【神经网络组件】Transformer Encoder
- 【神经网络组件】Transformer Encoder
- 1. seq2seq模型
- 2. 为什么只需要Transformer Encoder
- 3. Transformer Encoder的结构
1. seq2seq模型
-
什么是sequence:sequence指由多个向量组成的序列。例如,有三个向量:\(\mathbf{a} = [1,0,0]^T,\mathbf{b} = [0,1,0]^T,\mathbf{c} = [0,0,1]^T\),那么\([\mathbf{a},\mathbf{b},\mathbf{c}]\)构成一个sequence。
-
什么是seq2seq模型:
- seq2seq并不单指哪一个模型,而是一类模型的总称。Transformer就是seq2seq中的一种,也是最出名的一种。
- seq2seq有以下特点:它的输入是一个sequence,输出也是一个sequence,且输出sequence的长度不能事先确定,需要模型自主学习。
例如,机器翻译模型一般都是seq2seq模型。
如果想要把一段中文翻译成英文,那么模型的输入是中文,其中每个汉字可以表示成一个向量,这段中文可以表示成一个由向量组成的sequence。
输出是中文对应的英文,其中每个单词是一个向量,因此输出也可以表示成一个sequence。但是,输出sequence的长度不能确定,因为不能事先知道翻译过来的英文包含多少单词。
-
seq2seq的通用结构:Encoder-Decoder结构。Encoder处理输入sequence,把处理好的结果丢给Decoder,由Decoder生成输出sequence。
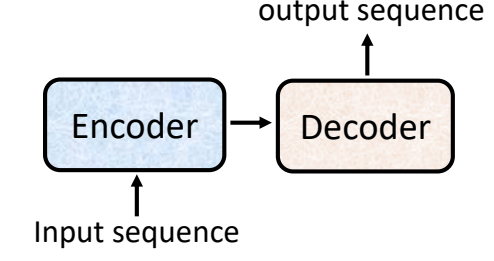
Transformer也是seq2seq模型,因此,Transformer中也分为Encoder和Decoder两部分。
2. 为什么只需要Transformer Encoder
对于Transformer中的Encoder和Decoder,可以这样理解它们各自的功能:Encoder负责对输入数据进行编码,Decoder根据编码后的数据生成新的序列。
在一些场景中,只需要对输入进行编码,不需要生成新的序列,也就是说,只会用到Transformer Encoder,不会用到Transformer Decoder。例如,情感分析,主题分类,垃圾邮件检测等文本分类任务;词性标注,命名实体识别等序列标注任务;以及在BERT中,都只会用到Transformer Encoder,而不会用到Transformer Decoder。
3. Transformer Encoder的结构
如果把Transformer Encoder看作一个黑盒,那么其输入是一个sequence,输出也是一个sequence,且输入sequence和输出sequence等长。
Encoder的内部是什么样的呢?
Encoder是由很多block连接在一起的。如果把每个block看作一个黑盒,那么每个block的输入是一个sequence,输出是同样长度的sequence。
block的内部是什么样的呢?
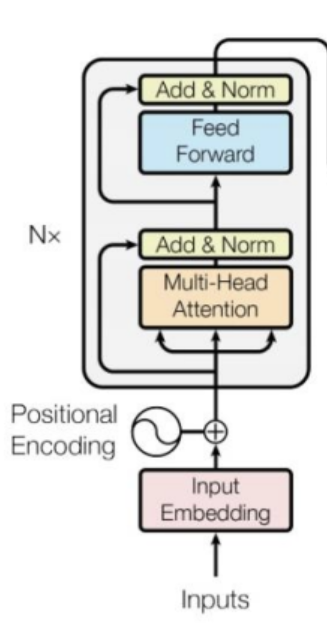
每个block的结构如下图。
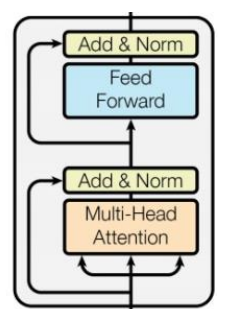
可以看到,block的结构大概分为两块,第一块是Multi-Head Attention和Add&Norm;第二块是Feed Forward 和Add&Norm。下面对这两块逐一讲解。
Multi-Head Attention和Add&Norm:
-
Multi-Head Attention表示多头自注意力层。
-
Add&Norm:
-
Add表示残差
-
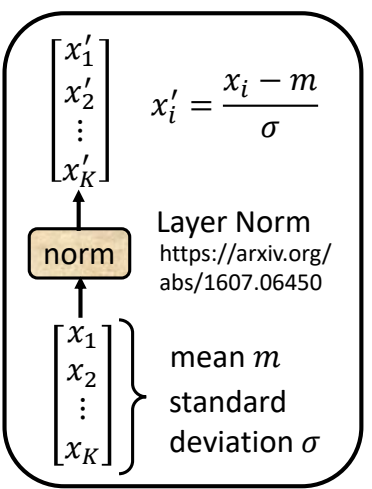
Norm表示lay normalization:计算sequence中,一个输入向量所有维度的均值和方差,对这个输入向量做归一化。例如,输入向量是$\mathbf{x} =[x_1,x_2,\cdots,x_K] \(,计算均值\)m = \sum_{i=1}^K x_i/K\(,方差\)\sigma = \sum_{i=1}K(x_i-m)2/K\(。对于\)\mathbf{x}\(中的元素\)x_i\(,经过layer norm的输出\)x_i'\(可以表示为\)x_i' = \frac{x_i-m}{\sigma}$
-
因此,block中这一块的结构可以表示下面的形式
Feed Forward 和Add&Norm:
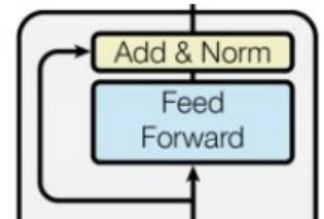
这一块和上一块很像,因此不展开讲解。
- Feed Forward :全连接层。
- Add&Norm:残差+layer normalization
其结构可以表示下面的形式
Transformer Encoder的完整结构:
在Transformer中,为了更好的利用位置信息,还要加上位置编码。
因此,Transformer Encoder的完整结构如下图。