作业3
我的getee仓库链接 https://gitee.com/LLLzt-III/crawl_project
作业3代码链接 https://gitee.com/LLLzt-III/crawl_project/tree/master/作业3
一、作业①:
- 要求:指定一个网站,爬取这个网站中的所有的图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
-务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。 - 输出信息:
- 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
1.1思路与步骤
-
确定目标网站和数据:
- 选择要爬取的网页:中国气象网(http://www.weather.com.cn)。
- 明确要爬取的图片,即这个网站中的所有的图片。
-
项目创建:
- 在项目中定义一个Item来存储图片的URL和二进制数据。
-
定义Item:
- 使用
BeautifulSoup对返回的网页内容进行解析,创建一个soup对象。
- 使用
-
编写Spider:
- 创建一个Spider,用于爬取中国气象网的图片。
-
图片下载:
- 实现图片的下载逻辑,并将图片保存到本地的images文件夹中。
-
测试与运行:
- 运行Spider并测试确保图片能够正确下载。
1.2作业代码与实现
import scrapy
from weather_images.items import WeatherImageItemclass WeatherSpider(scrapy.Spider):name = "weather1"allowed_domains = ["weather.com.cn"]start_urls = ["http://www.weather.com.cn/"] # 修复了 URL,移除了错误的字符def parse(self, response):item = WeatherImageItem()# 使用xpath选择器来提取图片的URLimage_urls = response.xpath('//img/@src').getall()item['image_urls'] = image_urls# 记录每个图片 URLfor url in image_urls:self.logger.info(f"Downloading image from: {url}")yield item
1.3运行结果:
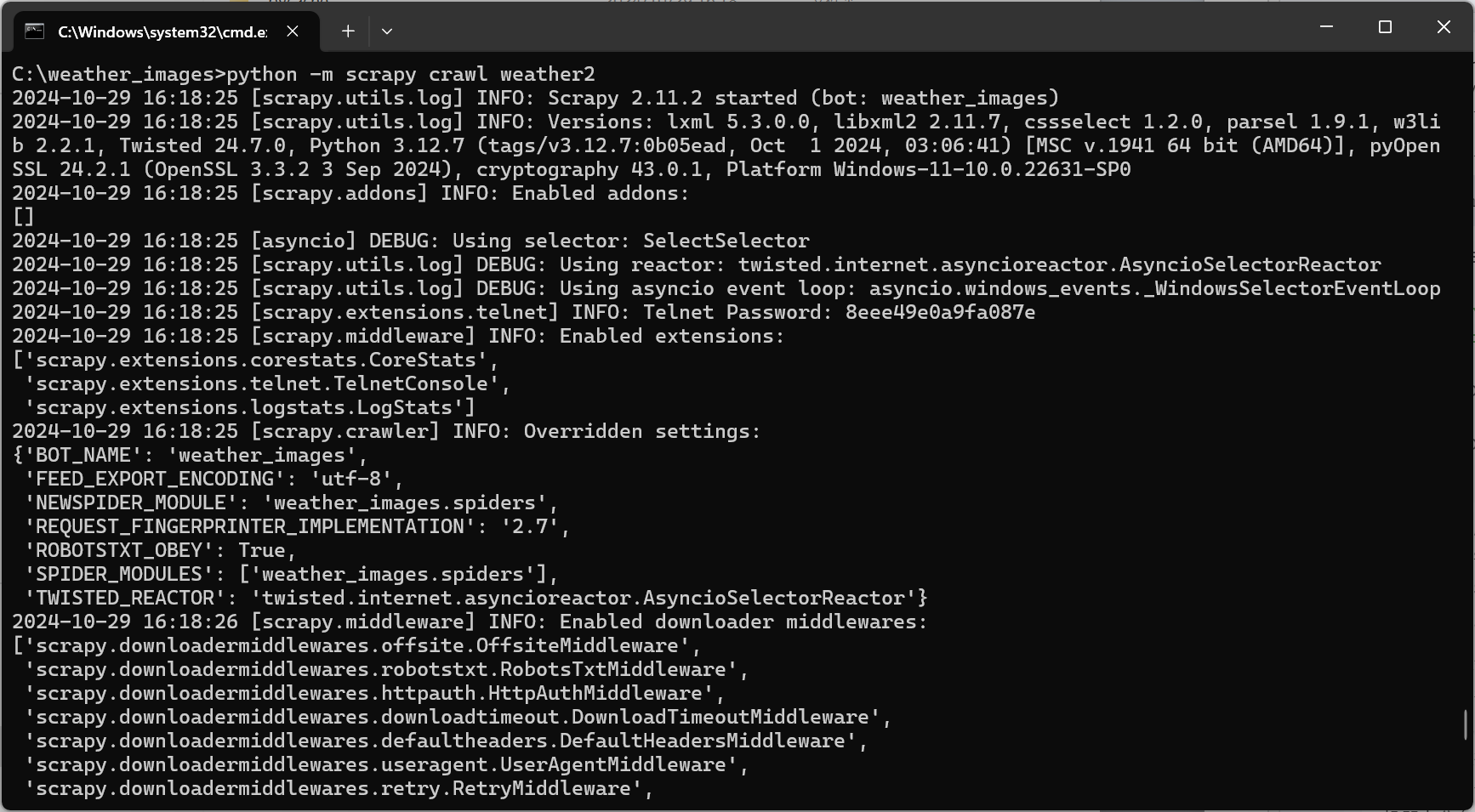
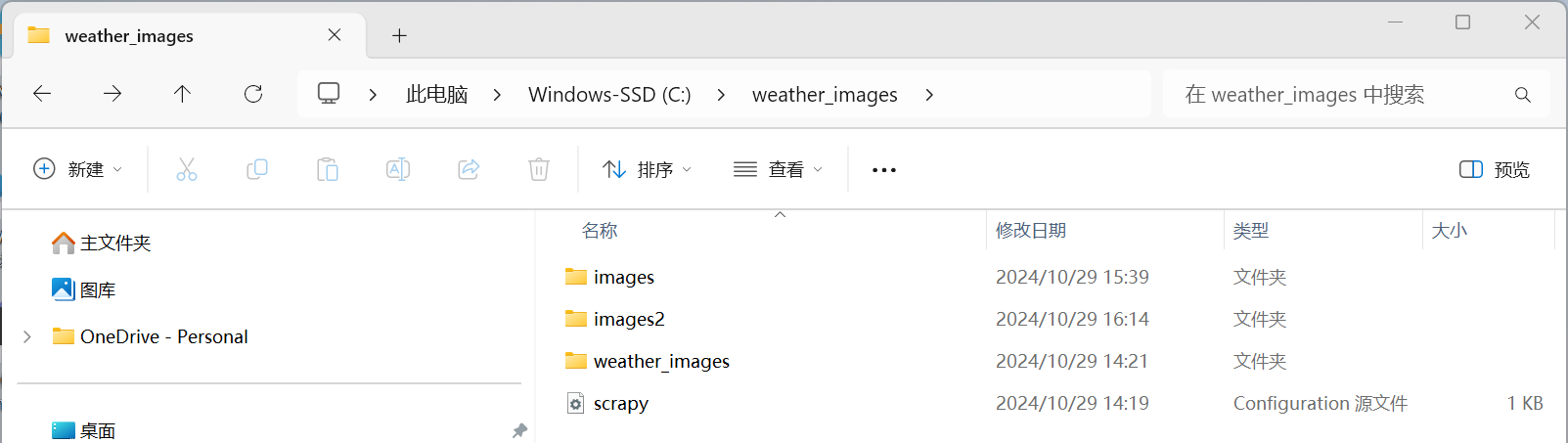
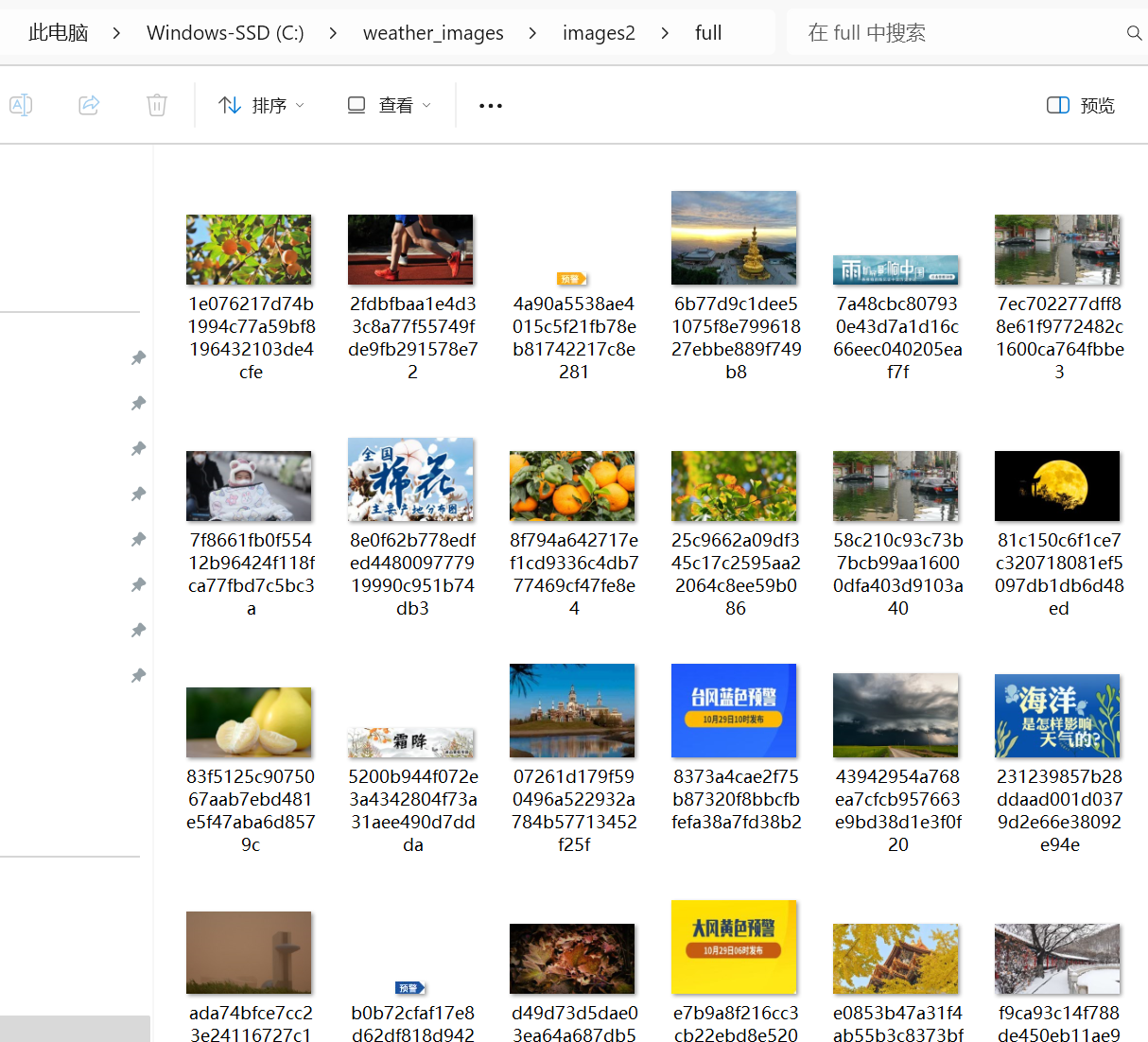
1.4代码解析:
1.导入模块:导入了scrapy用于爬虫框架,以及WeatherImageItem,这是一个自定义的Scrapy Item,用于存储爬取的图片信息。
2.定义Spider:定义了一个名为WeatherSpider的Scrapy Spider。
3.属性:
- name:爬虫的名称。
- allowed_domains:允许爬取的域名列表,这里只允许爬取weather.com.cn域下的页面。
- start_urls:初始URL列表,Scrapy将从这些URL开始爬取。
4.parse方法:这是Scrapy框架调用的主要方法,用于处理响应并提取数据。
- WeatherImageItem:创建一个WeatherImageItem实例,用于存储爬取的图片信息。
5.提取图片URL:使用XPath选择器//img/@src来提取页面中所有标签的src属性,即图片的URL。
6.记录图片URL::遍历所有提取到的图片URL,并使用self.logger.info记录每个URL,这将在Scrapy的日志中显示。
7.生成Item:yield关键字用于生成WeatherImageItem实例,Scrapy会将这些Item传递给Item Pipeline进行进一步处理,保存到数据库或文件中。
1.5作业心得:
在完成作业①的过程中,我学习了Scrapy框架的基本使用方法,包括如何创建项目、定义Item、编写Spider以及如何下载文件。我意识到了爬虫在数据采集中的强大能力,同时也体会到了在编写爬虫时需要遵守的道德和法律规范,比如控制爬取速度和数量,以免对目标网站造成不必要的负担。
二、作业②:
- 要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
- 候选网站:东方财富网:https://www.eastmoney.com/
- 输出信息:
- MySQL数据库存储和输出格式如下:
| 序号 | 股票代码 | 股票名称 | 最新报价 | 涨跌幅 | 涨跌额 | 成交量 | 振幅 | 最高 | 最低 | 今开 | 昨收 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 688093 | N世华 | 28.47 | 10.92 | 26.13万 | 7.6亿 | 22.34 | 32.0 | 28.08 | 30.20 | 17.55 |
| 2 | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
2.1思路与步骤
-
确定目标网站和数据:
- 选择要爬取的网页:东方财富网:https://www.eastmoney.com/
- 明确要提取的数据,即爬取股票相关信息。
-
项目创建:
- 使用Scrapy命令创建一个新的Scrapy项目。
-
数据库设计:
- 设计MySQL数据库表结构,以存储爬取的股票信息。
-
定义Item:
- 在项目中定义一个Item,包含所有需要爬取的股票信息字段。
-
编写Spider:
- 创建一个Spider,用于爬取东方财富网的股票信息。
-
数据存储:
- 实现Pipeline,将爬取的数据存储到MySQL数据库中。
-
测试与运行:
- 运行Spider并测试确保数据能够正确存储到数据库。
2.2作业代码
import scrapy
import json
from stock_info.items import StockInfoItemclass EastmoneySpider(scrapy.Spider):name = 'eastmoney'allowed_domains = ['eastmoney.com']base_url = "https://69.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112404359196896638151_1697701391202&pn={page}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=%7C0%7C0%7C0%7Cweb&fid=f3&fs=m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1697701391203"def start_requests(self):for page in range(1, 4): # 限制爬取前3页url = self.base_url.format(page=page)yield scrapy.Request(url=url, callback=self.parse)def parse(self, response):try:data = response.textjson_data = json.loads(data[data.find('{'):data.rfind('}') + 1])stock_list = json_data['data']['diff']for stock in stock_list:item = StockInfoItem() # 确保这里使用的是正确的Item类item['code'] = stock['f12']item['name'] = stock['f14']item['latest_price'] = stock['f2']item['change_degree'] = stock['f3']item['change_amount'] = stock['f4']item['volume'] = stock['f5']item['amplitude'] = stock['f6']item['highest'] = stock['f15']item['lowest'] = stock['f16']item['today'] = stock['f17']item['yestoday'] = stock['f18']yield itemexcept json.JSONDecodeError as e:self.logger.error(f"JSON解析错误: {e}")except KeyError as e:self.logger.error(f"字段缺失: {e}")
2.3运行结果:
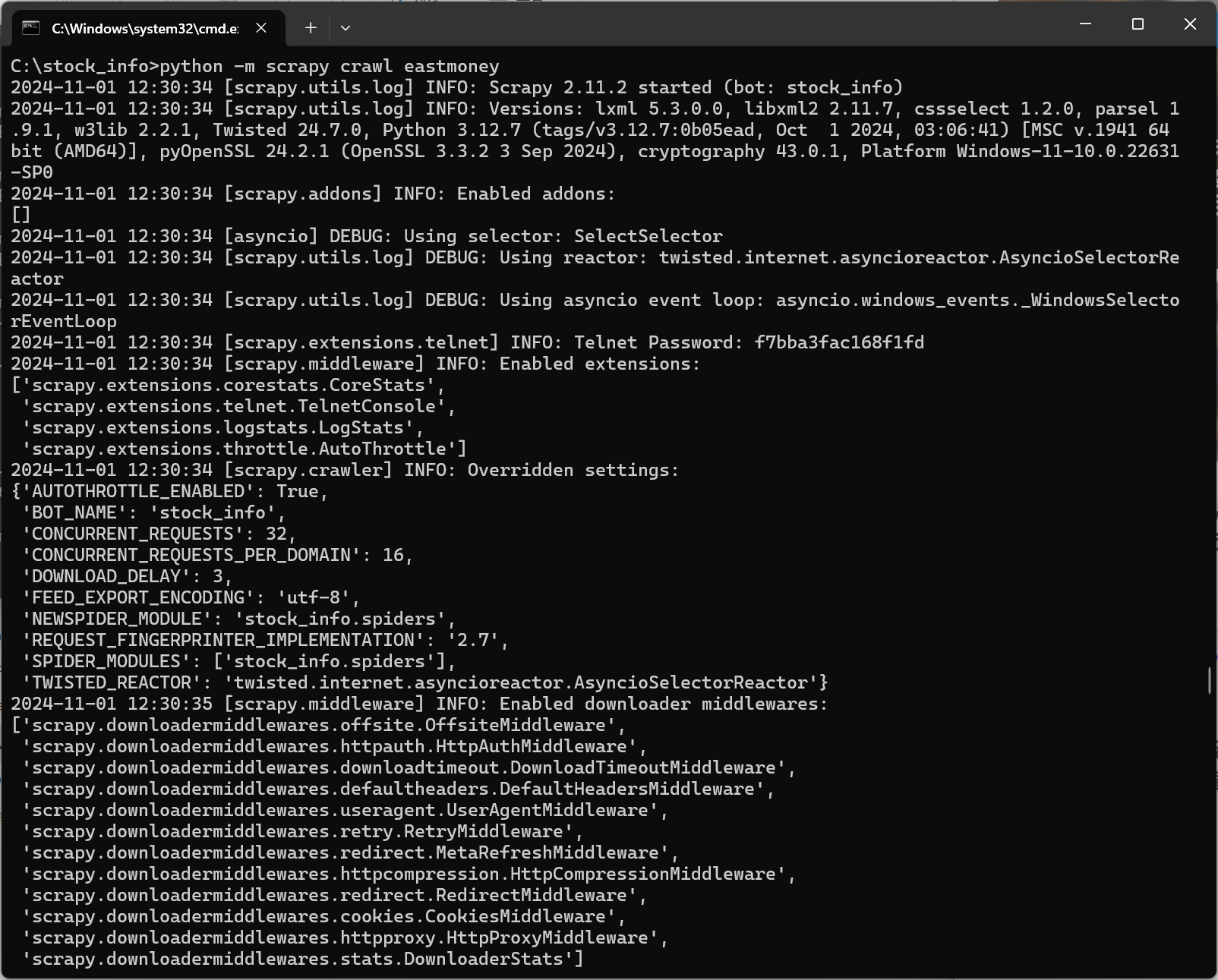
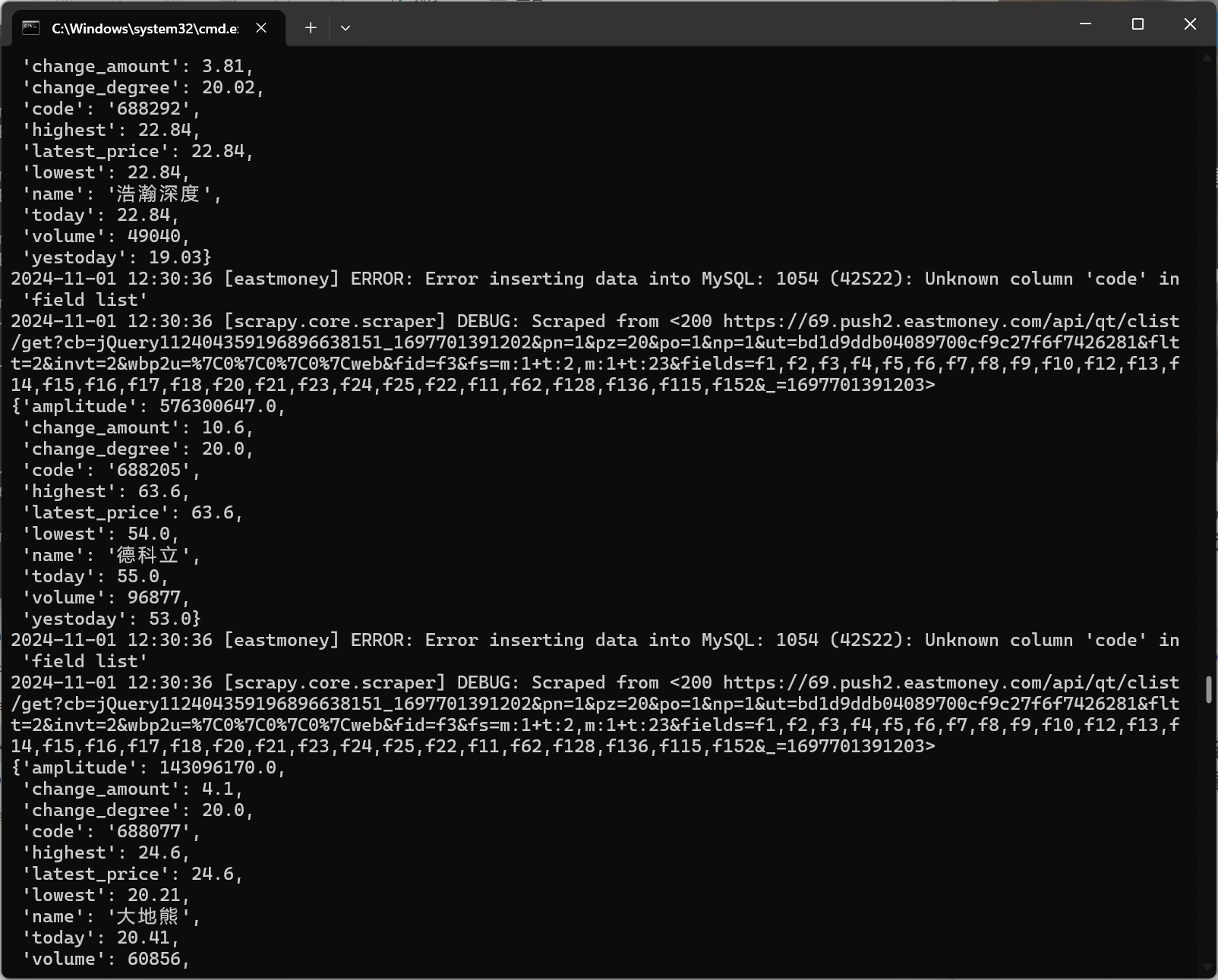
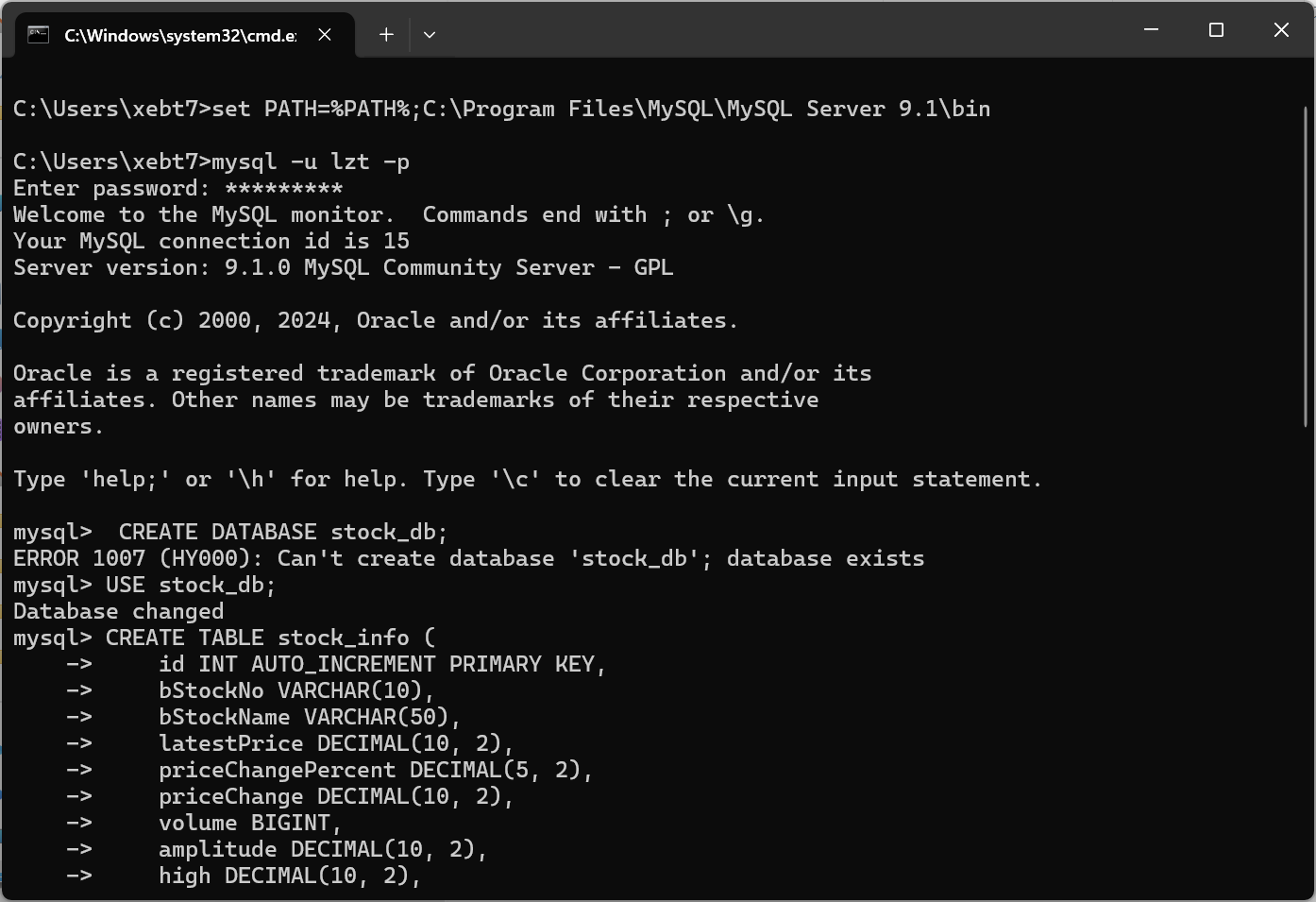
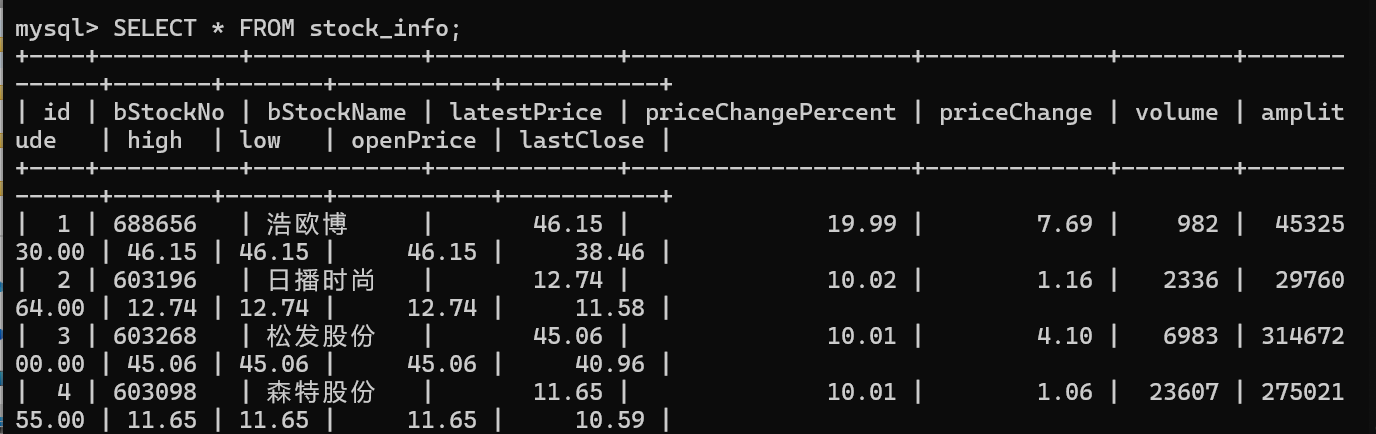
2.4代码解析:
1.导入模块:导入了scrapy用于爬虫框架,json用于处理JSON数据,以及StockInfoItem用于定义爬取的数据结构。
2.定义Spider:定义了一个名为EastmoneySpider的Scrapy Spider。
3.属性:
- name:爬虫的名称。
- allowed_domains:允许爬取的域名列表。
- base_url:请求的基础URL,用于构造请求的URL。
4.start_requests方法:Scrapy框架会调用此方法来生成初始请求。这里通过循环生成前3页的请求,并将parse方法作为回调函数
5.parse方法:这是回调函数,用于处理响应并提取数据。
2.5作业心得:
通过作业②,我深入了解了Scrapy框架与数据库结合使用的方法,学会了如何设计数据库表结构以及如何将数据存储到数据库中。这个过程中,我遇到了一些困难,比如如何正确地处理和转换数据类型,以及如何优化Scrapy的爬取效率。这些经验对于我未来处理和分析网络数据非常有帮助。
三、作业③:
- 要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
- 候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
- 输出信息:
| Currency | TBP | CBP | TSP | CSP | Time |
|---|---|---|---|---|---|
| 阿联酋迪拉姆 | 198.58 | 192.31 | 199.98 | 206.59 | 11:27:14 |
3.1思路与步骤
-
确定目标网站和数据:
- 选择要爬取的网页:中国银行网:https://www.boc.cn/sourcedb/whpj/
- 明确要提取的数据,即爬取外汇网站数据。
-
项目创建:
- 使用Scrapy命令创建一个新的Scrapy项目。
-
数据库设计:
- 设计MySQL数据库表结构,以存储爬取的外汇信息。
-
定义Item:
- 在项目中定义一个Item,包含所有需要爬取的外汇信息字段。
-
编写Spider:
- 创建一个Spider,用于爬取中国银行外汇牌价信息。
-
数据存储:
- 实现Pipeline,将爬取的数据存储到MySQL数据库中。
-
运行与测试:
- 运行Spider并测试确保数据能够正确存储到数据库。
3.2作业代码与实现
import scrapy
from forex.items import ForexItemclass BankSpider(scrapy.Spider):name = 'bank'allowed_domains = ['www.boc.cn']start_urls = ['https://www.boc.cn/sourcedb/whpj/']def parse(self, response):table = response.xpath('//table[1]')rows = table.xpath('.//tr')[1:] # 跳过表头for row in rows:item = ForexItem()item['Currency'] = row.xpath('.//td[1]/text()').get()item['TBP'] = row.xpath('.//td[2]/text()').get()item['CBP'] = row.xpath('.//td[3]/text()').get()item['TSP'] = row.xpath('.//td[4]/text()').get()item['CSP'] = row.xpath('.//td[5]/text()').get()item['Time'] = row.xpath('.//td[7]/text()').get()yield item
3.3运行结果:
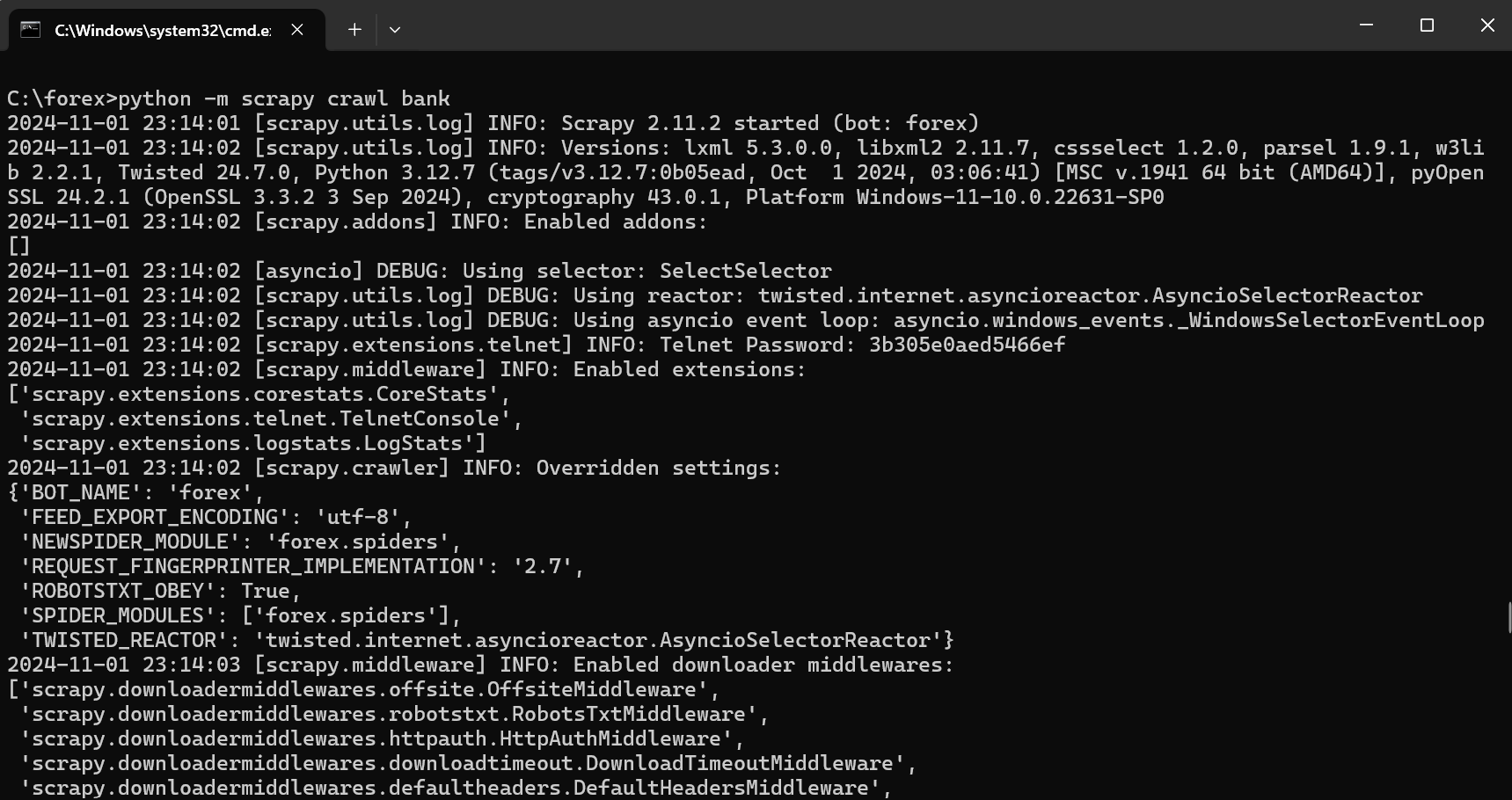
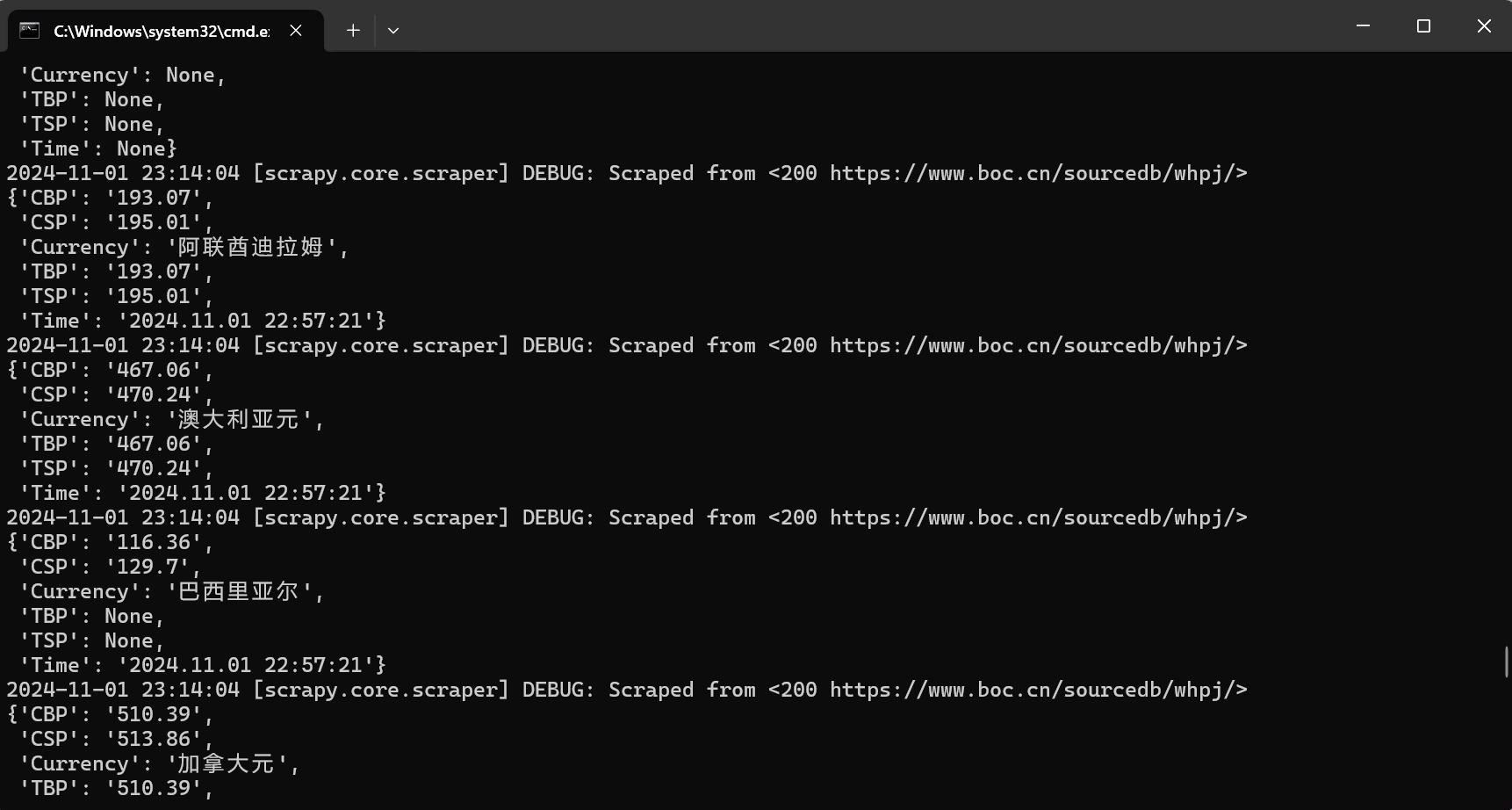
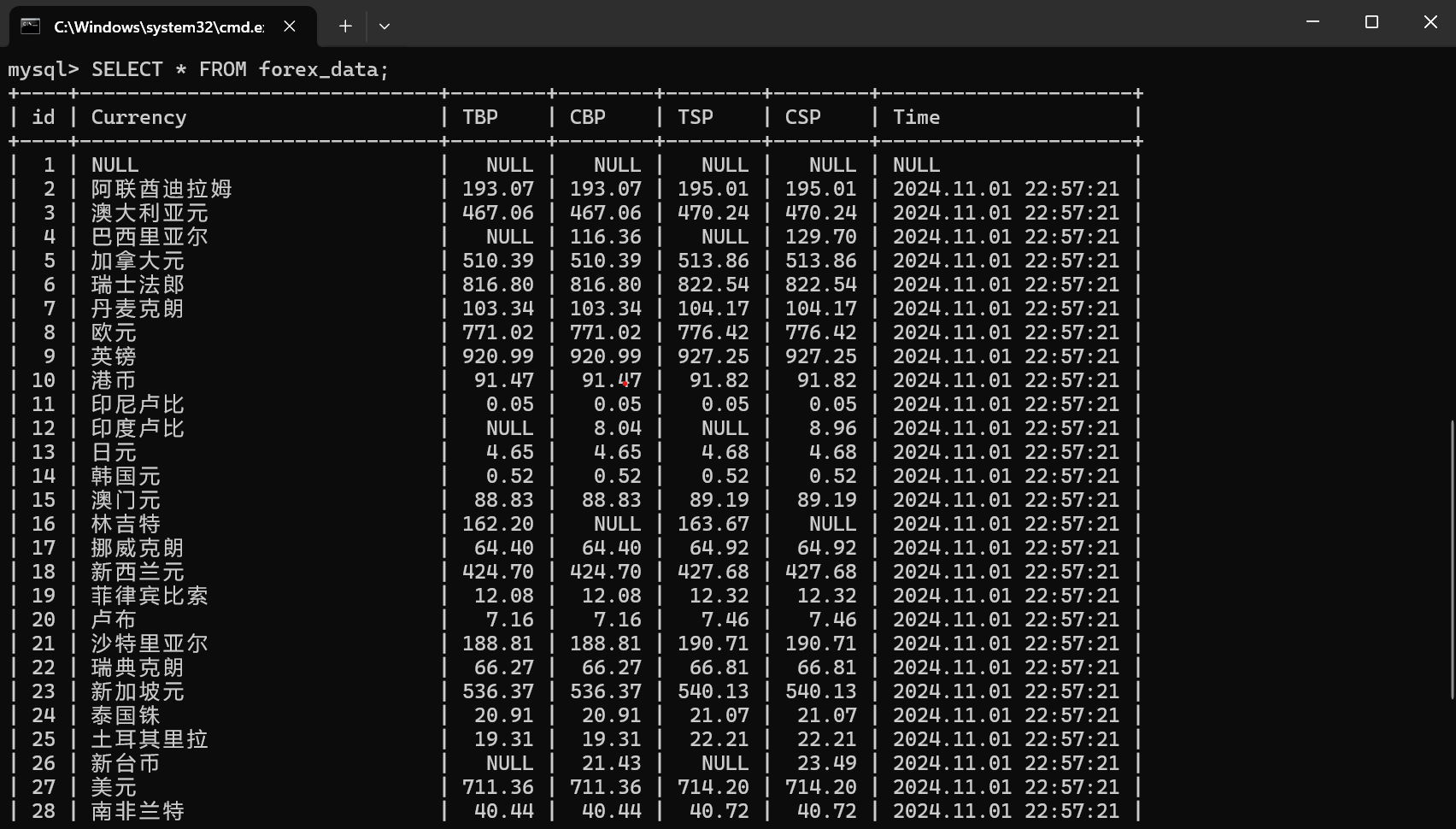
3.4代码解析:
1.导入模块:导入Scrapy框架的核心模块,使得可以使用Scrapy提供的类和函数。
2.定义Spider:定义BankSpider类,设置爬虫的名称、允许的域名和起始URL。
3.parse方法:用于解析网页响应,提取表格中的数据。
4.XPath选择器:使用XPath选择器定位表格行,并逐行提取货币名称、买入价、卖出价和时间等信息。
5.生成Item:将提取的数据存储到ForexItem实例中,并产出这些实例以供后续处理。
3.5作业心得:
在完成作业③的过程中,我学习了如何使用Scrapy框架来爬取网页上的表格数据,并且了解了如何将这些数据存储到MySQL数据库中。我遇到了一些挑战,比如如何处理网页中的分页和如何正确地提取表格数据。通过编写Pipeline,我学会了如何与数据库进行交互,并且理解了数据持久化的重要性。
总结
这三个作业不仅让我掌握了Scrapy框架的基本和高级用法,还让我学会了如何与数据库进行交互,以及如何将网络数据结构化存储。我学会了如何设计爬虫、处理异常、优化爬取策略,并且加深了对HTML和XPath的理解。这些技能对于我未来在数据分析、数据科学以及任何需要网络数据采集的领域的工作都是极其宝贵的。总的来说,这些作业极大地提升了我的技术能力,并为我未来的学习和职业发展打下了坚实的基础。