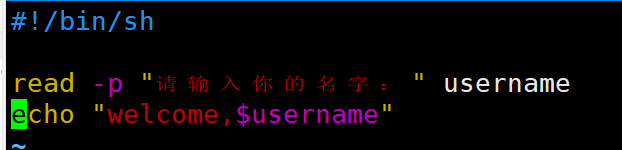
shell编程
1. 变量、条件判断、流程控制、函数
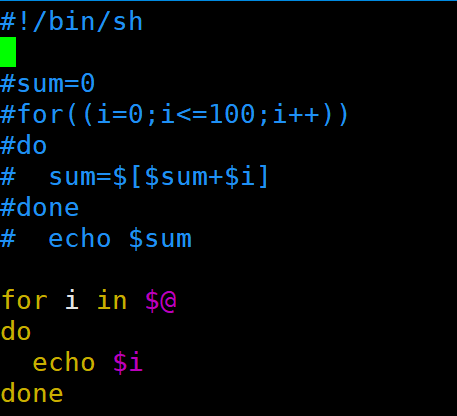
| $n (功能描述:n为数字,$0代表该脚本名称,$1-$9代表第一到第九个参数,十以上的参数,十以上的参数需要用大括号包含,如${10}) $# (功能描述:获取所有输入参数个数,常用于循环,判断参数的个数是否正确以及加强脚本的健壮性)。 $* (功能描述:这个变量代表命令行中所有的参数,$*把所有的参数看成一个整体) $@ (功能描述:这个变量也代表命令行中所有的参数,不过$@把每个参数区分对待)
$? (功能描述:最后一次执行的命令的返回状态。如果这个变量的值为0,证明上一个命令正确执行;如果这个变量的值为非0(具体是哪个数,由命令自己来决定1-255),则证明上一个命令执行不正确了。) |
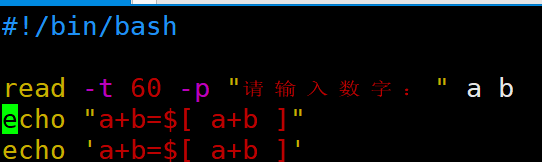
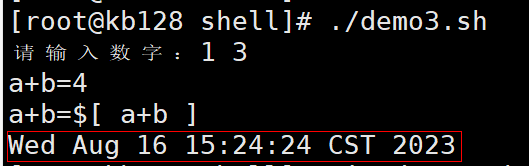
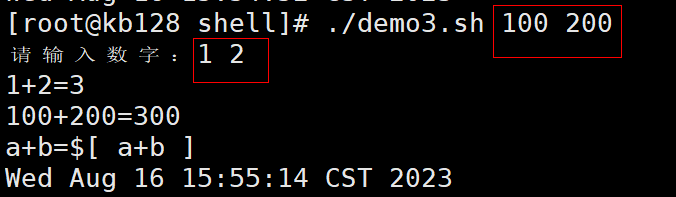
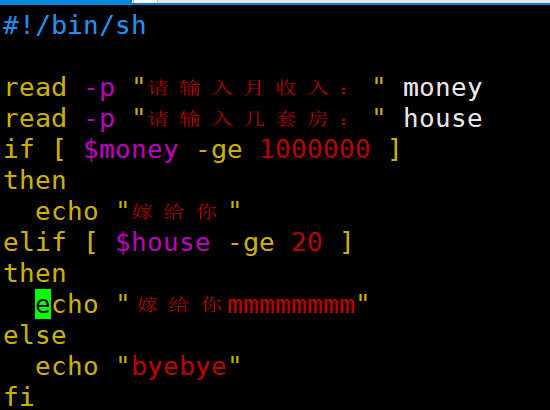
| read读取控制台输入 1)基本语法 read (选项) (参数) 选项: -p:指定读取值时的提示符; -t:指定读取值时等待的时间(秒)如果-t不加表示一直等待 参数 变量:指定读取值的变量名
|
|
执行系统函数需要用例如`date`特殊符号包裹,才可显示
(())等价于[] |
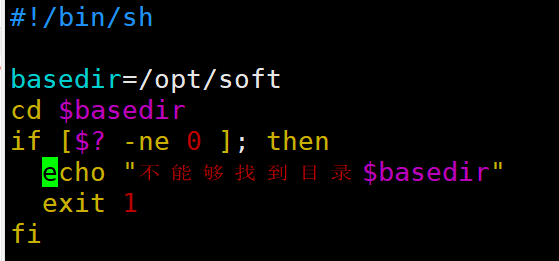
| if条件判断 > -gt(greater than) < -lt(less than) >= -ge(greater equal) <= -le(less than) == -eq(equal) != -ne(not equal) (1)单分支 if [ 条件判断式 ];then 程序 fi 或者 if [ 条件判断式 ] then 程序 fi
(2)多分支 if [ 条件判断式 ] then 程序 elif [ 条件判断式 ] then 程序 else 程序 fi
|
| $?返回0表示上一个命令执行成功 $?返回1-255表示上一个命令执行成功
|
| 修改文件名mv 原文件名 新文件名
|
| for循环 1)基本语法1 for (( 初始值;循环控制条件;变量变化 )) do 程序 done 普通for可循环和增强for循环 for((i=0;i<=100;i++))
|
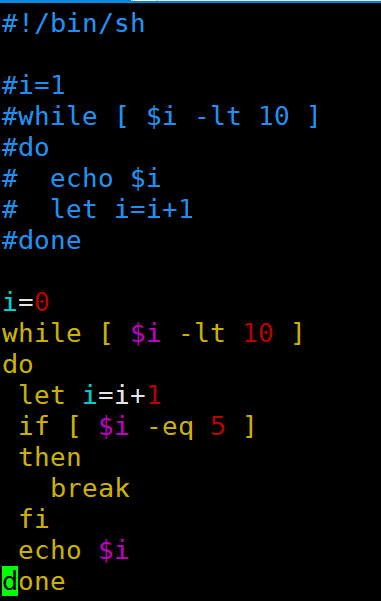
| while循环 1)基本语法 while [ 条件判断式 ] do 程序 done while循环中break和continue区别
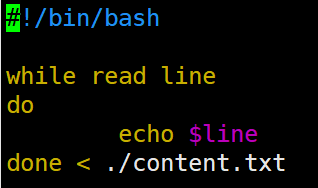
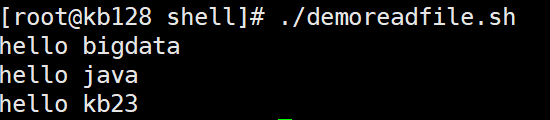
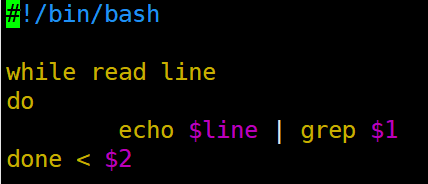
while循环读取输出文件内容
遍历读取并查找,使用管道操作grep搜索内容
|
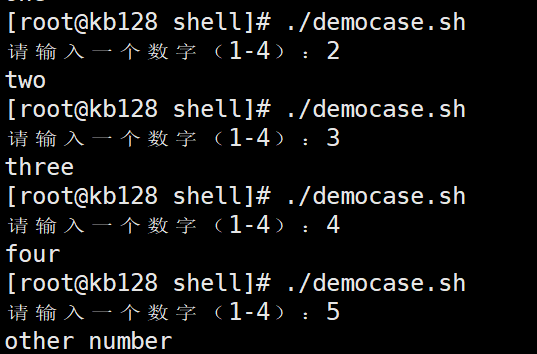
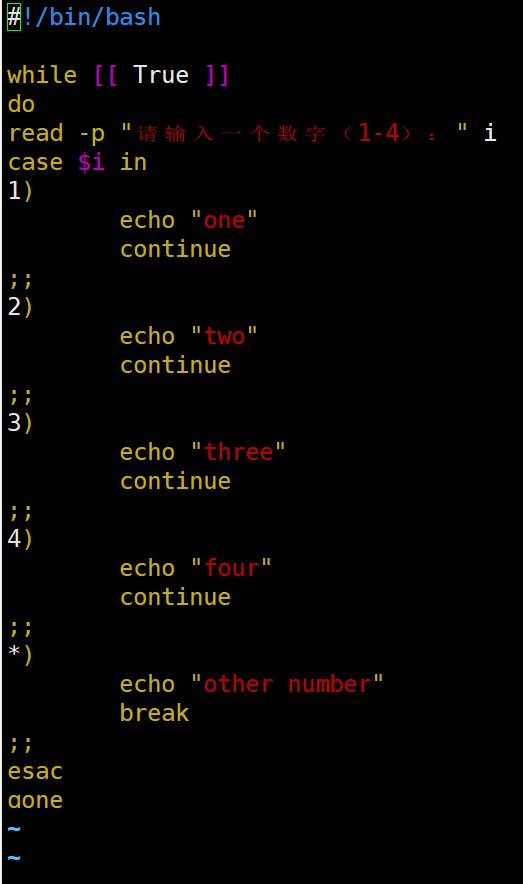
| case语句 1)基本语法 case $变量名 in "值1") 如果变量的值等于值1,则执行程序1 ;; "值2") 如果变量的值等于值2,则执行程序2 ;; …省略其他分支… *) 如果变量的值都不是以上的值,则执行此程序 ;; esac 注意事项: (1)case行尾必须为单词“in”,每一个模式匹配必须以右括号“)”结束。 (2)双分号“;;”表示命令序列结束,相当于java中的break。 (3)最后的“*)”表示默认模式,相当于java中的default。
实现简易计算器:函数或直接计算两种方式
|
| 函数
|













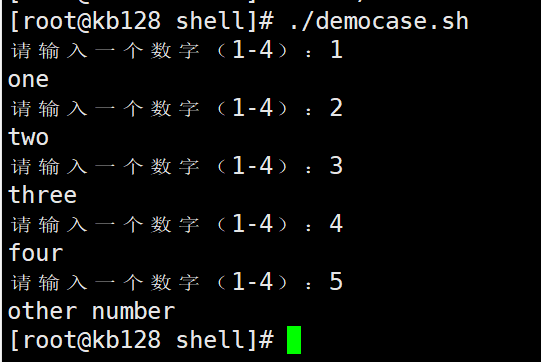
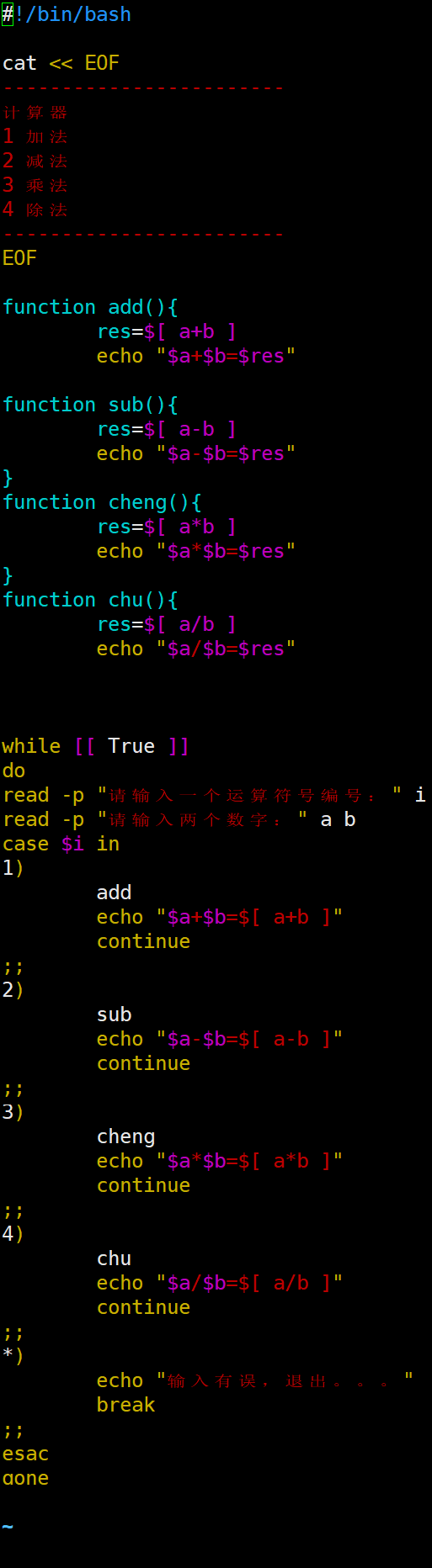
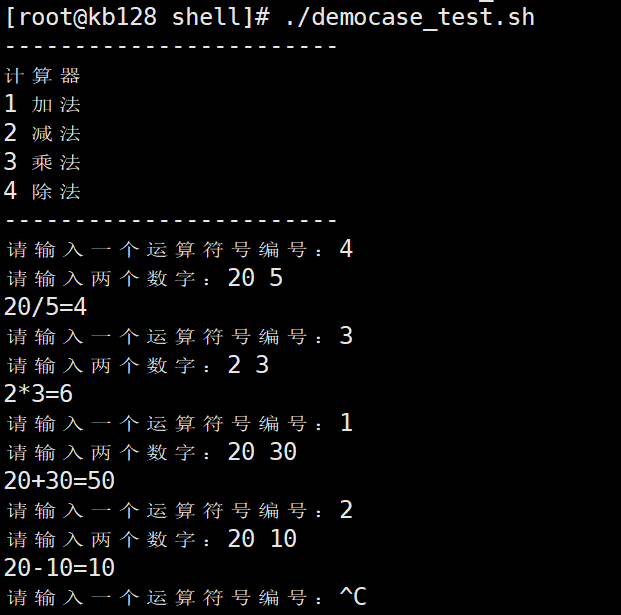
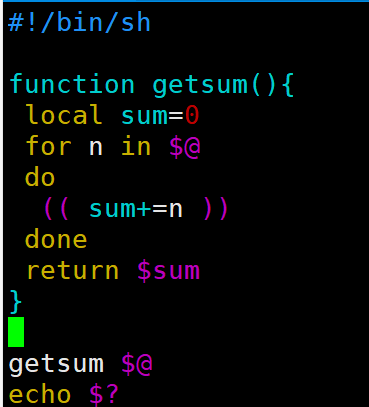
2.文件归档、正则表达式
| touch 创建一个文件 [atguigu@hadoop101 shells]$ touch for1.sh [atguigu@hadoop101 shells]$ vim for1.sh #!/bin/bash sum=0 for((i=0;i<=100;i++)) do sum=$[$sum+$i] done echo $sum |
| find 查找指定目录下的文件夹名
|
| head – n 2 显示文件前两行
|
| tail – n 2 显示文件末两行
|
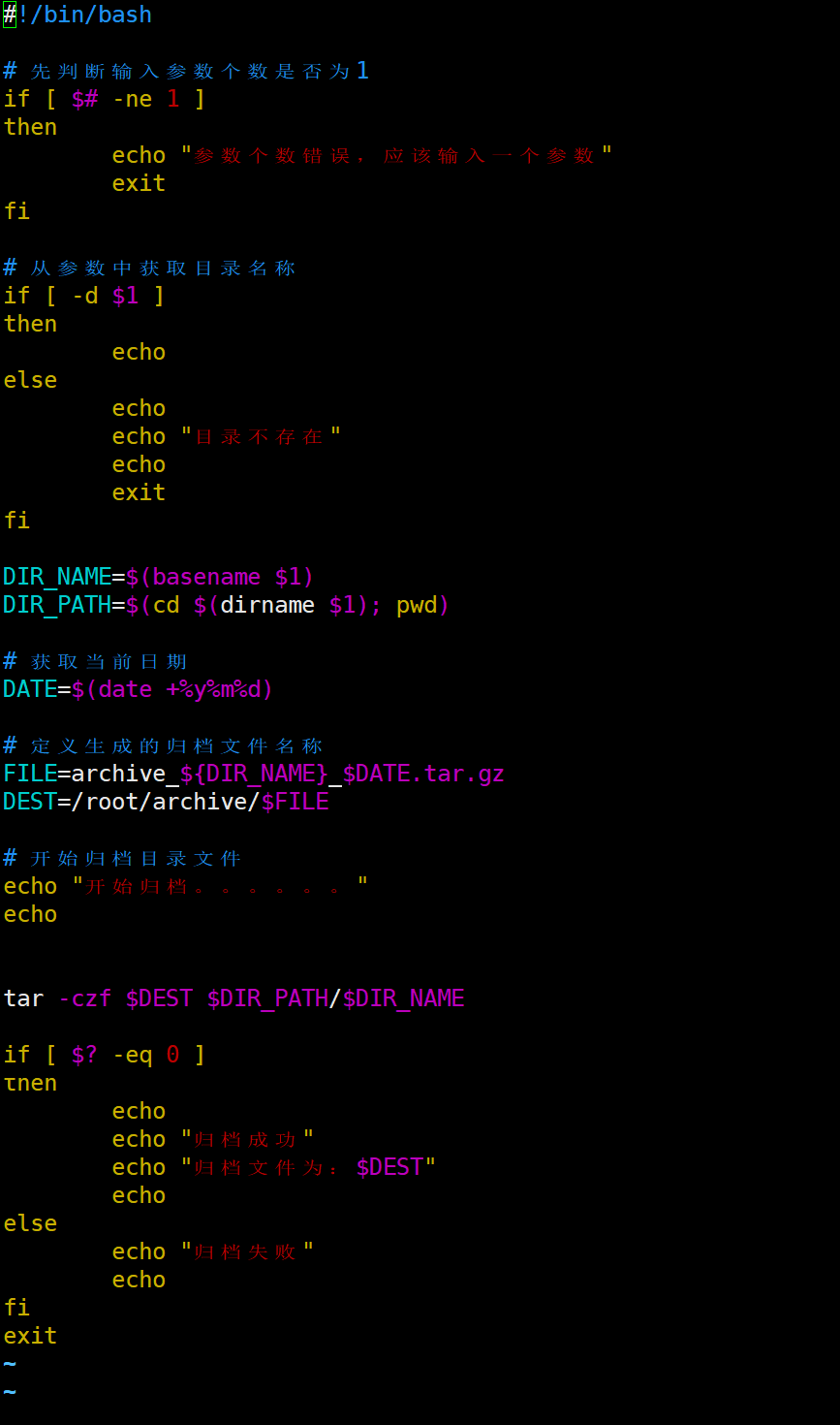
| 文件归档tar(可搭配定时器定时备份文档)
|
| 正则表达式 正则表达式使用单个字符串来描述、匹配一系列符合某个语法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些符合某个模式的文本。在Linux中,grep,sed,awk等命令都支持通过正则表达式进行模式匹配。 常规匹配:一串不包含特殊字符的正则表达式匹配它自己,例如: [atguigu@hadoop101 shells]$ cat /etc/passwd | grep atguigu 就会匹配所有包含atguigu的行 参数: 1)-i 忽略大小写
2)-E "正则表达式"
3)-n 显示匹配的行号,^$ 匹配空行
4)-c 显示匹配的行数,^$ 匹配空行
5)cat -b 表示同时显示匹配的行数
6)-An 显示匹配行及下n行
7)-Bn 显示匹配行及上n行
8)-n 显示匹配上及上下各n行
10.2 常用特殊字符 1)特殊字符:^ ^ 匹配一行的开头,例如: 会匹配出所有以root开头的行
2)特殊字符:$ $ 匹配一行的结束,例如 会匹配出所有以bash结尾的行
^$ 匹配空行 3)特殊字符:. . 匹配一个任意的字符,例如 [atguigu@hadoop101 shells]$ cat /etc/passwd | grep r..t 会匹配包含rabt,rbbt,rxdt,root等的所有行 4)特殊字符:* * 不单独使用,他和上一个字符连用,表示匹配上一个字符0次或多次,例如 [atguigu@hadoop101 shells]$ cat /etc/passwd | grep ro*t 会匹配rt, rot, root, rooot, roooot等所有行 思考:.* 匹配什么? 5)特殊字符:[ ] [ ] 表示匹配某个范围内的一个字符,例如 [6,8]------匹配6或者8 [0-9]------匹配一个0-9的数字 [0-9]*------匹配任意长度的数字字符串 [a-z]------匹配一个a-z之间的字符 [a-z]* ------匹配任意长度的字母字符串 [a-c, e-f]-匹配a-c或者e-f之间的任意字符 [atguigu@hadoop101 shells]$ cat /etc/passwd | grep r[a,b,c]*t 会匹配rt,rat, rbt, rabt, rbact,rabccbaaacbt等等所有行 6)特殊字符:\ \ 表示转义,并不会单独使用。由于所有特殊字符都有其特定匹配模式,当我们想匹配某一特殊字符本身时(例如,我想找出所有包含 '$' 的行),就会碰到困难。此时我们就要将转义字符和特殊字符连用,来表示特殊字符本身,例如 [atguigu@hadoop101 shells]$ cat /etc/passwd | grep a\$b 就会匹配所有包含 a$b 的行。 |
| sed (1)语法 sed [ option 参数] 1)-n 不自动打印到操作台中 2)-i 直接编辑文件 (2) cat fstab -n | sed 5p 编辑第五行,并在屏幕中显示
cat fstab -n | sed -n 4p 只显示第4行
cat fstab -n | sed -n 3,5p 显示3-5行内容
cat fstab -n | sed -n '3p;5p' 显示第三行和第五行
(3)'/正则表达式或内容/p' sed -n '/etc/p' fstab 显示etc所在行
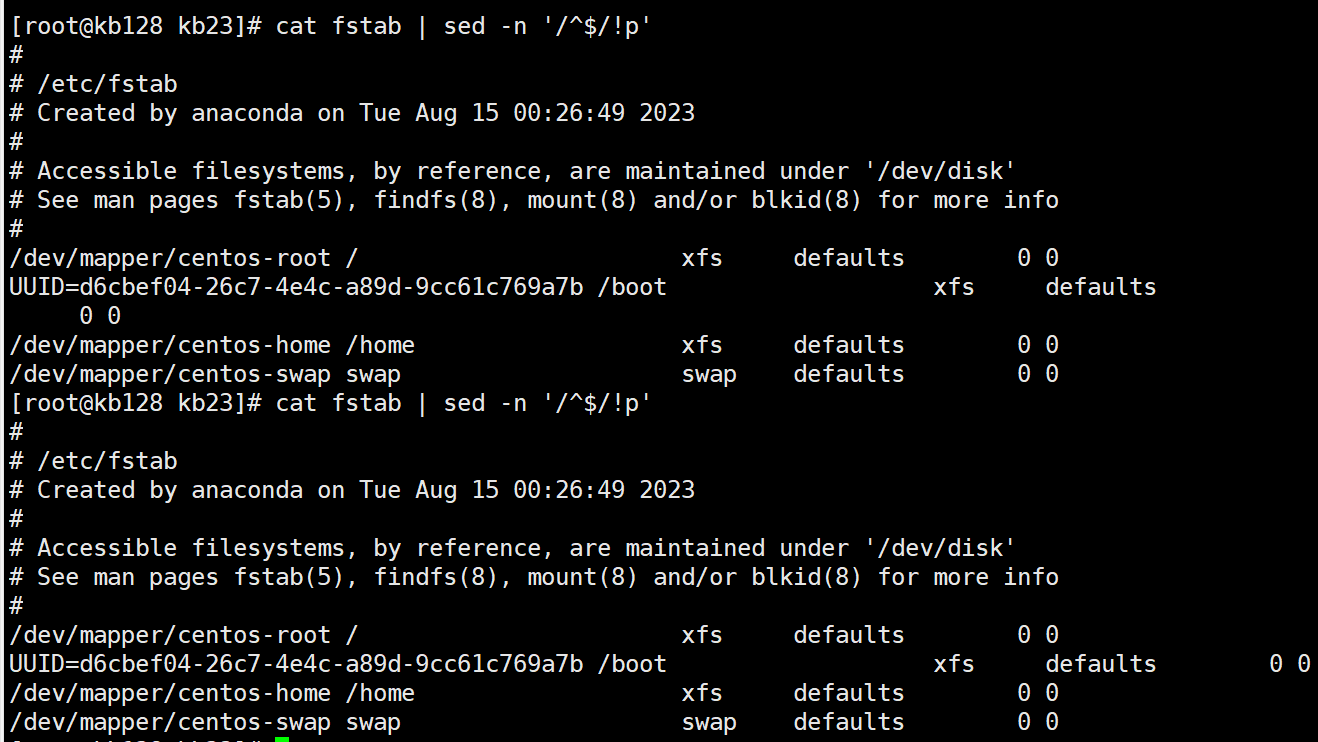
sed -n '/#/!p' fstab 显示不带#的行
sed -n '/\:/p' fstab 显示含:的行(:是特殊字符,需要使用\转译)
sed -n '/^UUID/p' fstab 显示以UUID开头的行
sed -n '/^$/!p' fstab 不显示空白行
sed -n '/^$/!p' fstab | sed -n '/^#/!p' 不显示空白行和#所在行
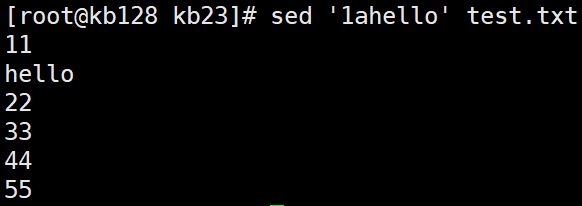
i、a—> 追加 sed '1ahello' test.txt 1a代表在第一行后下一行加入hello显示,不改变原文件
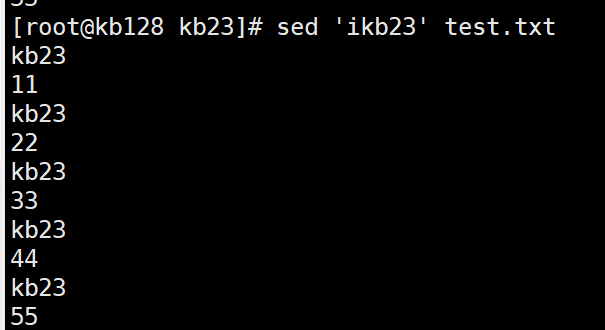
sed 'ikb23' test.txt i表示从第一行开始,每隔一行插入字符
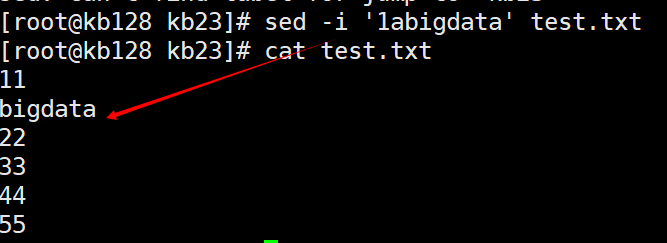
sed -i '1abigdata' test.txt -i直接在原文件内操作,会修改文件
sed '4ihello' test.txt 4i在第四行加入hello,其他内容向下行迁移
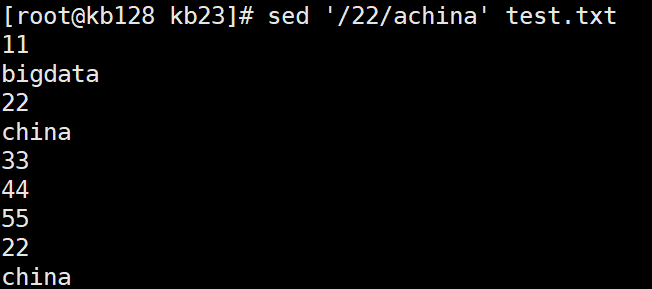
sed '/22/achina' test.txt 在匹配22的所有行的下一行添加china(批量添加)
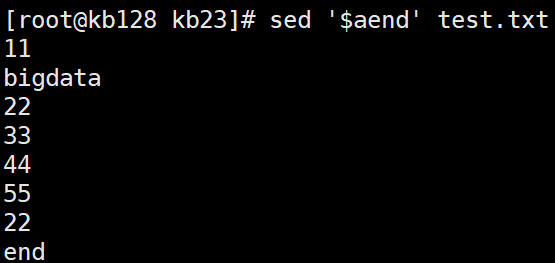
sed '$aend' test.txt $a在文件最后一行追加end
sed '/22/igood' test.txt 在匹配22的所有行的上一行添加china(批量添加)
sed '1cjavaweb' test.txt 1c将第一行的内容替换为javaweb
sed '/bigdata/c大数据' test.txt 将匹配到的bigdata行更改为大数据
d-->删除 sed '1d' test.txt 将第一行删除
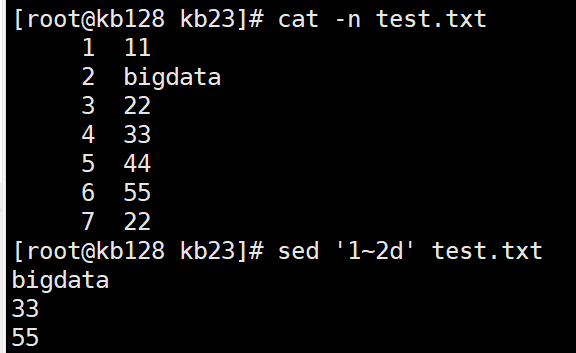
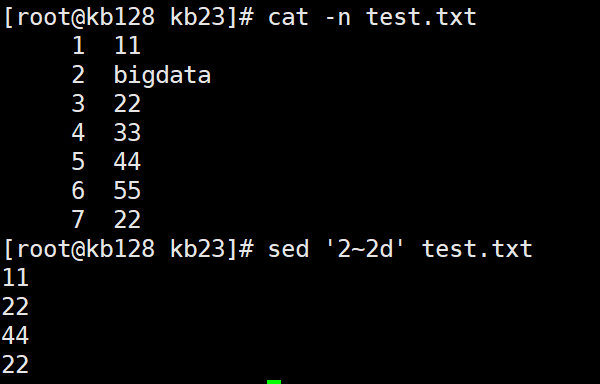
sed '1~2d' test.txt 从第一行开始,隔行删除,删除奇数行
sed '2~2d' test.txt 从第二行开始,隔行删除,删除奇数行
sed '1,5d' test.txt 删除第一行至第五行
sed '1,2!d' test.txt 删除 除了1-2行之外的行
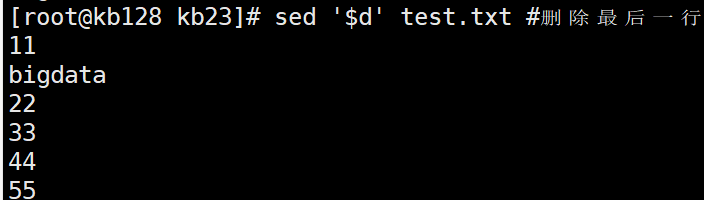
sed '$d' test.txt $d删除最后一行
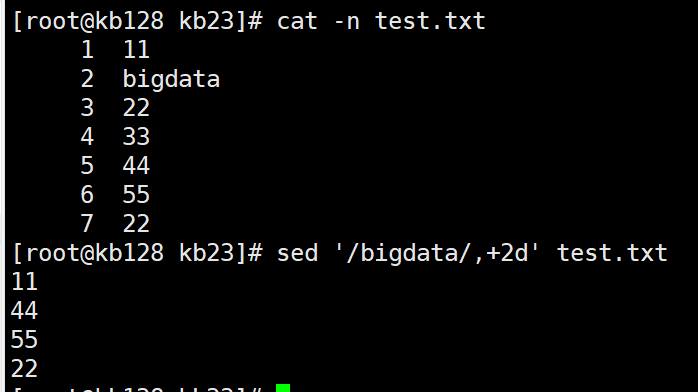
sed '/bigdata/,2d' test.txt 删除匹配到的行及以下2行
sed '/bigdata/,$d' test.txt 删除匹配到的行至最后一行
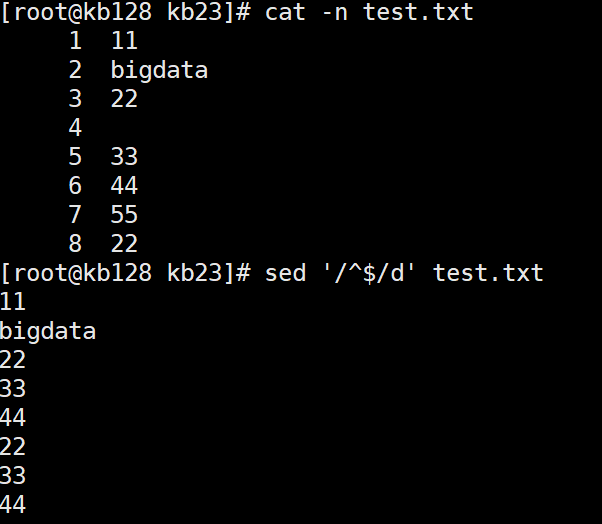
sed '/^$/d' test.txt 删除匹配到的空行
sed '/22\|^$/!d' test.txt 不删除匹配到的行
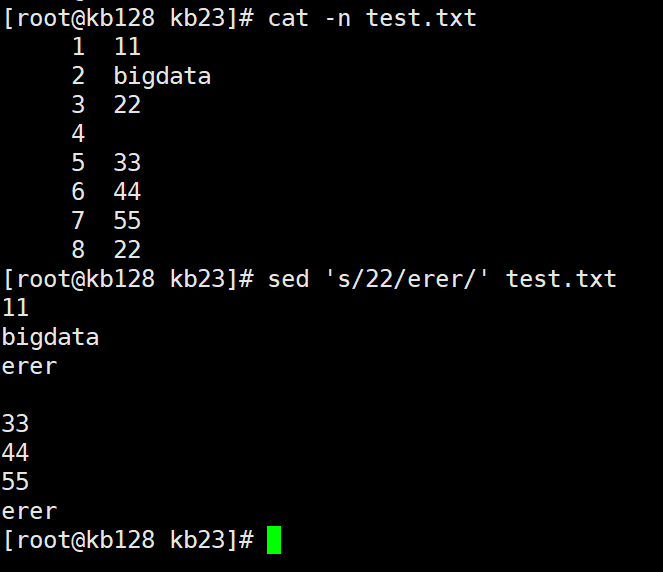
s—> 替换 sed 's/22/erer/' test.txt 将匹配到的22替换成erer(非整行替换)
|
































3. Shell工具
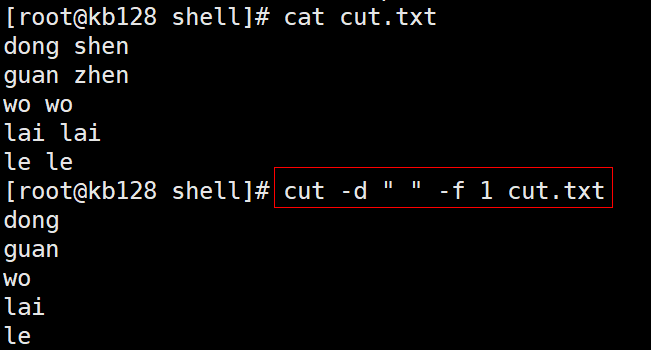
| 3.1 cut cut的工作就是“剪”,具体的说就是在文件中负责剪切数据用的。cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段输出。 1)基本用法 cut [选项参数] filename 说明:默认分隔符是制表符 2)选项参数说明 选项参数 功能 -f 列号,提取第几列 -d 分隔符,按照指定分隔符分割列,默认是制表符“\t” -c 按字符进行切割 后加加n 表示取第几列 比如 -c 1
|
| 3.2 awk 一个强大的文本分析工具,把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行分析处理。 1)基本用法 awk [选项参数] ‘/pattern1/{action1} /pattern2/{action2}...’ filename pattern:表示awk在数据中查找的内容,就是匹配模式 action:在找到匹配内容时所执行的一系列命令 2)选项参数说明 选项参数 功能 -F 指定输入文件折分隔符 -v 赋值一个用户定义变量 3)案例实操
取出2,4,6列的内容,默认分隔符为空格和制表符
取出2,4,6列的内容,指定分隔符为:和,
(1)搜索passwd文件以root关键字开头的所有行,并输出该行的第7列。
(2)搜索passwd文件以root关键字开头的所有行,并输出该行的第1列和第7列,中间以“,”号分割。
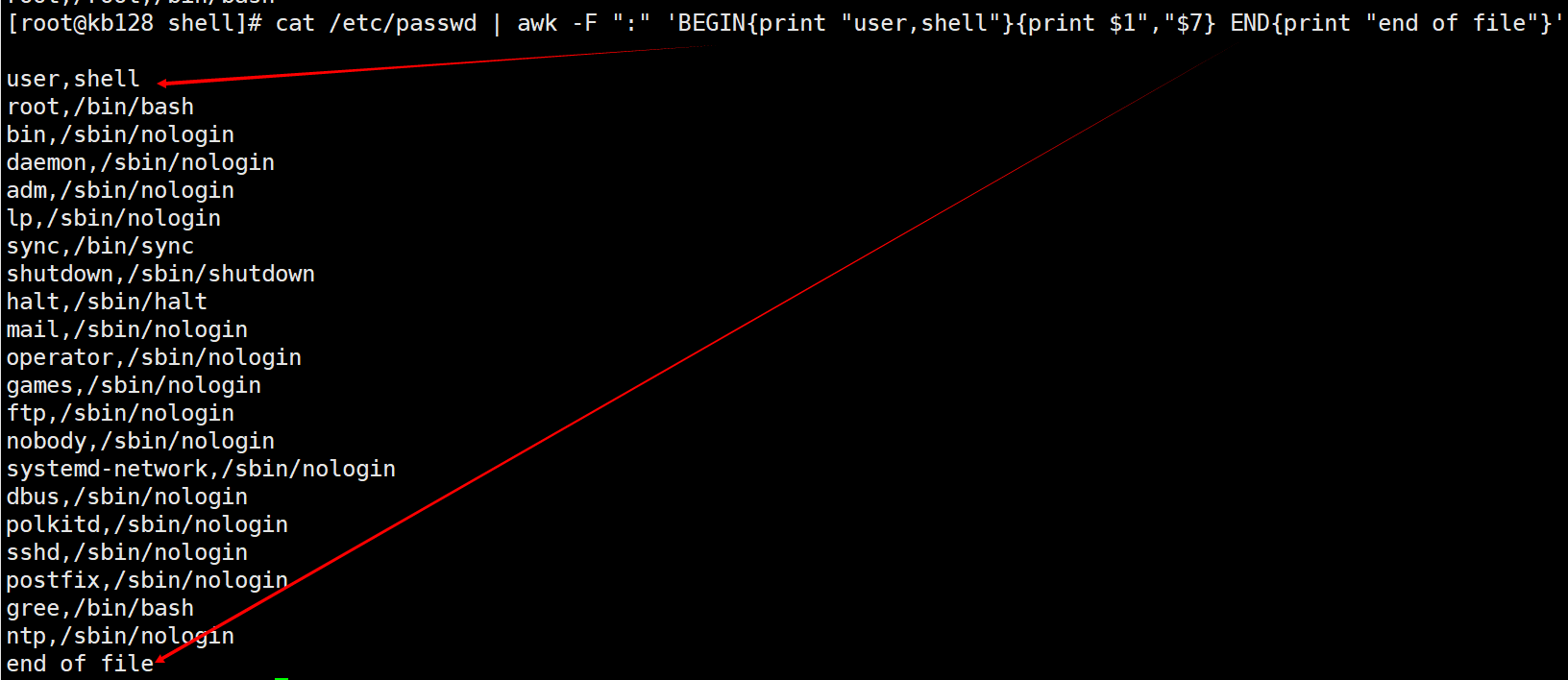
(3)只显示/etc/passwd的第一列和第七列,以逗号分割,且在所有行前面添加列名user,shell在最后一行添加"end of shell"。 注意:BEGIN 在所有数据读取行之前执行;END 在所有数据执行之后执行。
(5)将passwd文件中的用户id增加数值1并输出(使用-v参数)
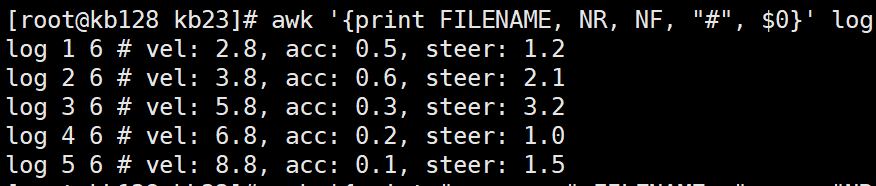
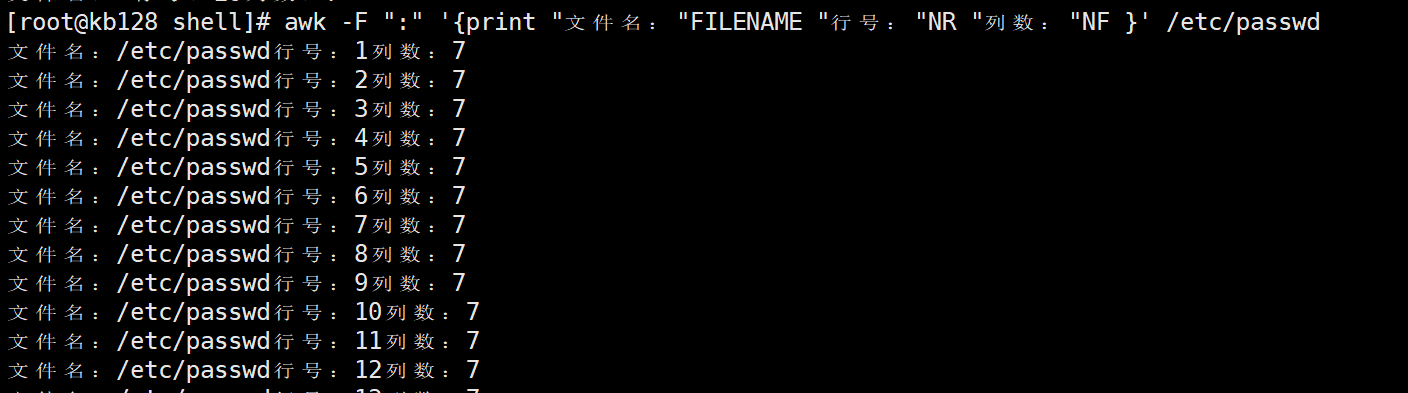
4)awk的内置变量 变量 说明 FILENAME 文件名 NR 已读的记录数(行号) NF 浏览记录的域的个数(切割后,列的个数) 5)案例实操
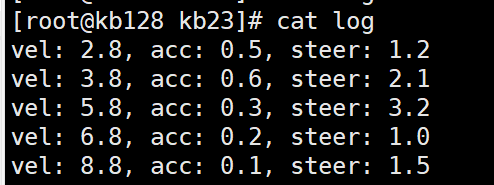
打印$2列值小于5.0全部行的内容
打印$2列的最大值
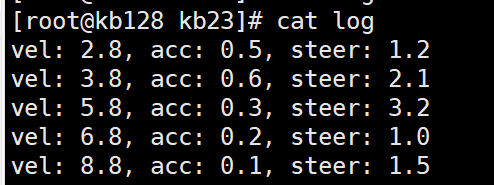
(1)统计passwd文件名,每行的行号,每行的列数
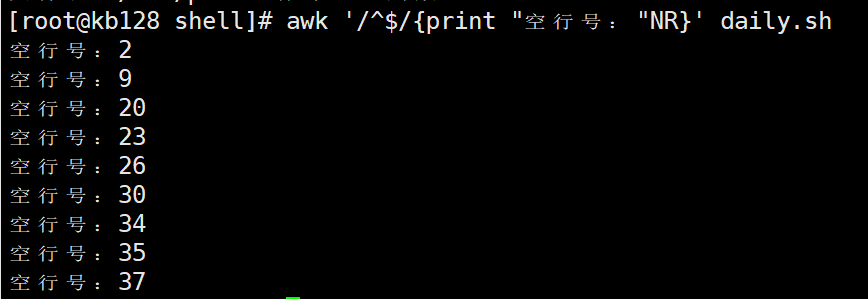
(2)查询文件输出结果中的空行所在的行号
(3)切割IP
|
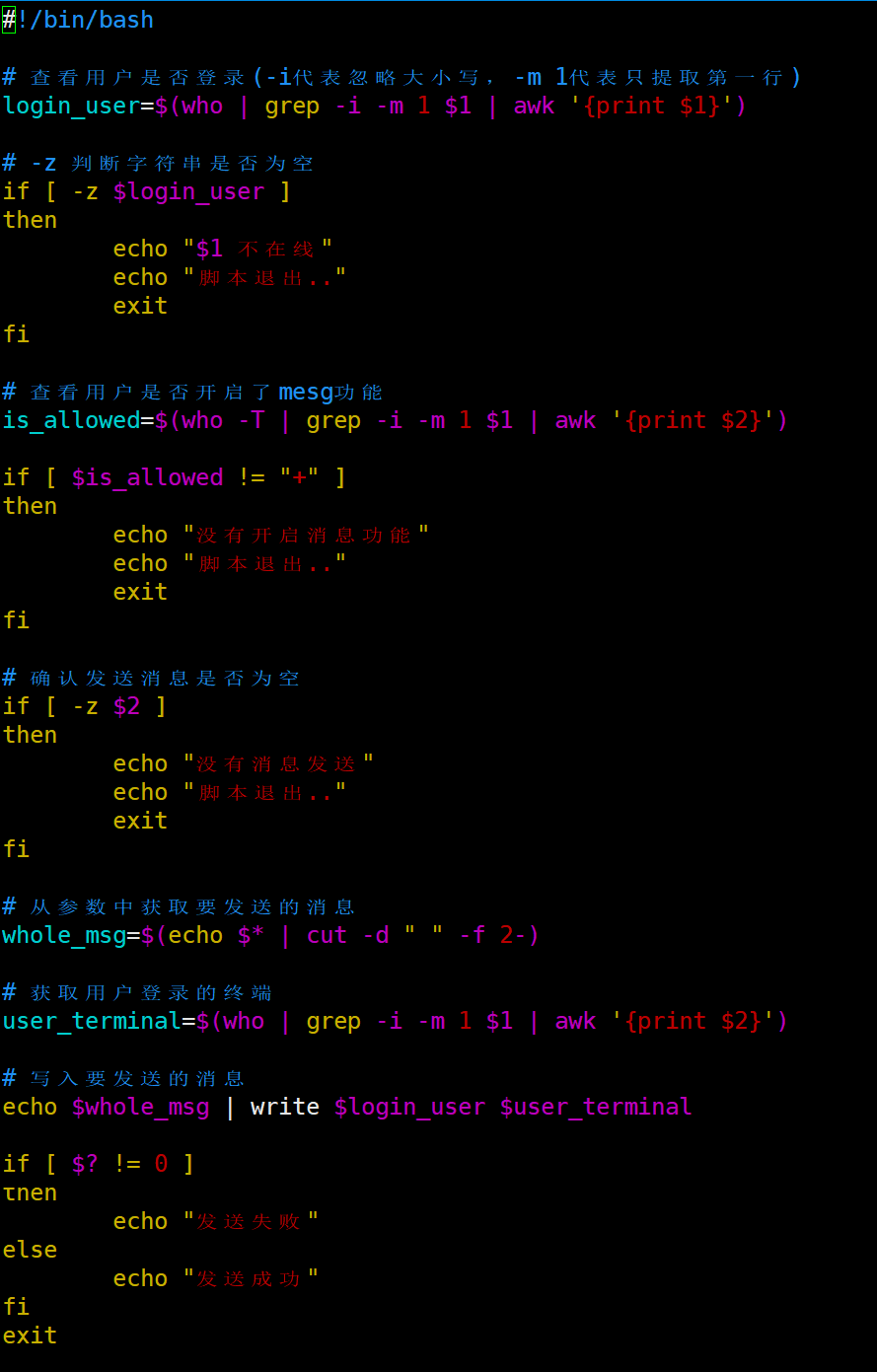
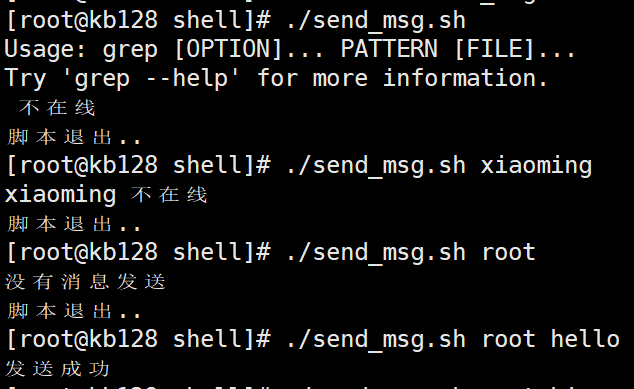
| 综合练习:编写脚本。实现给某个用户发送消息的功能
|