前言
- 第一次题目集主要学习了类和对象的基本使用,主要训练了对构造方法,私有公共属性,对象的封装的能力,建立起了基本的类的概念,题量正常,最后一题的设计建议十分有用!!!(我自己刚开始建会乱七八糟,但是有了这个框架建议后面每次迭代改进都可以照葫芦画瓢)
- 第二次题目集加深对类的概念的同时,引入容器及一些库函数的学习,比如链表,
compare方法接口,为最后一题做铺垫,需要学习新的容器来满足需求(HashMap&&AbstractMap.SimpleEntry<>),写题时开始需要考虑一些边缘情况,如果不考虑会出现大面积非零返回问题,题量正常,难度合适,最后一题不卡人
- 第三次题目集主要学习了对复杂题目的应对策略,对字符串解析的要求比较高,判断异常情况的严格程度也加强了,同时也学习了编程语言中的一些库,比如
localdate等,题量正常,难度比前两次大,最后一题想要全通过测试用例需要改很多次(仅个人及周围同学所见所得,应该对大部分同学都会是比较棘手的),不过大家卡的测试点都不太一样,和朋友互相帮对方推测恶心测试点的过程非常好玩,能互相学习解题思路。建议都在最后
设计与分析
1.答题判题程序-1
题目分析:
----输入分两类,格式化的题目与答卷,先输入题目数量,再输入题目(不按顺序),包括题号,题面与答案,答卷类按题目顺序输入答案(仅有一行),end结尾
"#N:"+题目编号+" "+"#Q:"+题目内容+" "#A:"+标准答案
#A:"+答案内容...
----输出,题目内容+"~"+答案
\n判题结果(true/false)
注意的点:
1.需要消除空格符,分析与提取需要格式化
2.题目输入的顺序与题号不对应,答案输入的顺序与题号对应
代码分析:


1.可以看出Maximum Complexity(该类中最复杂函数的复杂度)比较高,主要在于split_3和del_lr,前者是将输入的答案分隔提取函数,后者是将字符串前后空格删除而手写的函数,主要由于未使用正则表达式,后期被坑坑坑坑坑,导致许多代码没有被简化。
2.由于答卷类只有一行,所以输入即输出,有许多备用的容器没用上例如List<Integer>judges(存储答卷正误信息的数组)
3.题目附了设计建议,更好的设计了类直接的关系,比如题目与试卷是聚合关系,答卷与试卷是聚合关系,一个判断题目正确的函数由: 题目类的is_right->试卷类的is_paper_right -> 答卷类的is_reply_right
4.只用到了ArrayList<>容器
新掌握:
输入以某个标识符截止
String ori_ans = sc.nextLine();while (!ori_ans.equals("end")) {//.......ori_ans = sc.nextLine();}
2.答题判题程序-2
题目分析:
----在1的基础上新增试卷信息,试卷包含了试卷号,题号,题目分值,答卷新增了试卷号,输入增加一种,三种输入打乱顺序
"#S:"+试卷号+" "+"#A:"+答案内容
----输出新增试卷总分警告,新增分数输出,判卷信息输出合并
题目得分+" "+....+题目得分+"~"+总分
注意的点:
-
答卷可能无效对应,试卷也会无效对应,需要加判断
-
答案输入不全/输多了,两种情况都需要判断
-
试卷总分警告需要在试卷刚输入时输出
代码分析:


-
输入分析的时候写的是switch,现阶段只有三种输入,所以还算正常,但应该马上就不正常了
-
类图上比较明显的是,此次代码还是不习惯设
private,当然是不想写,下一次就改进了!get/set啦 -
输出时顺序:
out_all-->out_data-->out_judge-->out_score,这样一步步都分出一种方法,然后内嵌到out_all里就很完整方便维护。
新掌握:
- 类pair容器(键值对):发现java里没有pair,新学的,因为需要存储题目对应分值的集合,虽说也可以只存题号+分值来着 ,但这样就是更方便呃呃,而且需要保存题目顺序!!!个人认为是方便的
class paper: //试卷类
public List<AbstractMap.SimpleEntry<question, Integer>> questions; //类pair
public int is_paper_right(int que_id, String que_answer){question q = questions.get(que_id).getKey(); //这里的get是按输入顺序的0--n,不是key奥!return q.is_right(que_answer);
}
取私有属性值(偏麻烦):a_paper.questions.get(idx).getKey().gettext();
- 新加入正则表达式,开始有意识的做了替换,高级简洁多了(虽然还不是最简洁,但更好理解)
格式:"#T:"+试卷号+" "+题目编号+"-"+题目分值(#T:1 3-5 4-8 5-2)
String[] p = pa.split(" "); //以空格分隔Pattern pattern = Pattern.compile("#T:(\\d+)");Matcher matcher = pattern.matcher(p[0]);if (matcher.find()) {// 提取试卷号}paper pp = new paper(iid,p.length-1);for(int i = 1; i<p.length; i++){pattern = Pattern.compile("(\\d+)-(\\d+)");matcher = pattern.matcher(p[i]);if (matcher.find()) {//提取每个题目}}
2.答题判题程序-3
题目分析:
在2的基础上,新增学生信息,删除题目信息,共五种表达式混合输入。要分析格式错误
输出错误格式的信息,及各种警告,然后才是普通的输出批改结果
注意的点:
-
错误输入要判定!各种错误格式千奇百怪!各种都要考虑到(空字符||空格||非数字||顺序不对)
-
输出有优先级!看清题目要求!
-
各种不对应,不存在,答卷无效对应试卷,试卷无效对应题目(删除||真·不在,输出不同!被坑啦!!),学号对应无效
-
续上了第二题的答案输入为空,答案少输||多输
-
各种警告要对应!写到后期会混乱,最好记录一下
代码分析:


- 这题刚开始错了比较多,一开始直接错了1/3,然后发现是答案多输||少输||空字符的问题(第二题的子弹正中眉心),改完之后就还剩两个测试点了。
少输 (没输#A: || 没输题号 || 没输答案)= 输入为空,多输 = 无效,多输空格 = 没事,
-
剩下两个为:题目的格式错与试卷的格式错
-
这次总算把
public与private都改的像样了,虽然麻烦多了但感觉合规多了。
新掌握:
1.改进后的试卷提取版本,可以由结果推过程
public int paperStandard(String pa, questionList qqlist, paperList papers) { /* 试卷信息输入 */Pattern pattern = Pattern.compile("(#T:(\\d))");Matcher matcher = pattern.matcher(pa);if (matcher.find()) {s.append(matcher.group(1));// 提取的数字}else{return 0; /* 格式错,试卷号不对 */}pattern = Pattern.compile("(\\s(\\d+)-(\\d+))");matcher = pattern.matcher(pa);while (matcher.find()) {//循环提取}if(!s.toString().equals(pa)){ /* 格式错,当不相等则=输入有误 */return 0;}
2.输入方法时,先开好各集合的对象,再传入进去
void in_(paperList papermap, questionList qlist, replyList replylist,SStudentList studentlist)
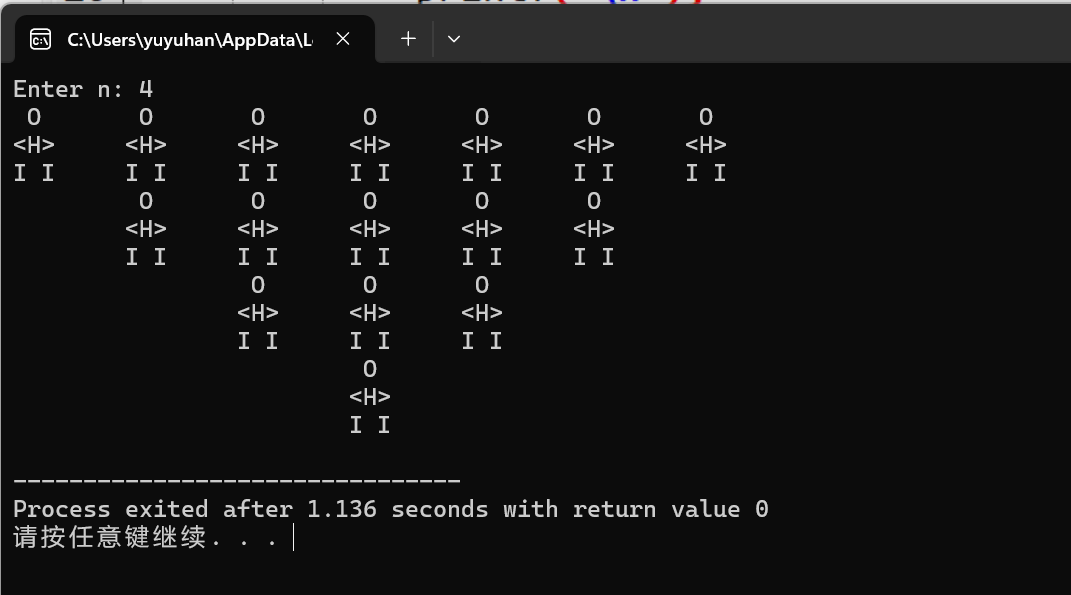
试卷输入顺序图:

踩坑心得
1.( 答题判题程序-1)未考虑输入答案也会有空格需要格式化,理所当然的认为空格也是答案的一部分。
典型输入:

正确输出:

理解:同时,题目输入的答案也需要消除空格,为第三个坑埋下伏笔
2. (答题判题程序-2)看清题目要求!试卷满分警告在输入试卷后即输出!不是在合集里输出!这个错误贯穿了后两题,需要引起重视

3.(答题判题程序-3)for循环的标志变量未置零,这也是经常犯的错误
4.(答题判题程序-3) 这个答案的输入涵盖最多,错误点也覆盖的最多,改了之后终于分清了"answer is null"与空字符输入

输出:

5.(答题判题程序-3) 题目输入的监测忘记监测标准答案值非空,硬控我好久,要注意每一个可能的点!
if(str[0].isEmpty() || str[1].isEmpty() || str[2].isEmpty()|| str[2].contains("#")){return 0;}
6.(答题判题程序-3) 非零返回问题,都是访问出错,最多的就是数组越界,访问空指针,这次一直错的是HashMap值没有保护措施,访问为空了还赋值,你不非零返回谁非零返回,以下是改进后代码
question qu;/*不存在就存一个unlive的问题*/if(qqlist.questionMap.containsKey(que)){qu = qqlist.questionMap.get(que);}else{qu = new question();}pp.saveQuestion(qu, sco);
改进建议
个人代码改进策略:
-
答题判题程序-1&&2都没有加注释,第三次修改时特别不方便,注释太太太重要l,特别是大作业。
-
需要多了解库函数,比如自己手敲的删除前后空格函数是有可以调用的
trim() -
本人的变量命名比较不规范,已经下载规范化代码插件学习进步
-
个人对正则表达式的运用还是比较不熟,有些函数本可以用正则表达式改进
-
正则表达式最好定义为常量字段,便于管理和修改,利用好其预编译功能,可以有效加快正则匹配速度。

-
喜欢使用未被定义的常量,数值使用不规范,多处使用不统一,修改时工作量大且容易遗漏

-
代码健壮性:
在deleteQuestion方法中,如果题目不存在,应该有相应的处理逻辑。
在replyStand方法中,如果reply对象的paperId或studentId无效,应该有相应的处理逻辑。 -
代码性能:
如果questionList、paperList、SStudentList和replyList中的集合很大,应该考虑使用更高效的数据结构或算法。
总结
学到了:
-
学习新方法/库函数/容器时,需要自己做点笔记,不然后期又忘记基本用法,教训就是
HashMap次次忘基本方法,每次都要重新搜。 -
对于删除操作,可以形删,类似这样的小技巧
-
学了一些新的函数与容器,记住,不要停止尝试新方法,怕麻烦最终会带来更大的麻烦
-
私有属性与公共属性更加熟练,对代码的保护加强
-
对各项边界值考虑的更加清楚,会考虑到很多以前不注意的点,输入为空等
展望:
-
个人认为,输入形式经常发生变化,但基本的类还是稳定的,所以习惯把输入格式分离的函数都放在一个
standard类里,同时操作,这样也可以把难题一次性解决,让其他稳定类更好单飞,不过后续要求多的时候,这个类比较冗杂,下次尝试新分类。 -
提高代码的内聚性等性能,内聚性是指子程序中各种操作之间联系的紧密程度。高内聚性是会降低bug出现频率的
功能上的内聚性顺序上的内聚性等耦合度表示类与类之间或者子程序与子程序之间关系的紧密程度,与耦合相对应的是模块之间的关系松散。 能使一个模块很容易被其他模块使用。总结就是一个子程序最好仅执行一项操作
对课程改进建议:
-
可以尝试让大家上传自己创的测试用例,互测,感觉现有的测试用例有些地方不够全面,比如答卷类输入
#S没有错误格式的测试点,没有写这方面的代码也能全对 -
可以选取一些写的较好的代码分享一下,想了解更规范的代码格式,对比才能更快进步