Yihan Wang, Lahav Lipson, and Jia Deng
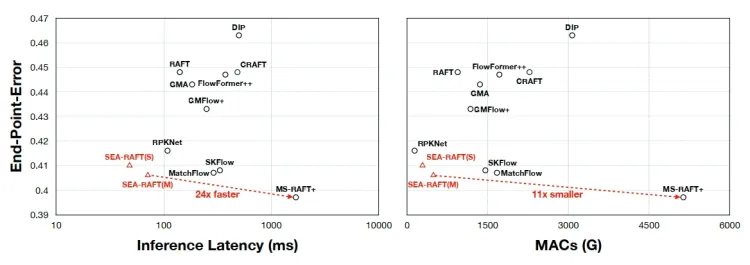
相比较原始的RAFT主要改进有三点:
- laplace 混合loss, 在RAFT中使用的是L1 loss。
- 直接回归初始化光流,在初始状态,不是从0开始,而是重复使用现有上下文解码器来直接预测初始光流,然后供应给输入的frame。
- 能够提升泛化性。
这些改进和现有的RAFT相关工作是垂直的,也就是说可以方便地迁移到别的方法上使用。首先是基于数据集TartanAir进行rigid flow预训练,而后再进行optical flow训练。
和光流相关的任务比如点匹配,在存在大位移、外观变化或均匀区域的情况下,密集流估计容易出错。 在遮挡的情况下或例如 天空,那里的预测必然是不准确的。PDCNet不仅估计了准确的对应关系,而且还估计了何时信任它们。它预测了一个稳健的不确定性地图,识别准确的匹配,并排除不正确和不匹配的像素。本文引进的MOL需要一个混合的,有一个常量方差,这样和L1 loss等价,更适合光流的评估标准。这样在光流中,每一个像素需要一个准确的反馈,不像点匹配中那样,是一个匹配的点集合。
备注,此处增加一些额外知识:
又是一堆新领域知识,来自GeoNet: Unsupervised Learning of Dense Depth, Optical Flow and Camera Pose. Zhichao Yin and Jianping S. 中文参考:https://zhuanlan.zhihu.com/p/37671541
与完整的场景理解相比,理解相机的齐次运动相对容易得多,因为大部分区域都受到相机的约束。为了从本质上分解三维场景的理解问题,将由相机运动控制的场景级一致性运动称为rigid flow,区别于物体运动(object motion)。所以计算rigid flow需要把相机运动算出来,通过把target像素pt映射到source 像素ps上,然后两个像素做差值计算pt-ps,这样得到rigid flow.
方法
3.1 迭代优化
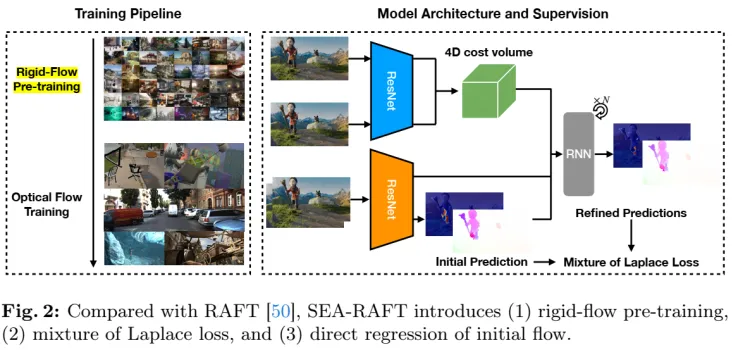
先进行rigid flow预训练,而后进行optical flow训练。
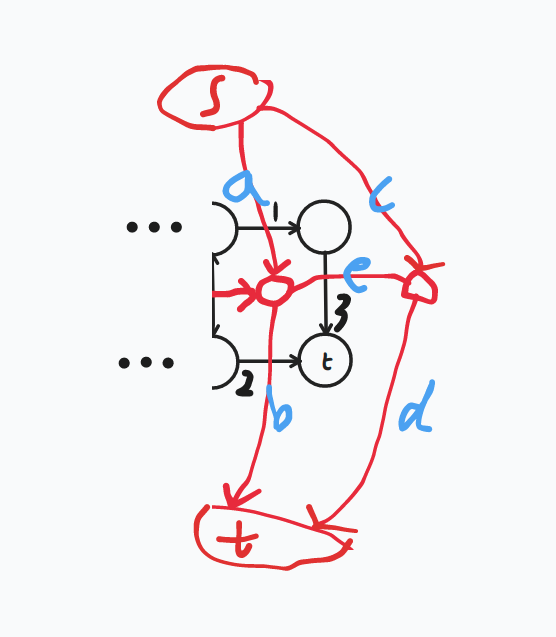
两个解码器,特征解码器F(图中蓝色部分),I1,I2作为输入,输出F(I1), F(I2),上下文解码器C(图中橙色部分),输入I1,输出C(I1)。 然后生成多尺度的4D 关联Vk,此处详细的框架可以参考RAFT原文中的图,如下图,这个图中,画的比较清楚,SEA-RAFT用convnet替换掉了GRU部分。
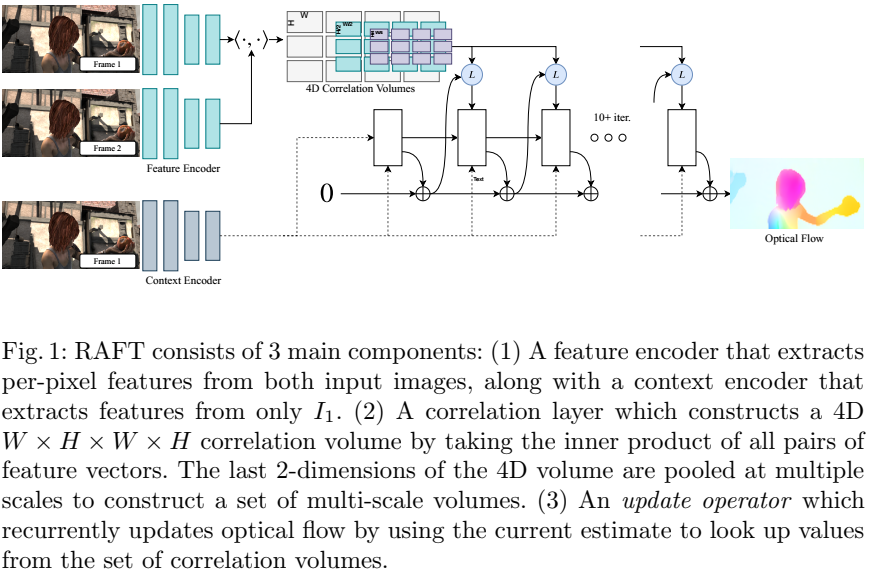
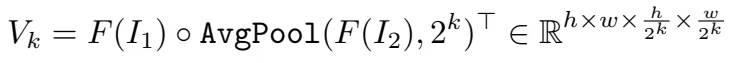 ,RAFT循环优化光流预测u。每一步都得到一个运动特征M
,RAFT循环优化光流预测u。每一步都得到一个运动特征M
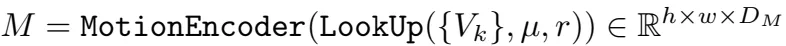
返回I1上每个像素点和I2上临近像素之间在半径r内的相似性。运动特征向量然后通过一个运动编码器转换。RNN但愿输入有一个隐藏状态h,运动特征,以及上下文特征。而后通过flow head得到delta u。
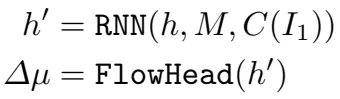
相比较来说,SEA-RAFT需要更少的迭代次数,RAFT相关的算法一般需要在训练过程中每一次需要12次迭代,推理时需要32次迭代,而sea-raft训练过程中只需要4次迭代,推理时需要12次迭代,同时结果已经相当优秀了。
3.2 Mixture-of-Laplace Loss
先前的工作大多是用EPE(endpoint-error loss on all pixels,光流估计中标准的误差度量,是预测光流向量与真实光流向量的欧式距离在所有像素上的均值。)进行监督学习,但是光流训练数据通常包含大量模棱两可、不可预测的样本,这样的数据充满这个loss数据。作者分析数据发现,这种模棱两可的情况主导了误差。
Review of Probabilistic Regression
PS: 概率回归问题,目的是点匹配过程中只找到最佳的匹配给预测概率值,而不是一个子集。
给定两张图I1,I2,光流真值ugt,训练误差损失
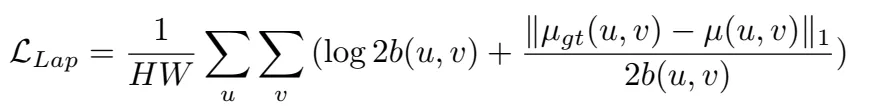
在对数空间进行优化,就是直接优化的值是取对数之后的值。
概率回归probablistic regression无法收敛的原因有两个:1. 回归范围太大,很小值到很大值之间。2. 损失函数来自标准的EPE,这种损失函数只关心L1误差,不关心不确定性估计。提出了两个Laplace distributions,一个是针对正常情况,一个是针对模棱两可的情况,混合稀疏是\alpha=[0,1]
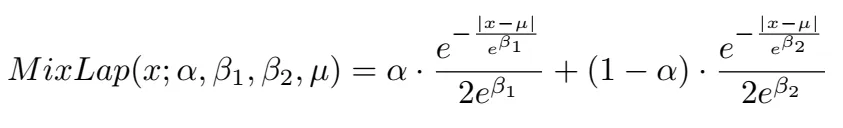
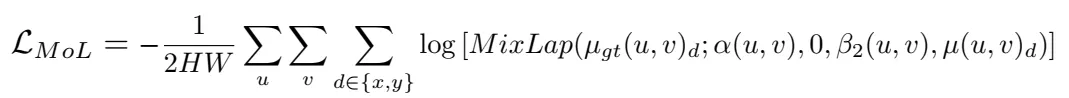
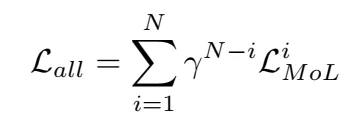
最后loss是这样的,其中r<1, n表示迭代的次数。
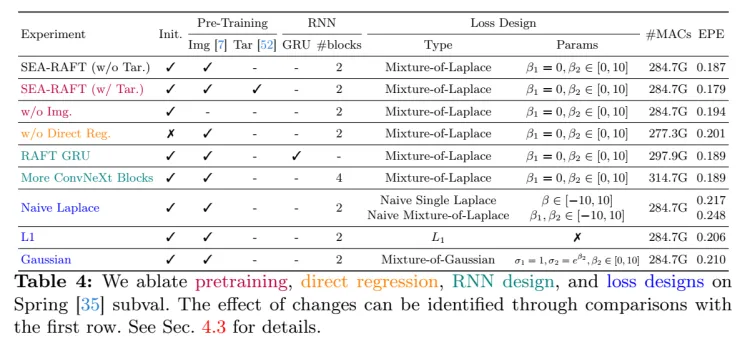
最后根据不同的配置,实验如下表所示。在实验中,使用imagenet做预训练效果会更好,同时loss的使用确实是MOL是更好的,同时把GRU换成了conv,但是可以看到计算量稍微减少了。从实验结果可以看到,替代掉GRU后,增加block数并不能提升。
整体来看,这篇文章工作没有RAFT惊艳是肯定的,但是实现了加速这算是解决了痛点。尤其是工程上用的时候,速度很关键,可以跑一下试试。作者网站上也公开了很多基于RAFT进行SLAM和3d重建的工作,可以参考。作者之一Jia Deng是L. FeiFei的学生,可能和他们创业成立AI 3d重建公司也有关。

相比较原始的RAFT主要改进有三点:
1laplace 混合loss, 在RAFT中使用的是L1 loss。
2直接回归初始化光流,在初始状态,不是从0开始,而是重复使用现有上下文解码器来直接预测初始光流,然后供应给输入的frame。
3能够提升泛化性。
这些改进和现有的RAFT相关工作是垂直的,也就是说可以方便地迁移到别的方法上使用。首先是基于数据集TartanAir进行rigid flow预训练,而后再进行optical flow训练。
和光流相关的任务比如点匹配,在存在大位移、外观变化或均匀区域的情况下,密集流估计容易出错。 在遮挡的情况下或例如 天空,那里的预测必然是不准确的。PDCNet不仅估计了准确的对应关系,而且还估计了何时信任它们。它预测了一个稳健的不确定性地图,识别准确的匹配,并排除不正确和不匹配的像素。本文引进的MOL需要一个混合的,有一个常量方差,这样和L1 loss等价,更适合光流的评估标准。这样在光流中,每一个像素需要一个准确的反馈,不像点匹配中那样,是一个匹配的点集合。
备注,此处增加一些额外知识:
又是一堆新领域知识,来自GeoNet: Unsupervised Learning of Dense Depth, Optical Flow and Camera Pose. Zhichao Yin and Jianping S. 中文参考:https://zhuanlan.zhihu.com/p/37671541
与完整的场景理解相比,理解相机的齐次运动相对容易得多,因为大部分区域都受到相机的约束。为了从本质上分解三维场景的理解问题,将由相机运动控制的场景级一致性运动称为rigid flow,区别于物体运动(object motion)。所以计算rigid flow需要把相机运动算出来,通过把target像素pt映射到source 像素ps上,然后两个像素做差值计算pt-ps,这样得到rigid flow.

先进行rigid flow预训练,而后进行optical flow训练。
两个解码器,特征解码器F(图中蓝色部分),I1,I2作为输入,输出F(I1), F(I2),上下文解码器C(图中橙色部分),输入I1,输出C(I1)。 然后生成多尺度的4D 关联Vk,此处详细的框架可以参考RAFT原文中的图,如下图,这个图中,画的比较清楚,SEA-RAFT用convnet替换掉了GRU部分。

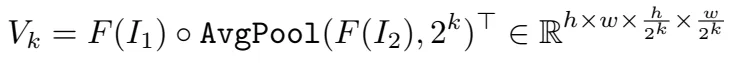
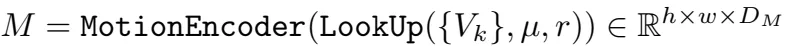
返回I1上每个像素点和I2上临近像素之间在半径r内的相似性。运动特征向量然后通过一个运动编码器转换。RNN但愿输入有一个隐藏状态h,运动特征,以及上下文特征。而后通过flow head得到delta u。
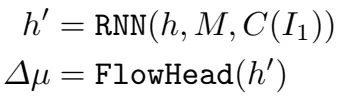
相比较来说,SEA-RAFT需要更少的迭代次数,RAFT相关的算法一般需要在训练过程中每一次需要12次迭代,推理时需要32次迭代,而sea-raft训练过程中只需要4次迭代,推理时需要12次迭代,同时结果已经相当优秀了。
先前的工作大多是用EPE(endpoint-error loss on all pixels,光流估计中标准的误差度量,是预测光流向量与真实光流向量的欧式距离在所有像素上的均值。)进行监督学习,但是光流训练数据通常包含大量模棱两可、不可预测的样本,这样的数据充满这个loss数据。作者分析数据发现,这种模棱两可的情况主导了误差。
Review of Probabilistic Regression
PS: 概率回归问题,目的是点匹配过程中只找到最佳的匹配给预测概率值,而不是一个子集。给定两张图I1,I2,光流真值ugt,训练误差损失
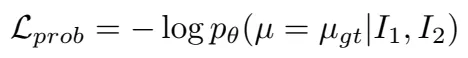
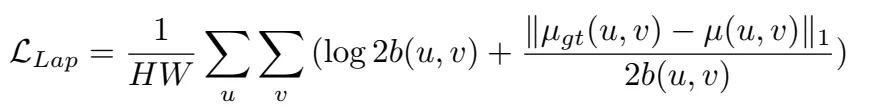
概率回归probablistic regression无法收敛的原因有两个:1. 回归范围太大,很小值到很大值之间。2. 损失函数来自标准的EPE,这种损失函数只关心L1误差,不关心不确定性估计。提出了两个Laplace distributions,一个是针对正常情况,一个是针对模棱两可的情况,混合稀疏是\alpha=[0,1]
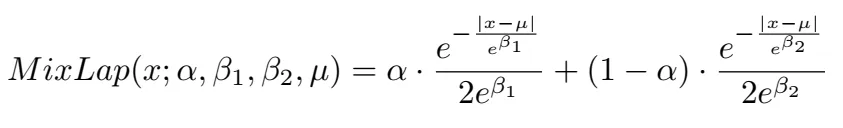
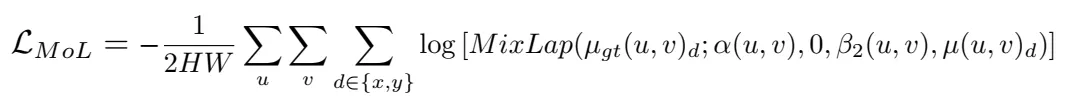
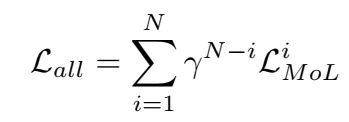
最后根据不同的配置,实验如下表所示。在实验中,使用imagenet做预训练效果会更好,同时loss的使用确实是MOL是更好的,同时把GRU换成了conv,但是可以看到计算量稍微减少了。从实验结果可以看到,替代掉GRU后,增加block数并不能提升。

整体来看,这篇文章工作没有RAFT惊艳是肯定的,但是实现了加速这算是解决了痛点。尤其是工程上用的时候,速度很关键,可以跑一下试试。作者网站上也公开了很多基于RAFT进行SLAM和3d重建的工作,可以参考。作者之一Jia Deng是L. FeiFei的学生,可能和他们创业成立AI 3d重建公司也有关。
若有收获,就点个赞吧




![[转]线性代数库介绍](https://img2020.cnblogs.com/blog/2073733/202108/2073733-20210804182726736-1535014566.png)