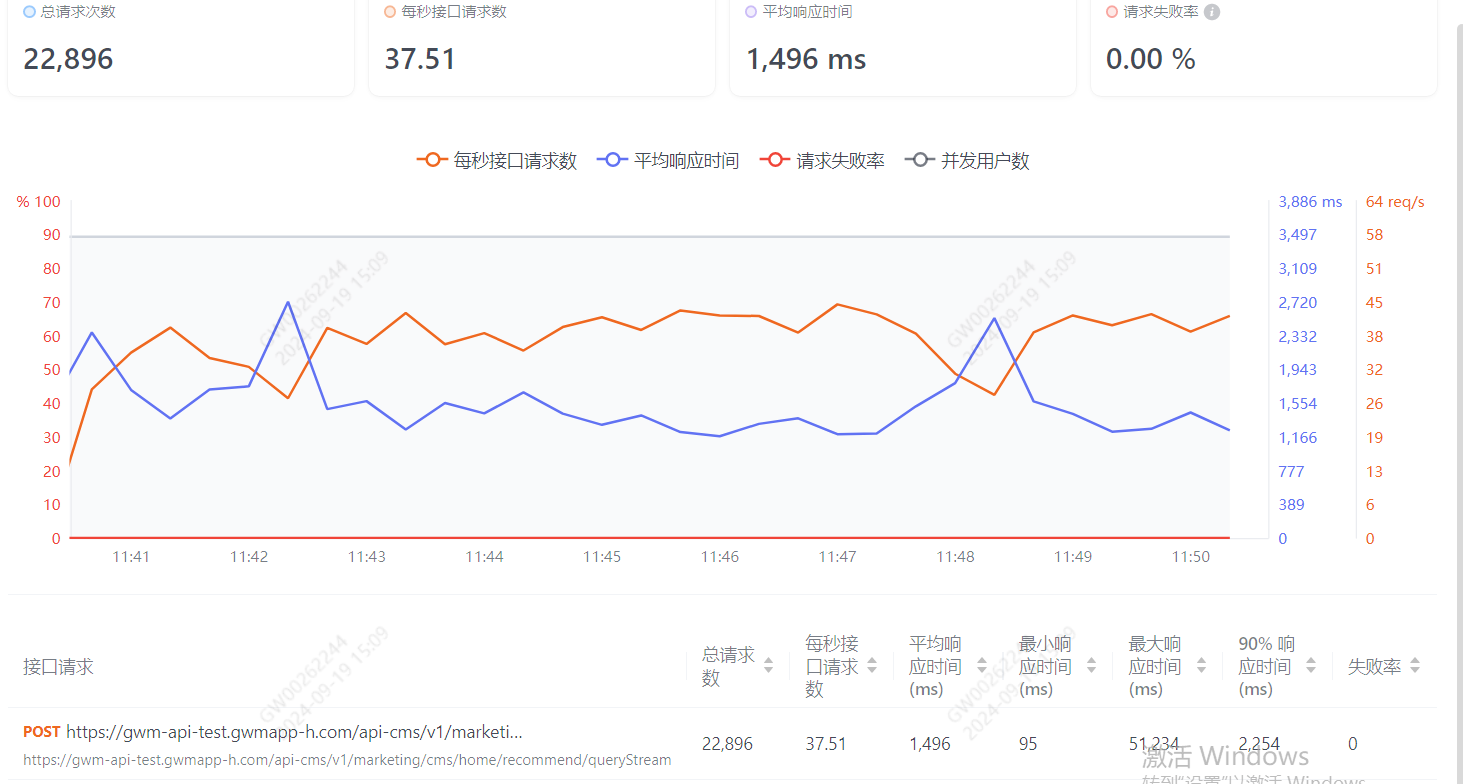
这个是能提升一定的性能,然后耗时比较严重的第二个部分 就是 feign调用- 为何单个接口的耗时很快,但是在feign调用时候就很慢?
首先feign调用 我们的配置是走了内网的,即不走网关-

我们的项目是基于nepxion里面的openfeign,openfeign使用的是默认的HttpURLConnection的链接方式,而且看了我们的openfeign的版本是 2.2.3的,这个版本还没有池化的概念-就是每次的rpc通过
feign调用的话,每次都需要走tpc的三次握手和四次挥手, 这个耗时在请求量比较少的情况下体现不出来,但是在并发量比较高的情况下,就体现出来了- 表现就是 明明在被调用方的耗时很小,但是在调用方显示出来的耗时就是很长,这个通过arthas和skywalking 的监控都证明了这一点。skywalking显示的 self耗时很长但是业务耗时很快,arthas在容器内看好是情况也是如此,因此需要对feign调用进行改造。
首先是对open-feign的版本进行升级,openfeign支持httpclient以及okhttpclient ,在最新的 4.2.0-SNAPSHOT 上 OkHttpFeignLoadBalancedConfiguration 里面已经是使用了连接池了,源码如下:
@Configuration(proxyBeanMethods = false) @ConditionalOnClass(OkHttpClient.class) @ConditionalOnProperty("spring.cloud.openfeign.okhttp.enabled") @ConditionalOnBean({ LoadBalancerClient.class, LoadBalancerClientFactory.class }) @EnableConfigurationProperties(LoadBalancerClientsProperties.class) class OkHttpFeignLoadBalancerConfiguration {@Bean@ConditionalOnMissingBean@Conditional(OnRetryNotEnabledCondition.class)public Client feignClient(okhttp3.OkHttpClient okHttpClient, LoadBalancerClient loadBalancerClient,LoadBalancerClientFactory loadBalancerClientFactory,List<LoadBalancerFeignRequestTransformer> transformers) {OkHttpClient delegate = new OkHttpClient(okHttpClient);return new FeignBlockingLoadBalancerClient(delegate, loadBalancerClient, loadBalancerClientFactory,transformers);}@Bean@ConditionalOnMissingBean@ConditionalOnClass(name = "org.springframework.retry.support.RetryTemplate")@ConditionalOnBean(LoadBalancedRetryFactory.class)@ConditionalOnProperty(value = "spring.cloud.loadbalancer.retry.enabled", havingValue = "true",matchIfMissing = true)public Client feignRetryClient(LoadBalancerClient loadBalancerClient, okhttp3.OkHttpClient okHttpClient,LoadBalancedRetryFactory loadBalancedRetryFactory, LoadBalancerClientFactory loadBalancerClientFactory,List<LoadBalancerFeignRequestTransformer> transformers) {OkHttpClient delegate = new OkHttpClient(okHttpClient);return new RetryableFeignBlockingLoadBalancerClient(delegate, loadBalancerClient, loadBalancedRetryFactory,loadBalancerClientFactory, transformers);}}
而我们这个2.2.3的还不支持池化,故首先把open-feign的版本升级了,以支持可以池化,另外就是需要配置 池化的参数以及开启okhttpclient
feign.httpclient.enabled = false #httpClient 关闭
feign.okhttp.enabled = true #okHttpClient 启用
feign.httpclient.maxConnections = 1000 #最大连接数
feign.httpclient.maxConnectionsPerRoute = 300 #feign单个路径的最大连接数
feign.httpclient.connectionTimeout = 3000 #超时时间 try {Request.Options options = new Request.Options(connectionTimeoutConfig.getFeignConnectionTimeout(),connectionTimeoutConfig.getFeignReadTimeout());data = gwmInterFeignClient.queryLikeAndCollectStatusByThreadsOptionLimit(appUserThreadStatusQuery,options).getData();} catch (Exception e) {log.error("===feign调用超时====请求废弃");data = new AppUserThreadFDto();}
再就是在arthas下面发现有日志也存在耗时严重的情况,对于非必要的日志,进行不去进行打印 或者修改日志级别为debug,当然还有一种方式 就是把写日志的方式 改成异步来写。
另外还发现代码里面如果判断一个对象是否在集合里,也会存在性能耗时的问题,这个需要改为并发执行 ,类似代码如下:
优化前:
streams.forEach(stream -> {stream.setIsLike(CollectionUtils.isNotEmpty(data.getLikeThreads()) ? (data.getLikeThreads().contains(stream.getThreadId()) ? ONE : ZERO) : ZERO);stream.setIsCollect(CollectionUtils.isNotEmpty(data.getCollectThreads()) ? (data.getCollectThreads().contains(stream.getThreadId()) ? ONE : ZERO) : ZERO);
优化后:
streams.forEach(stream -> {stream.setIsLike(CollectionUtils.isNotEmpty(finalData.getLikeThreads())? (finalData.getLikeThreads().parallelStream().anyMatch(d->d.equals(stream.getThreadId()))? ONE : ZERO) : ZERO);stream.setIsCollect(CollectionUtils.isNotEmpty(finalData.getCollectThreads()) ? (finalData.getCollectThreads().parallelStream().anyMatch(d->d.equals(stream.getThreadId())) ? ONE : ZERO) : ZERO);});
除了这个还有es的耗时严重的的问题,我们的es 采用的是5.7的版本,比较老了,es主要是组装数据 以及查询相对比较方便,库表大概有几千万的帖子数据,但是每次耗时 有时候也能达到400-500ms的延迟。
这个暂时没找到原因,后面有时间了在继续。
还有就是在首页里面加上sentinel 限流,首页里面有一部分耗时比较长的部分,比如 调用三方的接口,比如推荐部分,这部分三方接口本身就有一些性能压力,我们这边在调用时候 是使用的http来进行调用的,超时时间是3s,实测发现,当并发达到10 到20的时候,这部分基本就3s超时了。一部分是他们的推荐规则确实挺复杂的,推荐的数据要进行达标,要根据用户的个个业务维度去进行筛选,虽然数据已经提前写入缓存了,调用里面业务有些复杂 导致耗时比较严重,特别是并发稍微高的情况下。于是在调用他们这些推荐数据的地方 加了sentinel 的限流。
加sentinel限流的时候,一般有两种方式,一种是针对指定的资源,比如接口、指定的bean等进行限流和降级,还有一种是sentinel + openfeign 来进行限流和降级。两种方式的效果是类似的,只是配置略微有一些区别,另外第一种方式是有限制的,即限制的资源需要是spring 容器里面的bean对象,否则限流和降级不会生效。我使用的是第一种方式,代码如下
@Override@SentinelResource(value = "queryRecommend", fallback = "getStaticData",blockHandler = "blockExceptionHandler")public List<String> queryRecommend(HomeRecommendStreamQuery query, HomeRecommendStreamDto streamDto, String sourceApp) {//用户身份StopWatch st = StopWatch.create("内容中台推荐数据");String userType = this.getUserType(query.getIdentity(), query.getSource(), query.getUserId());//获取当前有用户是否推荐用户信息boolean isRecommend = true;if (StringUtils.isNotEmpty(query.getUserId())) {Set<String> userClosed = gwmRedisTemplate.opsForValue().get(USER_CLOSED_RECOMMEND);if (CollectionUtils.isNotEmpty(userClosed)) {boolean anyMatch = userClosed.stream().anyMatch(str -> str.equals(query.getUserId()));if (anyMatch) {isRecommend = false;}}}//构建推荐系统对象信息RecommendQuery build = RecommendQuery.builder().userType(userType)//推荐系统需要唯一标识,如果未登录用户传设备id,登录用户传userID.userId(StringUtils.isNotEmpty(query.getUserId()) ? query.getUserId() : query.getDeviceId()).intendedBrandList(query.getIntendedBrandList()).intendedVehicleList(query.getIntendedVehicleList()).recommendationSwitch(isRecommend).strategyType(query.getStrategyType()).deviceId(query.getDeviceId()).page(query.getPage()).pageSize(query.getSize()).build();st.start("推荐调用uc黑名单接口");if (StringUtils.isNotEmpty(query.getUserId())) {CmsAppUserIdQuery qry = new CmsAppUserIdQuery();qry.setUserId(query.getUserId());List<String> list = feignUserCenterClient.getBlackUserIds(qry, sourceApp).getData();if(query.isCheckBlack()){build.setBlacklistUsers(list);}query.setBlacklistUsers(list);}st.stop();// 调用内容中台推荐接口st.start("调用内容中台推荐接口");String recommend = okhttp3Util.postBody(config.getUrl(), build);st.stop();logger.info("首页推荐查询推荐系统入参:{},推荐系统返回:{} , ssoId:{}", JSONObject.toJSONString(build), recommend, query.getUserId());RecommendResponse<RecommendStrategyDto> response = parseBody(recommend, RecommendStrategyDto.class);List<String> idList = null;if (Objects.nonNull(response)) {if (response.isSuccessful()) {RecommendStrategyDto recommendStrategyDto = response.getData();streamDto.setStrategyType(recommendStrategyDto.getStrategyType());idList = recommendStrategyDto.getContentIds();} else if (!response.recommendChannelNormal()) {streamDto.setRecommendChannelAvailable(false);return new ArrayList<>();}}//查询推荐系统数据为空if (CollectionUtils.isEmpty(idList) && query.getPage() == 1) {//nacos兜底,取默认配置数据idList = Optional.ofNullable(config.getPostIds()).orElse(Collections.emptyList());}return idList;}
public List<String> getStaticData(HomeRecommendStreamQuery query, HomeRecommendStreamDto streamDto, String sourceApp) {logger.info("==========start sentinel 降级策略==========");try {Random random = new Random();int r = random.nextInt(100) + 1;logger.debug("========随机从缓存获取一组帖子id:" + r);Set<String> stringSet = gwmRedisTemplate.opsForValue().get(RedisConstants.THREAD_HOT_SCORE_KEY + r);logger.debug("=========随机从缓存获取帖子result=======" + JSONObject.toJSON(stringSet));if (CollectionUtils.isNotEmpty(stringSet)) {List<String> stringList = new ArrayList<>(stringSet);return stringList;} else {logger.debug("============读取默认配置数据========" + config.getPostIds());return Optional.ofNullable(config.getPostIds()).orElse(Collections.emptyList());}} catch (Exception e) {throw new RuntimeException(e);}}/*** blockHandler需要设置为static** @param ex* @return*/public List<String> blockExceptionHandler(HomeRecommendStreamQuery query, HomeRecommendStreamDto streamDto, String sourceApp,BlockException ex) {try {Random random = new Random();int r = random.nextInt(100) + 1;logger.debug("========随机从缓存获取一组帖子id:" + r);Set<String> stringSet = gwmRedisTemplate.opsForValue().get(RedisConstants.THREAD_HOT_SCORE_KEY + r);logger.debug("=========随机从缓存获取帖子result=======" + JSONObject.toJSON(stringSet));if (CollectionUtils.isNotEmpty(stringSet)) {List<String> stringList = new ArrayList<>(stringSet);return stringList;} else {logger.debug("============读取默认配置数据========" + config.getPostIds());return Optional.ofNullable(config.getPostIds()).orElse(Collections.emptyList());}} catch (Exception e) {throw new RuntimeException(e);}}
总结起来就是:针对首页的性能问题,优化了gc的方式,feign调用的改造,部分代码改为并行、日志优化 、es的查询优化以及使用sentinel做限流降级。 当然还有就是,我们这个首页这么多的内容都写到了一个接口里面,对于服务端的性能确实压力很大,后面看能不能进行拆分,让端上进行单个接口的请求,由一个接口变为多个接口,这样也能减少不少服务端的压力。最后优化后的压测结果:
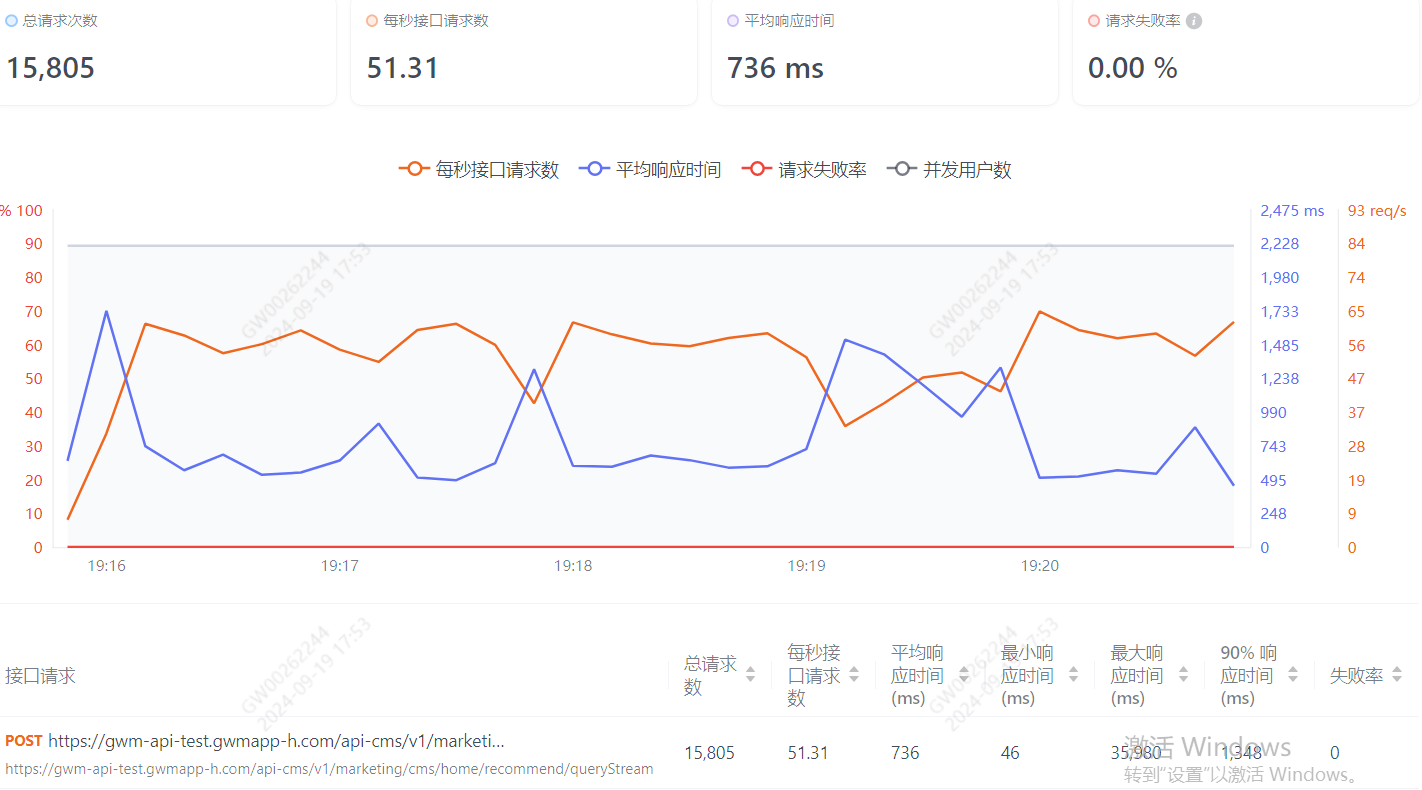
目前可优化的部分主要是集中在es这部分上面了。