1.引言
使用地平线 征程 6 算法工具链进行模型部署时,如果你的模型输入是图像格式,通常会遇到如下信息。

对于初学者,可能会存在一些疑问,比如:
- nv12 是什么?
- 明明算法模型是一个输入,为什么看 hbm 模型,有 y 和 uv 两个输入?
- 为什么 uv 的 valid shape 不是 (1,224,224,2) ,而是(1,112,112,2)
- stride 中为什么有 -1?如果需要自己计算,计算公式是什么?
- 为什么 aligned byte size 是 -1,而不是一个具体的值?如果需要自己计算,计算公式是什么?
相信阅读完本文,可以帮助大家理解上面 5 个问题,下面来一起看一下。
NV12 是一种广泛应用的图像格式,特别在视频编解码领域,自动驾驶领域,嵌入式端图像输入一般都是 NV12,例如英伟达和地平线。
NV12 属于 YUV 颜色空间中的一种,采用 YUV 4:2:0 的采样方式。主要特点是将亮度(Y)与色度(UV)数据分开存储,地平线使用的 NV12,U 和 V 色度分量交替存储。
在深入理解 NV12 之前,我们首先需要对 YUV 颜色空间有基本的了解,YUV 理论介绍参考地平线社区文章:常见图像格式 中的部分章节。
2.YUV
YUV 是一种彩色图像格式,其中 Y 表示亮度(Luminance),用于指定一个像素的亮度(可以理解为是黑白程度),U 和 V 表示色度(Chrominance 或 Chroma),用于指定像素的颜色,每个数值都采用 UINT8 表示,如下图所示。YUV 格式采用亮度-色度分离的方式,也就是说只有 U、V 参与颜色的表示,这一点与 RGB 是不同的。

不难发现,即使没有 U、V 分量,仅凭 Y 分量我们也能 “识别” 出一幅图像的基本内容,只不过此时呈现的是一张黑白图像。而 U、V 分量为这些基本内容赋予了色彩,黑白图像演变为了彩色图像。这意味着,我们可以在保留 Y 分量信息的情况下,尽可能地减少 U、V 两个分量的采样,以实现最大限度地减少数据量,这对于视频数据的存储和传输是有极大裨益的。这也是为什么,YUV 相比于 RGB 更适合视频处理领域。
2.1 YUV 常见格式
据研究表明,人眼对亮度信息比色彩信息更加敏感。YUV 下采样就是根据人眼的特点,将人眼相对不敏感的色彩信息进行压缩采样,得到相对小的文件进行播放和传输。根据 Y 和 UV 的占比,常用的 YUV 格式有:YUV444,YUV422,YUV420 三种。
用三个图来直观地表示不同采集方式下 Y 和 UV 的占比。
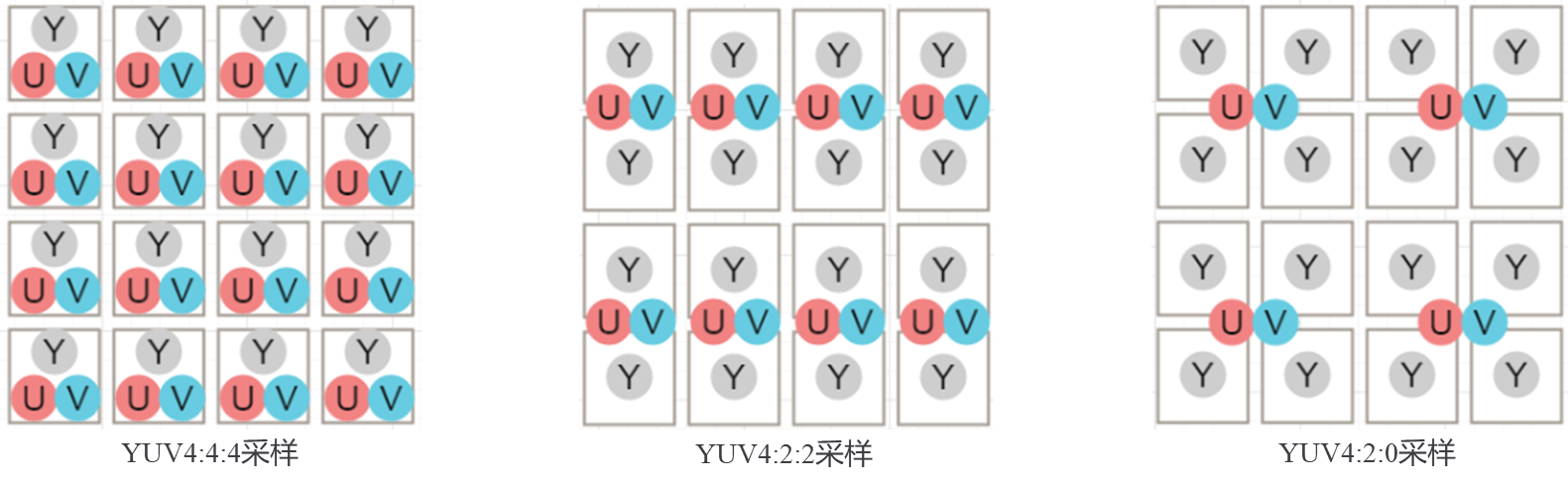
YUV444:每一个 Y 分量对应一对 UV 分量,每像素占用 3 字节(Y + U + V = 8 + 8 + 8 = 24bits);
YUV422:每两个 Y 分量共用一对 UV 分量,每像素占用 2 字节(Y + 0.5U + 0.5V = 8 + 4 + 4 = 16bits);
YUV420:每四个 Y 分量共用一对 UV 分量,每像素占用 1.5 字节(Y + 0.25U + 0.25V = 8 + 2 + 2 = 12bits);
此时来理解 YUV4xx 中的 4,这个 4,实际上表达了最大的共享单位!也就是最多 4 个 Y 共享一对 UV。
2.2 YUV420 详解
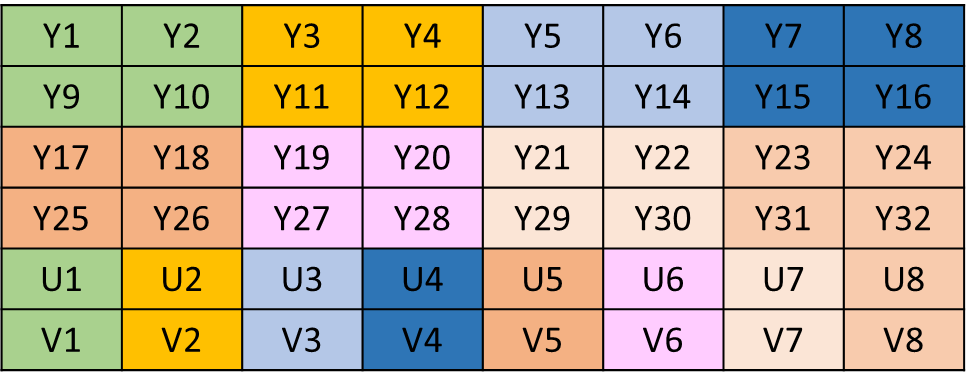
在 YUV420 中,一个像素点对应一个 Y,一个 4X4 的小方块对应一个 U 和 V,每个像素占用 1.5 个字节。依据不同的 UV 分量排列方式,还可以将 YUV420 分为 YUV420P 和 YUV420SP 两种格式。
YUV420P 是先把 U 存放完,再存放 V,排列方式如下图:
YUV420SP 是 UV、UV 交替存放的,排列方式如下图:
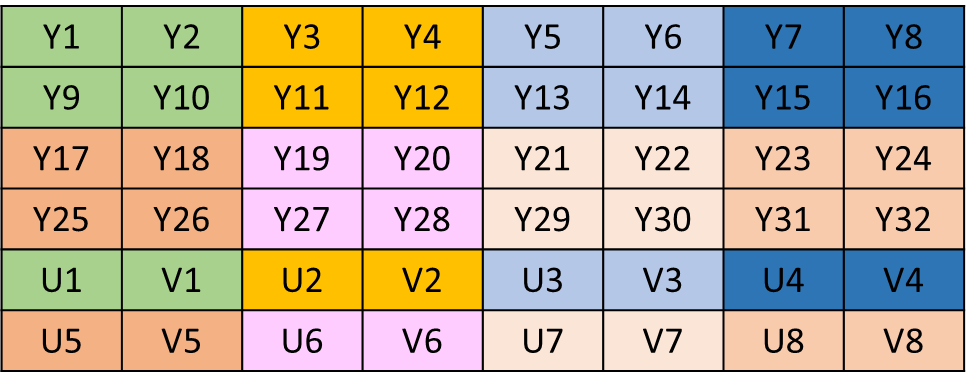
此时 ,相信大家就可以理解 YUV420 数据在内存中的长度应该是:width * height * 3 / 2 。
3.NV12 代码示例
地平线使用的 NV12 图像格式属于 YUV 颜色空间中的 YUV420SP 格式,每四个 Y 分量共用一组 U 分量和 V 分量,Y 连续存放,U 与 V 交叉存放,下面介绍两种常见库将图像转为 nv12 的代码。
3.1 PIL 将图像转为 nv12
import sys
import numpy as np
from PIL import Imagedef generate_nv12(input_path, output_path='./'):img = Image.open(input_path)w,h = img.size# 将图片转换为YUV格式yuv_img = img.convert('YCbCr')y_data, u_data, v_data = yuv_img.split()# 将Y、U、V通道数据转换为字节流y_data_bytes = y_data.tobytes()u_data_bytes = u_data.resize((u_data.width // 2, u_data.height // 2)).tobytes()v_data_bytes = v_data.resize((v_data.width // 2, v_data.height // 2)).tobytes()# 将UV数据按UVUVUV...的形式排列uvuvuv_data = bytearray()for u_byte, v_byte in zip(u_data_bytes, v_data_bytes):uvuvuv_data.extend([u_byte, v_byte])# y datay_path = output_path + "_y.bin"with open(y_path, 'wb') as f:f.write(y_data_bytes)# uv datauv_path = output_path + "_uv.bin"with open(uv_path, 'wb') as f:f.write(uvuvuv_data)nv12_data = y_data_bytes + uvuvuv_data# 保存为NV12格式文件nv12_path = output_path + "_nv12.bin"with open(nv12_path, 'wb') as f:f.write(nv12_data)# 用于bc模型的输入y = np.frombuffer(y_data_bytes, dtype=np.uint8).reshape(1, h, w, 1).astype(np.uint8)uv = np.frombuffer(uvuvuv_data, dtype=np.uint8).reshape(1, h//2, w//2, 2).astype(np.uint8)return y, uvif _name_ == "__main__":if len(sys.argv) < 3:print("Usage: python resize_image.py <input_path> <output_path>")sys.exit(1)input_path = sys.argv[1]output_path = sys.argv[2]y, uv = generate_nv12(input_path, output_path)
3.2 cv2 将图像转为 nv12
import cv2
import numpy as npdef image2nv12(image):image = image.astype(np.uint8)height, width = image.shape[0], image.shape[1]yuv420p = cv2.cvtColor(image, cv2.COLOR_BGR2YUV_I420).reshape((height * width * 3 // 2, ))y = yuv420p[:height * width]uv_planar = yuv420p[height * width:].reshape((2, height * width // 4))uv_packed = uv_planar.transpose((1, 0)).reshape((height * width // 2, ))nv12 = np.zeros_like(yuv420p)nv12[:height * width] = y # y分量nv12[height * width:] = uv_packed # uv分量,uvuv交替存储,征程6拆开就是这种# return y, uv_packed # 分开返回return nv12 # 合在一起返回nv12,看大家需要image = cv2.imread("./image.jpg")
nv12 = image2nv12(image)
阅读到这儿,相信前 3 个疑问,已经介绍清楚了,下面再来看剩下 2 个问题。
4.对齐规则
对于 NV12 输入,地平线 BPU 要求模型输入 HW 都是偶数,主要是为了满足 UV 是 Y 的一半的要求。
有效数据排布和对齐数据排布用 validShape 和 stride 表示。
- validShape 是有效数据的 shape。
- stride 表示 validShape 各维度的步长,描述跨越张量各个维度所需要经过的字节数。当数据类型为 NV12(Y、UV)时比较特殊,只要求 W 方向 32 对齐。
BPU 对模型输入输出内存首地址有对齐限制,要求输入与输出内存的首地址 32 对齐。
使用 hbUCPMalloc 与 hbUCPMallocCached 接口申请的内存首地址默认 32 对齐。 当用户申请一块内存,并使用偏移地址作为模型的输入或输出时,请检查偏移后的首地址是否 32 对齐。
完了,没看懂,什么有效数据?步长?W 方向 32 对齐?首地址 32 对齐?没看懂?举个例子:
为了直观展示,假设对齐前的 NV12 有效数据的 shape:H=4,W=8,步长 Stride=12,Y 分量和 UV 分量分别存储在两块不同的内存空间中,内存首地址分别用 mem[0]和 mem[1]表示,Y 分量占用 412=48 字节,UV 分量共占用 212=24 字节。

相信到这儿,你懂了。
5.动态输入 -1 介绍
当模型输入张量属性 stride 中含有 -1 时,代表该模型的输入是动态的,需要根据实际输入对动态维度进行填写。此时需要大家想起来:
- W 方向保证 32 对齐。
- stride[idx] >= stride[idx+1] ∗ validShape.dimensionSize[idx+1],其中 idx 代表当前维度。
举个例子,如文章最上方的截图:
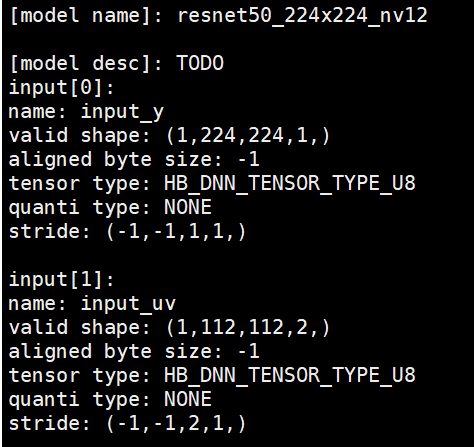
- input_y : validShape = [1,224,224,1], stride = [-1,-1,1,1]
- input_uv : validShape = [1,112,112,2], stride = [-1,-1,2,1]
stride 计算如下所示,保证动态维度 32 对齐,其中 ALIGN_32 代表 32 字节对齐:
input_y :
- stride[3] = 1,结合 tensor type 看,每个元素 8bit 也就是 1byte 大小;
- stride[2] = 1;
- stride[1] = ALIGN_32(stride[2] * validShape.dimensionSize[2]) = ALIGN_32(1 * 224) = 224;
- stride[0] = ALIGN_32(stride[1] * validShape.dimensionSize[1]) = ALIGN_32(224 * 224) = 50176;
input_uv :
- stride[3] = 1,结合 tensor type 看,每个元素 8bit 也就是 1byte 大小;
- stride[2] = 2;
- stride[1] = ALIGN_32(stride[2] * validShape.dimensionSize[2]) = ALIGN_32(2 * 112) = 224;
- stride[0] = ALIGN_32(stride[1] * validShape.dimensionSize[1]) = ALIGN_32(224 * 112) = 25088;
在准备输入时,就需要按照上面的 stride 和 validshape 准备数据了。
但此时,无法解释为什么 nv12 输入时,这里的 stride 为什么必须是 -1,毕竟可以通过公式计算得到啊,为什么工具不计算好直接提供出来呢?别问,问就是还没理解透彻,这是甲鱼的臀部——“规定”。
看到这儿,第 4 个问题也解决了。
6.aligned byte size 如何计算
NV12 输入时,alignedByteSize = stride[0]。
在别的输入格式时,可能会遇到 alignedByteSize > stride[0] 的情况,这就是另外的故事了,下次再聊~