RAG+Agent人工智能平台:RAGflow实现GraphRA知识库问答,打造极致多模态问答与AI编排流体验
1.RAGflow简介
-
最近更新:
- 2024-09-13 增加知识库问答搜索模式。
- 2024-09-09 在 Agent 中加入医疗问诊模板。
- 2024-08-22 支持用RAG技术实现从自然语言到SQL语句的转换。
- 2024-08-02 支持 GraphRAG 启发于 graphrag 和思维导图。
- 2024-07-23 支持解析音频文件。
- 2024-07-08 支持 Agentic RAG: 基于 Graph 的工作流。
- 2024-06-27 Q&A 解析方式支持 Markdown 文件和 Docx 文件,支持提取出 Docx 文件中的图片和 Markdown 文件中的表格。
- 2024-05-23 实现 RAPTOR 提供更好的文本检索。
-
主要功能
-
"Quality in, quality out"
- 基于深度文档理解,能够从各类复杂格式的非结构化数据中提取真知灼见。
- 真正在无限上下文(token)的场景下快速完成大海捞针测试。
-
基于模板的文本切片
- 不仅仅是智能,更重要的是可控可解释。
- 多种文本模板可供选择
-
有理有据、最大程度降低幻觉(hallucination)
- 文本切片过程可视化,支持手动调整。
- 有理有据:答案提供关键引用的快照并支持追根溯源。
-
兼容各类异构数据源
- 支持丰富的文件类型,包括 Word 文档、PPT、excel 表格、txt 文件、图片、PDF、影印件、复印件、结构化数据、网页等。
-
自动化的 RAG 工作流
- 全面优化的 RAG 工作流可以支持从个人应用乃至超大型企业的各类生态系统。
- 大语言模型 LLM 以及向量模型均支持配置。
- 基于多路召回、融合重排序。
- 提供易用的 API,可以轻松集成到各类企业系统。
-

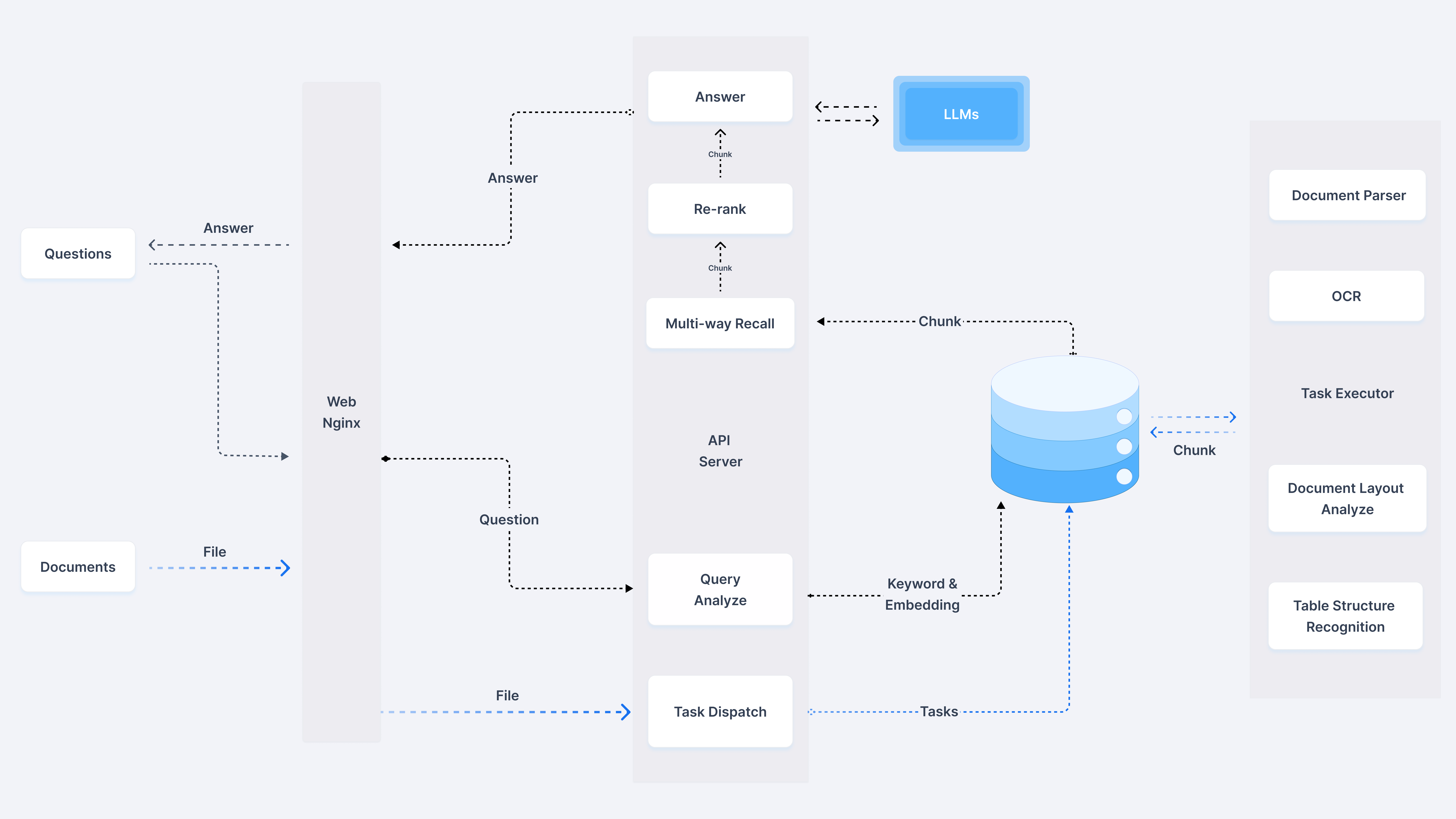
- 系统架构
2.快速开始
- 环节要求
- CPU >= 4 核
- RAM >= 16 GB
- Disk >= 50 GB
- Docker >= 24.0.0 & Docker Compose >= v2.26.1
如果你并没有在本机安装 Docker(Windows、Mac,或者 Linux), 可以参考文档 Install Docker Engine 自行安装。
2.1 启动服务器
vm.max_map_count是Linux内核中的一个重要参数,它定义了一个进程可以拥有的最大内存映射区域数。内存映射区域通常指的是内存映射文件、匿名内存映射等。
-
性能优化:通过增加vm.max_map_count的值,可以允许应用程序创建更多的内存映射区域,从而提高性能和效率。特别是对于需要频繁访问大量文件或数据的应用程序,这种优化效果尤为明显。 -
稳定性保障:如果应用程序尝试创建的内存映射区域数超过了系统设置的限制,可能会导致映射失败,进而引发性能问题或直接导致应用程序崩溃。因此,合理设置vm.max_map_count参数有助于保障系统的稳定性。 -
设置方法
临时设置:可以通过sysctl命令临时修改vm.max_map_count的值,但这种更改在系统重启后会失效。例如,要将vm.max_map_count的值设置为262144,可以执行sudo sysctl -w vm.max_map_count=262144命令。永久设置:为了确保在系统重启后vm.max_map_count的值仍然有效,需要将该值写入到/etc/sysctl.conf文件中。添加或更新vm.max_map_count=262144(或其他所需的数值)到该文件中,并保存更改。之后,可以通过执行sudo sysctl -p命令使更改立即生效。
-
确保
vm.max_map_count不小于 262144:如需确认
vm.max_map_count的大小:$ sysctl vm.max_map_count如果
vm.max_map_count的值小于 262144,可以进行重置:# 这里我们设为 262144: $ sudo sysctl -w vm.max_map_count=262144你的改动会在下次系统重启时被重置。如果希望做永久改动,还需要在 /etc/sysctl.conf 文件里把
vm.max_map_count的值再相应更新一遍:vm.max_map_count=262144 -
克隆仓库:
$ git clone https://github.com/infiniflow/ragflow.git -
进入 docker 文件夹,利用提前编译好的 Docker 镜像启动服务器:
$ cd ragflow/docker $ chmod +x ./entrypoint.sh $ docker compose -f docker-compose-CN.yml up -d请注意,运行上述命令会自动下载 RAGFlow 的开发版本 docker 镜像。如果你想下载并运行特定版本的 docker 镜像,请在 docker/.env 文件中找到 RAGFLOW_VERSION 变量,将其改为对应版本。例如 RAGFLOW_VERSION=v0.11.0,然后运行上述命令。
核心镜像文件大约 9 GB,可能需要一定时间拉取。请耐心等待。
镜像拉在太慢的化参考链接:镜像拉去提速
-
服务器启动成功后再次确认服务器状态:
$ docker logs -f ragflow-server出现以下界面提示说明服务器启动成功:
____ ______ __/ __ \ ____ _ ____ _ / ____// /____ _ __/ /_/ // __ `// __ `// /_ / // __ \| | /| / // _, _// /_/ // /_/ // __/ / // /_/ /| |/ |/ / /_/ |_| \__,_/ \__, //_/ /_/ \____/ |__/|__//____/* Running on all addresses (0.0.0.0)* Running on http://127.0.0.1:9380* Running on http://x.x.x.x:9380INFO:werkzeug:Press CTRL+C to quit如果您跳过这一步系统确认步骤就登录 RAGFlow,你的浏览器有可能会提示
network abnormal或网络异常,因为 RAGFlow 可能并未完全启动成功。 -
在你的浏览器中输入你的服务器对应的 IP 地址并登录 RAGFlow。
上面这个例子中,您只需输入 http://IP_OF_YOUR_MACHINE 即可:未改动过配置则无需输入端口(默认的 HTTP 服务端口 80)。
-
在 service_conf.yaml 文件的
user_default_llm栏配置 LLM factory,并在API_KEY栏填写和你选择的大模型相对应的 API key。详见 llm_api_key_setup。
部署遇到问题解决(🔺)
资源不足问题,ES会占用较多资源建议设置大一些
修改.env文件,根据自己内存资源进行设置,我就设置了70G,es默认吃一半
#Increase or decrease based on the available host memory (in bytes)MEM_LIMIT=72864896288

遇到知识库构建,索引构建卡住无法解析
问题描述:索引构建过程一直卡着,经过排查发现是系统盘空间不够95%+了,报错如下
ApiError('search_phase_execution_exception', meta=ApiResponseMeta(status=503, http_version='1.1', headers={'X-elastic-product': 'Elasticsearch', 'content-type': 'application/vnd.elasticsearch+json;compatible-with=8', 'content-length': '365'}, duration=0.004369974136352539, node=NodeConfig(scheme='http', host='es01', port=9200, path_prefix='', headers={'user-agent': 'elasticsearch-py/8.12.1 (Python/3.11.0; elastic-transport/8.12.0)'}, connections_per_node=10, request_timeout=10.0, http_compress=False, verify_certs=True, ca_certs=None, client_cert=None, client_key=None, ssl_assert_hostname=None, ssl_assert_fingerprint=None, ssl_version=None, ssl_context=None, ssl_show_warn=True, _extras={})), body={'error': {'root_cause': [{'type': 'no_shard_available_action_exception', 'reason': None}], 'type': 'search_phase_execution_exception', 'reason': 'all shards failed', 'phase': 'query', 'grouped': True, 'failed_shards': [{'shard': 0, 'index': 'ragflow_304817a205d211efa4de0242ac160005', 'node': None, 'reason': {'type': 'no_shard_available_action_exception', 'reason': None}}]}, 'status': 503})
- 如果系统盘空间不够,请对docker迁移
修改Docker默认存储路径参考
迁移后问题解决:
不得不说,ragflow的文档解析能力还挺强的


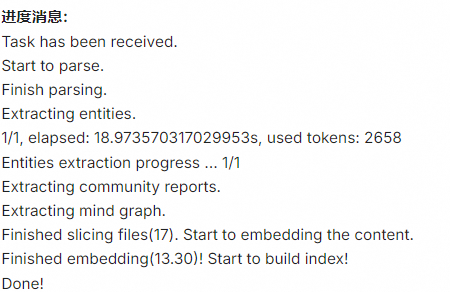
2.2 系统配置
系统配置涉及以下三份文件:
- .env:存放一些基本的系统环境变量,比如
SVR_HTTP_PORT、MYSQL_PASSWORD、MINIO_PASSWORD等。 - service_conf.yaml:配置各类后台服务。
- docker-compose-CN.yml: 系统依赖该文件完成启动。
请务必确保 .env 文件中的变量设置与 service_conf.yaml 文件中的配置保持一致!
./docker/README 文件提供了环境变量设置和服务配置的详细信息。请一定要确保 ./docker/README 文件当中列出来的环境变量的值与 service_conf.yaml 文件当中的系统配置保持一致。
如需更新默认的 HTTP 服务端口(80), 可以在 docker-compose-CN.yml 文件中将配置 80:80 改为 <YOUR_SERVING_PORT>:80。
所有系统配置都需要通过系统重启生效:
$ docker compose -f docker-compose-CN.yml up -d
2.3 源码编译、安装 Docker 镜像
如需从源码安装 Docker 镜像:
$ git clone https://github.com/infiniflow/ragflow.git
$ cd ragflow/
$ docker build -t infiniflow/ragflow:v0.11.0 .
$ cd ragflow/docker
$ chmod +x ./entrypoint.sh
$ docker compose up -d
2.4 源码启动服务
如需从源码启动服务,请参考以下步骤:
- 克隆仓库
$ git clone https://github.com/infiniflow/ragflow.git
$ cd ragflow/
- 创建虚拟环境(确保已安装 Anaconda 或 Miniconda)
$ conda create -n ragflow python=3.11.0
$ conda activate ragflow
$ pip install -r requirements.txt
如果 cuda > 12.0,需额外执行以下命令:
$ pip uninstall -y onnxruntime-gpu
$ pip install onnxruntime-gpu --extra-index-url https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/onnxruntime-cuda-12/pypi/simple/
- 拷贝入口脚本并配置环境变量
$ cp docker/entrypoint.sh .
$ vi entrypoint.sh
使用以下命令获取python路径及ragflow项目路径:
$ which python
$ pwd
将上述 which python 的输出作为 PY 的值,将 pwd 的输出作为 PYTHONPATH 的值。
LD_LIBRARY_PATH 如果环境已经配置好,可以注释掉。
#此处配置需要按照实际情况调整,两个 export 为新增配置
PY=${PY}
export PYTHONPATH=${PYTHONPATH}
#可选:添加 Hugging Face 镜像
export HF_ENDPOINT=https://hf-mirror.com
- 启动基础服务
$ cd docker
$ docker compose -f docker-compose-base.yml up -d
-
检查配置文件
确保docker/.env中的配置与conf/service_conf.yaml中配置一致, service_conf.yaml中相关服务的IP地址与端口应该改成本机IP地址及容器映射出来的端口。 -
启动服务
$ chmod +x ./entrypoint.sh
$ bash ./entrypoint.sh
- 启动WebUI服务
$ cd web
$ npm install --registry=https://registry.npmmirror.com --force
$ vim .umirc.ts
#修改proxy.target为http://127.0.0.1:9380
$ npm run dev
- 部署WebUI服务
$ cd web
$ npm install --registry=https://registry.npmmirror.com --force
$ umi build
$ mkdir -p /ragflow/web
$ cp -r dist /ragflow/web
$ apt install nginx -y
$ cp ../docker/nginx/proxy.conf /etc/nginx
$ cp ../docker/nginx/nginx.conf /etc/nginx
$ cp ../docker/nginx/ragflow.conf /etc/nginx/conf.d
$ systemctl start nginx
3. 案例快速实践
3.1 模型接入
- 商业模型接入:

参考链接:国内大模型LLM选择以及主流大模型快速使用教程
- ollama接入
参考链接:Ollama简化流程,OpenLLM灵活部署,LocalAI本地优化
- xinference 接入
Xinference实战指南
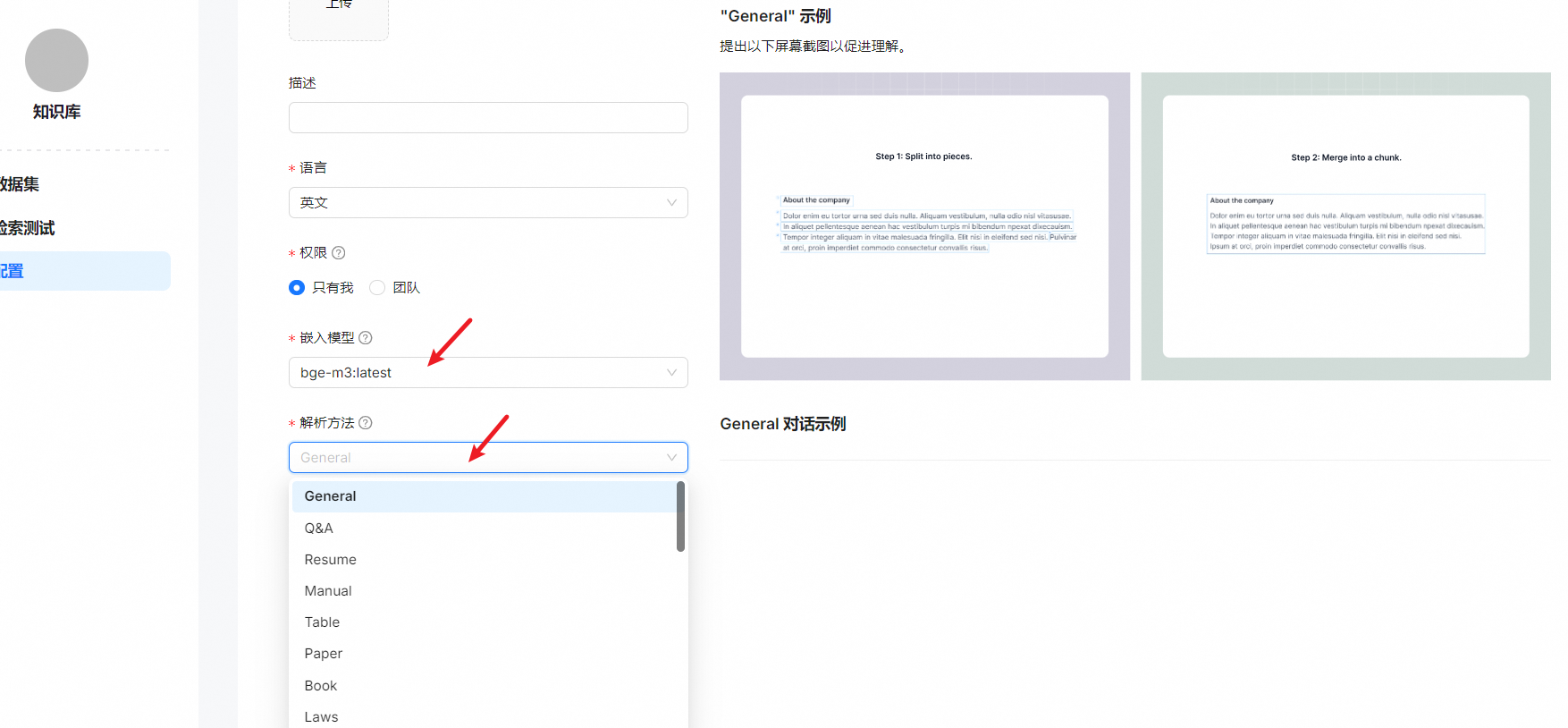
3.0 知识库构建
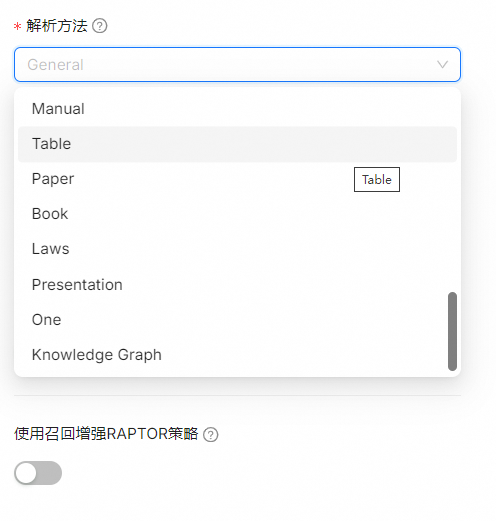
| Template | Description | File format |
|---|---|---|
| General | Files are consecutively chunked based on a preset chunk token number. | DOCX, EXCEL, PPT, PDF, TXT, JPEG, JPG, PNG, TIF, GIF |
| Q&A | EXCEL, CSV/TXT | |
| Manual | ||
| Table | EXCEL, CSV/TXT | |
| Paper | ||
| Book | DOCX, PDF, TXT | |
| Laws | DOCX, PDF, TXT | |
| Presentation | PDF, PPTX | |
| Picture | JPEG, JPG, PNG, TIF, GIF | |
| One | The entire document is chunked as one. | DOCX, EXCEL, PDF, TXT |
| Knowledge Graph | DOCX、EXCEL、PPT、IMAGE、PDF、TXT、MD、JSON、EML |
- "General" 分块方法说明
支持的文件格式为DOCX、EXCEL、PPT、IMAGE、PDF、TXT、MD、JSON、EML、HTML。
此方法将简单的方法应用于块文件:
系统将使用视觉检测模型将连续文本分割成多个片段。
接下来,这些连续的片段被合并成Token数不超过“Token数”的块。
- "Q&A" 分块方法说明
此块方法支持 excel 和 csv/txt 文件格式。
如果文件以 excel 格式,则应由两个列组成 没有标题:一个提出问题,另一个用于答案, 答案列之前的问题列。多张纸是 只要列正确结构,就可以接受。
如果文件以 csv/txt 格式为 用作分开问题和答案的定界符。
未能遵循上述规则的文本行将被忽略,并且 每个问答对将被认为是一个独特的部分。
- "Knowledge Graph" 分块方法说明
支持的文件格式为DOCX、EXCEL、PPT、IMAGE、PDF、TXT、MD、JSON、EML
文件分块后,使用分块提取整个文档的知识图谱和思维导图。此方法将简单的方法应用于分块文件: 连续的文本将被切成大约 512 个 token 数的块。
接下来,将分块传输到 LLM 以提取知识图谱和思维导图的节点和关系。
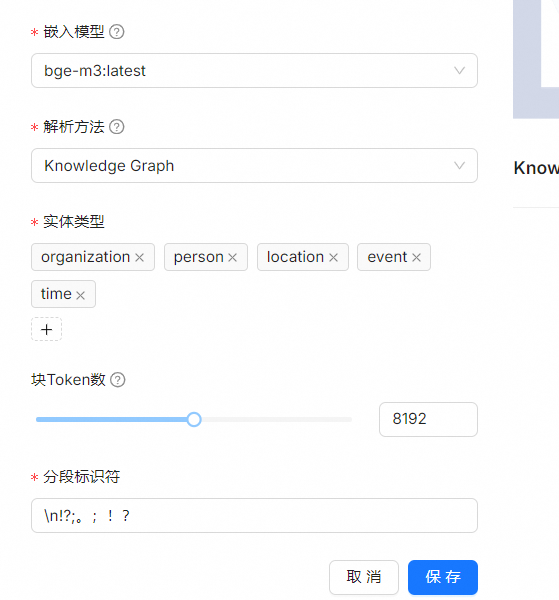
- 支持embedding model
- BAAI/bge-large-zh-v1.5
- BAAI/bge-base-en-v1.5
- BAAI/bge-large-en-v1.5
- BAAI/bge-small-en-v1.5
- BAAI/bge-small-zh-v1.5
- jinaai/jina-embeddings-v2-base-en
- jinaai/jina-embeddings-v2-small-en
- nomic-ai/nomic-embed-text-v1.5
- sentence-transformers/all-MiniLM-L6-v2
- maidalun1020/bce-embedding-base_v1
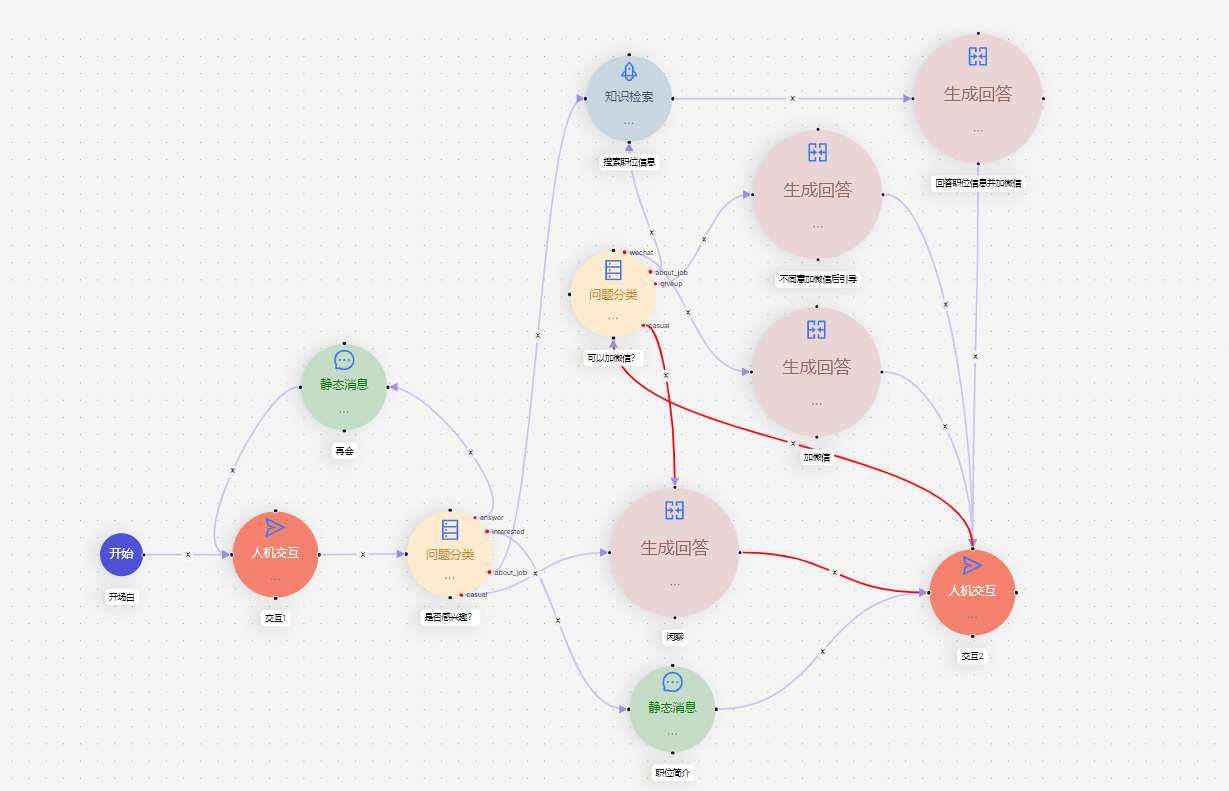
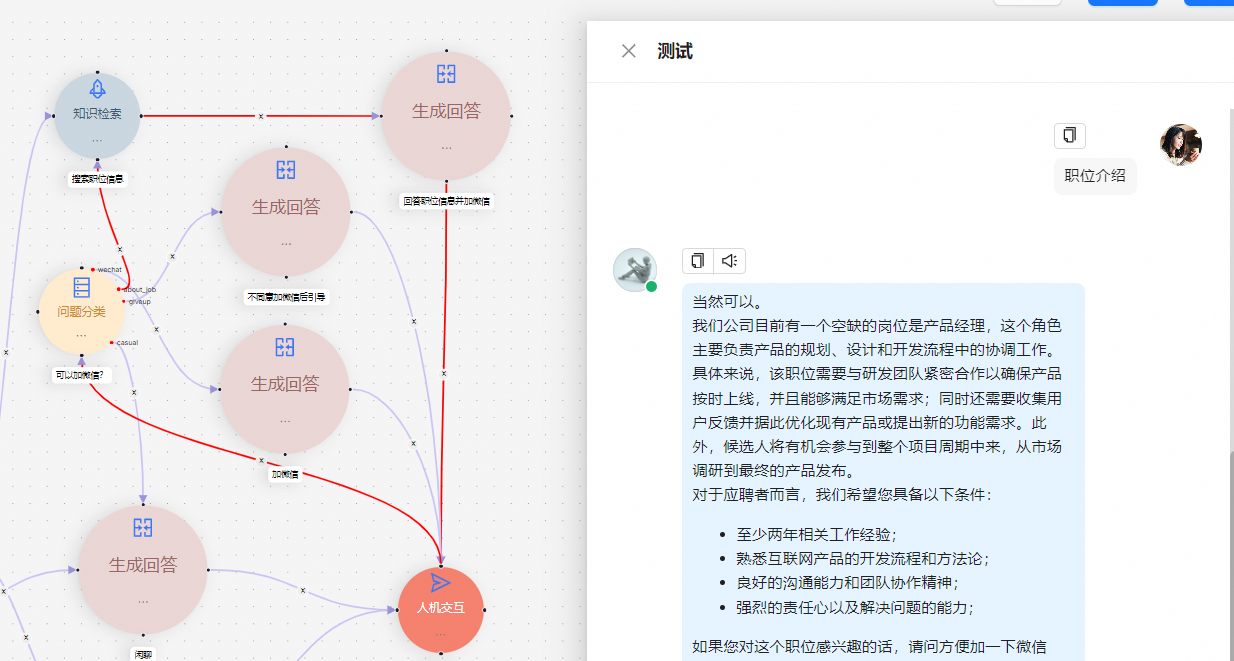
智能问答 & AI 编排流
Agent模块--->模板选择--->HR招聘助手
- 技术文档
- Quickstart
- User guide
- References
- FAQ