100tok/s生成速度,就问够不够fast?用过cursor的小伙伴一定对有个功能印象深刻,那就是fast apply功能。只要点一下,就可以把对话框中AI生成的代码快速地应用到编辑器的当前代码文件里, 然后下一步就是对比变更,accept或者reject代码块,相比于要手动从对话框复制代码到编辑器里粘贴修改,这个方式非常高效方便,是cursor的杀手锏功能.
现在可以通过vscode插件continue使用本地的小模型来实现这个功能,这个模型就是Qwen2.5-Coder-1.5b。1.5B的GGUF量化模型在我本地电脑M2 Max上通过LMStudio来跑,测试速度大约是q8_0 100 tok/s,q4_0 140 tok/s,fp16 70 tok/s,7B版本的q4_0 40 tok/s。兼顾性能和速度的话,我还是选择了1.5B的q8_0版本。
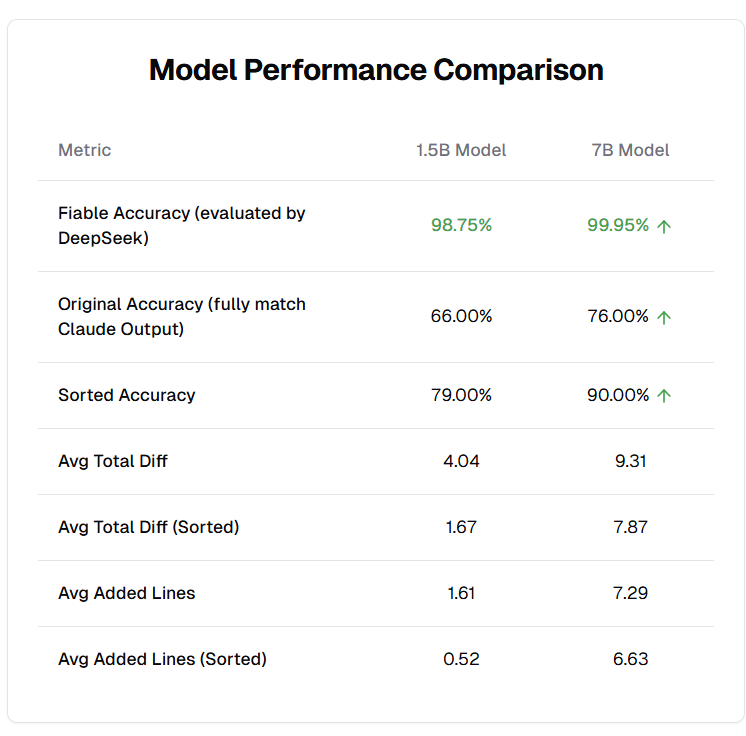
这件事起因是我看到一个专门用于fast apply的微调模型FastApply-1.5B-v1.0,是通过微调qwen2.5-coder-1.5B和7B模型实现的,专门用于代码合并fast apply功能的模型,准确率比原版有提升。
我试图把它接入到continue里,不知道continue的小伙伴可以看这个视频入门(continue开源AI代码编程助手-自定义api-SiliconFlow硅基流动与deepseek配置教程-哔哩哔哩)。可惜它的输出格式是<updated-code>[Full-complete updated file]</updated-code>,要通过修改continue源码来解析模型生成的代码,这太复杂了,我就放弃折腾,直接用原版qwen2.5-coder-1.5B好了。
经过我粗略对比,原版容易删除注释和换行空格,没有那么守规矩。微调版输出更准确,但是原版能力也不差,可以使用,200行内的简单代码合并轻轻松松,并且1.5B既能支持fast apply,也可以支持代码补全fim,一个模型两个用途,本地运行非常划算。
下面是如何配置continue:
// ~/.continue/config.json
{"models": [{"title": "fastapply-1.5b-v1.0@f16","model": "qwen2.5-coder-1.5b-instruct@q8_0","apiBase": "http://192.168.8.110:5000/v1","provider": "lmstudio","contextLength": 4000,"completionOptions": {"maxTokens": 4000,"stop": ["<|endoftext|>"],"temperature": 0.01}}],"tabAutocompleteModel": {"title": "ollama_model","provider": "lmstudio","model": "qwen2.5-coder-1.5b-instruct@q8_0","template": "qwen","apiBase": "http://192.168.8.110:5000/v1"},"modelRoles": {"applyCodeBlock": "fastapply-1.5b-v1.0@f16","inlineEdit": "fastapply-1.5b-v1.0@f16"}
}
// ~/.continue/config.ts
export function modifyConfig(config: Config): Config {const gptEditPrompt: PromptTemplate = (_, otherData) => {// 原版enclosed within <updated-code> and </updated-code> tags// system You are a coding assistant that helps merge code updates// Do not include any additional text, explanations, placeholders, ellipses, or code fences.// 为了方便兼容改成markdown格式的// enclosed within markdown \`\`\`your update code\`\`\`const systemMessage =`<|im_start|>system You are a coding assistant that helps fix code and merge code updates, ensuring every modification is fully integrated.<|im_end|>`;const userMessage =`<|im_start|>user Merge all changes from the <update> snippet into the <code> below. - Preserve the code's structure, order, comments, and indentation exactly. - Output only the updated code, enclosed within markdown \`\`\`your update code\`\`\`. - Do not include any additional text, explanations, placeholders, ellipses.`;if (otherData ? .codeToEdit ? .trim().length === 0) {return `${systemMessage}
${userMessage}
<code>${otherData.prefix}[BLANK]${otherData.suffix}</code>
<update>${otherData.userInput}</update>
Provide the complete updated code.<|im_end|>
<|im_start|>assistant `;}// const codeBlock = `${otherData.prefix}<code>${otherData.codeToEdit}$</code>{otherData.suffix}`; // 使用prefix, suffixconst codeBlock = `<code>${otherData.codeToEdit}</code>`;const updateBlock = `<update>${otherData.userInput}</update>`;return `${systemMessage}
${userMessage}
${codeBlock}
${updateBlock}
Provide the complete updated code.<|im_end|>
<|im_start|>assistant `;};let modelName = "fastapply-1.5b-v1.0@f16"// Fix the model finding logiclet applyModel = config.models.find(model => model.title === modelName);if (applyModel) {applyModel.promptTemplates = {edit: gptEditPrompt,};// console.log('done')} else {// console.warn('Model "fastapply-1.5b-v1.0@f16" not found in config.models');}return config;
}
我还向continue仓库提了一个issue,希望能兼容fastApply微调模型,欢迎跟踪进度。