检索增强生成(RAG)技术概述
检索增强生成(Retrieval-Augmented Generation,简称 RAG)是一种旨在提升大型语言模型(Large Language Models,LLMs)性能的技术方法。其核心思想是通过整合外部可靠知识库的信息来增强模型的输出质量。
RAG 的工作原理可以概括如下:当 LLM 接收到查询时,它不仅依赖于自身的预训练知识,还会主动从指定的知识源检索相关信息。这种方法确保了生成的输出能够参考大量上下文丰富的数据,并得到最新、最相关可用信息的支持。
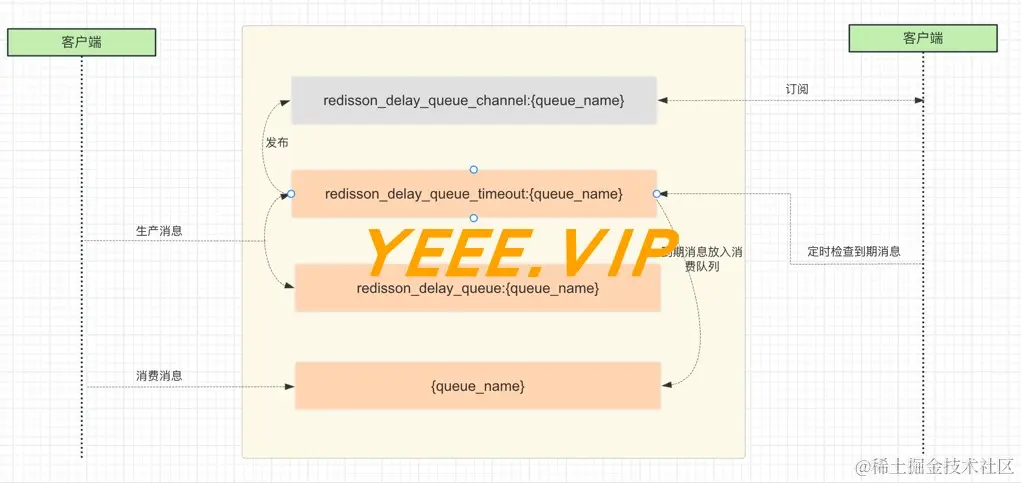
RAG 系统的核心组件
标准 RAG 系统主要由三个关键组件构成:
- 检索器组件(Retriever Component):- 功能:在知识库或大规模文档集中搜索与查询主题高度相关的信息。- 工作方式:识别在语义上与查询相关的文档,并通过相似度度量(通常采用向量间的余弦相似度)计算相关性。
- 生成器(Generator):- 定义:通常是一个大型语言模型。- 输入:检索到的相关信息和原始查询。- 输出:基于输入生成响应。
- 知识库(Knowledge Base):- 用途:作为检索器查找文档或信息的数据源。
RAG 的工作流程
- 从外部源收集相关信息。
- 将收集到的信息附加到用户的原始提示中。
- 将增强后的提示作为输入发送给语言模型。
- 在生成阶段,LLM 结合增强提示和自身的训练数据表示,生成针对用户查询定制的响应。
这一过程产生的响应融合了个性化和可验证的信息,特别适用于聊天机器人等应用场景。
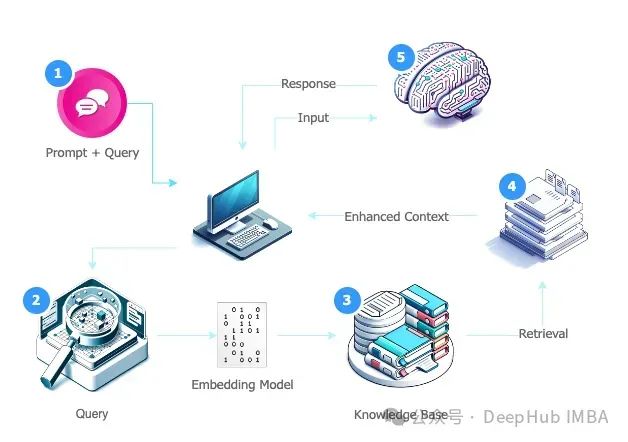
图2:检索增强生成流程示意
https://avoid.overfit.cn/post/1c6163da1c1d43d099fad164d01710c1