目录
- 1 损失函数和反向传播
- 1.1 损失函数
- 1.2 反向传播
- 2 优化器
- 3 现有网络模型的使用及修改
- 4 网络模型的保存与读取
- 4.1 网络模型的保存
- 4.2 网络模型的读取(加载)
- 5 完整的模型训练套路
- 6 利用GPU训练模型
- 7 完整的模型验证套路:
1 损失函数和反向传播
1.1 损失函数
前言: torch.nn里面的Loss Functions用来衡量误差。
什么是Loss Functions呢?它的作用是什么呢?
答:比如说一张总分为100(也就是target为100)的试卷由选择、填空、解答三部分组成,选择占30分,填空占20分,解答占50分。但是我们实际考了多少分呢?假设选择考了10分,填空考了20分,解答考了50分,则实际的总分为30分(也就是实际输出的output=30)。那么我们就需要用一个Loss来衡量实际我们考的分数(也就是神经网络的输出)和我们真实想要的结果(也就是总分100分)之间的差距,比如说这里的Loss算出来是差距了70分。我们得到这个差距之后,要根据这个差距来指导我们让output去接近target。所以说这个Loss(误差)在大多数情况下按照定义肯定是越小越好。
我们要根据Loss去提高output的输出,比如说我们对神经网络经过不断的训练。训练的依据就从Loss来,比如通过看这个分数,看到我们的解答题实在是太弱了,所以我们要对这个解答题多训练训练,对解答题这个模块着重的进行一下更新。再比如说经过我们的努力解答题进行了一个上升考了20分,那么它这个Loss就会进行一个相应的下降。
所以说Loss Functions的作用主要是:(1)计算实际输出和目标之间的差距;(2)为我们更新输出提供一定的依据(这其实就是反向传播)。
一个实例进行具体理解:
nn_loss.py
import torch
from torch.nn import L1loss
from torch import nninputs = torch.tensor([1,2,3],dtype=torch.float32)
targets = torch.tensor([1,2,5],dtype=torch.float32)#这里把inputs、targets的格式都变成了1batch_size,1channel,1行3列
inputs = torch.reshape(inputs,(1,1,1,3))
targets = torch.reshape(targets,(1,1,1,3))#然后我们求我们的这个loss
#这里以L1loss函数进行举例使用的
#括号里什么都没写的话,说明我们这里L1loss这个函数所实现的公式是误差相加之后求一个平均值,这个平均值就是最后的返回结果
loss = L1loss()
#如果我们把这里reduction这个参数设置为sum,则意思为误差相加。说明我们这里L1loss这个函数所实现的公式是误差相加,这个相加后的数值就是最后的返回结果
#loss = L1loss(reduction='sum')
#运行以后我们会发现它要求的数据类型要是浮点数,不能是Long,否则就会报错
result = loss(inputs,targets)#这里以MSELoss函数进行举例使用的
#括号里什么都没写的话,说明我们这里MSELoss这个函数所实现的公式就是平方差求和之后再求平均的公式,这个平均值就是最后的返回结果
#平方差求和之后再求平均的公式:[(x1-y1)的平方+(x2-y2)的平方...+(xn-yn)的平方]/n
loss_mse = MSELoss()
result_mse = loss_mse(inputs,targets)print(result)
#运行结果为tensor(0.6667)
#如果我们把这里reduction这个参数设置为sum,运行结果为tensor(2.)
print(result_mse)
#运行结果为tensor(1.3333)#这里以CrossEntropyLoss(交叉熵)函数进行举例使用的
#这个函数一般用在:当你训练一个分类问题的时候,这个分类问题有C个类别,比如像我们CIFAR10这个数据集里面有10个分类类别。
#对于这个函数计算公式的理解如图一所示:比如现在有一个三分类的问题,分成了Person、dog、cat三类,我们现在拿出了一张dog的图片当作输入,经过神经网络之后会产生一个预测出来的概率,比如说Person的概率是0.1,dog的概率是0.2,cat的概率是0.3(即给一个output为[0.1,0.2,0.3])。但是实际过程会给一个target为1(这个1的意思就是dog的意思[Person代表第0位、dog代表第1位、cat代表第2位])
#接着我们计算交叉熵的时候,公式里面的x指的就是[0.1,0.2,0.3],target的那个1指的就是class,代入公式可得Loss(x,class)=-0.2+log(exp(0.1)+exp(0.2)+exp(0.3))。
#如果你想要loss越来越小的话,exp(0.1)+exp(0.2)+exp(0.3)也就要比较小,它就能保证我们预测成Person、dog、cat比较合理。不然预测的三个值为0.8、0.9、0.8这种,三个都比较高的话看不出来差距,这个分类器的能力就不会很强。所以log(exp(0.1)+exp(0.2)+exp(0.3))是来限制概率分布的。
#-x[class]也要比较小,所以x[class]这部分就要求比较大。
x = torch.tensor([0.1,0.2,0.3])
y = torch.tensor([1])
#这里意思是把x变成了1batch_size,3类的格式
x = torch.reshape(x,(1,3))
loss_cross = nn.CrossEntropyLoss()
return_cross = loss_cross(x,y)
print(return_cross)
#运行结果为tensor(1.1019)
图一: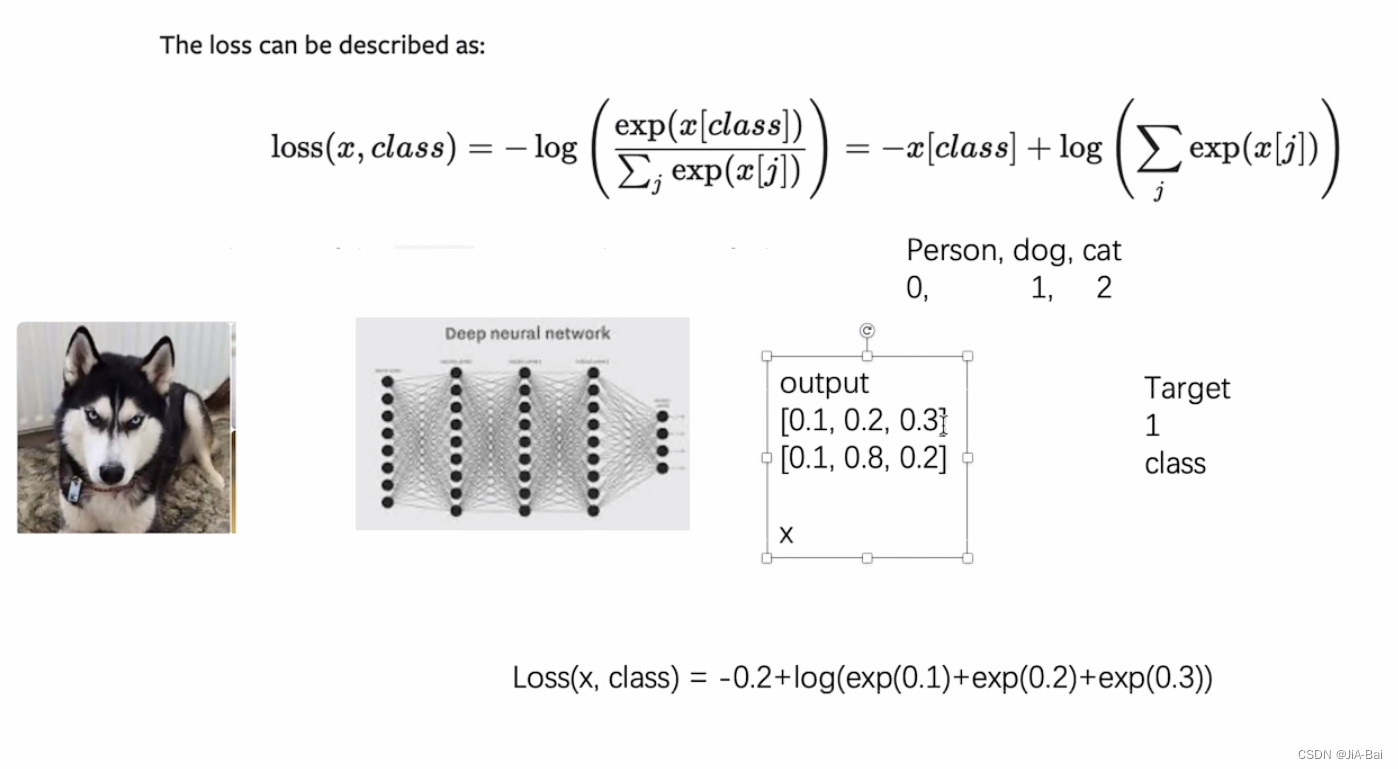
接下来再来看看如何在之前写的神经网络中用到Loss Function(损失函数)呢?
nn_loss_network.py
from torch import nn
from torch.nn import Conv2d,MaxPool2d,Flatten,Linear,Sequential
import torch
import torchvision
from torch.utils.data import DataLoader
from torch.utils.ensorboard import SummaryWriter#获取数据集
dataset = torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
#加载数据到神经网络中去
dataloader = Dataloader(dataset,batch_size=1)class Feihan(nn.module):def __init__(self):super(Feihan,self).__init__()self.model1 = Sequential(Conv2d(3,32,5,stride=1,padding=2),MaxPool2d(2),Conv2d(32,32,5,stride=1,padding=2),MaxPool2d(2),Conv2d(32,64,5,stride=1,padding=2),MaxPool2d(2),Flatten(),Linear(1024,64),Linear(64,10))def forward(self,x):x = self.model1 (x)return x#这种分类问题可以用前面介绍过的交叉熵进行loss的计算
loss = nn.CrossEntropyLoss()#初始化这个网络
feihan = Feihan()
for data in dataloader:imgs,targets = dataoutputs = feihan(imgs)#我们需要看一下outputs和targets长什么样,看选择什么样的损失函数#print(outputs)#print(targets)#运行结果格式类似于:#tensor([[-0.0731,0.0964,...]])括号里面有10个数字,每个代表预测是这个类别的概率#tensor([3])代表我们真实的targets是3result_loss = loss(outputs,targets)print(result_loss)#运行结果格式类似于:tensor(2.3247),代表神经网络中的输出和我们真实输出之间的一个误差
1.2 反向传播
那么它是如何为我们更新输出提供一定的依据(这其实就是反向传播)呢?
答:它就是给我们每一个需要调优的参数,对神经网络来说,或者对卷积层来说,其中的每一个卷积核当中的参数就是我们需要进行调的。它对我们每一个卷积核当中的参数设置了一个grad(就是梯度),当我们采用反向传播的时候,每一个节点(或者说每一个要更新的参数)都会求出来一个对应的梯度,在优化的过程中就可以根据这个梯度对其中的参数进行一个优化,最终以达到loss降低的目的。
梯度下降:如图二所示就是一个梯度下降,当前这个卷积核当中的一个参数处于最大圆球的位置,红色的曲线是整个的Loss Function,当我们采用反向传播的时候,就求出了最大圆球对应顶点的梯度。当我们进行更新时就可以根据梯度进行一个下降,进行一个参数的更新,最终以达到整个loss降低的功能。
图二: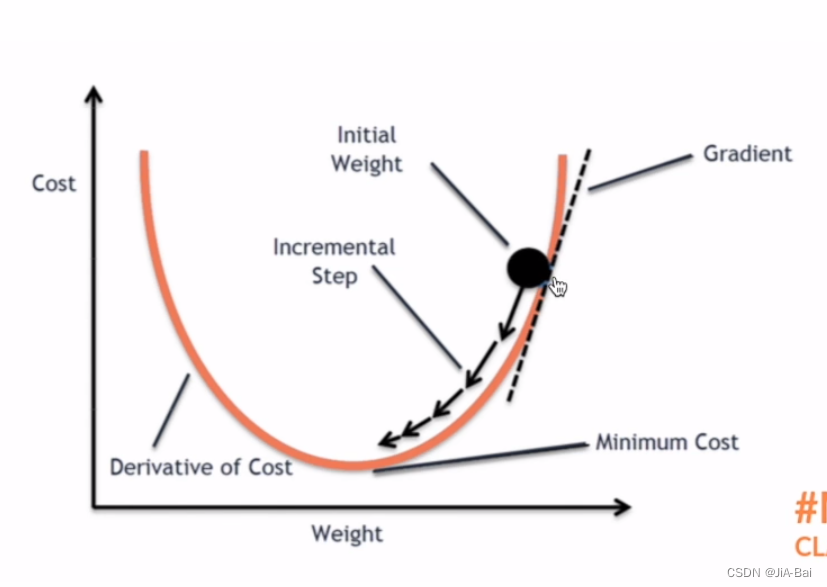
用代码来看一下我们如何采用反向传播? (这段代码其实就是前面的nn_loss_network.py中的代码,里面别的地方全都一样,只是把最后一行代码进行了一个修改)
from torch import nn
from torch.nn import Conv2d,MaxPool2d,Flatten,Linear,Sequential
import torch
import torchvision
from torch.utils.data import DataLoader
from torch.utils.ensorboard import SummaryWriter#获取数据集
dataset = torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
#加载数据到神经网络中去
dataloader = Dataloader(dataset,batch_size=1)class Feihan(nn.module):def __init__(self):super(Feihan,self).__init__()self.model1 = Sequential(Conv2d(3,32,5,stride=1,padding=2),MaxPool2d(2),Conv2d(32,32,5,stride=1,padding=2),MaxPool2d(2),Conv2d(32,64,5,stride=1,padding=2),MaxPool2d(2),Flatten(),Linear(1024,64),Linear(64,10))def forward(self,x):x = self.model1 (x)return x#这种分类问题可以用前面介绍过的交叉熵进行loss的计算
loss = nn.CrossEntropyLoss()#初始化这个网络
feihan = Feihan()
for data in dataloader:imgs,targets = dataoutputs = feihan(imgs)#我们需要看一下outputs和targets长什么样,看选择什么样的损失函数#print(outputs)#print(targets)#运行结果格式类似于:#tensor([[-0.0731,0.0964,...]])括号里面有10个数字,每个代表预测是这个类别的概率#tensor([3])代表我们真实的targets是3result_loss = loss(outputs,targets)#反向传播result_loss.backward()
2 优化器
前面我们提到了反向传播,其中提到了当我们使用损失函数的时候我们可以调用损失函数的backward()函数得到反向传播。反向传播就可以求出我们每一个需要调节的参数,这个参数对应的一个梯度。有了这个梯度就可以利用优化器,让这个优化器根据这个梯度去进行调整,以达到整体误差降低的目的。
所有的优化器都是集中在torch.optim中。
用代码具体感受一下优化器的使用,具体代码示例如下所示:
nn_optim.py
from torch import nn
from torch.nn import Conv2d,MaxPool2d,Flatten,Linear,Sequential
import torch
import torchvision
from torch.utils.data import DataLoader
from torch.utils.ensorboard import SummaryWriter#获取数据集
dataset = torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
#加载数据到神经网络中去
dataloader = Dataloader(dataset,batch_size=1)class Feihan(nn.module):def __init__(self):super(Feihan,self).__init__()self.model1 = Sequential(Conv2d(3,32,5,stride=1,padding=2),MaxPool2d(2),Conv2d(32,32,5,stride=1,padding=2),MaxPool2d(2),Conv2d(32,64,5,stride=1,padding=2),MaxPool2d(2),Flatten(),Linear(1024,64),Linear(64,10))def forward(self,x):x = self.model1 (x)return x#这种分类问题可以用前面介绍过的交叉熵进行loss的计算
loss = nn.CrossEntropyLoss()
#初始化这个网络
feihan = Feihan()
#设置优化器
#这里是以SGD梯度下降作为举例进行学习
#lr代表学习速率,一般不能设置的太大(太大的话模型训练起来很不稳定),也不能设置的太小(太小的话模型训练起来又比较慢)。一般情况下我们一开始采用比较大的学习速率来学习,学习到后面的时候采用比较小的学习速率来学习。
optim = torch.optim.SGD(feihan.parameters(),lr=0.01)
#定义了20轮循环过程
for epoch in range(20):#在每一轮开始之前都把loss设置成了0running_loss = 0.0#这是学习一轮所用的的循环,一般只循环一轮并不会有什么学习效果,所以我们需要在最外层再加一个循环for data in dataloader:imgs,targets = dataoutputs = feihan(imgs)result_loss = loss(outputs,targets)#把每一个网络模型当中每个可以调节参数对应的梯度调为0optim.zero_grad()#用优化器对参数进行优化#优化器需要每个参数的梯度,所以需要利用backward来得到#反向传播result_loss.backward()#调用优化器对每个参数进行一个调优optim.step()#每一轮学习过程中整体的一个loss的求和running_loss = running_loss + result_lossprint(running_loss)
3 现有网络模型的使用及修改
下面将用vgg16这个模型进行举例讲解,注意一下:使用vgg16的前提是需要提前安装scipy这个包。
一个实例进行具体理解,对vgg16这个网络模型进行添加或修改操作:
model_pretrained.py
from torch import nn
import torchvision#仅加载网络模型,且网络模型中的参数都是初始化的,即默认的参数;不需下载。
vgg16_false = torchvision.models.vgg16(pretrained=False)
#不仅加载网络模型,且网络模型中的参数都是在ImageNet这个训练集上训练好的;仍需下载
vgg16_true = torchvision.models.vgg16(pretrained=True)print('ok')
print(vgg16_true )#获取数据集
train_data = torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
#前面ImageNet这个训练集有1000种分类,而CIFAR10仅有10种分类,那么我们如何把现有的vgg16用到CIFAR10这个数据集当中去呢?应该如何进行修改?
#方法1:我们想在vgg16这个网络中添加一层,将Linear线性层中的in_features设置为1000,out_features设置为10即可。
vgg16_true.add_module('add_linear',nn.Linear(1000,10))
#或在vgg16这个网络的classifier层进行添加一层,将Linear线性层中的in_features设置为1000,out_features设置为10即可,具体代码如:vgg16_true.classifier.add_module('add_linear',nn.Linear(1000,10))
print(vgg16_true)#方法2:直接对vgg16这个网络进行修改,而不是添加。将Linear线性层中的out_features设置为10即可。
#由于前面我们已经对vgg16_true这个网络进行了一定的操作,下面我们就以vgg16_false进行演示
print(vgg16_false)
vgg16_false.classifier[6] = nn.Linear(4096,10)
print(vgg16_false)
4 网络模型的保存与读取
4.1 网络模型的保存
以vgg16模型的保存作为一个实例进行具体理解:
model_save.py
import torchvision
import torch
from torch import nnvgg16 = torchvision.models.vgg16(pretrained=False)
#保存方式1:模型结构+模型参数
#参数1:把vgg16这个网络模型放进去
#参数2:保存路径
torch.save(vgg16,"vgg16_method1.pth")
#这种方式不仅保存了网络模型的结构,还保存了网络模型的参数#保存方式2:模型参数(官方推荐)
#参数2:保存路径
torch.save(vgg16.state_dict(),"vgg16_method2.pth")
#这种方式把vgg16的状态保存成了一种字典形式,相当于把vgg16网络模型的参数保存成了字典。它不再保存网络模型的结构了,它保存网络模型当中的一些参数。#陷阱
#这里我们自己写了一个网络结构
class Feihan(nn.module):def __init__(self):super(Feihan,self).__init__()self.conv1 = nn.Conv2d(3,64,kernel_size=3)def forward(self,x):x = self.conv1 (x)return x#初始化这个网络
feihan = Feihan()
#用方式1进行了保存
torch.save(feihan,"feihan_method1.pth")
4.2 网络模型的读取(加载)
再创建一个model_load.py文件来进行模型的加载。
model_load.py
import torch
import torchvision
from torch import nn
#与下面将class Feihan(nn.module):这个模型整个复制过来的操作一样,一般在这里进行一次性引用。复制和在这里一次性引用选一个即可。
from model_save import *#方式1(对应上面model_save.py中的保存方式1)加载模型
#参数:指定路径
model = torch.load("vgg16_method1.pth")
#print(model)#方式2(对应上面model_save.py中的保存方式2)加载模型
#参数:指定路径
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load("vgg16_method2.pth"))
#model = torch.load("vgg16_method2.pth")
#print(model)
#print(vgg16)#陷阱1
#因为用方式1进行的保存,所以对应用方式1进行加载
#如果这里不把模型的这个类引进来,则会报错,实现不了加载功能
#class Feihan(nn.module):#def __init__(self):#super(Feihan,self).__init__()#self.conv1 = nn.Conv2d(3,64,kernel_size=3)#def forward(self,x):#x = self.conv1 (x)#return xmodel = torch.load('feihan_method1.pth')
print(model)
5 完整的模型训练套路
以CIFAR10数据集作为一个例子,完成对数据集的分类问题。这个数据集之前讲过它有十个类别,也就是一个十分类的问题。
一个实例进行具体理解:
train.py
import torchvision
from torch.utils.data import DataLoader
from model import *
from torch import nn
from torch.utils.ensorboard import SummaryWriter#准备训练数据集
train_data = torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
#准备测试数据集
test_data = torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)#数据集的长度
train_data_size = len(train_data)
test_data_size = len(test_data)
#如果train_data_size=10,训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))#利用DataLoader来加载数据集
train_dataloader = Dataloader(train_data,batch_size=64)
test_dataloader = Dataloader(test_data,batch_size=64)#搭建神经网络
#这个神经网络已经被单独写在了model.py文件中,需要使用时我们进行一个引用即可
#引用的代码:from model import *,一定要注意这个被引用的model文件夹和train这个文件夹要在同一个文件夹底下才行。#创建网络模型
feihan = Feihan()#损失函数
loss_fn = nn.CrossEntropyLoss()#优化器
learning_rate = 0.01
#还可以写成learning_rate = 1e-2
#1e-2=1*10^(-2) = 1/100 = 0.01
optimizer = torch.optim.SGD(feihan.parameters(),lr=learning_rate)#设置训练网络的一些参数
#记录训练的次数
total_train_step = 0
#记录测试的次数
total_test_step = 0
#训练的轮数
epoch = 10#添加tensorboard
writer = SummaryWrite("logs")for i in range(epoch):print("--------第 {} 轮训练开始-------".format(i+1))#训练步骤开始feihan.train()for data in train_dataloader:imgs,targets = dataoutputs = feihan(imgs)loss = loss_fn(outputs,targets)#优化器优化模型optimizer.zero_grad()loss.backward()optimizer.step()total_train_step = total_train_step + 1if total_train_step % 100 == 0:print("训练次数:{},Loss:{}".format(total_train_step,loss.item()))writer.add_scalar("train_loss",loss.item(),total_train_step)#测试步骤开始feihan.eval()total_test_loss = 0total_accuracy = 0with torch.no_grad():for data in test_dataloader:imgs,targets = dataoutputs = feihan(imgs)loss = loss_fn(outputs,targets)total_test_loss = total_test_loss + loss.item()#argmax(1)横向最大值;argmax(0)纵向最大值accuracy = (outputs.argmax(1) == targets).sum()total_accuracy = total_accuracy + accuracyprint("整体测试集上的Loss:{}".format(total_test_loss))print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))writer.add_scalar("test_loss",total_test_loss,total_test_step)writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)total_test_step = total_test_step + 1torch.save(feihan,"feihan_{}.pth".format(i))#torch.save(feihan.state_dict(),"feihan_{}.pth".format(i))print("模型已保存")writer.close()
model.py
#搭建神经网络
from torch import nn
import torchclass Feihan(nn.module):def __init__(self):super(Feihan,self).__init__()self.model = nn.Sequential(nn.Conv2d(3,32,5,stride=1,padding=2),nn.MaxPool2d(2),nn.Conv2d(32,32,5,stride=1,padding=2),nn.MaxPool2d(2),nn.Conv2d(32,64,5,stride=1,padding=2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(1024,64),nn.Linear(64,10))def forward(self,x):x = self.model (x)return xif __name__ == '__main__':
#很多人一般喜欢在这里验证网络的正确性feihan = Feihan()input = torch.ones((64,3,32,32))output = feihan(input)print(output.shape)
6 利用GPU训练模型
如何使用GPU进行训练?其实使用GPU训练,我们只要在原来的代码修改几行就可以。我们仅需要关注网络模型、数据(输入、标注)、损失函数、.cuda()这几部分即可。但是GPU训练有两种方式,所以我们分别以具体的代码进行一个详细理解。
方式一(.cuda):
train_gpu_1.py
import torchvision
from torch.utils.data import DataLoader
#from model import *
from torch import nn
import torch
from torch.utils.ensorboard import SummaryWriter
#time是用来计时的
import time#准备训练数据集
train_data = torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
#准备测试数据集
test_data = torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)#数据集的长度
train_data_size = len(train_data)
test_data_size = len(test_data)
#如果train_data_size=10,训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))#利用DataLoader来加载数据集
train_dataloader = Dataloader(train_data,batch_size=64)
test_dataloader = Dataloader(test_data,batch_size=64)#搭建神经网络
class Feihan(nn.module):def __init__(self):super(Feihan,self).__init__()self.model = nn.Sequential(nn.Conv2d(3,32,5,stride=1,padding=2),nn.MaxPool2d(2),nn.Conv2d(32,32,5,stride=1,padding=2),nn.MaxPool2d(2),nn.Conv2d(32,64,5,stride=1,padding=2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(1024,64),nn.Linear(64,10))def forward(self,x):x = self.model (x)return x#创建网络模型
feihan = Feihan()
#想利用GPU进行训练,所以转到cuda上面
if torch.cuda.is_available():feihan = feihan.cuda()#损失函数
loss_fn = nn.CrossEntropyLoss()
#想利用GPU进行训练,所以转到cuda上面
if torch.cuda.is_available():loss_fn = loss_fn.cuda()#优化器
learning_rate = 0.01
#还可以写成learning_rate = 1e-2
#1e-2=1*10^(-2) = 1/100 = 0.01
optimizer = torch.optim.SGD(feihan.parameters(),lr=learning_rate)#设置训练网络的一些参数
#记录训练的次数
total_train_step = 0
#记录测试的次数
total_test_step = 0
#训练的轮数
epoch = 10#添加tensorboard
writer = SummaryWrite("logs")
start_time = time.time()
for i in range(epoch):print("--------第 {} 轮训练开始-------".format(i+1))#训练步骤开始feihan.train()for data in train_dataloader:imgs,targets = data#想利用GPU进行训练,所以转到cuda上面if torch.cuda.is_available():imgs = imgs.cuda()targets = targets.cuda()outputs = feihan(imgs)loss = loss_fn(outputs,targets)#优化器优化模型optimizer.zero_grad()loss.backward()optimizer.step()total_train_step = total_train_step + 1if total_train_step % 100 == 0:end_time = time.time()print(end_time - start_time)print("训练次数:{},Loss:{}".format(total_train_step,loss.item()))writer.add_scalar("train_loss",loss.item(),total_train_step)#测试步骤开始feihan.eval()total_test_loss = 0total_accuracy = 0with torch.no_grad():for data in test_dataloader:imgs,targets = data#想利用GPU进行训练,所以转到cuda上面if torch.cuda.is_available():imgs = imgs.cuda()targets = targets.cuda()outputs = feihan(imgs)loss = loss_fn(outputs,targets)total_test_loss = total_test_loss + loss.item()#argmax(1)横向最大值;argmax(0)纵向最大值accuracy = (outputs.argmax(1) == targets).sum()total_accuracy = total_accuracy + accuracyprint("整体测试集上的Loss:{}".format(total_test_loss))print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))writer.add_scalar("test_loss",total_test_loss,total_test_step)writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)total_test_step = total_test_step + 1torch.save(feihan,"feihan_{}.pth".format(i))#torch.save(feihan.state_dict(),"feihan_{}.pth".format(i))print("模型已保存")writer.close()
方式二(.to):
train_gpu_2.py
import torchvision
from torch.utils.data import DataLoader
#from model import *
from torch import nn
import torch
from torch.utils.ensorboard import SummaryWriter
#time是用来计时的
import time#定义训练设备
device = torch.device("cuda")
#device = torch.device("cuda:0")#但显卡
#device = torch.device("cuda:1")#双显卡
#device = torch.device("cuda" if torch.cuda.is_available() else "cpu")#如果没有cuda,用cpu
#这四种写法都是常见的,为了适应各种环境#准备训练数据集
train_data = torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
#准备测试数据集
test_data = torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)#数据集的长度
train_data_size = len(train_data)
test_data_size = len(test_data)
#如果train_data_size=10,训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))#利用DataLoader来加载数据集
train_dataloader = Dataloader(train_data,batch_size=64)
test_dataloader = Dataloader(test_data,batch_size=64)#搭建神经网络
class Feihan(nn.module):def __init__(self):super(Feihan,self).__init__()self.model = nn.Sequential(nn.Conv2d(3,32,5,stride=1,padding=2),nn.MaxPool2d(2),nn.Conv2d(32,32,5,stride=1,padding=2),nn.MaxPool2d(2),nn.Conv2d(32,64,5,stride=1,padding=2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(1024,64),nn.Linear(64,10))def forward(self,x):x = self.model (x)return x#创建网络模型
feihan = Feihan()
#相当于把我们的网络转移到我们定义的设备当中去
feihan = feihan.to(device)#损失函数
loss_fn = nn.CrossEntropyLoss()
#相当于把我们的损失函数转移到我们定义的设备当中去
loss_fn = loss_fn.to(device)#优化器
learning_rate = 0.01
#还可以写成learning_rate = 1e-2
#1e-2=1*10^(-2) = 1/100 = 0.01
optimizer = torch.optim.SGD(feihan.parameters(),lr=learning_rate)#设置训练网络的一些参数
#记录训练的次数
total_train_step = 0
#记录测试的次数
total_test_step = 0
#训练的轮数
epoch = 10#添加tensorboard
writer = SummaryWrite("logs")
start_time = time.time()
for i in range(epoch):print("--------第 {} 轮训练开始-------".format(i+1))#训练步骤开始feihan.train()for data in train_dataloader:imgs,targets = data#相当于把我们的数据转移到我们定义的设备当中去imgs = imgs.to(device)targets = targets.to(device)outputs = feihan(imgs)loss = loss_fn(outputs,targets)#优化器优化模型optimizer.zero_grad()loss.backward()optimizer.step()total_train_step = total_train_step + 1if total_train_step % 100 == 0:end_time = time.time()print(end_time - start_time)print("训练次数:{},Loss:{}".format(total_train_step,loss.item()))writer.add_scalar("train_loss",loss.item(),total_train_step)#测试步骤开始feihan.eval()total_test_loss = 0total_accuracy = 0with torch.no_grad():for data in test_dataloader:imgs,targets = data#相当于把我们的数据转移到我们定义的设备当中去imgs = imgs.to(device)targets = targets.to(device)outputs = feihan(imgs)loss = loss_fn(outputs,targets)total_test_loss = total_test_loss + loss.item()#argmax(1)横向最大值;argmax(0)纵向最大值accuracy = (outputs.argmax(1) == targets).sum()total_accuracy = total_accuracy + accuracyprint("整体测试集上的Loss:{}".format(total_test_loss))print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))writer.add_scalar("test_loss",total_test_loss,total_test_step)writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)total_test_step = total_test_step + 1torch.save(feihan,"feihan_{}.pth".format(i))#torch.save(feihan.state_dict(),"feihan_{}.pth".format(i))print("模型已保存")writer.close()
7 完整的模型验证套路:
完整的模型验证(测试、demo)套路:利用已经训练好的模型,然后给它提供输入。
一个实例进行具体理解:
test.py
from PIL import Image
import torchvision
from torch import nnimage_path = "../imgs/dog.png"
image = Image.open(image_path)
print(image)#因为png格式是四个通道,出来rgb三通道外,还有一个透明度通道。所以我们调用image = image.convert('RGB'),保留其通道颜色。
#当然,如果图片本来就是三通道,则不需要进行此操作。
image = image.convert('RGB')transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),torchvision.transforms.ToTensor()])image = transform(image)
print(image.shape)class Feihan(nn.module):def __init__(self):super(Feihan,self).__init__()self.model = nn.Sequential(nn.Conv2d(3,32,5,stride=1,padding=2),nn.MaxPool2d(2),nn.Conv2d(32,32,5,stride=1,padding=2),nn.MaxPool2d(2),nn.Conv2d(32,64,5,stride=1,padding=2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(1024,64),nn.Linear(64,10))def forward(self,x):x = self.model (x)return xmodel = torch.load("feihan_0.pth")
#如果运行报错,我们可以修改为这样:model = torch.load("feihan_0.pth",map_location=torch.device('cpu'))
print(model)
image = torch.reshape(image,(1,3,32,32))
model.eval()
with torch.no_grad():output = model(image)
print(output)print(output.argmax(1))