最近,又用我的脚本管理,写了一个代码生成器。
用在一个.net core Web MVC项目中,想要把原来的一些Area,拷贝替换表名。
业务上来说是:把推广模块,单独复制出一个推广-外部渠道的模块。专门给公司外部的推广人员用,但是不影响原来的功能。
本质结构
- 代码生成器 = 模板 + 替换
结论先写在上面了,下面是得到结论的过程。
- 字符串拼接
我一开始,都是用的字符串拼接的方式。那代码就类似于:
var sb = new StringBuilder();
sb.ApendLine(@"......")。//可能是粘贴过来的代码。
sb.ApendLine(@"......")。//可能是个性的代码,不一样的地方。
sb.ApendLine(@"......")。//可能是粘贴过来的代码。
那些粘贴过来的代码,是从目前能运行的代码中复制来的,是相对不变的部分------也就是模板。
那些个性的代码,是变化的部分------也就是模板中要替换的东西。
- 模板引擎
后来看着别人用模板引擎写,我也用模板引擎。
用过t4模板,后来又用了razor模板。
razor的语法,看起来很好,特殊的符号就是@,@{},直接@可以用C#中的变量,加花括号,可以写整段的C#代码。然后没有更多特殊的语法了。
而且razor是我们做一些web项目时,在.cshtml文件中用的语法;相对来说会更加熟悉。相比之下,t4好像有更多特殊语法,没有razor一把刀解决一切的感觉。
所以当时我很喜欢razor模板。

贴一段razor写的winform的,关于单增删改查的,详情页的,前后置代码。
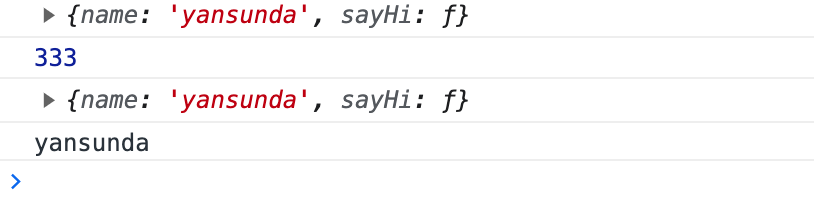
主要的就是要获取【实体类】的反射信息;可以看出【实体类名】经常会替换到生成的类的类名中去;而【字段信息】经常用来生成控件有关的代码。
在用模板引擎后,我更加确定了:代码生成器 = 模板 + 替换。
按上图来说,发黑的那些是相对固定的;@{}花括号里的代码,实现了对可变部分的替换。
- 源码当模板
后来,我开始直接用可以运行的源码当模板了。
好处就是,模板可以单独调试。因为模板不是一直不变的,是有时会调整一下的。
如果用模板引擎,或者拼接的方式:就是在一份源码中调试好了以后,粘贴到模板里。然后运行一下生成,生成的代码,还要再运行一下,才知道有没有粘贴错误。
那我的模板,如果是直接可以运行的源码呢?我就可以单独先调试好模板了。

仍然是上面模板,.cshtml文件,改成.cs文件后,就是这样的。这是一个直接改成.cs文件的初级版本。
然后我可以查找类名替换,查找某些注释去替换。
而且是用我的脚本管理工具,写脚本来实现替换,生成文件的;这样很方便。
- 代码片段的生成
从上面说的开始,方案就变成了简单纯粹的用脚本进行【文本处理】了。

文本处理,源文件可能是csv的,json的,html的;如果格式经常用到,我会把它当做模板或常用的,单独放一起。
以后遇到这种数据源的拷贝一个就行了 ,大多数时候,就是循环拼接的地方不一样;改一改文件路径,改一改循环拼接的地方,我就有了代码片段的生成器。
这在工作中,有时是很有用的。比如上面的模板,是一次工作中,需要把图片放到腾讯云的对象存储时用到的。
通过类似于上面的脚本可以很快找到这个页面用的大概100张照片,复制出来;批量替换src为对象存储的。
当然,这项工作的范围,超过代码生成器了。是文本处理比较多了。
上文写的内容,实际是我之前体会到的。
下文想写:关于可变部分------其实大多是表名,和字段名。
可变部分
可变内容的部分,大部分是根据表名和字段名来变化的。
以前感觉CodeFirst比较好,可以加各种标签之类的,标签可以帮助实现校验类的功能,好像很方便。好像也有种感觉,感觉CodeFirst更先进,DBFirst是老早就有的方式。
但是在实践的过程中,越来越发现,用表名是更为直觉式的方式。
因为用CodeFirst用实体类的类名的话,虽然有上面说的好处,但是会让注意力集中到功能上。
而DBFirst,先去弄清楚(表名,字段名,字段说明),会让注意力放在数据上。而且要弄清楚的内容比较少,注意力容易集中。
哪种思维方式更常用呢?实际是业务导向,注意力在数据变化上,比较常用。
不写代码的人,用户,也是在关注数据怎样;写代码的人,初次接手一个项目,也会点开界面,问熟悉系统的同事,这些都是什么业务,这些数字文本都是代表什么意思。
- 暂时到这里
本来写这个,主要是想写这个大标题的。
但是,回忆了很多,之前的。
现在,写的烦了,不想写了。
等下次,大概再看到,让我想到这些事情的源码的时候;再写吧。