数据采集与融合技术实验课程作业一
| 作业所属课程 | https://edu.cnblogs.com/campus/fzu/2024DataCollectionandFusiontechnology |
|---|---|
| 作业链接 | https://edu.cnblogs.com/campus/fzu/2024DataCollectionandFusiontechnology/homework/13286 |
| gitee码云代码位置 | https://gitee.com/wang-qiangsy/crawl_project/tree/master/作业一 |
| 学号 | 102202106 |
目录
- 数据采集与融合技术实验课程作业一
- 作业内容
- 作业①:
- 作业②:
- 作业③:
- 作业①:爬取大学排名信息
- 主要代码
- 代码运行结果
- 作业心得
- 作业②:爬取商城中商品名称与价格
- 主要代码
- 代码运行结果
- 作业心得
- 作业③:爬取网页JPEG和JPG格式文件
- 主要代码
- 代码运行结果
- 作业心得
- 作业内容
作业内容
作业①:
要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020)的数据,屏幕打印爬取的大学排名信息。
输出信息:
| 排名 | 学校名称 | 省市 | 学校类型 | 总分 |
|---|---|---|---|---|
| 1 | 清华大学 | 北京 | 综合 | 852.5 |
| 2 | ...... |
作业②:
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
输出信息:
| 序号 | 价格 | 商品名 |
|---|---|---|
| 1 | 65.00 | xxx |
| 2 | ...... |
作业③:
要求:爬取一个给定网页( https://news.fzu.edu.cn/yxfd.htm)或者自选网页的所有JPEG和JPG格式文件
输出信息:将自选网页内的所有JPEG和JPG文件保存在一个文件夹中
作业①:爬取大学排名信息
主要代码
# 定义获取院校数据的函数
def get_university_data():url = 'https://www.shanghairanking.cn/rankings/bcur/2021'response = requests.get(url)response.encoding = 'utf-8'soup = BeautifulSoup(response.text, 'html.parser')university_data = []# 查找包含院校信息的表格table = soup.find('table')for row in table.find_all('tr')[1:]: cols = row.find_all('td')if len(cols) > 1:rank = cols[0].text.strip()name = ' '.join(cols[1].text.strip().split()) # 删除换行符province = cols[2].text.strip()type_ = cols[3].text.strip() # 院校类型total_score = cols[4].text.strip() # 总分university_data.append((rank, name, province, type_, total_score)) return university_data
代码运行结果

作业心得
- 数据抓取与解析
在这次作业中,我使用了 requests 库来发送 HTTP 请求,并使用 BeautifulSoup 库来解析 HTML 内容。这两个库的结合实现数据抓取和解析。通过解析网页中的表格数据,我能够提取出每所大学的排名、名称、所在省份、类型和总分。 - 数据展示
为了更好地展示抓取到的数据,我使用了 PrettyTable 库。这个库可以将数据以表格的形式美观地展示出来。通过设置表格的字段名称和对齐方式,我能够清晰地展示每所大学的详细信息。
作业②:爬取商城中商品名称与价格
主要代码
# 获取网页内容
def get_html(url):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36'}try:response = requests.get(url, headers=headers)response.raise_for_status() # 确保请求成功return response.textexcept requests.RequestException as e:print(f"Error fetching data from {url}: {e}")return ""# 解析网页内容,提取商品名称和价格
def parse_page(data):uinfo = []plt = re.findall(r'"sku_price":"([\d.]+)"', data) # 商品价格tlt = re.findall(r'"ad_title_text":"(.*?)"', data) # 商品名称min_length = min(len(plt), len(tlt))for i in range(min_length):price = plt[i]name = tlt[i].strip()uinfo.append((name, price)) # 添加名称和价格到uinfo列表return uinfo
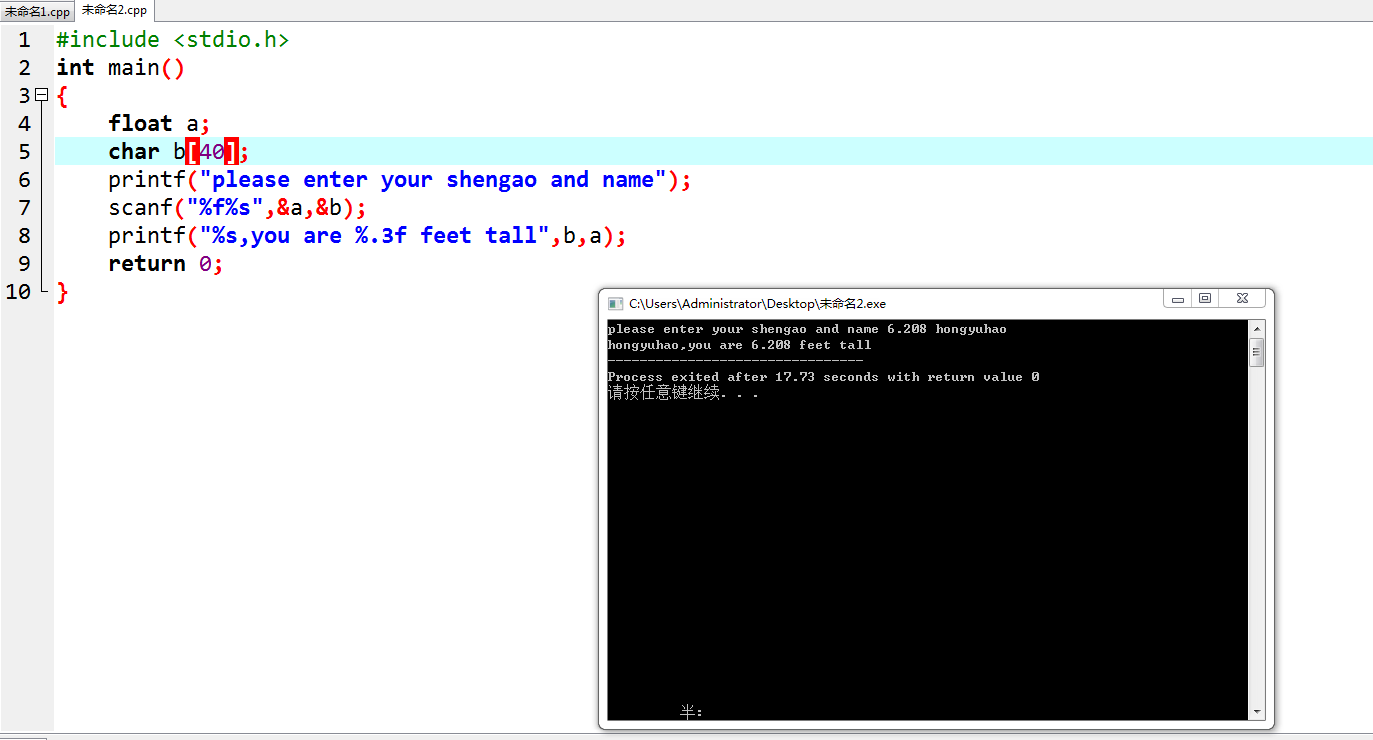
代码运行结果

作业心得
- 数据抓取与解析
在这次作业中,我使用了 requests 库来发送 HTTP 请求,并使用 BeautifulSoup 库来解析 HTML 内容。这两个库的结合实现数据抓取和解析。通过解析网页中的 JSON 数据,我能够提取出每个商品的名称和价格。 - 正则表达式的应用
在数据解析过程中,我使用了 re 库中的正则表达式来提取商品的价格和名称。在这次作业中,我通过正则表达式提取了所需的数据。
作业③:爬取网页JPEG和JPG格式文件
主要代码
# 获取网页内容
def get_html(url):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36'}try:response = requests.get(url, headers=headers)response.raise_for_status() # 确保请求成功return response.textexcept requests.RequestException as e:print(f"Error fetching data from {url}: {e}")return ""# 解析网页内容,提取图片链接
def parse_page(html, base_url):soup = BeautifulSoup(html, 'html.parser')img_urls = []for img in soup.find_all('img'):src = img.get('src')if src and (src.lower().endswith('.jpg') or src.lower().endswith('.jpeg')):full_url = urljoin(base_url, src)img_urls.append(full_url)return img_urls
代码运行结果


作业心得
- 数据抓取与解析
在这次作业中,我使用了 requests 库来发送 HTTP 请求,并使用 BeautifulSoup 库来解析 HTML 内容。通过解析网页中的数据,我能够提取出所需的图片的URL信息。 - URL 处理
在这次作业中,我使用了 urljoin 函数来处理相对 URL 和绝对 URL 的拼接。这个函数可以确保生成的 URL 是正确的,避免了手动拼接 URL 可能带来的错误。