一、写作目的:(全文字数4926,阅读大约需25min)
首先,我有一个相关的需求要做,然后在拜读了网络上各大UE4序列化解析的文章后,发现大都讲的很模糊,对新入序列化大门的小白非常不友好。有的直接贴上一大段代码(好似直接糊脸上的不解释连招),也有的讲着讲着嘎然而止,也有的总是讲一些空洞的理论而没有实际的用处,让人看完文章后不知其所指。这些种种可能是由于ue序列化缺少官方文章,源码读起来也比较拗口,所以今天我就来抛砖引玉,以二进制分析为主+ue序列化源码阅读为辅写一篇从入门到精通的连载文章。这第一篇,我们以科普为主,小需求为辅,简单的聊一聊题目中描述的ue资产序列化是干什么?以及我这篇文章在说什么?
注:本文不会粘贴太多引擎源码,但会告知你源码所在位置,之所以这么做的原因有二,其一,大量粘贴ue引擎源码会拉长文章,让阅读不连续、其二,ue4引擎序列化源码在各个版本的细枝末节不尽相同,本文只是抛砖引玉,如果你要了解你所使用的ue引擎的序列化源码,还需自己去下点功夫。
二、需求:
没有需求空讲理论,我觉得这就有点八股文的味道了,如果只是为了背八股文,我觉得没必要入序列化这个坑...因为ue自身序列化一般人改不动也没必要改。只有对于一些特定的项目有这种需求才会去弄,而且大多数情况下对ue资源的操作可以直接通过commandlet使用LoadObject去完成资源序列化加载,然后再像在ue中使用UObject一样去进行二次加工就行了。
但如果你偏偏就是想学ue资产序列化又或者想去定制化优化项目引擎的序列化代码,了解其中的方方面面,那倒是可以多读文章多调源码去入坑了。
现在,我们第一个虚拟的需求是“从一个ue资产(uasset/uexp)中定位某个特定UObject的使用情况”,从需求出发,慢慢地浅析ue序列化的源码吧!
三、基础知识:
虽然我上面说不支持空讲理论,但我同时也要考虑到一个小白读这篇文章时可能会什么都不懂的情况,所以我这里以极短的篇幅先浅述一下相关的一些基础知识。如果你对以下标题十分熟悉了建议跳过
一些二进制常识
....
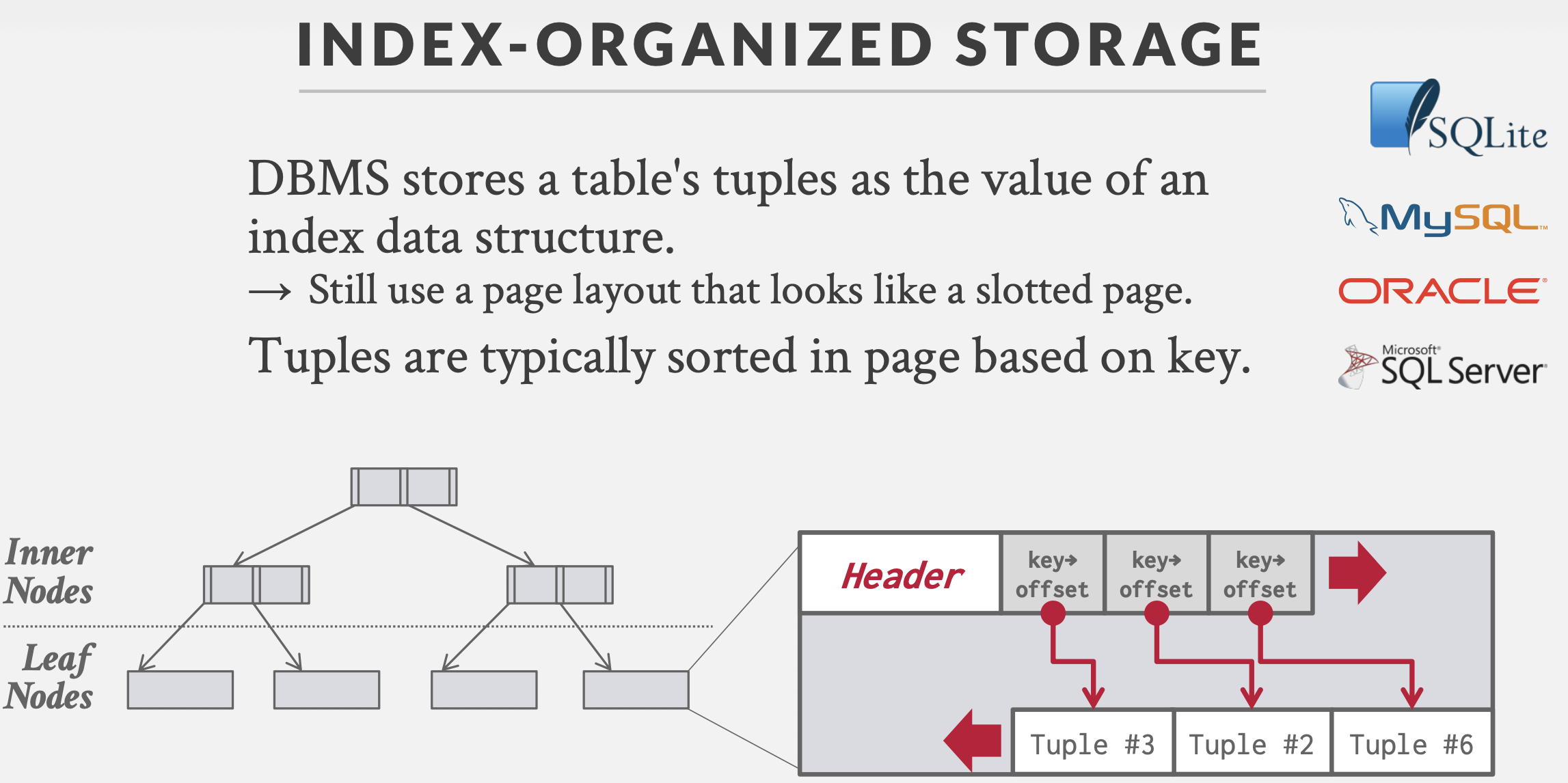
ue资产是什么?
ue资产通常指以.uasset/uexp/ubulk结尾的资源文件,我们在ue引擎中使用的一个个蓝图往往就对应着一个uasset。如ue自带的FPSdemo,其中的ContentBrowser就对应着项目路径下Content文件夹,其中的蓝图资产与uasset文件是一一对应的。说通俗点,在蓝图中的是ue资产的数据可视化形态,在磁盘中的是其二进制的数据形态,我们下面要做的反序列化就是将其二进制形态的数据加载成数据可视化的形态,而反序列化的过程即将可视化形态数据保存成二进制数据。
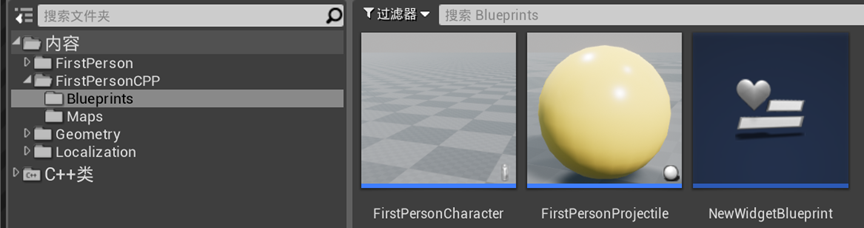
uexp/ubulk又是什么?
如果你不接触打包的话可能不会接触太多uexp/ubulk,但是今天我们既然说到ue资产那就不可避免地要想你介绍一下了,uexp即ue引擎在烘培了上述ue原始uasset资产后,将文件头之后的数据段剥离而形成的,可以说,uexp就是uasset的数据段,而烘培后的uasset则只剩下文件头了,但具体划分还需要从实际出发,因为当数据段过少或某些特定场景时,烘培后也不会产生uexp。在使用时就很简单了,如果uasset存在对应的uexp,则只需要将其读取后放在uasset后面,ue中也确实是这样做的,如果需要读取在uexp中的某个数据,那他在uexp中的offset偏移则可以通过offset - uasset.size得到。而ubulk又不同了,ubulk看名字就知道是存大数据的,当数据段过大时它就会产生(具体的阈值依设置而定),其应用场景一般为高分辨率纹理、高质量声音或其他大型数据时使用。
拆分成uexp/ubulk的好处?
通俗的讲,就是ue引擎为了减少数据的大量同时加载为我们做的优化,具体原因分为:
1.提升加载性能:初始化时只需加载元数据,减少游戏启动或关卡初始化时间。
2.内存优化:元数据和资源数据分开加载,大内存占用减小,且减少内存浪费。
3.灵活性和可扩展性:针对平台做出优化,特定资源更新只需修改uexp。
4.减少打包和传输大小:uexp单独可压缩,减少包体积,资源文件按需下载。
5.文件管理和维护:可以单独更新资源数据而不影响元数据。
什么是序列化?什么又是反序列化?
通俗的讲,序列化就是将结构分明的数据转成紧密相连的二进制,而反序列化就是将紧密相连的二进制数据转换成结构分明的数据。在网络上有一篇将序列化举例为切豆腐的文章,我觉得有点不太合适。
相信大家小时候都看过葫芦娃吧,我觉得拿这个举例是非常了然的,在动画中有一幕,七个葫芦娃合体形成了一座七彩葫芦山,而妖精们将这山一块块切割,然后每一块就变成了一个个葫芦娃。。。

可以毫不夸张的说,葫芦娃合体成一座山就是序列化的过程,将层次分明的数据挤成一块,然后存入磁盘中。而妖精们将其分块切割然后变成一个葫芦娃的过程就是反序列化的过程,将紧密相连的数据取其一段,然后将其赋予某些特征,最后全部的二进制数据都被拆分成一个个结构分明的数据即完成了反序列化。
ue中的序列化
序列化跟反序列化一直是左右手的存在,在ue中更是如此,你可以在阅读后面的文章中发现,我往往只需要分析一边,那另一边的也能知道个七七八八(如同人的左右手,在大体上是对称的,但细节的纹路又有所区别),这是因为ue序列化本身也是使用的访问者模式去完成序列化,序列化和反序列化都是通过FArchive的一个<<接口去实现的,其源码上区别也就是那一些细节罢了。
FArchive
关于FArchive,别的文章已经讲述得很详细了,本文就不再赘述,简单理解就是一个将二进制数据读取写入内存的工具,帮助我们加载or写入一定数量的比特。具体解读可以去看“UE4对象系统_序列化和uasset文件格式的前半部分”
ue文件结构
如果要如庖丁解牛般去解析一个ue资产,那我们首先得知道其各成分是什么,这里直接给出,
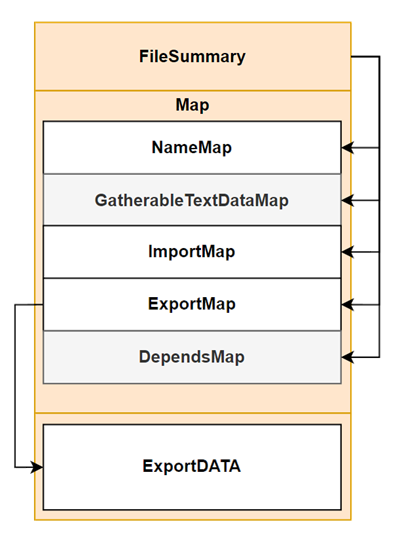
至于我为什么这么画(mach-o文件结构描述图/elf运行视图)而不那么画(elf文件结构链接视图),那是我认为ue的文件结构如同mach-o,是一种承上启下,一层一层的。为什么说是承上启下一层一层的呢?如同我图中箭头所指,我们是首先读取了FileSummary,然后通过FileSummary去定位各项Map,然后在通过ExportMap去解析data段中的各种export(也即OBject),所以这是一种顺序解析的文件结构,而我们的解析之旅也将根据这个流程来进行。
四、二进制分析+源码解析
ue资源解析源码定位
ue4资源解析的源码位于\UObjcet\LinkerLoad.cpp中,在这里你将见到我上述说的文件头各部分解析源码(FileSummary+Map)
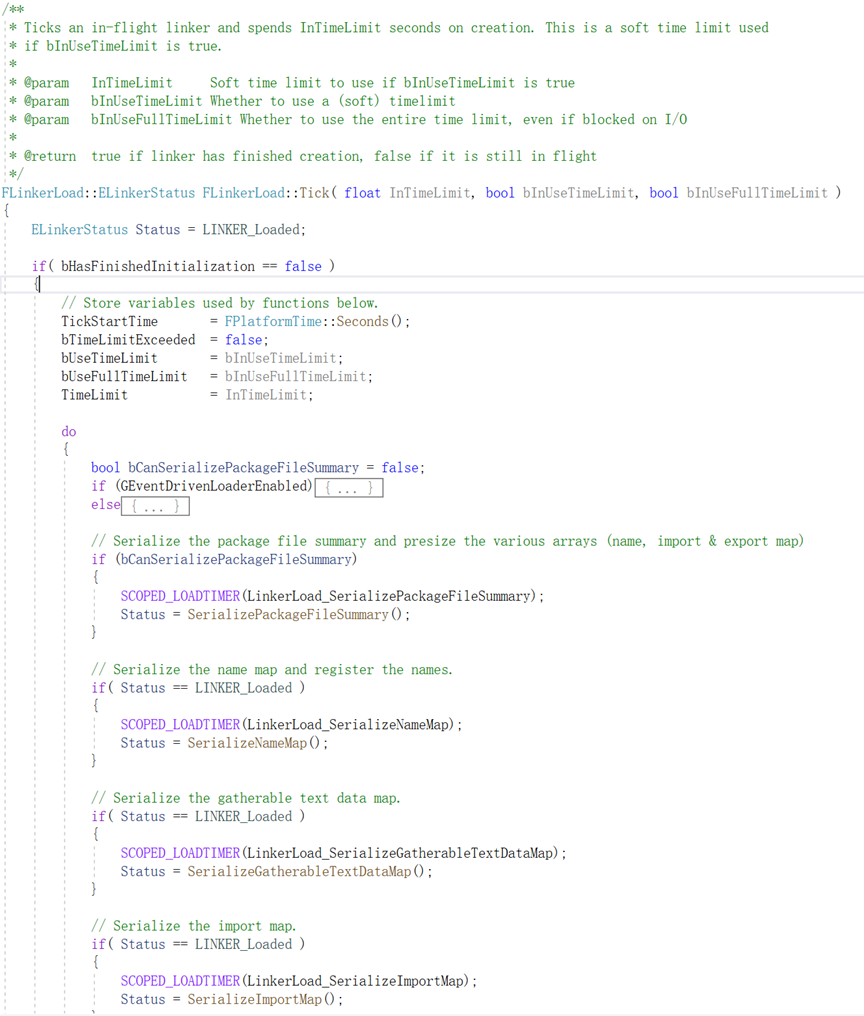
FileSummary
我们打开一个uasset或者阅读,首当其冲的就是FileSummary,FileSummary是什么呢?如上图所述,他是我们处理后续数据的指引,其具体包含的数据如下图所示(在FileSummary序列化读取源码中即获取了一个该类型的结构体),具体的源码在FLinkLoad.h的SerializePackageFileSummary()中

然后让我们依次来介绍一下其是什么吧!(主要的地方我尽可能详细解读)
Tag
Tag,ue中给其的名称,在其他文件系统中叫magic number,是该文件类型的名称,等同于文件后缀,不过这是给计算机读的,意味着只要读取了前四位数据那我们就知道这是否是一个uasset(uexp是uasset的副产品,其二进制数据不包含文件类型信息等),其具体的校验源码如下图所示

这里的两个TAG定义其实都是0x9E2A83C1,不过一个是LE一个是BE,所以我们读到这里也不难发现,ue正是通过这个Tag来获取其后续数据的大小端读取方式的(这里为什么叫Tag不叫Magic,因为它不仅是类型标识,更是一种大小端的标识),我们打开一个uasset的二进制文件发现也确实如此(后续我们也将通过二进制分析的方式来检验我们源码理解的正确性)
Version
一个文件版本、三个ue引擎版本、和一个自定义版本信息容器,除了第一个其余的往往无多大用处,因为你随便打开一个烘培好的文件会发现其全是0...,因为我们往往会采用与版本无关的方式去分发数据资产。
而第一个文件版本信息则是告诉我们这个ue资产文件是什么版本的以让我们正确的解析它。其源码的注释如下(ue5即为-8)

我使用的是ue4,所以这里也理所当然的是-7即0xF9FFFFFF(LE)

除了ue自带的版本信息,还给我们预留了一些自定义版本信息,这个就需要有一定的深入才能知道其用处了,所以这里先暂时不讲,但其读取方式可以讲一下,以便各位能从二进制的角度理解它
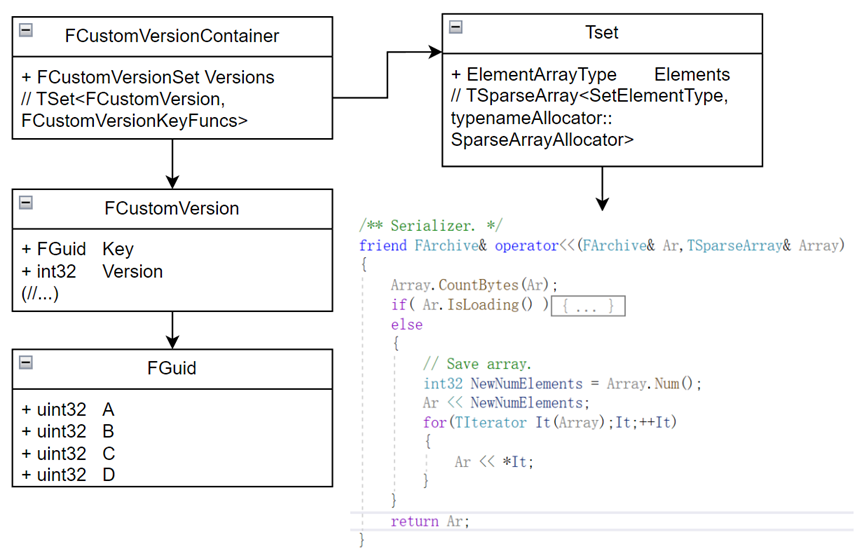
FCVC即FCustomVersionContainer,是使用ue自己的Tset容器保存的FCustomVersion信息,而单个FCustomVersion又包括1个FGuid的Key和一个int32位的Version,一个FGuid包含四个uint32的数值。而TSet的序列化方式也如上图所述(底层通过Array保存),在保存一个Num后,保存各个成员信息。了解了这些之后也不难解读了,即uasset文件的第21-24个比特信息会告述你有多少个FCustomVersion,而一个FCustomVersion又将占用5个四字节的int32(比如说我这里的是4个0即没有FCVC)。至此,版本信息就被我们读取完了。
TotalHeaderSize
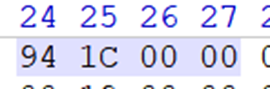
听名字也能知道,这就是文件头的总大小,如我这里的0x941C0000就刚好是.uasset的大小,同时这也证明我这是一个烘培后拆分了文件头(uasset)与数据段(uexp)的ue4资源。如未拆分,我们将通过这个大小获取文件头的范围。

FolderName
此包所在的Generic Browser文件夹名称(FString类型的文件名),在很多场景下,其为None值,而FString类型在ue的序列化中也很简单,先存储int32的字符串长度,再存储字符串本身,在我的例子中即长度为5的”None\0”(ue中字符串的存储方式同C风格字符串以\0结尾,中文字符串又有所不同,带中文的字符串将以Unicode编码(具体为UTF-16),采用宽字节进行存储,即英文/中文都采用两个字节为一个单位表示)

PackageFlags
uint32的包体标签数据,告知我们解包时包体的具体类型,如我这里的0x00000480即可表示一个Developer modulePackage,具体定义在UObject\ObjectMacros.h的enum EPackageFlags中

NameCount和NameOffset
随后的两个int32数据即NameMap的关键信息了,它将告知我们NameMap中具体的Name数量以及起始偏移位置,如我的测试uasset中即有115个Name,其起始偏移为193

GatherableTextDataCount和GatherableTextDataOffset
随后的两个int32数据即GatherableTextData的数量和起始偏移
ExportCount和ExportOffset
随后的两个int32数据即ExportMap中Export的数量和起始偏移
ImportCount和ImportOffset
随后的两个int32数据即ImportMap中Import的数量和起始偏移
DependsOffset
Preload Dependencies的起始偏移
...(一些额外的头部描述信息)
NameMap
在获取了上述FileSummary信息之后,我们就可以继续解析后续的资源信息了,第一个我们需要解读的即NameMap,NameMap是什么呢?我觉得可以将它比作elf/mach-o中的符号表,即该文件内部的一些名称信息的集合,具体来说它包括文件名、文件路径、类名、函数名、变量名...,其在ue中对应的具体数据类型为FName,对于系统中自己使用的FName类型数据和使用者去定义的一些FName类型数据(不管是默认值还是操作赋值),都将存在于FNameMap中,然后其在uasset/uexp文件中具体的使用处则通过索引NameMap的方式来获取其需要的FName数据。
具体地,其序列化源码位于UObject\LinkerLoad.cpp文件中
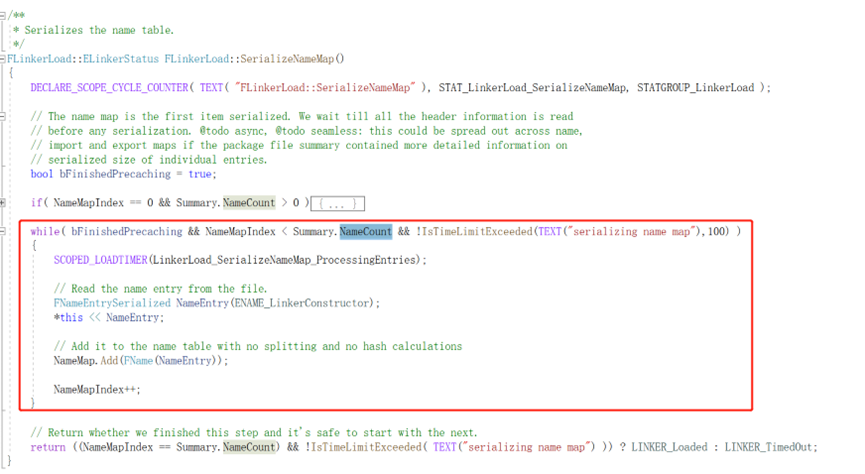
可以看到,其具体的做法即序列化了NameCount个NameEntry,具体的FNameEntrySerialized序列化源码如下图所示,其本质做法即获取FName的String类型表达,然后序列化这个FString的数据,具体的展开就不一一赘述了(FString类型的数据序列化即通过先存一个int32的长度len,然后是len个比特的实际数据)
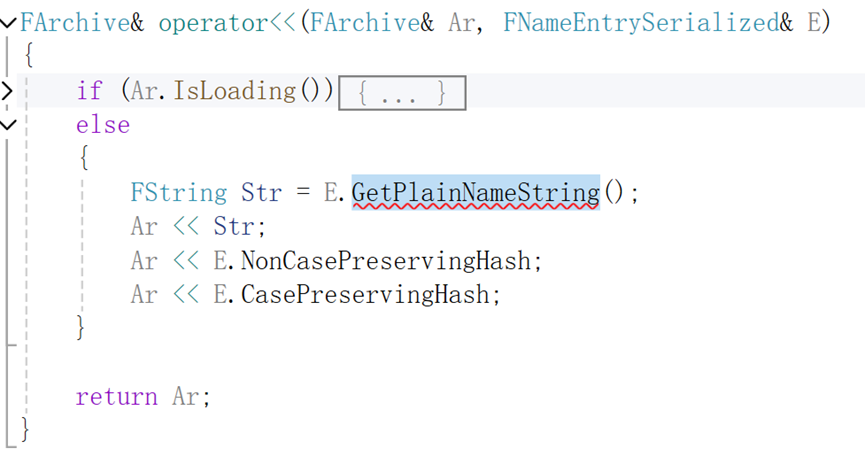
最后加上两个uint 16的Hash值,具体的NameHash计算位于UObject\UnrealNames.cpp文件下的FNameEntrySerialized()函数中,其本质即通过一些位运算操作使得字符串获取一个大小写无关一个大小写有关的Hash值用于Name间进行比较。
现在我们序列化完成了一个FNameEntry,而我们加载FName的过程即加载多个FNameEntry,让我们来对照二进制数据看一看吧!(通过使用上文FileSummary中的NameCo...部分已获取NameMap的偏移和数量)

可以看到从偏移193处,先是读取了一个int32的len 0x33000000,对应的字符串长度为51,随后是51字节的字符串数据,最后跟了两个uint16的比较hash值,然后重复这个步骤不断读取便解析了NameMap数据
ImportMap
导入表,包含一些需要从外部导入的信息,序列化ImportMap的源码也同样位于UObject\LinkerLoad.cpp下
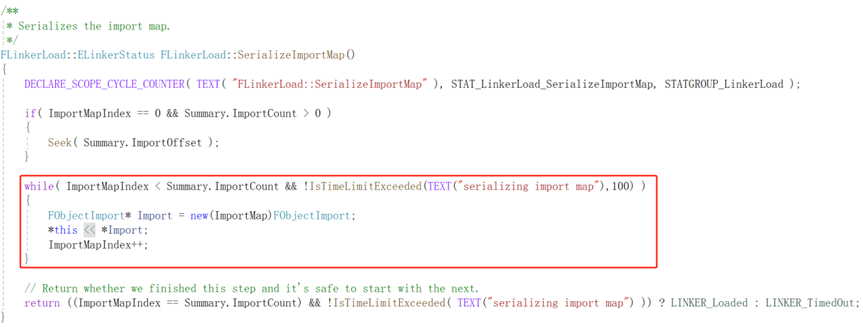
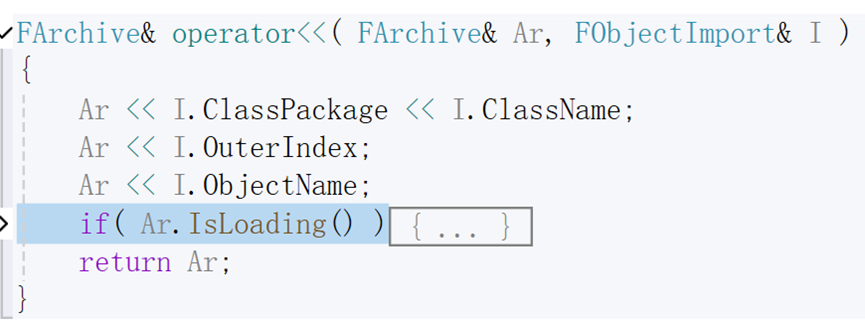
通过阅读FObjectImport的源码,我们可以很清晰的知道其内部即存储了三个FName数据ClassPackage、ClassName、ObjectName和一个FPackageIndex数据OuterIndex(实际为int32类型),
ExportMap
导出表,描述可以从该ue资产文件导出的一些数据信息,与elf文件结构不同,ue中不管外部是否使用的数据,都将存储在ExportMap中,可以这样理解,Export即是该ue文件的数据,我们在蓝图中定义的所有东西(不管是UI还是事件蓝图,亦或者音频材质资源),最后都是体现在Export上,所以Export的解析尤为重要。
其源码同样位于LinkLoad.cpp文件中,其内部参数过多,这里就不一一赘述了,感兴趣的读者可以自己去怼源码。
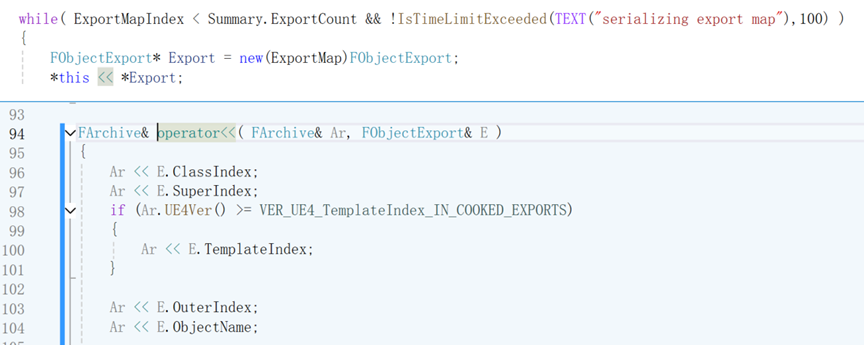
其一个FObjectExport内主要的序列化相关数据如下图所示

这里主要的关键信息有4个,分别为ClassIndex、ObjectName、SerialSize、SerialOffset:
ClassIndex,类型下标,当它<0时,其是一个外部导入的类型,ImportIndex = -ClassIndex - 1,通过计算ImportIndex,即可在ImportMap中根据下标定位到具体的Import(该export的描述信息),当它>0是,其是一个内部定义类型。
当它=0时,此导出类对象没有资源。
ObjectName,为此资源表示的UObject的名称,该处仅存储索引,具体读取方式如下图。

SerialSize、SerialOffset即该export资源在本文件中占用的数据块大小以及偏移。
我们通过该偏移和大小可以找到该资源实际的数据区块,然后根据上述ClasIndex描述的类型信息进行解读数据区块即可完成该类export资源的加载。
...
五、需求实现
现在,我们已经完成了对uasset(即文件头)的解析工作,若我们想要在一个ue资源中寻找某一个Object的使用情况,那我们则可以通过”解析FileSummary->定位解析NameMap->定位解析ImportMap->定位解析ExportMap->循环遍历ExportMap,获取其每一个Export的类型和名称->统计特定OObject的使用情况”