不包含乘法的运算符,如移位和加法,因其与硬件的兼容性而日益受到重视。然而,采用这些运算符的神经网络(
NNs)通常表现出比具有相同结构的传统NNs更低的准确性。ShiftAddAug利用成本较高的乘法来增强高效但功能较弱的无乘法运算符,从而在没有任何推理开销的情况下提高性能。将一个ShiftAdd小型神经网络嵌入到一个大型的乘法模型中,并鼓励其作为子模型进行训练以获得额外的监督。为了解决混合运算符之间的权重差异问题,论文提出了一种新的权重共享方法。此外,使用了一种新颖的两阶段神经架构搜索,以获得对较小但更强大的无乘法小型神经网络的更好增强效果。通过在图像分类和语义分割方面的实验验证了ShiftAddAug的优越性,始终带来显著的改善。值得注意的是,与其直接训练的其它网络相比,它在CIFAR100上的准确性提高了多达4.95%,甚至超过了乘法神经网络的性能。来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: ShiftAddAug: Augment Multiplication-Free Tiny Neural Network with Hybrid Computation

- 论文地址:https://arxiv.org/abs/2407.02881
Introduction
深度神经网络(DNNs)在资源受限平台上的应用仍然有限,因为它们巨大的能量需求和计算成本。为了获得可以部署在边缘设备上的小型模型,常用的技术包括剪枝、量化和知识蒸馏。然而,上述工作的设计的神经网络均基于乘法。数字信号处理中的常见硬件设计实践表明,乘法可以通过逐位移位和加法来替代,从而实现更快的速度和更低的能耗。将这一思想引入神经网络设计,DeepShift和AdderNet分别提出了ShiftConv运算符和AddConv运算符。
本文在无乘法神经网络的方向上更进一步,提出了一种通过混合计算增强的小型无乘法神经网络的,显著提高准确性且没有任何推理开销。考虑到无乘法运算符无法恢复原始运算符的所有信息,采用ShiftAdd计算的小型神经网络表现出明显的欠拟合。从NetAug中获得启发,ShiftAddAug选择构建一个更大的混合计算神经网络进行训练,并将无乘法部分设置为在推理和部署中使用的目标模型。将更强的乘法部分作为增强,可以进一步推使目标无乘法模型达到更好的状态。
在增强训练中,混合运算符共享权重。但由于不同运算符的权重分布各异,乘法的有效权重可能不适用于移位或加法操作,这促使论文开发一种用于增强的异构权重共享策略。
此外,由于NetAug将网络扩展限制在网络宽度上,ShiftAddAug则通过探索深度和运算符变化来突破限制。因此,采用一种两步神经架构搜索策略,以寻找高效的无乘法小型神经网络。
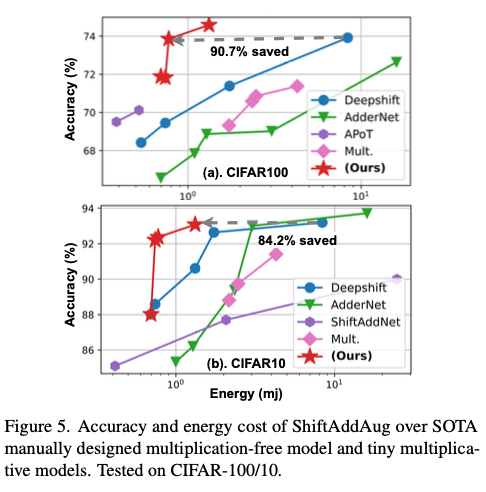
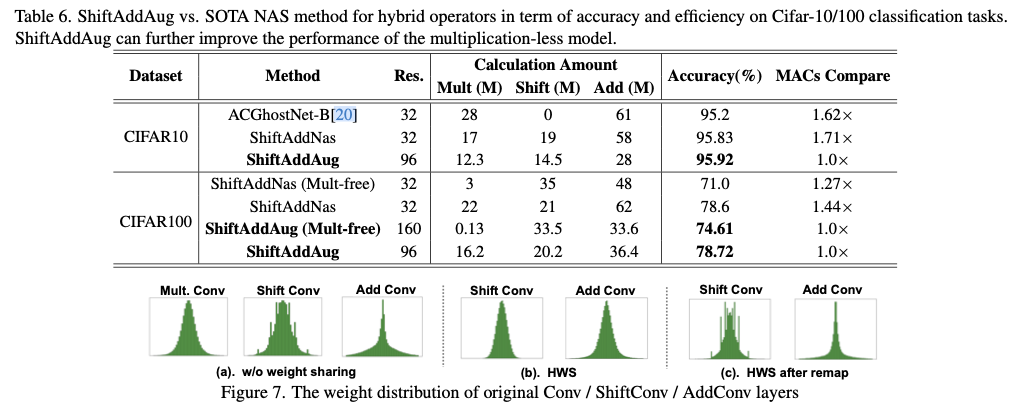
在MCU级别(单片机)的小型模型上进行评估。与乘法神经网络相比,直接训练的无乘法神经网络可以在降低准确率的情况下获得显著的速度提升(\(2.94 \times\) 到 \(3.09 \times\))和节能($\downarrow 67.75% \sim 69.09% $),但ShiftAddAug可以在提高准确率( \(\uparrow 1.08\% \sim 4.95\%\))的同时,保持硬件效率。
论文的贡献可以总结如下:
-
对于无乘法的小型神经网络,提出了混合计算增强,利用乘法运算符来增强目标的无乘法网络。在保持相同模型结构的同时,产生了一个更具表现力且极具效率的网络。
-
为了混合计算增强,提出了一种新的权重共享策略,该策略解决了在增强过程中异构(例如,高斯与拉普拉斯)权重共享中的权重差异问题。
-
基于增强的思想,采用了两阶段的架构搜索方法。首先从搜索空间中提取一个增强的大型网络,然后在该增强网络中搜索可部署的小型网络。
Related Works
-
Multiplication-Free NNs
为了减轻与乘法相关的高能耗和时间成本,一个关键策略是采用硬件友好的运算符来替代乘法。
ShiftNet提出了零参数、零浮点运算的卷积。DeepShift保留了原始卷积的计算方法,但用位移和位反转替代乘法。- 二值神经网络(
BNNs)对权重或激活进行二值化,以构建由符号变化组成的深度神经网络(DNNs)。 AdderNet选择用成本更低的加法替代乘法卷积,并设计了一种高效的硬件实现。
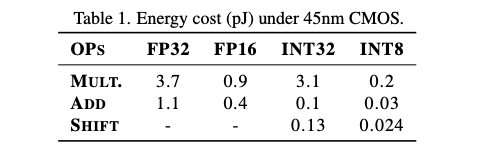
ShiftAddNet结合了位移和加法,如表1所示,在硬件上实现了高达\(196 \times\) 的能量节省。ShiftAddVit将这一理念应用于视觉变换器,通过专家混合执行混合计算。
-
Network Augmentation
关于小型神经网络的研究正在快速发展。专为MCU设计的网络和优化技术目前已经出现。
Once-for-all提出了渐进收缩(Progressive Shrinking),并发现所获得模型的准确性优于直接训练的对比模型。受到这一结果的启发,NetAug提出了一个观点,即小型神经网络在训练中需要更多的容量,而不是正则化。因此,他们选择了一种与Dropout等正则化方法相反的方案:扩展模型的宽度,让大型模型引导小型模型以实现更好的准确性。
-
Neural Architecture Search
神经架构搜索(NAS)在自动化创建高效神经网络架构方面取得了显著成功,提升准确性的同时,将延迟和内存使用等硬件考虑因素融入设计过程。NAS还扩展了其应用,探索更快的运算符实现并整合网络结构进行优化,使设计更接近硬件要求。ShiftAddNAS开创了一个搜索空间,其中包括乘法和无乘法运算符。
ShiftAddAug
Preliminaries
-
Shift
位移运算符的计算与使用权重 \(W\) 的标准线性或卷积运算符相似,只不过 \(W\) 被四舍五入为最接近的2的幂。采用位移和位反转技术以实现与传统方法相当的计算结果,如公式1所示。输入在计算之前进行量化,并在获得输出时进行去量化。
-
Add
加法运算符用减法和 \(\ell_1\) 距离替代了乘法,因为减法可以通过使用补码轻松转化为加法。
-
NetAug
网络增强鼓励目标小型乘法神经网络作为扩展宽度的大型模型的子模型,目标小型神经网络和增强的大型模型是共同训练的。训练损失和参数更新如下所示:
其中, \(\mathcal L\) 是损失函数, \(W_t\) 是目标小型神经网络的权重, \(W_a\) 是增强神经网络的权重,而 \(W_t\) 是 \(W_a\) 的一个子集。
Hybrid Computing Augment
ShiftAddAug在NetAug的基础上进一步发展,利用强运算符来增强弱运算符。
以 \(n\) 通道的深度可分离卷积为例,NetAug将其扩展了一个因子 \(\alpha\) ,使得卷积权重变为 \(\alpha n\) 个通道。在计算过程中,目标模型只使用前 \(n\) 个通道,而增强模型则采用所有 \(\alpha n\) 个通道。在训练完成后,如公式3所示, \(\alpha n\) 个通道中重要的权重被重新排序到前 \(n\) 个,并且仅将这 \(n\) 个通道导出用于部署。
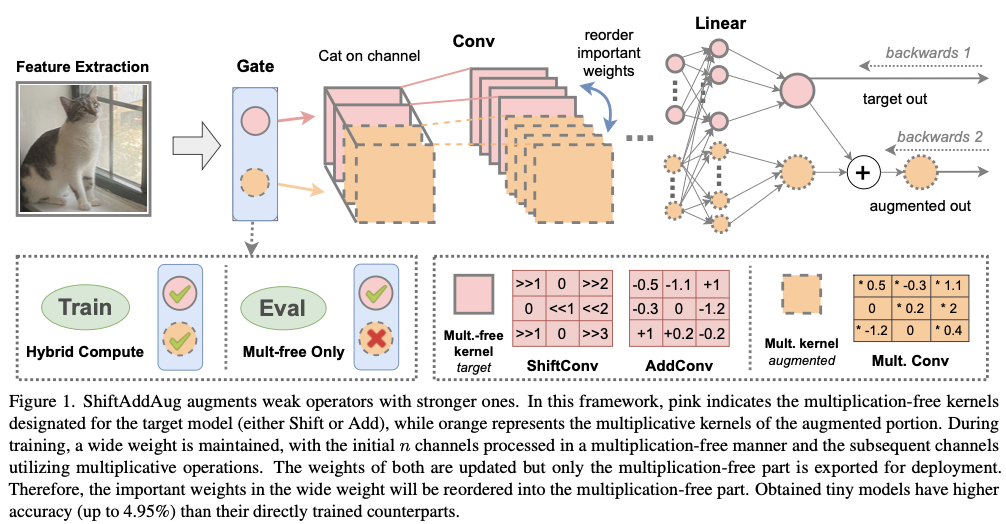
如图1所示,ShiftAddAug使用 \([0, n)\) 通道(目标部分)和 \([n, \alpha n)\) 通道(增强部分)进行不同的计算方法。目标部分将使用无乘法卷积(可选择 \(\texttt{MFConv}\) 、ShiftConv或AddConv),而增强部分则使用乘法卷积 ( \(\texttt{MConv}\) ,即原始卷积)。
由于卷积的通道被扩展,每个卷积的输入也相应地被扩展,可以在概念上将其分为目标部分 \(X_t\) 和增强部分 \(X_a\) ,输出 \(Y_t\) 和 \(Y_a\) 也是如此。在ShiftAddAug中, \(X_t\) 和 \(Y_t\) 主要承载 \(\texttt{MFConv}\) 的信息,而 \(X_a\) 和 \(Y_a\) 则是由原始卷积获得的。
这里讨论了三种常用的构建小型神经网络的操作符:卷积(Conv)、深度可分离卷积(DWConv)和全连接(FC)层。
DWConv的混合计算增强是最直观的:将输入分为 \(X_t\) 和 \(X_a\) ,然后分别使用 \(\texttt{MFConv}\) 和 \(\texttt{MConv}\) 进行计算,并在通道维度上连接得到的 \(Y_t\) 和 \(Y_a\) 。- 对于
Conv,使用全部输入 \(X\) 通过 \(\texttt{MConv}\) 获取 \(Y_a\) 。但要得到 \(Y_t\) ,仍然需要分割输入并分别计算,最后将结果相加。 - 由于
FC层仅用作分类头,其输出不需要增强。将输入分开,并分别使用 \(Linear\) 和 \(ShiftLinear\) 进行计算,并将结果相加。如果使用了偏置,它将优先绑定到无乘法操作符。
Heterogeneous Weight Sharing
-
Dilemma
在每个训练周期结束时,重要的权重将被重新排序到目标部分(使用 \(\ell_1\) 范数来衡量重要性)。这是一个权重共享的过程,是有效增强的关键。
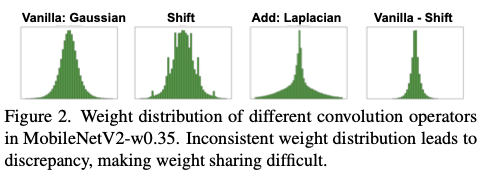
然而,无乘法操作符的权重分布与原始卷积不一致。这导致了权重的不一致性,即原始卷积中的好的权重在MFConv中可能表现不佳。如图2所示,原始卷积中的权重符合高斯分布,而ShiftConv在一些特定值处出现尖峰。AddConv中的权重符合拉普拉斯分布。ShiftConv中的权重是原始卷积的权重加上一个方差较小的拉普拉斯分布。
ShiftAddNas在损失函数中增加了一个惩罚项,以引导权重符合相同的分布,这影响了网络达到其最佳性能。其提出的变换核在卤味的方法上也不起作用,因为损失会发生发散。论文认为他们的方法使训练变得不稳定。这一困境促使论文提出了新的异构权重共享策略。
-
Solution: heterogeneous weight sharing
为了解决上述困境,论文提出了一种新的异构权重共享策略,用于移位和加法操作符。该方法基于原始卷积,并通过一个映射函数 \(\mathcal{R}(\cdot )\) 将参数重新映射到不同分布的权重。通过这种方式,内存中的所有权重将在高斯分布下共享,但会被重新映射到适当的状态以进行计算。
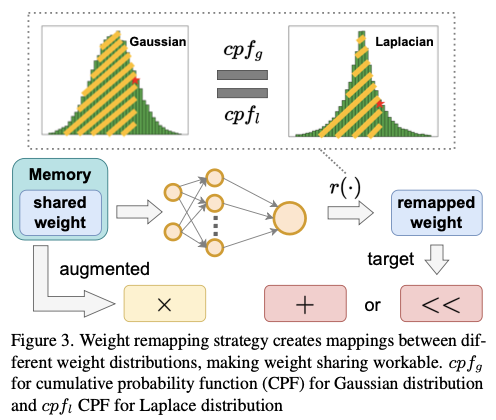
在将高斯分布映射到拉普拉斯分布时,希望原始值和映射结果的累积概率相同。首先,计算高斯中原始权重的累积概率。然后,将结果放入拉普拉斯的百分位点函数中。工作流程如图3所示。高斯的均值和标准差可以通过权重进行计算,但对于拉普拉斯分布,这两个值需要通过先验知识来确定。
其中 \(W_g\) 是符合高斯分布的原始卷积中的权重, \(W_l\) 是通过映射得到的符合拉普拉斯分布的权重。 \(\texttt{FC}\) 是一个全连接层,它在增强训练中经过预训练并被冻结。之所以需要这样做,是因为权重并不完全符合分布。 \(\texttt{cpf}_g(\cdot)\) 是高斯的累积概率函数, \(\texttt{ppf}_l(\cdot)\) 是拉普拉斯的百分位点函数。
Neural Architecture Search
为了在微型模型尺寸下获得最先进的无乘法模型,论文提出了一种两阶段的神经架构搜索(NAS)方法。
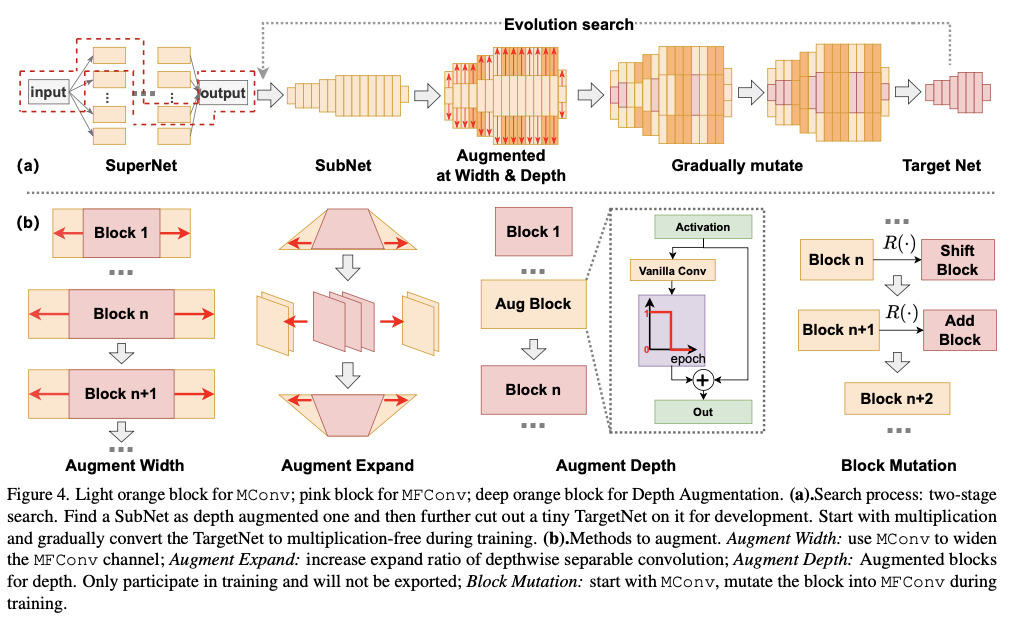
基于增强的理念,ShiftAddAug从一个乘法的超级网络(SuperNet)出发,剪切出一个深度子网络(SubNet)作为深度增强神经网络(depth-augmented NN)。然后选择子网络中的一些层,形成最终使用的微型目标网络(TargetNet)。目标网络应满足预设的硬件限制。这样的设置使得目标网络成为子网络的一部分,便于通过权重共享进行联合训练,如公式3所示。子网络中未被选中的层作为一种深度增强的形式。此外,用于深度增强的层最初被选择,但在训练过程中会逐渐从目标网络中淘汰。
论文还提出了一种新的块变体训练方法,在训练过程中逐渐将乘法运算符转变为无乘法状态,以使训练过程更加稳定。训练开始时包含所有的乘法,目标网络的各层从浅层到深层逐渐变为无乘法。在训练结束时,可以获得一个完全无乘法的目标网络(TargetNet)。
虽然ShiftAddNas直接使用混合计算来训练超级网络(SuperNet),并直接剪切出满足硬件要求的子网络(SubNets),但论文从乘法超级网络出发,将搜索过程分为两个步骤。中间步骤用于增强训练,这是ShiftAddAug的独特之处。

结合前面的宽度增强(Width Augmentation)和扩展增强(Expand Augmentation),根据表2构建了增强部分的搜索空间。遵循tinyNAS的方法来构建超级网络(SuperNet)并剪切出子网络(SubNet)。然后使用进化搜索来寻找后续步骤。
Experiments
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】