本文是对公开论文的核心提炼,而非直接翻译,旨在进行学术交流。如有任何侵权问题,请及时联系号主以便删除。
来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: Can OOD Object Detectors Learn from Foundation Models?

- 论文地址:https://arxiv.org/abs/2409.05162
- 论文代码:https://github.com/CVMI-Lab/SyncOOD
创新点
- 研究并发掘在大规模开放集数据上训练的文本到图像生成模型在目标检测任务中合成
OOD对象的潜力。 - 引入一种自动化的数据整理过程以获取可控的、带注释的场景级合成
OOD图像,用于OOD目标检测。该过程利用大型语言模型(LLMs)进行新对象发现,并使用视觉基础模型进行数据注释和过滤。 - 发现在保持
ID/OOD图像上下文的一致性以及获得更准确的OOD注释边界框,对合成数据在OOD目标检测中的有效性至关重要。 - 在多个基准上的全面实验证明了该方法的有效性,在使用最少合成数据的情况下显著超越了现有的最先进方法。
内容概述
分布外(OOD)目标检测是一项具有挑战性的任务,因为缺乏开放集的OOD数据。受到近期在文本到图像生成模型方面的进展的启发,例如Stable Diffusion,论文研究了基于大规模开放集数据训练的生成模型合成OOD样本的潜力,从而增强OOD目标检测。
论文提出了SyncOOD,这是一种简单的数据策划方法。该方法利用大型基础模型的能力,从文本到图像的生成模型中自动提取有意义的OOD数据,使得模型能够访问包含在现成基础模型中的开放世界知识。合成的OOD样本随后被用于增强一个轻量级、即插即用的OOD检测器的训练,从而有效地优化了在分布内(ID)/OOD的决策边界。
在多个基准上进行的广泛实验表明,SyncOOD在性能上显著优于现有方法,凭借最少的合成数据使用,建立了新的最先进性能。
SyncOOD
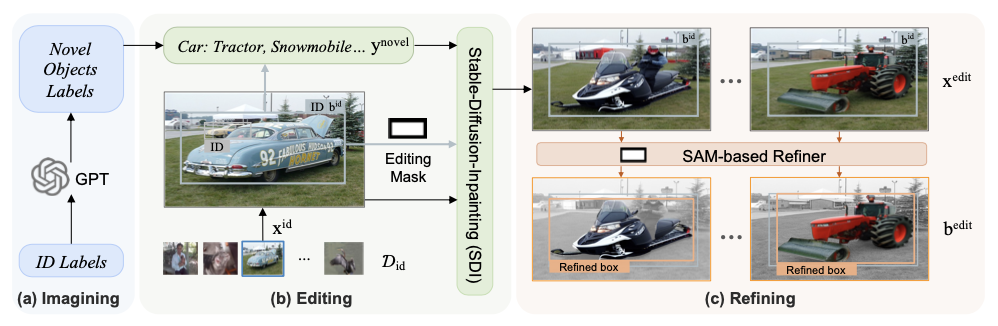
异常合成管道包括两个部分:
- 合成一组有效的照片真实感场景级
OOD图像 \(\textbf{x}^{\text{edit}}\) ,记为 \(\mathcal{D}_{\text{edit}} = \left\{(\textbf{x}^{\text{edit}}, \textbf{b}^{\text{edit}})\right\}\) ,该图像包含新颖对象及其相应的标注框 \(\textbf{b}^{\text{edit}}\) ,这一过程基于从 \(\mathcal{D}_{\text{id}}\) 进行全自动化的区域级编辑。 - 选择和使用高效的合成数据,为训练
OOD对象检测器提供伪OOD监督,与训练集中ID样本一起使用。
合成新语义对象
-
从分布内对象想象新概念对象
如图 (a) 所示,基于训练集 \(\mathcal{D}_{\text{id}}\) 中的ID标签 \(\mathcal{Y}_{\text{id}}\) ,利用大型语言模型LLM(如GPT-4)广泛的知识和推理能力来检查视觉相似度和上下文兼容性,为每个ID对象标签设想了一组新颖对象,记为 \(\mathcal{Y}_{\text{novel}}\) ,同时保持了想象对象与ID对象之间的语义可分性。这能够关联ID对象,并通过使用包含上下文示例的提示来促进可能的新对象的概念化,以替换现有的ID对象。
-
在指定区域内编辑对象
为了生成包含新概念 \(y_j \in \textbf{y}^{\text{novel}}_i\) 的新图像,选择替换现有图像中标签为 \(y_i^{\text{id}}\) 的现有ID对象,而不是寻找新的位置或从头生成图像。通过这样做,可以确保上下文兼容性,并消除场景上下文中的干扰,因为上下文得以保留。
如图 (b) 所示,使用稳定扩散修复(Stable-Diffusion-Inpainting)对ID图像进行区域级编辑,得到包含新对象的编辑图像 \(\textbf{x}^{\text{edit}}\) 为:
-
细化新对象的注释框
由于扩散模型中的随机性,编辑对象的属性,如质量、体积和定位,可能与原始对象框不匹配。为了解决这个问题,如图 (c) 所示,设计一个基于SAM的高效、有效的细化器,以获取新对象的精确边界框。
使用从 \(\textbf{b}^{\text{id}}\) 扩展出的填充区域作为提示,并使用SAM输出该区域中新对象的最高置信度实例掩码 \(\textbf{m}^{\text{SAM}}\) :
将获得的掩码 \(\textbf{m}^{\text{SAM}}\) 转换为边界框 \(\textbf{b}^{\text{SAM}}\) ,并计算 \(\textbf{b}^{\text{SAM}}\) 与相应的 \(\textbf{b}^{\text{id}}\) 之间的交并比(IoU),以过滤出在尺度上变化较大的新对象:
发掘难OOD样本以及模型训练
-
Mining Hard OOD Objects with High Visual Similarities for Training
最可能被目标检测器混淆为原始ID对象的新对象视为最有效。因此,基于预训练目标检测器的潜在空间中的成对相似性,寻找最容易被混淆为ID的合成OOD样本。
对于一个现成的目标检测器 \(\mathcal{F}_\text{det}\) ,为每一对提取潜在特征 \(\textbf{z}^{\text{edit}}\) 和 \(\textbf{z}^{\text{id}}\) ,根据相似性进行过滤,以提供伪OOD监督:
-
通过合成样本优化
ID/OOD决策边界
一旦获得了ID和合成OOD对象,使用一个轻量级的多层感知器(MLP) \(\mathcal{F}_\text{ood}\) ,作为经过二分类损失优化的OOD检测器参与训练:
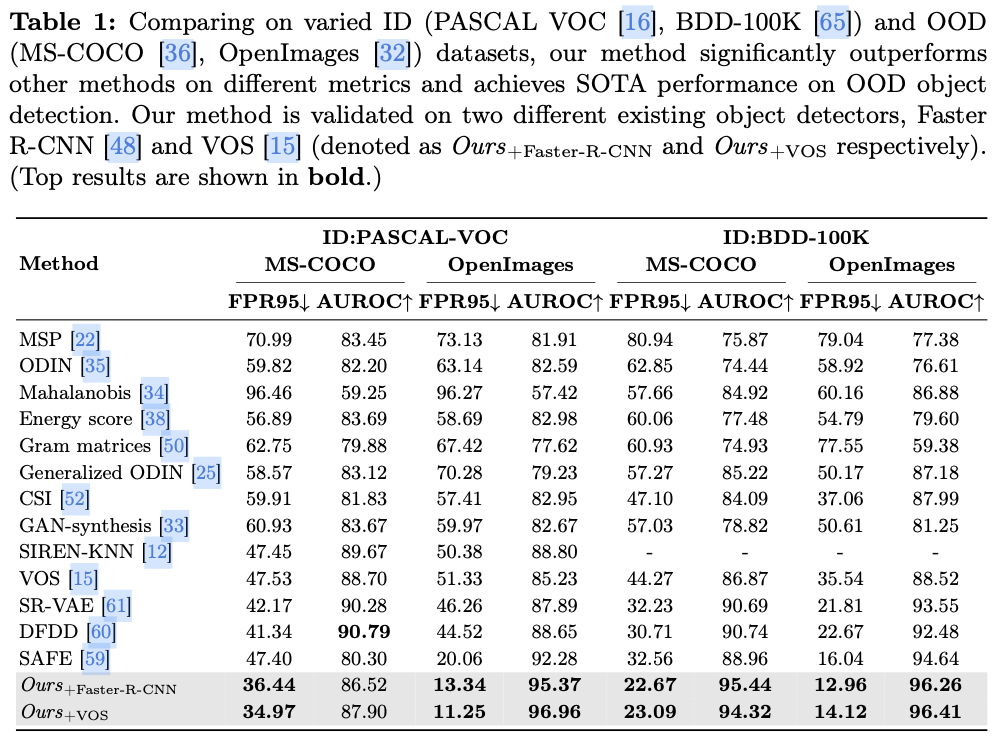
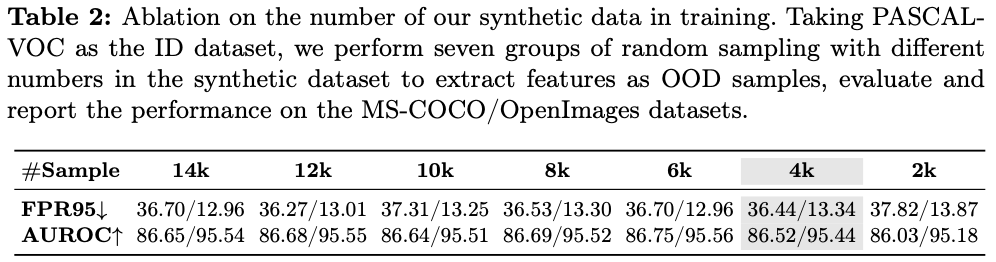
主要实验

如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】