1. 基于某个字段
比如要处理一批数据,把 id 作为查询条件,500 条数据作为一个批次
工具类代码如下:
public class DataLoopUtil {/*** 基于某个字段(比如 id, createTime 等), 循环处理数据* P > Param* R > Result** @param dataQueryFunction 查询数据* @param dataProcessConsumer 处理数据* @param extractParamFunction 从 R 中获取 P* @param startParam 起始参数*/public static <P, R> void processData(Function<P, List<R>> dataQueryFunction,Consumer<List<R>> dataProcessConsumer,Function<R, P> extractParamFunction,P startParam) {List<R> dataList;do {dataList = dataQueryFunction.apply(startParam);if (CollUtil.isNotEmpty(dataList)) {log.info("data process result {}", LambdaUtils.mapToList(dataList, extractParamFunction));dataProcessConsumer.accept(dataList);startParam = extractParamFunction.apply(dataList.get(dataList.size() - 1));}} while (CollUtil.isNotEmpty(dataList));log.info("processData exist start param is {}", startParam);}
}
使用代码如下
@Component
public class DataLoopService {@Resourceprivate MemberUserMapper memberUserMapper;public void loopGetMemberInfo() {DataLoopUtil.processData(getMemberQueryFn(), getMemberProcessConsumer(), MemberUserDO::getId, 600L);}// 查数据 Functionprivate Function<Long, List<MemberUserDO>> getMemberQueryFn() {return startId -> memberUserMapper.selectList(new LambdaQueryWrapper<MemberUserDO>().gt(MemberUserDO::getId, startId).last(" limit 3"));}// 处理数据 Consumerprivate Consumer<List<MemberUserDO>> getMemberProcessConsumer() {return dataList -> dataList.forEach(member -> {MemberUserDO update = new MemberUserDO();update.setId(member.getId());update.setRegisterIp(member.getId().toString());memberUserMapper.updateById(update);});}
}
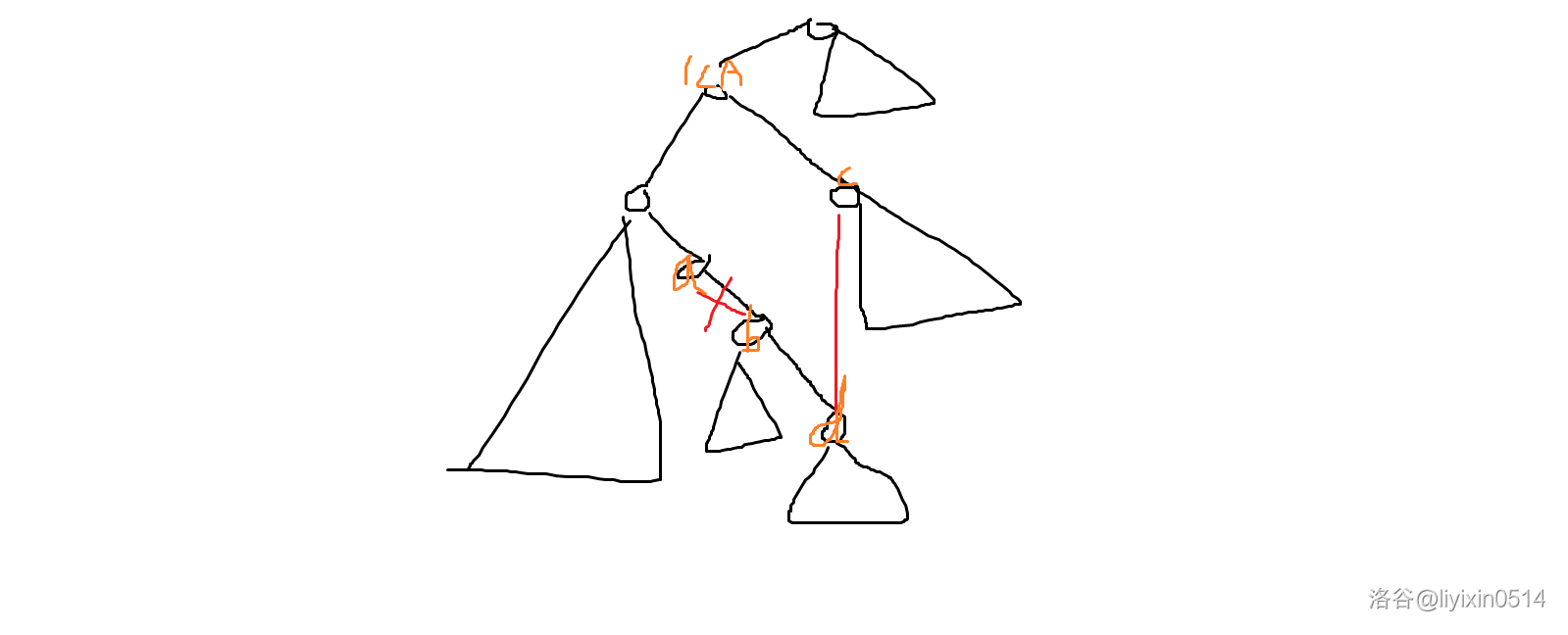
2. 基于上一批字段
比如初始化部门表的 parent_ids,先从第一批开始,然后开始第二批,轮子如下
工具类代码是如下
/*** 基于上次结果,循环处理数据* 比如查询部门,先用顶级部门 id 查询,查到下级,再用下级的 ids 查下下级*/
public static <P, R> void processDataBatch(Function<Collection<P>, Collection<R>> dataQueryFunction,Consumer<Collection<R>> dataProcessConsumer,Function<Collection<R>, Collection<P>> extractParamFunction,Collection<P> startParam) {Collection<R> dataList;do {log.info("loop utils param is {}", JSONUtil.toJsonStr(startParam));dataList = dataQueryFunction.apply(startParam);if (CollUtil.isNotEmpty(dataList)) {dataProcessConsumer.accept(dataList);startParam = extractParamFunction.apply(dataList);}} while (CollUtil.isNotEmpty(dataList));log.info("processData exist start param is {}", startParam);
}
使用代码如下
@Override
public void initAncestor() {// 先查出第一批根部门List<DeptDO> deptDOList = deptMapper.selectListByParentId(Lists.newArrayList(DeptDO.PARENT_ID_ROOT));List<Long> parentIds = LambdaUtils.mapToList(deptDOList, DeptDO::getId);// 先处理根部门deptMapper.update(new LambdaUpdateWrapper<DeptDO>().set(DeptDO::getParentIds, DeptDO.PARENT_ID_ROOT_STR).eq(DeptDO::getParentId, 0L));// 循环处理DataLoopUtil.processDataBatch(getListDeptFn(),getDeptConsumer(),getParamExtractFn(),parentIds);
}////////////////////////// 下面是参数获取方法 //////////////////////////private Function<Collection<DeptDO>, Collection<Long>> getParamExtractFn() {return deptList -> LambdaUtils.mapToSet(deptList, DeptDO::getId);
}private Function<Collection<Long>, Collection<DeptDO>> getListDeptFn() {return parentIds -> deptMapper.selectListByParentId(parentIds);
}private Consumer<Collection<DeptDO>> getDeptConsumer() {return deptList -> {if (CollUtil.isEmpty(deptList)) {return;}// 批量查询父级部门Set<Long> parentIds = LambdaUtils.mapToSet(deptList, DeptDO::getParentId);List<DeptDO> parentDeptList = deptMapper.selectBatchIds(parentIds);Map<Long, DeptDO> parentMap = LambdaUtils.toMap(parentDeptList, DeptDO::getId);// 开始处理Map<Long, List<DeptDO>> deptMap = LambdaUtils.groupList(deptList, DeptDO::getParentId);deptMap.forEach((parentId, list) -> {DeptDO parent = parentMap.get(parentId);if (parent == null) {log.info("parent dept not exists, id {}", parentId);return;}list.forEach(dept -> deptMapper.update(new LambdaUpdateWrapper<DeptDO>().set(DeptDO::getParentIds, parent.getParentIds() + "," + parent.getId()).eq(DeptDO::getId, dept.getId())));});};
}