数据采集与融合技术实践课第三次作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/2024DataCollectionandFusiontechnology |
|---|---|
| 码云作业gitee仓库 | https://gitee.com/huang-yuejia/DataMining_project/tree/master/work3 |
| 学号 | 102202149 |
| 姓名 | 黄悦佳 |
目录
- 数据采集与融合技术实践课第三次作业
- 一、作业内容
- 作业①:
- 1.爬取网站图片(作业1)
- 2.心得体会
- 作业②:
- 1.爬取股票数据
- 2.心得体会
- 作业③:
- 1.爬取外汇数据
- 2.心得体会
- 二、作业总结
- 一、作业内容
一、作业内容
作业①:
- 要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
1.爬取网站图片(作业1)
本作业源码链接:https://gitee.com/huang-yuejia/DataMining_project/blob/master/work3/work3.1
-
结果展示:
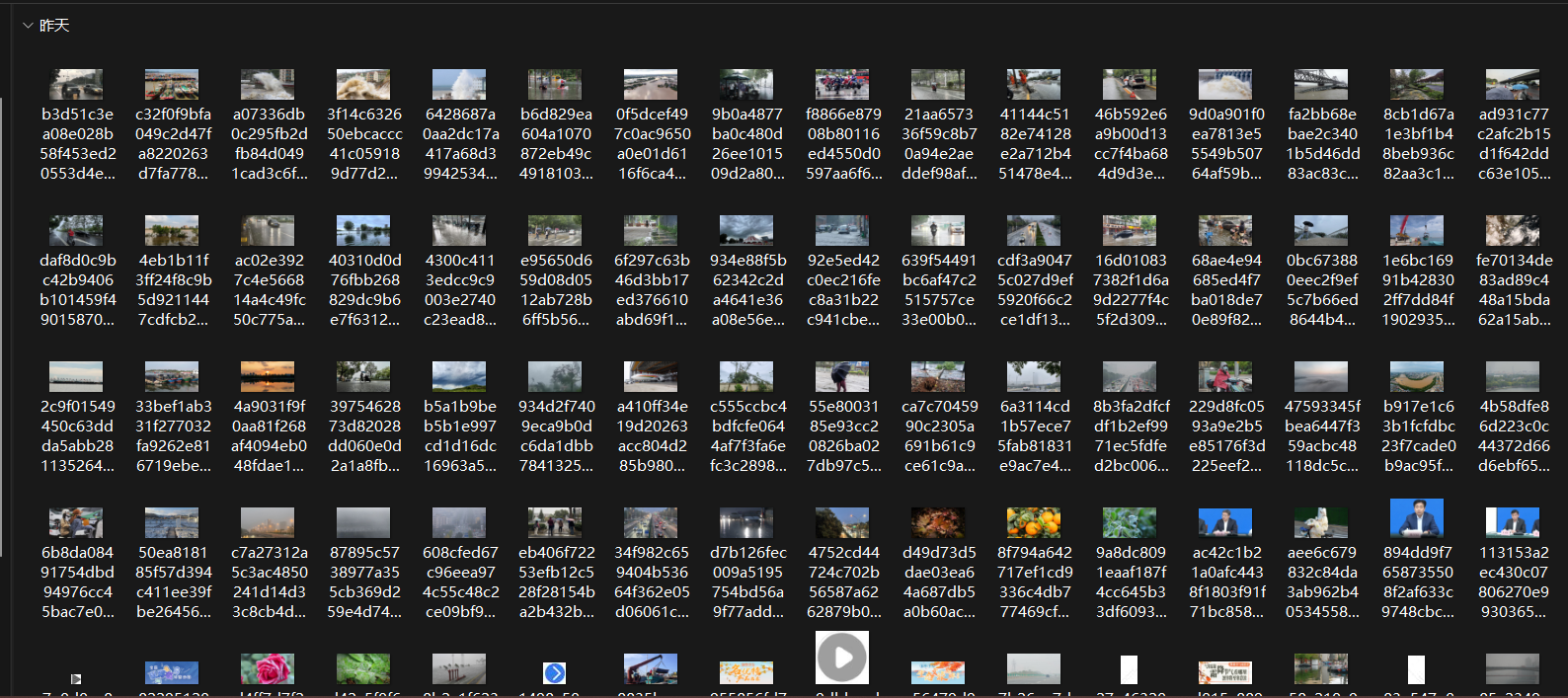
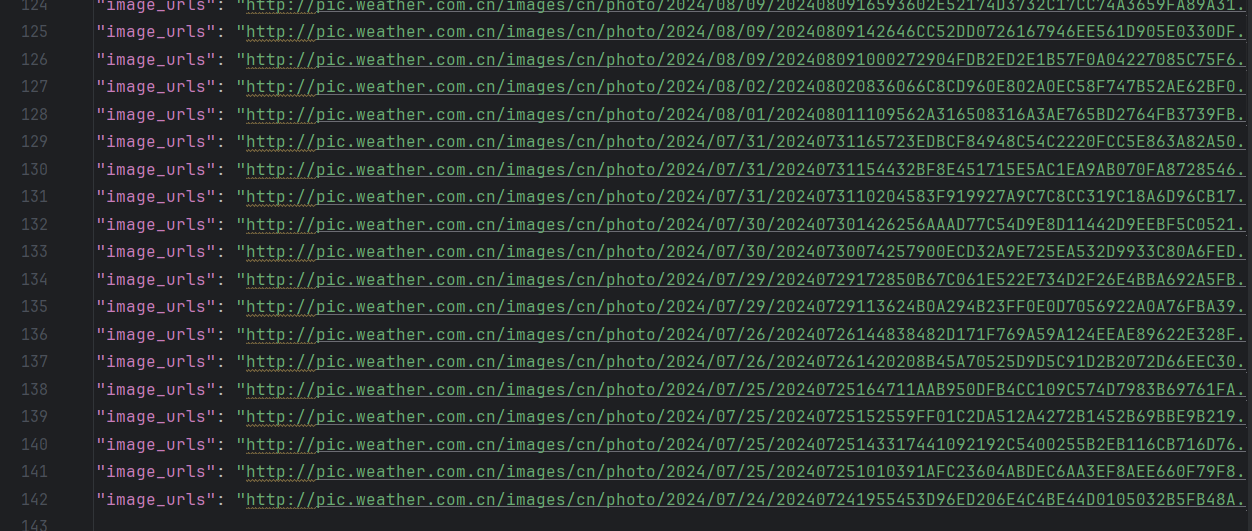
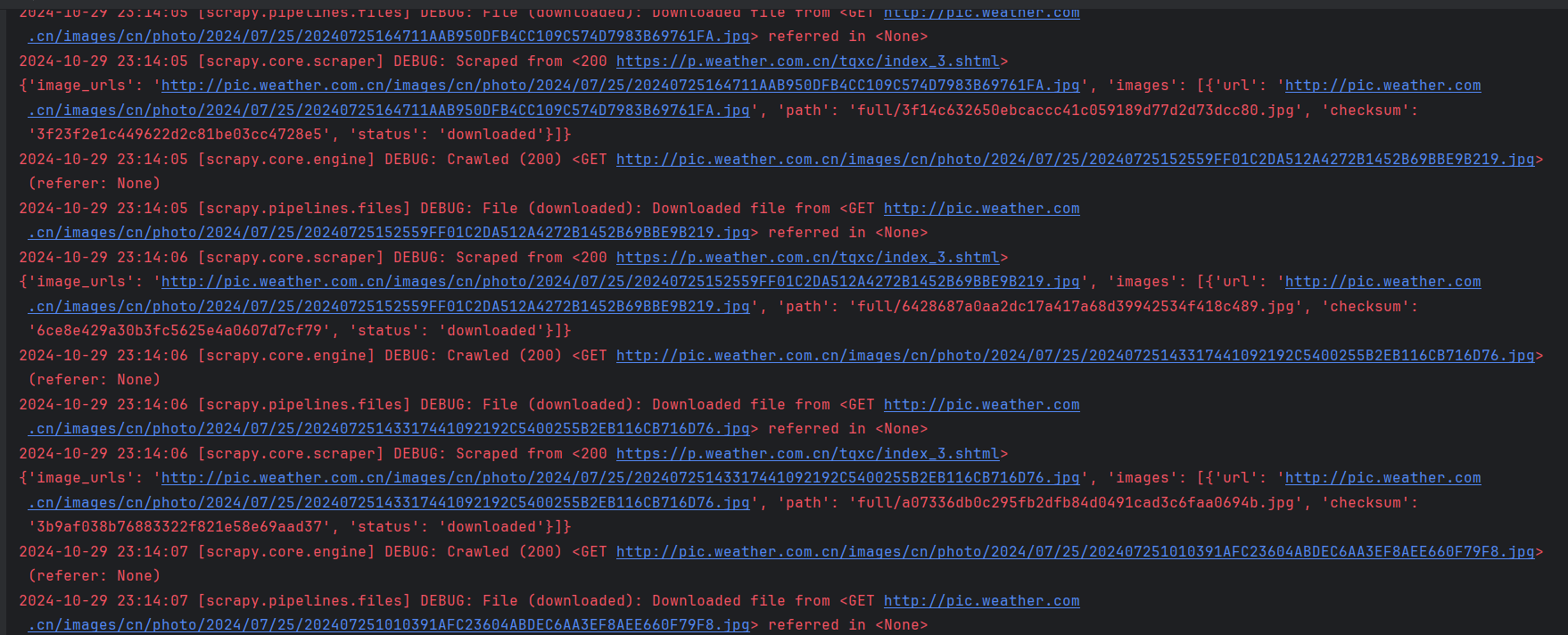
-
关键代码展示:
class WeatherNewSpider(scrapy.Spider):name = 'weather_new_spider'# 设置允许爬取的页面数量和图片数量max_pages = 5 # 控制总页数max_images = 142 # 控制下载的图片数量image_count = 0 # 当前下载的图片数量current_page = 1 # 当前页数start_urls = ['https://p.weather.com.cn/tqxc/index.shtml']def parse(self, response):# 找到图片链接image_urls = response.css('img::attr(src)').getall()for img_url in image_urls:if self.image_count >= self.max_images:breakself.image_count += 1yield {'image_urls': img_url}# 控制页数,爬取下一页if self.current_page < self.max_pages and self.image_count < self.max_images:self.current_page += 1next_page = f'https://p.weather.com.cn/tqxc/index_{self.current_page}.shtml'yield response.follow(next_page, self.parse)def close(self, reason):self.log(f'Total images downloaded: {self.image_count}')
体现多线程
# 最大并发请求数
CONCURRENT_REQUESTS = 16 # 可以根据需要调整# 下载延迟(避免对服务器的压力)
DOWNLOAD_DELAY = 0.5 # 每个请求之间的延迟,单位为秒
2.心得体会
- 分别实现了单线程和多线程的爬取方式。使用 Scrapy 的 CSS 选择器获取图片链接,并在 parse 方法中进行图片链接的提取和处理。当达到设定的最大图片数量或最大页数时,停止爬取。在多线程部分,通过设置 CONCURRENT_REQUESTS 和 DOWNLOAD_DELAY 来控制并发请求数和下载延迟,以优化爬取效率并避免对服务器造成过大压力。
作业②:
- 要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/1.爬取股票数据
本作业源码链接:https://gitee.com/huang-yuejia/DataMining_project/blob/master/work3/work3.2
- 结果展示:
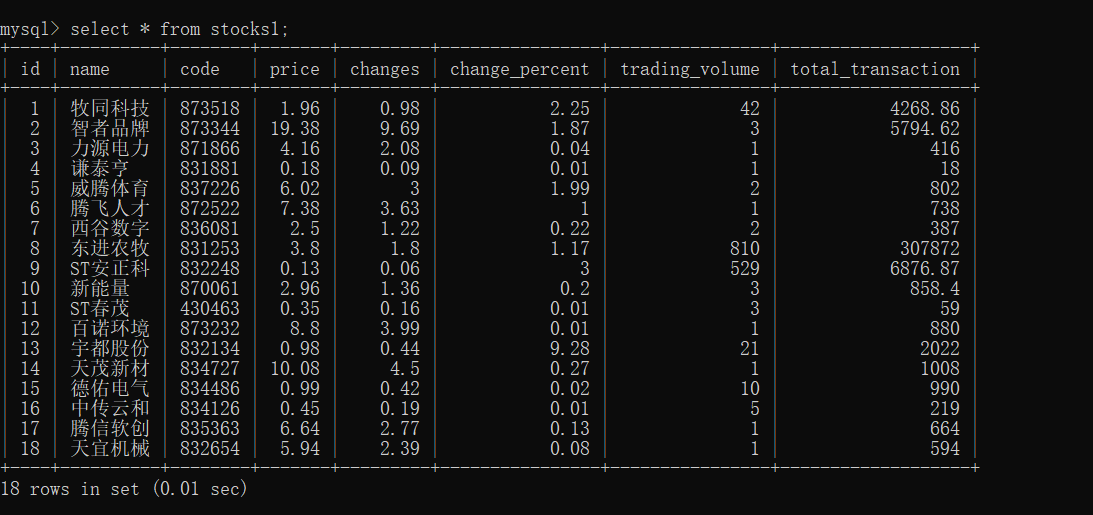
- 关键代码展示:
爬取数据
def parse(self, response):# 提取 JSON 数据json_str_start = response.text.index('(') + 1json_str_end = response.text.rindex(')')json_str = response.text[json_str_start:json_str_end]# 解析 JSON 数据data = json.loads(json_str)if 'data' in data and 'diff' in data['data']:for stock in data['data']['diff']:item = StockItem()item['code'] = stock.get('f12') # 股票代码item['name'] = stock.get('f14') # 股票名称item['price'] = stock.get('f2') # 当前价格item['change'] = stock.get('f4') # 涨跌item['trading_volume'] = stock.get('f5') # 交易量item['total_transaction'] = stock.get('f6') # 总交易金额item['change_percent'] = stock.get('f10') # 涨跌幅度yield itemelse:self.logger.error("数据格式不正确或未找到 'diff' 字段。")
2.心得体会
- 实践了mysql与scrapy技术的结合,将爬取的数据存储在连接的数据库中,方便对数据进一步的操作和分析。
作业③:
- 要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
本作业源码链接:https://gitee.com/huang-yuejia/DataMining_project/blob/master/work3/work3.3
1.爬取外汇数据
-
结果展示:
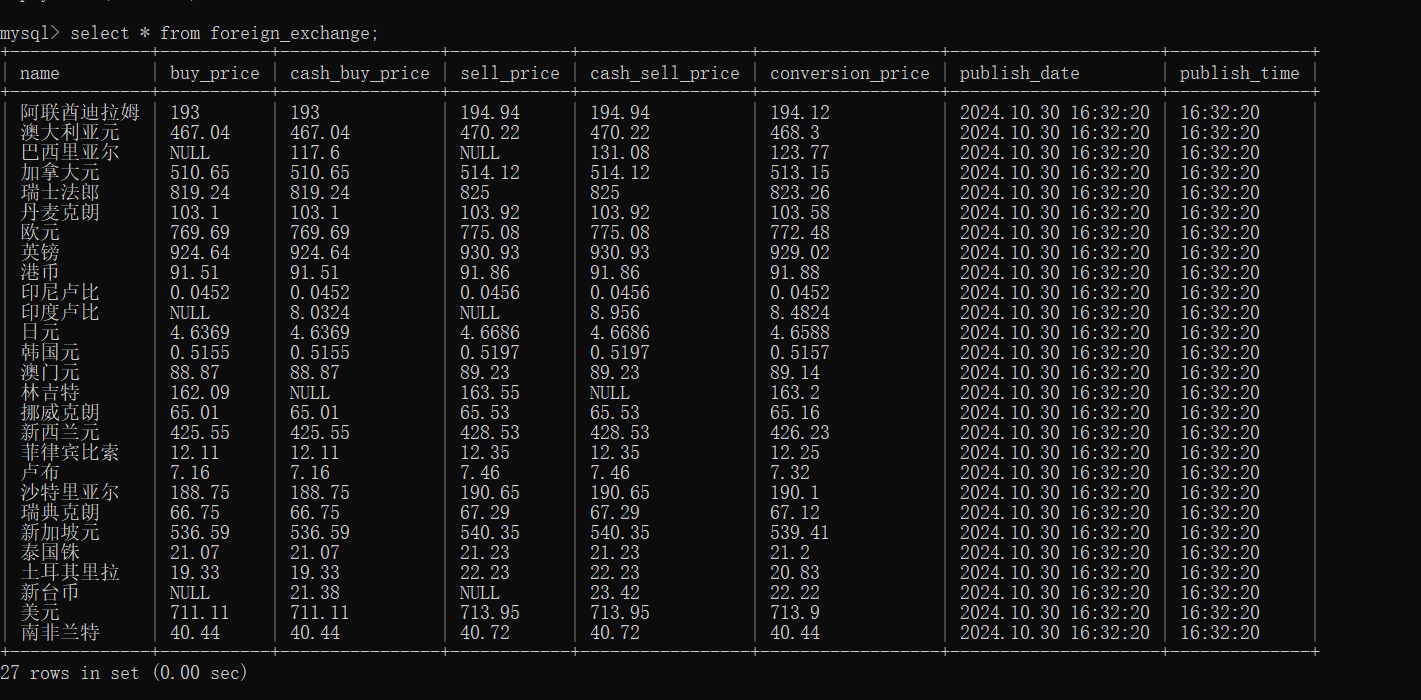
-
关键代码展示:
class ForeignSpider(scrapy.Spider):name = "foreign"allowed_domains = ["boc.cn"]start_urls = ["https://www.boc.cn/sourcedb/whpj/"]def parse(self, response):rows = response.xpath('//table//tr[position()>1]')for row in rows:item = ForeignExchangeItem()item['name'] = row.xpath('./td[1]/text()').get()item['buy_price'] = row.xpath('./td[2]/text()').get()item['cash_buy_price'] = row.xpath('./td[3]/text()').get()item['sell_price'] = row.xpath('./td[4]/text()').get()item['cash_sell_price'] = row.xpath('./td[5]/text()').get()item['conversion_price'] = row.xpath('./td[6]/text()').get()item['publish_date'] = row.xpath('./td[7]/text()').get()item['publish_time'] = row.xpath('./td[8]/text()').get()yield item
2.心得体会
- 通过 XPath 表达式定位网页中的表格数据,进行准确的筛选爬取。
二、作业总结
- 通过本次作业,对数据采集技术有了更全面和深入的实践经验。在完成各项任务的过程中,不仅掌握了 Scrapy 框架的核心技能,还学会了如何应对各种实际问题和挑战。虽然在过程中遇到了一些困难,但通过不断地调试和学习,逐渐克服了这些问题,提高了自己的编程能力和数据处理能力。在今后的学习和实践中,将继续深化这些技术的应用,不断改进和完善数据采集方案,以满足更多复杂的数据获取需求。同时,也会关注数据的质量和合法性,确保采集到的数据能够为后续的分析和应用提供可靠的支持。