出于阅读文献的需要,导师让我写一个能够爬取dblp上文献资料的爬虫,话不多说,开学。
学习路径总结
- 前端基本知识
- request库与bs库
- 目标特征,规划爬取步骤
- 动态加载的应对方法-selenium
前端基本知识
前端开发是指创建Web页面或应用程序用户可以与之交互的部分。前端开发主要涉及三种语言:HTML、CSS和JavaScript。
-
HTML:HTML 是 HyperText Markup Language(超文本标记语言)的缩写,是用于创建网页内容的标准标记语言。HTML 不是一种编程语言,而是一种标记语言,标记语言是一套标记标签 (markup tag)。HTML 使用标记标签来描述网页。HTML 文档包含了HTML 标签及文本内容。HTML文档也叫做 web 页面。
-
CSS:CSS 是 Cascading Style Sheets(级联样式表)的缩写,用于描述网页上的元素应该如何被渲染。它可以让我们的网页更加美观,例如定义颜色、字体、布局等。
-
JavaScript:JavaScript 是一种轻量级的编程语言。JavaScript 是可插入 HTML 页面的编程代码。JavaScript 插入 HTML 页面后,可由所有的现代浏览器执行。JavaScript 很容易学习。它是一种解释性脚本语言,主要用于在浏览器上实现更复杂的功能。
HTML 基本介绍:
HTML 文档,也称为网页,由嵌套的 HTML 元素和文本组成。HTML元素通过"标签"进行标记。标签通常是成对出现的,比如 <p> 和 </p>,其中 <p> 是开始标签,</p> 是结束标签。
下面是一个简单的 HTML 文档示例:
<!DOCTYPE html>
<html>
<head><title>页面标题</title>
</head>
<body><h1>这是一个标题</h1><p>这是一个段落。</p><p>这是另一个段落。</p><a href="https://www.runoob.com">这是一个链接</a><img src="https://s2.loli.net/2024/03/07/MTh95SVOIcARyL1.jpg" width="720" height="540" /><div id="header">This is a header</div> <p class="text-muted">This is a paragraph.</p><!--class: 给元素指定一个或多个类名,方便通过 CSS 或 JavaScript 操作--><span style="color: red;">This text is red.</span><!--style: 直接为元素定义 CSS 样式--><img src="https://s2.loli.net/2024/01/31/TD67mOMGSt3EkPY.gif" alt="Description" width="180" height="135"><!--其中alt表示图片的描述文本--></body>
</html>
<!DOCTYPE html>声明这是一个 HTML5 文档。<html>元素是根元素,页面的所有其他元素都嵌套在其中。<head>元素包含了所有的头部标签元素。在<head>元素中你可以插入脚本(scripts), 样式文件(CSS),及各种meta信息。<title>元素描述了页面的标题。<body>元素包含了可见的页面内容。<h1>元素定义一个大标题。<p>元素定义一个段落。
渲染效果如图所示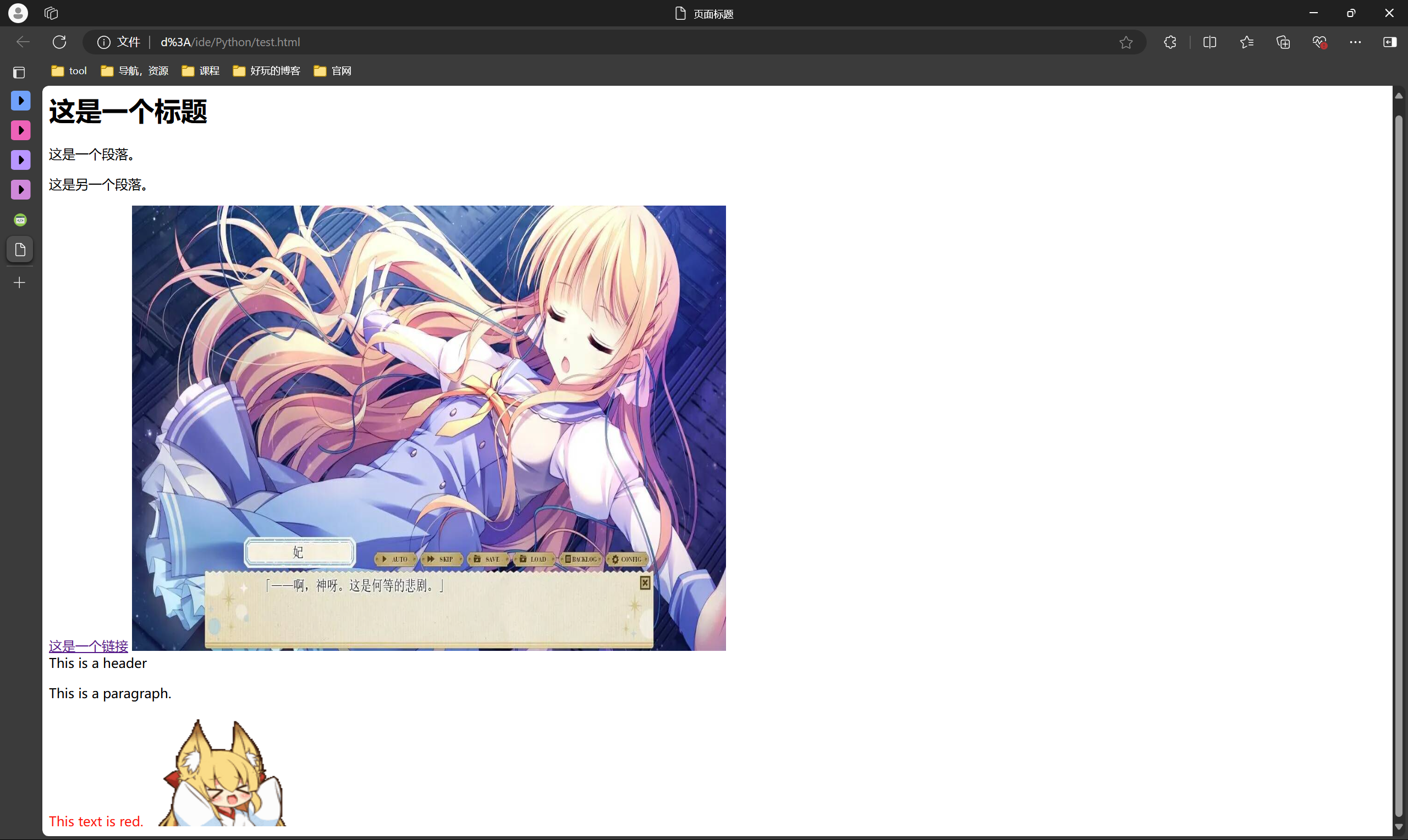
requests库与bs库基本使用方法
requests.get()
res = requests.get(url,headers=headers,params,timeout)
""" url:要抓取的 url 地址。• headers:用于包装请求头信息。• params:请求时携带的查询字符串参数。• timeout:超时时间,超过时间会抛出异常。"""
"res是一个Httpresponse响应对象,具备以下属性"
import requests
response = requests.get('http://www.baidu.com')
print(response.encoding)
response.encoding="utf-8" #更改为utf-8编码
print(response.status_code) # 打印状态码
print(response.url) # 打印请求url
print(response.headers) # 打印头信息
print(response.cookies) # 打印cookie信息
print(response.text) #以字符串形式打印网页源码
print(response.content) #以字节流形式打印request下载图片:
import requests
url = 'https://ss2.bdstatic.com/70cFvnSh_Q1YnxGkpoWK1HF6hhy/it/u=38785274,1357847304&fm=26&gp=0.jpg'
#简单定义浏览器ua信息
headers = {'User-Agent':'Mozilla/4.0'}
#读取图片需要使用content属性
html = requests.get(url=url,headers=headers).content
#以二进制的方式下载图片
with open('C:/Users/Administrator/Desktop/image/python_logo.jpg','wb') as f:f.write(html)此处仅仅介绍get方法,post,cookie,session等内容暂且用不上。
bs库
Beautiful Soup是一个用于解析结构化数据的Python 库。它允许您以与使用开发人员工具与网页交互类似的方式与 HTML 交互。
soup=BeautifulSoup(page.content,"html.parser")
注意是解析content内容,因为解析text可能出现字符编码问题,而content属性保留原始字节,更加方便解码。
而html.parer是其一种解析器,其他解析器参见[解析器概述](Beautiful Soup 文档 — Beautiful Soup 4.12.0 文档 --- Beautiful Soup Documentation — Beautiful Soup 4.12.0 documentation (crummy.com))
而我们已经知道,在html网页中,每个元素都将分配一个div属性,使其具有唯一可识别性。
result=soup.find(id="***")"""这将返回第一个id为***的元素"""
job_elements = results.find_all("div", class_="card-content")"""返回所有class为'card-content'的内容"""
for job_element in job_elements:title_element = job_element.find("h2", class_="title")company_element = job_element.find("h3", class_="company")location_element = job_element.find("p", class_="location")print(title_element.text.strip())#strip用于删除多余空格print(company_element.text.strip())print(location_element.text.strip())print()python_jobs = results.find_all("h2", string="Python")#string将严格匹配h2内容
解析原站html
这一步主要通过f12或是查看网站源代码实现(注意f12通过检查看到的源代码虽然齐整,却是经过处理后的,可能出现与网页源代码不一致的情况)
此处以[dblp中搜索icml 2024为例](dblp: Search for "icml 2024"),我们可以知道dblp搜索页面为我们提供了论文列表,而我们可以通过列表中的url信息访问论文源站,因此爬取策略定为从dblp中获取每一篇论文的url,然后再通过url抓取论文的标题,摘要等信息。
try:# 获取所有 'publ' 类的元素soup = bs(driver.page_source, 'html.parser')all_urls = soup.find_all("nav", attrs={"class": "publ"})except Exception as e:print(f"解析页面时出错: {e}")return []urls = []for publ in all_urls:try:first_a = publ.find('a')if first_a and 'href' in first_a.attrs:urls.append(first_a['href'])except Exception as e:print(f"提取 URL 时出错: {e}")return urls
但此时就会发现一个问题,即dblp的搜索网页采用了动态加载模式,即其不会一次性加载所有内容,而是会在你浏览到页面底部时自动刷新其余内容,这样就带来了一个问题,如果我们直接get源站内容就只能获取网页初始呈现的内容,为了解决这一问题,我们就需要selenium来帮助我们模拟浏览器的这一下拉行为,从而获取网页的所有内容。
selenium
def fetch_dblp_urls(query):# 设置 Edge 浏览器选项edge_options = Options()#配置浏览器启动参数,zedge_options.add_argument("--headless")
"""add_argument(argument) 方法:
用途:向浏览器添加启动参数。
参数:argument 是字符串,表示启动参数。
示例:options.add_argument("--start-maximized")
功能:添加参数 --headless,使浏览器以无界面模式运行(不显示界面)"""# 启动 Edge 浏览器service = Service(r"D:\tool\edgedriver_win32\msedgedriver.exe") # 替换为实际的 msedgedriver 路径"""Service(executable_path) 类:
来源:from selenium.webdriver.edge.service import Service
用途:指定 EdgeDriver 可执行文件的位置"""driver = webdriver.Edge(service=service, options=edge_options)#创建了一个交互对象try:url = f"https://dblp.org/search?q={query}"#f-string字符串格式化,用以在字符串中嵌入变量***driver.get(url)#让浏览器访问指定urltry:# 等待页面加载WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CLASS_NAME, 'publ')))"""WebDriverWait(driver, timeout) 类:
来源:from selenium.webdriver.support.ui import WebDriverWait
用途:显式等待,直到某个条件发生或超时。
until(method, message='') 方法:
用途:等待某个条件成立。
EC.presence_of_element_located(locator):
来源:from selenium.webdriver.support import expected_conditions as EC
用途:判断某个元素是否出现在 DOM 中。
By.CLASS_NAME:
来源:from selenium.webdriver.common.by import By
用途:定位策略,通过元素的 class 属性定位。
功能:
等待最多 10 秒,直到页面中出现 class 为 'publ' 的元素。"""except Exception as e:print(f"页面加载时出错: {e}")# 模拟滚动以加载更多内容last_height = driver.execute_script("return document.body.scrollHeight")"""
driver.execute_script("return document.body.scrollHeight")
execute_script(script, *args) 方法:
用途:在当前页面执行 JavaScript 脚本。
参数:
script:要执行的 JavaScript 代码。
*args:脚本中需要的参数。
功能:
获取当前页面的总高度(滚动高度),用于判断是否需要继续滚动加载。
"""while True:try:# 滚动到底部driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
"""JavaScript 脚本解释:
window.scrollTo(x, y):将窗口滚动到指定位置。
document.body.scrollHeight:页面的总高度。
功能:
将页面滚动到最底部,触发懒加载或无限滚动加载新内容"""time.sleep(2) # 等待加载更多内容# 检查新内容是否已加载new_height = driver.execute_script("return document.body.scrollHeight")if new_height == last_height: # 如果没有新内容breaklast_height = new_heightexcept Exception as e:print(f"滚动过程中出错: {e}")breaktry:# 获取所有 'publ' 类的元素soup = bs(driver.page_source, 'html.parser')all_urls = soup.find_all("nav", attrs={"class": "publ"})except Exception as e:print(f"解析页面时出错: {e}")return []urls = []for publ in all_urls:try:first_a = publ.find('a')if first_a and 'href' in first_a.attrs:urls.append(first_a['href'])except Exception as e:print(f"提取 URL 时出错: {e}")return urlsexcept Exception as e:print(f"处理过程中出现错误: {e}")finally:driver.quit() # 关闭浏览器
这里是本次项目使用到的selenium模块,当然selenium内容还有很多,就不再在一一列举了。
总结一下:
- 获取用户输入的查询关键字和年份。
- 使用 Selenium 启动无界面的 Edge 浏览器,访问构造的 DBLP 搜索页面。
- 等待页面加载指定的元素,确保内容已显示。
- 模拟用户滚动操作,加载更多内容,直到所有内容加载完成。
- 使用 BeautifulSoup 解析页面源代码,提取所有目标链接。
- 返回提取的链接列表。
- 根据目标链接指向的源站,重复使用bs提取其中的abstract与title,由于各种不同源站结构不同,所以分类讨论的过程极其折磨。
这里仅提供其中一个示例
elif "openreview" in url:#divcontent title=soup.find("h2", attrs={"class": "citation_title"})if title:title=title.textelse:title=Noneabstract = soup.find("span", attrs={"class": "note-content-value"})if abstract:abstract = abstract.textelse:abstract = None
最后将爬取的摘要与信息写入文件,就大功告成了。







![GoogLeNet训练CIFAR10[Pytorch+训练信息+.pth文件]](https://img2024.cnblogs.com/blog/3436794/202410/3436794-20241003145032765-402076656.png)