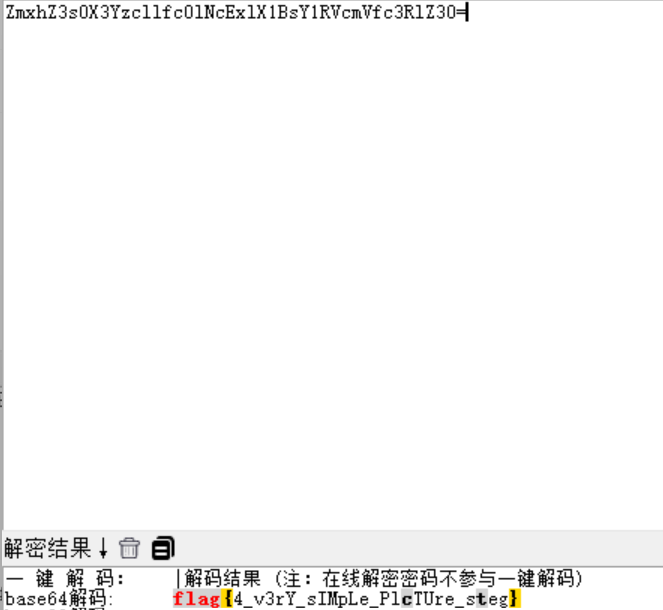
1.用法 vmstat [-a] [-n] [-S unit] [delay [ count]] vmstat [-s] [-n] [-S unit] vmstat [-m] [-n] [delay [ count]] vmstat [-d] [-n] [delay [ count]] vmstat [-p disk partition] [-n] [delay [ count]] vmstat [-f] vmstat [-V]
-a:显示活跃和非活跃内存
-f:显示从系统启动至今的 fork 数量 。
-m:显示 slabinfo
-n:只在开始时显示一次各字段名称。
-s:显示内存相关统计信息及多种系统活动数量。
delay:刷新时间间隔。如果不指定,只显示一条结果。
count:刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷。
-d:显示磁盘相关统计信息。
-p:显示指定磁盘分区统计信息
-S:使用指定单位显示。参数有 k 、K 、m 、M ,分别代表 1000、1024、1000000、1048576 字节(byte)。 默认单位为 K(1024 bytes)
-V:显示 vmstat 版本信息。
例子:
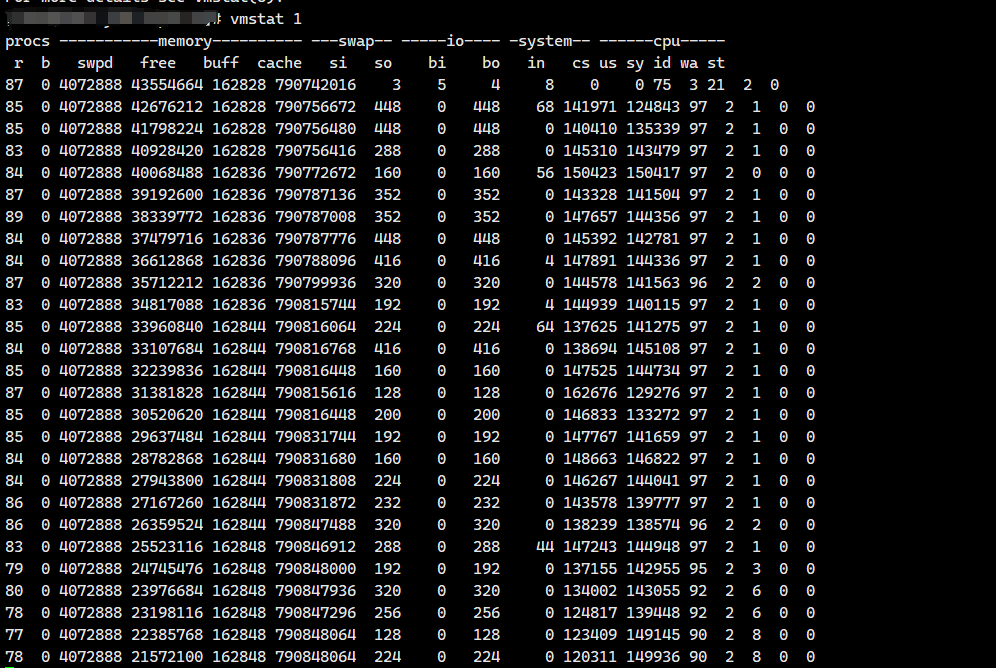
字段说明: Procs(进程):
r: 运行的和等待(CPU 时间片)运行的进程数,这个值也可以判断是否需要增加 CPU(长期大于 1) b: 等待 IO 的进程数量,处于不可中断状态的进程数,常见的情况是由 IO 引起的
Memory(内存):
swpd: 使用虚拟内存大小,切换到交换内存上的内存(默认以 KB 为单位)
如果 swpd 的值不为 0,或者还比较大,比如超过 100M 了,但是 si, so 的值长期为 0,这种情况我 们可以不用担心,不会影响系统性能。 free: 空闲的物理内存 buff: 用作缓冲的内存大小 cache: 用作缓存的内存大小,文件系统的 cache,如果 cache 的值大的时候,说明 cache 住的文件数 多,如果频繁访问到的文件都能被 cache 住,那么磁盘的读 IO bi 会非常小
Swap:
si: 每秒从交换区写到内存的大小,交换内存使用,由磁盘调入内存 so: 每秒写入交换区的内存大小,交换内存使用,由内存调入磁盘
内存够用的时候,这 2 个值都是 0,如果这 2 个值长期大于 0 时,系统性能会受到影响。磁盘 IO 和
CPU 资源都会被消耗。
常有人看到空闲内存(free)很少或接近于 0 时,就认为内存不够用了,实际上不能光看这一点的,还 要结合 si,so,如果 free 很少,但是 si,so 也很少(大多时候是 0),那么不用担心,系统性能这时不会受 到影响的。
IO:(现在的 Linux 版本块的大小为 1024bytes)
bi: 每秒读取的块数,从块设备读入的数据总量(读磁盘) (KB/s) bo: 每秒写入的块数,写入到块设备的数据总理(写磁盘) (KB/s)
随机磁盘读写的时候,这 2 个值越大(如超出 1M),能看到 CPU 在 IO 等待的值也会越大
system:
in: 每秒中断数,包括时钟中断。 cs: 每秒上下文切换数。
上面这 2 个值越大,会看到由内核消耗的 CPU 时间会越多 CPU(以百分比表示):
us: 用户进程消耗的 CPU 时间百分比,us 的值比较高时,说明用户进程消耗的 CPU 时间多,但是如 果长期超过 50% 的使用,那么我们就该考虑优化程序算法或者进行加速了 sy: 内核进程消耗的 CPU 时间百分比,sy 的值高时,说明系统内核消耗的 CPU 资源多,这并不是良 性的表现,我们应该检查原因。 id: CPU 处在空闲状态时间百分比(包括 IO 等待时间) wa: IO 等待消耗的 CPU 时间百分比,wa 的值高时,说明 IO 等待比较严重,这可能是由于磁盘大量 作随机访问造成,也有可能是磁盘的带宽出现瓶颈(块操作)。
显示活跃和非活跃内存
使用-a 选项显示活跃和非活跃内存时,所显示的内容除增加 inact 和 active 外,其他显示内容与例子 1
相同。
字段说明: Memory(内存):
inact: 非活跃内存大小(当使用-a 选项时显示) active: 活跃的内存大小(当使用-a 选项时显示)
注:如果 r 经常大于 4,且 id 经常少于 40,表示 cpu 的负荷很重,如果 bi,bo 长期不等于 0,表示内 存不足,如果 disk 经常不等于 0,且在 b 中的队列大于 3,表示 io 性能不好。
CPU 问题现象: 1.)如果在processes中运行的序列(process r)是连续的大于在系统中的CPU的个数表示系统现在运行比较 慢,有多数的进程等待 CPU. 2.)如果 r 的输出数大于系统中可用 CPU 个数的 4 倍的话,则系统面临着 CPU 短缺的问题,或者是 CPU 的速 率过低,系统中有多数的进程在等待 CPU,造成系统中进程运行过慢. 3.)如果空闲时间(cpu id)持续为 0 并且系统时间(cpu sy)是用户时间的两倍(cpu us)系统则面临着 CPU 资源 的短缺.
解决办法:
当发生以上问题的时候请先调整应用程序对 CPU 的占用情况.使得应用程序能够更有效的使用 CPU.同 时可以考虑增加更多的 CPU. 关于 CPU 的使用情况还可以结合 mpstat, ps aux top prstat –a 等 等一些相应的命令来综合考虑关于具体的CPU的使用情况,和那些进程在占用大量的CPU时间.一般情 况下,应用程序的问题会比较大一些.比如一些 SQL 语句不合理等等都会造成这样的现象.
内存问题现象:
内存的瓶颈是由 scan rate (sr)来决定的.scan rate 是通过每秒的始终算法来进行页扫描的.如果 scan rate(sr)连续的大于每秒 200 页则表示可能存在内存缺陷.同样的如果 page 项中的 pi 和 po 这两栏表示每 秒页面的调入的页数和每秒调出的页数.如果该值经常为非零值,也有可能存在内存的瓶颈,当然,如果个 别的时候不为 0 的话,属于正常的页面调度这个是虚拟内存的主要原理.
解决办法: 1.调节 applications & servers 使得对内存和 cache 的使用更加有效. 2.增加系统的内存. 3. Implement priority paging in s in pre solaris 8 versions by adding line "set priority paging=1" in /etc/system. Remove this line if upgrading from Solaris 7 to 8 & retaining old /etc/system file.
关于内存的使用情况还可以结 ps aux top prstat –a 等等一些相应的命令来综合考虑关于具体的内 存的使用情况,和那些进程在占用大量的内存.一般情况下,如果内存的占用率比较高,但是,CPU 的占用 很低的时候,可以考虑是有很多的应用程序占用了内存没有释放,但是,并没有占用 CPU 时间,可以考虑 应用程序,对于未占用 CPU 时间和一些后台的程序,释放内存的占用