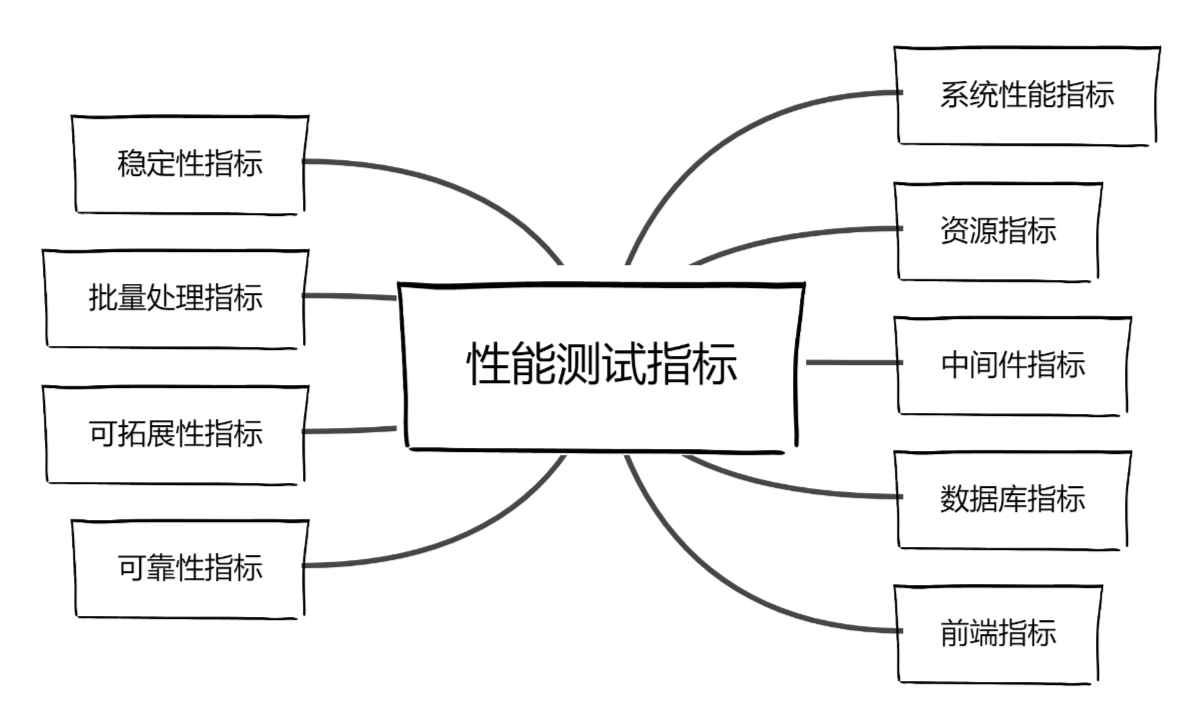
1.系统性能指标
1.1 系统响应时间
响应时间(Response Time: RT)指用户从客户端发起一个请求开始,到客户端接收到从服务器端返回的响应结束,整个过程所耗费的时间。在性能检测中一般以 压力发起端至被压测服务器返回处理结果的时间 为计量,单位一般为秒(s)或毫秒(ms)。
平均响应时间指系统稳定运行时间段内,同一交易的平均响应时间。一般而言,交易响应时间都是指平均响应时间。 平均响应时间指标值应根据不同的交易分别设定,一般情况下,分为 复杂交易响应时间、简单交易响应时间、特殊交易响应时间。其中,特殊交易响应时间的设定必须明确该交易在响应时间方面的特殊性。
不同行业不同业务可接受的响应时间是不同的,一般情况,对于 在线实时交易:
- 互联网企业:500 毫秒以下,例如淘宝业务 10 毫秒左右。
- 金融企业:1 秒以下为佳,部分复杂业务 3 秒以下。
- 保险企业:3 秒以下为佳。
- 制造业:5 秒以下为佳。
对于 批量交易:
时间窗口:即整个压测过程的时间,不同数据量则时间不一样,例如双 11 和 99 大促,数据量级不一样则时间窗口不同。大数据量的情况下,2 小时内可完成压测。
1.2 系统处理能力
系统处理能力是指 系统在利用系统硬件平台和软件平台进行信息处理的能力。系统处理能力通过 系统每秒钟能够处理的交易数量 来评价,交易有两种理解:
- 一是业务人员角度的一笔业务过程;
- 二是系统角度的一次交易申请和响应过程。
前者称为业务交易过程,后者称为事务。两种交易指标都可以评价应用系统的处理能力。一般建议与系统交易日志保持一致,以便于统计业务量或者交易量。系统处理能力指标是技术测试活动中重要指标。
一般情况下,用以下指标来度量:
HPS(Hits per Second):每秒点击次数,单位是次 / 秒。
TPS(Transaction per Second):系统每秒处理交易数,单位是笔 / 秒。
QPS(Query per Second):系统每秒处理查询次数,单位是次 / 秒。
对于互联网业务中,如果某些业务有且仅有一个请求连接,那么 T P S = Q P S = H P S TPS=QPS=HPSTPS=QPS=HPS,一般情况下用 TPS 来衡量 整个业务流程,用 QPS 来衡量 接口查询次数,用 HPS 来表示 对服务器单击请求。
无论 T P S 、 Q P S 、 H P S TPS、QPS、HPSTPS、QPS、HPS,此指标是衡量系统处理能力非常重要的指标,越大越好,根据经验,一般情况下:
金融行业:1000 TPS ~ 50000 TPS,不包括互联网化的活动。
保险行业:100 TPS ~ 100000 TPS,不包括互联网化的活动。
制造行业:10 TPS ~ 5000 TPS。
互联网电子商务:10000 TPS ~ 1000000 TPS。
互联网中型网站:1000 TPS ~ 50000 TPS。互联网小型网站:500 TPS ~ 10000 TPS。
1.3 并发用户
并发用户数(Virtual User:VU)指在同一时刻内,登录系统并进行业务操作的用户数量。
并发用户数(Virtual User:VU)指在同一时刻内,登录系统并进行业务操作的用户数量。
并发用户数对于 长连接系统 来说最大并发用户数即是系统的并发接入能力。对于 短连接系统 而言最大并发用户数并不等于系统的并发接入能力,而是与系统架构、系统处理能力等各种情况相关。例如系统吞吐能力很强,加上短连接一般都有连接复用,往往并发用户数大于系统的并发接入连接数。所以对于大部分短连接类型的系统,吞吐量模式(RPS 模式,Request Per Second)比较适合,也是阿里的最佳实践,PTS 支持 RPS 模式的压测,吞吐量的压测构建和衡量一步到位。 在测试中,采用虚拟用户来模拟现实中用户进行业务操作。
一般情况下,性能测试是将 系统处理能力容量 测出来,而不是测试并发用户数,除了服务器长连接可能影响并发用户数外,系统处理能力不受并发用户数影响,可以用最小的用户数将系统处理能力容量测试出来,也可以用更多的用户将系统处理能力容量测试出来。
1.4 错误率
错误率(Virtual Failure Ratio:FR)指系统在负载情况下,失败交易的概率。错误率=(失败交易数 / 交易总数)×100%。稳定性较好的系统,其错误率应该由 超时 引起,即为超时率。
不同系统对错误率的要求不同,但一般不超出千分之六,即成功率不低于99.4%。
2.资源指标
2.1 CPU
中央处理器(Central Processing Unit:CPU)是一块超大规模的集成电路,是一台计算机的运算核心(Core)和控制核心(Control Unit)。它的功能主要是解释计算机指令以及处理计算机软件中的数据。CPU Load:系统正在干活的多少的度量,队列长度。系统平均负载。
CPU 指标主要指的:CPU使用率、利用率,包括用户态(user)、系统态(sys)、等待态(wait)、空闲态(idle)。
CPU 使用率、利用率要低于业界警戒值范围之内,即小于或者等于 75%、CPU sys% 小于或者等于30%,CPU wait% 小于或者等于5%。单核 CPU 也需遵循上述指标要求。CPU Load 要小于 CPU 核数。
2.2 内存
内存(Memory)是计算机中重要的部件之一,它是与 CPU 进行沟通的桥梁。计算机中所有程序的运行都是在内存中进行的,因此内存的性能对计算机的影响非常大。
现代的操作系统为了最大利用内存,在内存中存放了缓存,因此内存利用率 100% 并不代表内存有瓶颈,衡量系统内有瓶颈主要靠 SWAP(与虚拟内存交换)交换空间利用率,一般情况下,SWAP 交换空间利用率要低于 70%,太多的交换将会引起系统性能低下。
2.3 磁盘吞吐量
磁盘吞吐量(Disk Throughput)是指在无磁盘故障的情况下单位时间内通过磁盘的数据量。
磁盘指标主要有 每秒读写多少兆,磁盘繁忙率,磁盘队列数,平均服务时间,平均等待时间,空间利用率。其中 磁盘繁忙率 是直接反映磁盘是否有瓶颈的重要依据,一般情况下,磁盘繁忙率要低于70%。
2.4 网络吞吐量
网络吞吐量(Network Throughput)是指在无网络故障的情况下 单位时间内通过的网络的数据数量。单位为 Byte/s。网络吞吐量指标用于衡量系统对于网络设备或链路传输能力的需求。当网络吞吐量指标接近网络设备或链路最大传输能力时,则需要考虑升级网络设备。
网络吞吐量指标主要有 每秒有多少兆流量进出,一般情况下不能超过设备或链路最大传输能力的 70%。
2.5 内核参数
操作系统内核参数主要包括 信号量、进程、文件句柄,一般不要超过设置的参数值即可。
3.中间件指标
常用的中间件例如 Tomcat、Weblogic(一个基于 JAVAEE 架构的中间件),指标主要包括 JVM、ThreadPool、JDBC,具体如下:
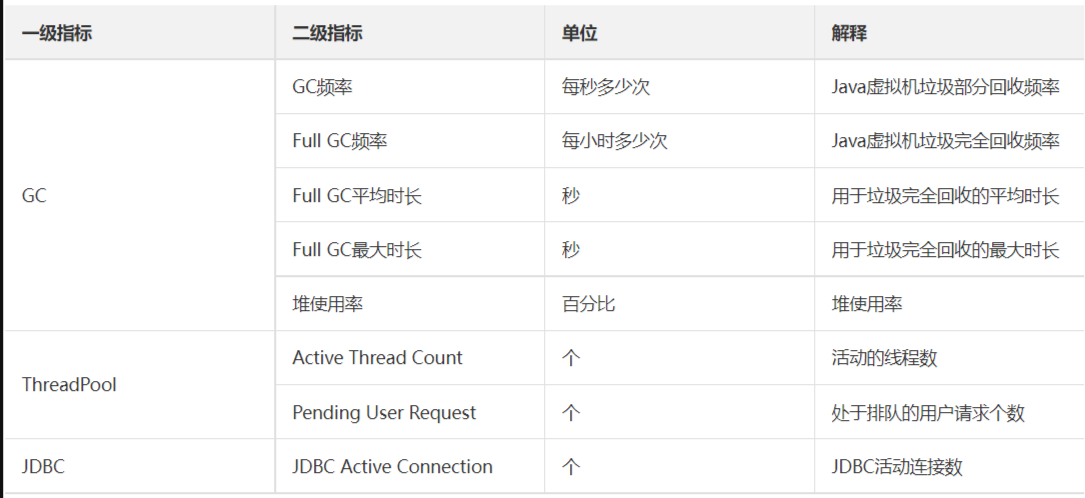
当前正在运行的线程数不能超过设定的最大值。一般情况下系统性能较好的情况下,线程数最小值设置 50 和最大值设置 200 比较合适。
当前运行的 JDBC 连接数不能超过设定的最大值。一般情况下系统性能较好的情况下,JDBC 最小值设置 50 和最大值设置 200 比较合适。
GC(Garbage Collection,垃圾回收)频率不能频繁,特别是FULL GC 更不能频繁,一般情况下系统性能较好的情况下,JVM 最小堆大小和最大堆大小分别设置1024M 比较合适。
4.数据库指标
常用的数据库例如MySQL,指标主要包括 SQL、吞吐量、缓存命中率、连接数 等,具体如下:
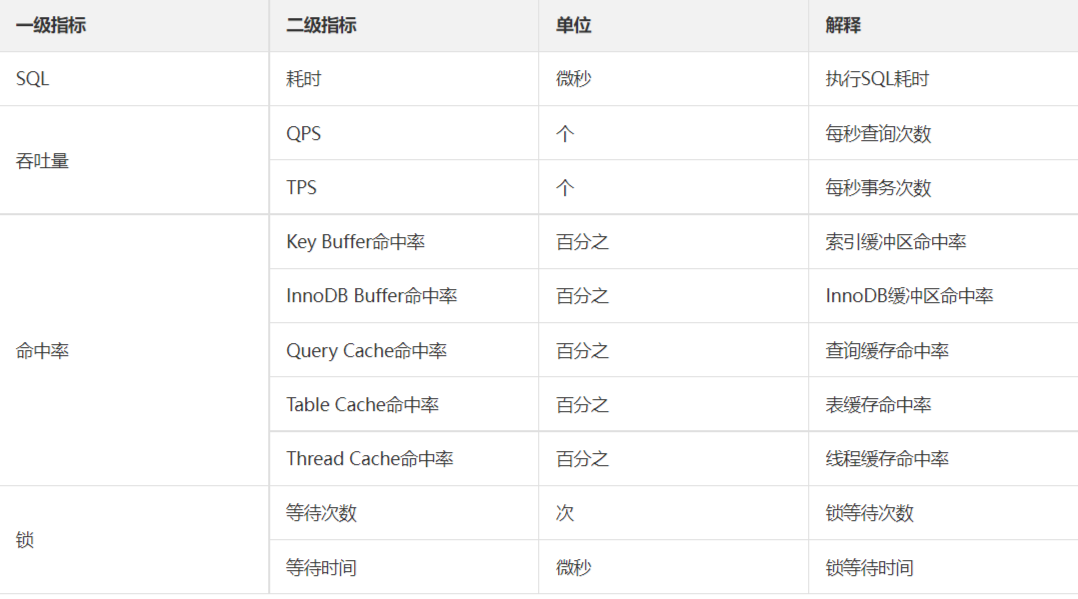
- SQL耗时越小越好,一般情况下微秒级别。
- 命中率越高越好,一般情况下不能低于 95%。
- 锁等待次数越低越好,等待时间越短越好。
5.前端指标
前端指标主要包括 页面展示 和 网络 所花的时间,具体如下:
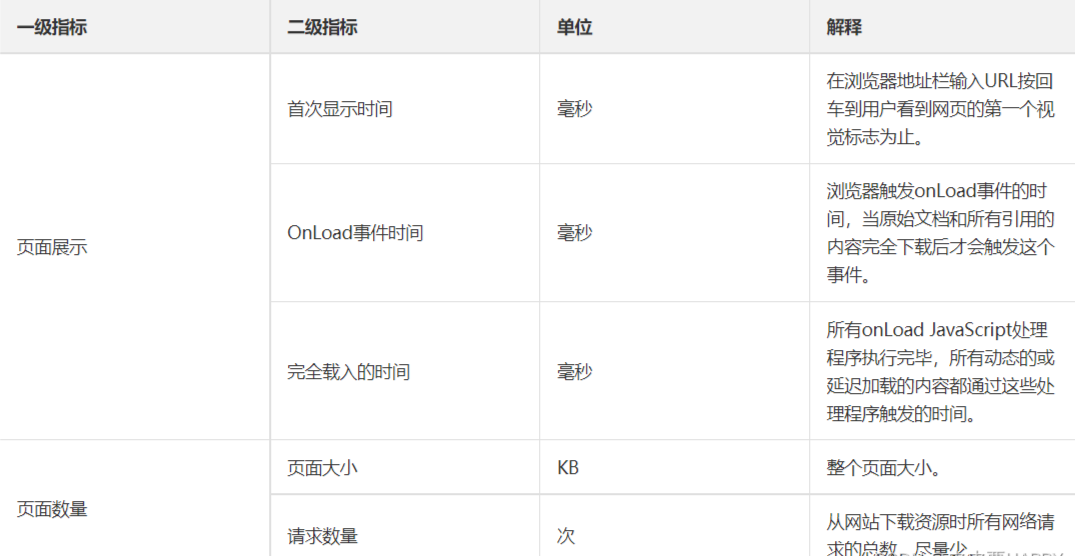
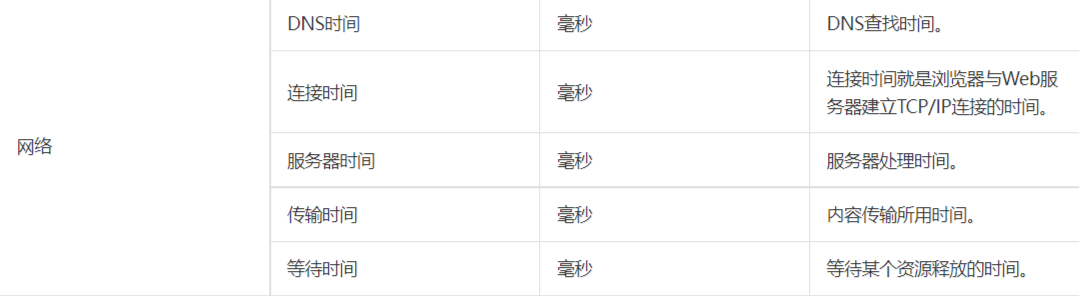
- 页面要尽可能小及压缩。
- 页面展示和花费时间越短越好。
6.稳定性指标
最短稳定时间:系统按照 最大容量的 80% 或标准压力(系统的预期日常压力)情况下运行,能够稳定运行的最短时间。
一般来说,对于正常工作日(8小时)运行的系统,至少应该能保证系统稳定运行 8 小时以上。对于 7×24 运行的系统,至少应该能够保证系统稳定运行 24 小时以上。 如果系统不能稳定的运行,上线后,随着业务量的增长和长时间运行,将会出现性能下降甚至崩溃的风险。
- TPS 曲线稳定,没有大幅度的波动。
- 各项资源指标没有泄露或异常情况。
7.批量处理指标
批量处理程序单位时间内处理的数据数量。一般用每秒处理的数据量来衡量。处理效率 是估算批量处理时间窗口最重要的计算指标。 关于批量处理时间窗口,不同系统的批量处理时间窗口在起止时间上可以部分重叠。另外,同一系统内部,也可能存在多个批量处理过程同时进行,其时间窗口相互叠加。 长时间批量处理将会对联机在线实时交易产生重大的性能影响。
- 在数据量很大的情况下,批处理时间窗口时间越短越好。
- 不能影响实时交易系统性能。
8.可拓展性指标
指应用软件或操作系统以集群方式部署,增加的硬件资源与增加的处理能力之间的关系。计算公式为:(增加性能 / 原始性能)/(增加资源 / 原始资源)× 100%。
扩展能力应通过多轮测试获得扩展指标的变化趋势。 一般扩展能力非常好的应用系统,扩展指标应是 线性或接近线性的,现在很多大规模的分布式系统的扩展能力非常好。
- 理想的扩展能力是:资源增加几倍,性能就提升几倍。
- 扩展能力至少在 70% 以上。
9.可靠性指标
9.1 双机热备
双机热备系统 是 集群的最小组成单位,就是将中心服务器安装成互为备份的两台服务器,并且在同一时间内只有一台服务器运行。当其中运行着的一台服务器出现故障无法启动时,另一台备份服务器会迅速的自动启动并运行(一般为数分钟左右),从而保证整个网络系统的正常运行!双机热备的工作机制实际上是为整个网络系统的中心服务器提供了一种故障自动恢复能力。
对于将双机热备作为可靠性保障手段的系统,可衡量的指标如下:
- 节点切换是否成功及其消耗时间。
- 双机切换是否有业务中断。
- 节点回切是否成功及其耗时
- 双机回切是否有业务中断。
- 节点回切过程中的数据丢失量。在进行双机切换的同时,使用压力发生工具模拟实际业务发生情况
- 对应用保持一定的性能压力,保证测试结果符合生产实际情况。
9.2 集群
对于使用集群方式的系统,主要通过以下方式考量其集群可靠性:
- 集群中某个节点出现故障时,系统是否有业务中断情况出现。
- 在集群中新增一个节点时,是否需要重启系统。
- 当故障节点恢复后,加入集群,是否需要重启系统。
- 当故障节点恢复后,加入集群,系统是否有业务中断情况出现。
- 节点切换需要多长时间。在验证集群可靠性的同时,需根据具体情况使用压力工具模拟实际业务发生相关情况,对应用保持一定的性能压力,确保测试结果符合生产实际情况。
9.3 备份和恢复
本指标为了验证系统的备份、恢复机制是否有效可靠,包括系统的备份和恢复、数据库的备份和恢复、应用的备份和恢复,包括以下测试内容:
- 备份是否成功及其消耗时间。
- 备份是否使用脚本自动化完成。
- 恢复是否成功及其消耗时间。
- 恢复是否使用脚本自动化完成指标体系的运用原则。
- 指标项的采用和考察取决于对相应系统的测试目的和测试需求。被测系统不一样,测试目的不一样,测试需求也不一样,考察的指标项也有很大差别。
- 部分系统涉及额外的前端用户接入能力的,需要考察用户接入并发能力指标。
- 对于批量处理过程的性能验证,主要考虑批量处理效率并估算批量处理时间窗口。
- 如测试目标涉及到系统性能容量,测试需求中应根据相关指标项的定义,明确描述性能指标需求。
- 测试指标获取后,需说明相关的前提条件(如在多少的业务量、系统资源情况等)。