整除的基本知识
有 \(12\) 个苹果,恰好平分给 \(x\) 个人(每个人分到的苹果完整且数量相同),\(x\) 能取到哪些值?
分别以 \(1\) 到 \(12\) 假设 \(x\),发现只有 \(x=1,2,3,4,6,12\) 这 \(6\) 个数字满足,这里用到的就是整除的概念。整数之间的整除性,体现为两个整数相除没有余数,此时两数具有倍数和约数的关系。
设 \(a,b\) 是两个整数,且 \(a \ne 0\),如果存在另一个整数 \(q\),使得 \(b=aq\),那么就说 \(b\) 可被 \(a\) 整除,记作 \(a | b\),且称 \(b\) 是 \(a\) 的倍数,\(a\) 是 \(b\) 的约数。
在 C++ 中,用 a%b==0 来表示 \(b\) 能够整除 \(a\)。
整除有几个常用性质:
- 若 \(a|b\) 且 \(b|c\),那么 \(a|c\)。
回忆一下直尺上的刻度,每 \(5\) 个 \(1mm\) 小刻度形成一个 \(5mm\) 中刻度,两个 \(5mm\) 中刻度会形成一个 \(1cm\) 大刻度。这蕴涵了 \(10\) 个 \(1mm\) 小刻度形成 \(1cm\) 大刻度。也就是说,已知 \(1|5\) 和 \(5|10\),可以推出 \(1|10\)。 - 若 \(a|b\) 且 \(a|c\),那么对于任意的整数 \(x,y\),有 \(a|bx+cy\)。
对 \(a\) 的倍数任意加减得到的仍然是 \(a\) 的倍数。想象一下一杯饮料 \(10\) 元,那么 \(20\) 元纸币恰好能买两杯,\(50\) 元纸币恰好能买五杯,那么无论多少张 \(20\) 元和 \(50\) 元纸币,都能买到整数杯饮料。甚至,找回来的钱也可以是 \(20\) 元纸币或 \(50\) 元纸币,对应减法。值得注意的是,\(0\) 是任何正整数的倍数。也就是说,\(a|(b-b)\) 也是对的。 - 设整数 \(m \ne 0\),那么 \(a|b\) 等价于 \(ma | mb\)。
显然将两数放大若干倍,它们之间的整除性不变。
有 \(120\) 个苹果,恰好平分给 \(x\) 个人(每个人分到的苹果完整且数量相同),\(x\) 能取到哪些值?
实质上就是找 \(120\) 的所有约数,但是对于 \(120\),逐个枚举的计算量很大,但是注意到 \(120\) 的约数是成对出现的,比如 \(1 \times 120 = 120\) 和 \(2 \times 60 = 120\),其中 \(1,120,2,60\) 全都是 \(120\) 的约数。也就是说,一旦知道较小的因数 \(k\) 就可以求出那个较大的因数 \(\dfrac{120}{k}\),因为限定了大小,所以 \(k \le \dfrac{120}{k}\),\(k\) 是整数,可以得出 \(k \le 10 < \sqrt{120} < 11\),可以发现枚举量急剧减小。
不超过 \(10\) 的 \(120\) 的因数有 \(1,2,3,4,5,6,8,10\),那么对应的另一个约数就是 \(120,60,40,30,24,20,15,12\)。至此,很快就找出了 \(120\) 的全部约数。
同理,可以尝试应用这种优化过的枚举法寻找 \(n\) 的所有约数:如果 \(k\) 是 \(n\) 的约数,那么 \(n/k\) 也一定是 \(n\) 的约数,只要限定 \(k \le \dfrac{n}{k}\),即 \(k \le \sqrt{n}\),就可以在 \(O(\sqrt{n})\) 的时间复杂度内找到 \(n\) 的所有约数。
vector<int> vec; // vec用来存储n的所有约数(无序)
int find_divisors(int n) { // 返回值为约数个数int cnt = 0;for (int k = 1; k * k <= n; k++) {// 考虑到k*k有可能溢出,有时写成k<=n/kif (n % k == 0) {vec.push_back(k);if (k != n / k) vec.push_back(n / k);// 约数成对出现,但要注意k=n/k时可能出现重复}}return cnt;
}
例题:P2926 [USACO08DEC] Patting Heads S
给定 \(n\) 和 \(n\) 个正整数,求每个数是另外多少个数的倍数。\(n \le 10^5\),数字 \(a_i\) 不超过 \(10^6\)。例如给出 \(5\) 个数,分别是 \(2,1,2,3,4\) 时,答案分别是 \(2,0,2,1,3\)。
分析:如果直接枚举每对数,则时间复杂度为 \(O(n^2)\),显然不足以通过本题(能够获得 \(47\) 分)。
参考代码 $O(n^2)$
#include <cstdio>
const int N = 1e5 + 5;
int a[N], ans[N];
int main()
{int n; scanf("%d", &n);for (int i = 1; i <= n; i++) scanf("%d", &a[i]);for (int i = 1; i <= n; i++) {for (int j = 1; j <= n; j++) {if (i == j) continue;if (a[i] % a[j] == 0) ans[i]++;}}for (int i = 1; i <= n; i++) printf("%d\n", ans[i]);return 0;
}
如果从枚举约数的角度思考,会很自然地得到这样一个算法:对于每个数 \(a_i\),枚举它的所有约数,再看这些约数在 \(n\) 个数中出现了几次(可以在输入时预处理),对它们求和即为答案。这个算法的时间复杂度是 \(O(n \sqrt{A})\),这里 \(A\) 指的是 \(\max \{ a_i \}\),比一开始的 \(O(n^2)\) 更优,能够通过本题。
参考代码 $O(n \sqrt { A })$
#include <cstdio>
const int N = 1e5 + 5;
const int A = 1e6 + 5;
int a[N], ans[N], cnt[A];
int main()
{int n; scanf("%d", &n);for (int i = 1; i <= n; i++) {scanf("%d", &a[i]); cnt[a[i]]++;}for (int i = 1; i <= n; i++) {int ans = 0;// 枚举a[i]的所有约数for (int j = 1; j * j <= a[i]; j++) {if (a[i] % j == 0) {int d1 = j, d2 = a[i] / j;ans += cnt[d1];if (d2 != d1) ans += cnt[d2];} }printf("%d\n", ans - 1); // 减去自己的贡献}return 0;
}
本题还可以从枚举倍数的角度思考:对于一个数 \(i\),如果它在原数组中出现了 \(c_i\) 次,那么 \(i\) 这个数会对它的每一个倍数产生 \(c_i\) 的贡献。
#include <cstdio>
#include <algorithm>
using std::max;
const int N = 1e5 + 5;
const int A = 1e6 + 5;
int a[N], ans[A], cnt[A];
int main()
{int n; scanf("%d", &n);int maxa = 0;for (int i = 1; i <= n; i++) {scanf("%d", &a[i]); cnt[a[i]]++; maxa = max(maxa, a[i]);}for (int i = 1; i <= maxa; i++) {for (int j = i; j <= maxa; j += i) {ans[j] += cnt[i]; // i 这个数会对 j 产生 cnt[i] 的贡献}}for (int i = 1; i <= n; i++) printf("%d\n", ans[a[i]] - 1); // 要减掉 a[i] 对自己的贡献return 0;
}
乍一看有上限到 \(10^6\) 的双重循环,但是实际上有这样一个数学性质:\(\sum \limits_{i=1}^{n} \dfrac{n}{i} \approx n \ln n\),因此上面这个算法的时间复杂度为 \(O(A \log A)\),由于换底公式,对数的底数不同可以忽略,不过不同于其他很多算法比如二分,在二分这样的算法中,对数的来源是折半,因此会涉及 $\log_2 $,而本题这种情况下涉及的对数是自然对数 \(\ln\),这个复杂度俗称为调和级数复杂度。
调和级数复杂度的证明涉及到微积分,目前可以先当成结论记忆。感兴趣可以阅读:调和级数的复杂度。
质数与合数
当寻找 \(2,3,5,7,11,13\) 这些数的约数时,可以发现它们除了 \(1\) 和自身以外没有其他的约数,这类数被称作质数。
设正整数 \(p \ne 0,1\),如果它除了 \(1\) 和 \(p\) 以外没有其他的约数,那么就称 \(p\) 为质数。若正整数 \(a \ne 0\),\(1\) 且 \(a\) 不是质数,则称 \(a\) 为合数。
若 \(a\) 为合数,则 \(a\) 能被表示成 \(a=pq\),其中 \(p,q>1\)。易证 \(p,q\) 中一定有一个不超过 \(\sqrt{a}\),因为如果 \(p,q\) 都超过 \(\sqrt{a}\),则会有 \(pq>a\),矛盾。更严格地,若 \(a\) 为合数,则一定存在质数 \(p|a\),且 \(p \le \sqrt{a}\)。
计算题:从 \(2\) 至 \(8\) 的 \(7\) 个整数中随机取 \(2\) 个不同的数,这两个数互质的概率为?
答案
从 \(8\) 个数中随机取 \(2\) 个不同的数有 \(C_7^2 = 21\) 种情况,其中互质的情况包括:\(2\) 与 \(3,5,7\),\(3\) 与 \(4,5,7,8\),\(4\) 与 \(5,7\),\(5\) 与 \(6,7,8\),\(6\) 与 \(7\),\(7\) 与 \(8\),因此概率为 \(\dfrac{3+4+2+3+1+1}{21} = \dfrac{2}{3}\)。
例题:P3383 【模板】线性筛素数
给出若干(不超过 \(10^6\))个正整数 \(k\),依次输出第 \(k\) 小的素数,素数的范围是 \(10^8\) 以内。
判断一个整数是否为质数有一个时间复杂度为 \(O(\sqrt{n})\) 的算法:
bool is_prime(int x) { // 判断x是否为质数for (int i = 2; i * i <= x; i++) { // 枚举不超过sqrt(x)的iif (x % i == 0) return false; }return true;
}
这里之所以枚举到 \(\sqrt{x}\),就是因为如果 \(x\) 是合数,则一定存在质数 \(p|x\),且 \(p \le \sqrt{x}\)。
这同时也给出了一个寻找一定范围内所有质数的算法。例如,为了求出不超过 \(100\) 的所有质数,只要把 \(1\) 和不超过 \(100\) 的正合数都删去。
只需要用不超过 \(10\) 的全部质数(\(2,3,5,7\))找出,然后删去它们在 \(100\) 以内的所有倍数(\(2\) 的倍数,\(3\) 的倍数,\(5\) 的倍数,\(7\) 的倍数),就删去了所有 \(100\) 以内的合数,剩下的就是 \(100\) 以内的质数。
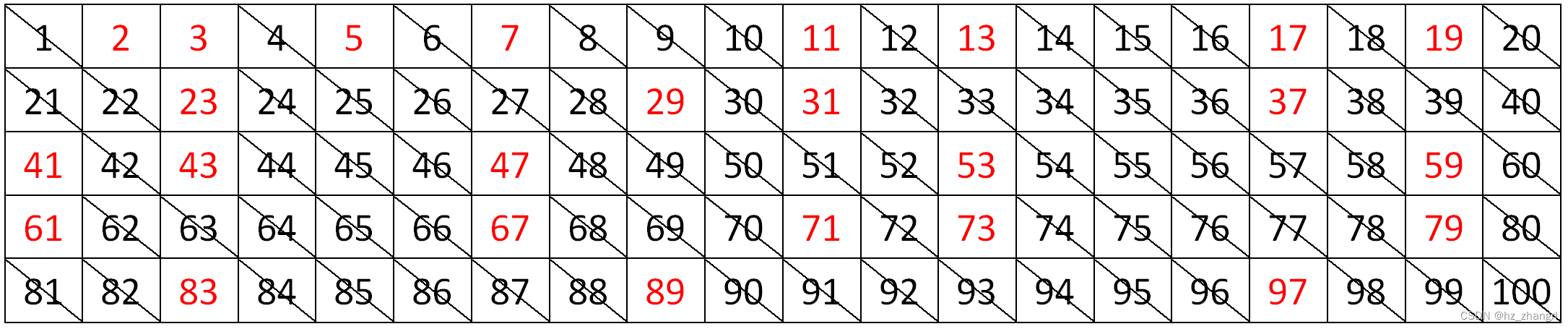
可以看出,没有删去的数是 \(2,3,5,7,\cdots,97\),共 \(25\) 个质数。从这 \(25\) 个质数出发,还可以找出 \(100 \times 100 = 10000\) 以内的所有质数。这个方法由古希腊数学家埃拉托斯特尼提出,称为埃拉托斯特尼筛,简称埃氏筛。
vector<int> p;
void eratosthenes_sieve(int n) {// 寻找不超过n的所有质数,数组flag用来做标记,flag[i]==true表示i被标记,是合数flag[1] = true;for (int i = 2; i * i <= n; i++) {if (!flag[i]) { // 如果i未被之前的数所标记说明i是质数for (int j = 2 * i; j <= n; j += i) {flag[j] = true; // 将i除了自己以外的倍数标记为合数}}}for (int i = 2; i <= n; i++)if (!flag[i]) p.push_back(i);
}
埃氏筛的时间复杂度是 \(O(n \ln\ln n)\)。
参考代码
#include <cstdio>
#include <vector>
using std::vector;
const int N = 1e8 + 5;
vector<int> p;
bool flag[N];
void eratosthenes_sieve(int n) {for (int i = 2; i * i <= n; i++) {if (!flag[i]) {for (int j = 2 * i; j <= n; j += i) {flag[j] = true;}}} for (int i = 2; i <= n; i++) if (!flag[i]) p.push_back(i);
}
int main()
{int n, q; scanf("%d%d", &n, &q);eratosthenes_sieve(n);for (int i = 1; i <= q; i++) {int k; scanf("%d", &k);printf("%d\n", p[k - 1]);}return 0;
}
既然质数的(大于 \(1\) 的)整数倍是合数,那么(大于 \(1\) 的)整数的质数倍数也一定是合数。就像 \(3\) 的 \(4\) 倍 \(12\) 是合数,那么 \(4\) 的 \(3\) 倍也一定是合数。于是可以得到埃氏筛的另外一种形式:
for (int i = 2; i <= n; i++) {if (!flag[i]) { // 如果i没有被筛去p.push_back(i); // 那么i就是一个质数}for (int j : p) { // 枚举当前的所有质数if (i > n / j) break; flag[i * j] = true; // i的j倍是合数}
}
在这个形式中,只有当 \(j \le i\) 时,\(i \times j\) 才会被筛去。为什么这是正确的?考虑 \(j>i\) 的情况,设 \(i\) 的最小质因子是 \(p_i\),则 \(i \times j\) 会在 \(i' = j \times \dfrac{i}{p_i}, \ j' = p_i\) 的时候被筛去。
在这个基础上,再添加一行代码,就可以得到欧拉筛,一种时间复杂度为 \(O(n)\) 的线性筛。
for (int i = 2; i <= n; i++) {if (!flag[i]) { p.push_back(i); }for (int j : p) { if (i > n / j) break; flag[i * j] = true; if (i % j == 0) break; // 欧拉筛的核心}
}
为什么增加这一句判断,就可以提前结束循环呢?设 \(n\) 的最小质因子为 \(p_n\),如 \(p_9 = 3, p_{12} = 2\)。那么在线性筛中,一个合数 \(n\) 会且仅会在 \(i = \dfrac{n}{p_n}\) 的时候被筛去。
首先证明充分性:合数 \(n\) 会在 \(i = \dfrac{n}{p_n}\) 的时候被筛去。显然 \(\dfrac{n}{p_n}\) 是大于等于 \(p_n\) 的,否则 \(\dfrac{n}{p_n}\) 的最小质因子一定比 \(p_n\) 小,且它也是 \(n\) 的一个质因子,那么 \(n\) 的最小质因子就不是 \(p_n\) 了。也就是说,当 \(i = \dfrac{n}{p_n}\) 时,\(p_n\) 一定已经被保存在 p 数组中。同时,如果 \(j\) 还没访问到 \(p_n\) 就已经 break 了,就代表着有一个比 \(p_n\) 更小的某个 \(j\),它可以整除 \(i\),也就是 \(i = \dfrac{n}{p_n}\) 的一个质因子,那么这个比 \(p_n\) 更小的质数 \(j\) 也一定是 \(n\) 的一个质因子,这也与 \(p_n\) 是 \(n\) 的最小质因子矛盾了。
然后证明必要性:合数 \(n\) 仅会在 \(i = \dfrac{n}{p_n}\) 的时候被筛去。假设 \(p'\) 是一个大于 \(p_n\) 的 \(n\) 的质因子,那么需要证明的是:当 \(i = \dfrac{n}{p'}\) 的时候,在 \(j\) 枚举到 \(p'\) 之前,第二层循环就已经 break 了。这其实也很简单:因为 \(p'\) 和 \(p_n\) 互质,且同时是 \(n\) 的质因子,所以 \(p_n\) 也一定是 \(\dfrac{n}{p'}\) 的一个质因子。那么当 \(i = \dfrac{n}{p'}\) 时,当 \(j\) 枚举到 \(p_n\) 时,\(j\) 就整除 \(i\) 了,此时第二层循环就会 break,而不会让 \(j\) 再往后枚举到 \(p'\)。
也就是说,对于每一个合数,它只会被 flag[i*j]=true 这条语句标记为合数一次,也就是说这条语句实际上只会被执行不超过 \(n\) 次,那么整个算法的时间复杂度显然就是 \(O(n)\) 了。
参考代码
#include <cstdio>
#include <vector>
using std::vector;
const int N = 1e8 + 5;
vector<int> p;
bool flag[N];
void euler_sieve(int n) {for (int i = 2; i <= n; i++) {if (!flag[i]) { p.push_back(i); }for (int j : p) { if (i > n / j) break; flag[i * j] = true;if (i % j == 0) break;}}
}
int main()
{int n, q; scanf("%d%d", &n, &q);euler_sieve(n);for (int i = 1; i <= q; i++) {int k; scanf("%d", &k);printf("%d\n", p[k - 1]);}return 0;
}
完善程序题:
(好运的日期)一个日期可以用 \(x\) 年 \(y\) 月 \(z\) 日来表示。我们称一个日期是好运的,当且仅当 \(xy(w-z+1)\) 为质数,其中 \(w\) 为 \(x\) 年 \(y\) 月的总天数。输入 \(x,y,z\),判断其对应的日期是否好运。保证 \(x\) 是不超过 \(2024\) 的正整数,\(y\) 是不超过 \(12\) 的正整数,\(x,y,z\) 可以构成一个合法的日期。试补全线性筛法算法,空间限制 512MiB。
#include <bits/stdc++.h>
using namespace std;const int MAXW = ①;
const int days[13] = {0, 31, 0, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31};
int prime[MAXW], cnt;
bool not_prime[MAXW];void linear_prime(int n) {--n;not_prime[0] = not_prime[1] = true;for (int i = 2; i <= n; i++) {if (not_prime[i] == false)prime[++cnt] = i;for (int j = 1; ②; j++) {not_prime[i * prime[j]] = 1;if (i % prime[j] == 0)③;}}
}
bool check(int n) {return ④;
}int main() {linear_prime(MAXW);int x, y, z, w;cin >> x >> y >> z;if (y == ⑤)w = check(x) ? 29 : 28;elsew = days[y];if (not_prime[x * y * (w - z + 1)])cout << "unlucky" << endl;elsecout << "lucky" << endl;return 0;
}
①处可以填?
A. 753005 / B. 10000000000 / C. 725041 / D. 2024
②处可以填?
A. j <= cnt / B. i * prime[j] <= n
C. (j <= cnt) && (i * prime[j] <= n) / D. (i <= cnt) && (prime[i] * prime[j] <= n)
③处可以填?
A. not_prime[i] = true / B. return / C. continue / D. break
④处可以填?
A. n % 4 == 0 / B. (n % 400 == 0 || (n % 4 == 0 && n % 100 != 0))
C. (n % 4 == 0 && n % 100 != 0) / D. (n % 100 == 0 || (n % 4 == 0 && n % 100 != 0))
⑤处可以填?
A. 1 / B. 7 / C. 8 / D. 2
答案

答案:ACDBD