1.lambda方式查询
在使用Mybatis-plus进行查询时,我们正常的操作是创建一个QueryWrapper,然后根据字段去做查询操作(如下图)
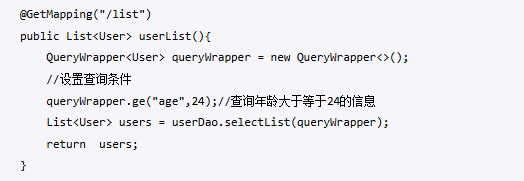
那么就有一个问题,每个数据库的字段都需要写出来,遇到驼峰字段还需要转换为下划线形式,非常影响开发效率。而官方也考虑到这个问题,后续的版本已经提供了lambda的方式,直接使用对象属性方式

这种方式是不是非常舒服,开发效率不就提起来了吗
2.持久层接口IService
IService是MyBatis-Plus 提供的一个通用 Service 层接口,它封装了常见的 CRUD 操作,包括插入、删除、查询和分页等。通过继承 IService 接口,可以快速实现对数据库的基本操作,同时保持代码的简洁性和可维护性。
简单来说,就是其内部封装了一系列常用的方法,可以减少代码的冗余,那如何去使用呢?其实很简单,只需要在service接口继承 IService即可
package com.zxh.service;import com.baomidou.mybatisplus.extension.service.IService; import com.zxh.entity.User;public interface UserService extends IService<User> {}
于此同时,此接口的实现类也需要继承IServiceImpl
package com.zxh.service.impl;import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl; import com.zxh.dao.UserDao; import com.zxh.entity.User; import com.zxh.service.UserService; import org.springframework.stereotype.Service;@Service public class UserServiceImpl extends ServiceImpl<UserDao, User> implements UserService { }
此时就可以直接使用service的通用方法(这里直接以官网案例说明)
2.1保存save
// 插入一条记录(选择字段,策略插入) boolean save(T entity); // 插入(批量) boolean saveBatch(Collection<T> entityList); // 插入(批量) boolean saveBatch(Collection<T> entityList, int batchSize);
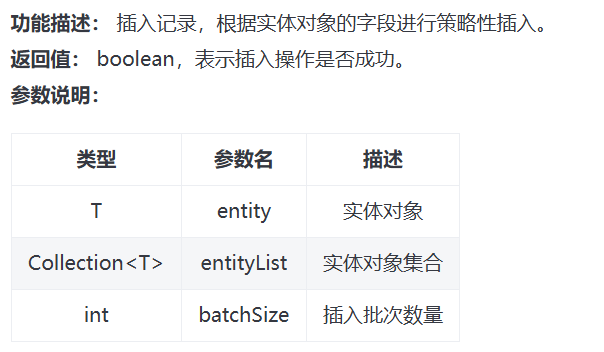
示例(save):
User user = new User(); user.setName("John Doe"); user.setEmail("john.doe@example.com"); boolean result = userService.save(user); if (result) {System.out.println("User saved successfully."); } else {System.out.println("Failed to save user."); }
生成的 SQL:
INSERT INTO user (name, email) VALUES ('John Doe', 'john.doe@example.com')
示例(saveBatch):
List<User> users = Arrays.asList(new User("Alice", "alice@example.com"),new User("Bob", "bob@example.com"),new User("Charlie", "charlie@example.com") ); // 使用默认批次大小进行批量插入,默认是1000 boolean result = userService.saveBatch(users); if (result) {System.out.println("Users saved successfully."); } else {System.out.println("Failed to save users."); }
生成的 SQL:
INSERT INTO user (name, email) VALUES ('Alice', 'alice@example.com'), ('Bob', 'bob@example.com'), ('Charlie', 'charlie@example.com')
示例(saveBatch 指定批次大小):
List<User> users = Arrays.asList(new User("David", "david@example.com"),new User("Eve", "eve@example.com"),new User("Frank", "frank@example.com"),new User("Grace", "grace@example.com") ); // 指定批次大小为 2进行批量插入 boolean result = userService.saveBatch(users, 2); if (result) {System.out.println("Users saved successfully."); } else {System.out.println("Failed to save users."); }
生成的 SQL(指定批次大小为 2):
-- 第一批次 INSERT INTO user (name, email) VALUES ('David', 'david@example.com'), ('Eve', 'eve@example.com')-- 第二批次 INSERT INTO user (name, email) VALUES ('Frank', 'frank@example.com'), ('Grace', 'grace@example.com')
2.2保存或修改saveOrUpdate
// TableId 注解属性值存在则更新记录,否插入一条记录 boolean saveOrUpdate(T entity); // 根据updateWrapper尝试更新,否继续执行saveOrUpdate(T)方法 boolean saveOrUpdate(T entity, Wrapper<T> updateWrapper); // 批量修改插入 boolean saveOrUpdateBatch(Collection<T> entityList); // 批量修改插入,指定批次数量 boolean saveOrUpdateBatch(Collection<T> entityList, int batchSize);
后续示例直接参考官网对应案例,这里只枚举提供的方法
2.3修改update
// 根据 UpdateWrapper 条件,更新记录 需要设置sqlset boolean update(Wrapper<T> updateWrapper); // 根据 whereWrapper 条件,更新记录 boolean update(T updateEntity, Wrapper<T> whereWrapper); // 根据 ID 选择修改 boolean updateById(T entity); // 根据ID 批量更新 boolean updateBatchById(Collection<T> entityList); // 根据ID 批量更新 boolean updateBatchById(Collection<T> entityList, int batchSize);
2.4获取get
// 根据 ID 查询 T getById(Serializable id); // 根据 Wrapper,查询一条记录。结果集,如果是多个会抛出异常,随机取一条加上限制条件 wrapper.last("LIMIT 1") T getOne(Wrapper<T> queryWrapper); // 根据 Wrapper,查询一条记录 T getOne(Wrapper<T> queryWrapper, boolean throwEx); // 根据 Wrapper,查询一条记录 Map<String, Object> getMap(Wrapper<T> queryWrapper); // 根据 Wrapper,查询一条记录 <V> V getObj(Wrapper<T> queryWrapper, Function<? super Object, V> mapper);
2.5列表list
// 查询所有 List<T> list(); // 查询列表 List<T> list(Wrapper<T> queryWrapper); // 查询(根据ID 批量查询) Collection<T> listByIds(Collection<? extends Serializable> idList); // 查询(根据 columnMap 条件) Collection<T> listByMap(Map<String, Object> columnMap); // 查询所有列表 List<Map<String, Object>> listMaps(); // 查询列表 List<Map<String, Object>> listMaps(Wrapper<T> queryWrapper); // 查询全部记录 List<Object> listObjs(); // 查询全部记录 <V> List<V> listObjs(Function<? super Object, V> mapper); // 根据 Wrapper 条件,查询全部记录 List<Object> listObjs(Wrapper<T> queryWrapper); // 根据 Wrapper 条件,查询全部记录 <V> List<V> listObjs(Wrapper<T> queryWrapper, Function<? super Object, V> mapper);
2.6列表分页list
// 无条件分页查询 IPage<T> page(IPage<T> page); // 条件分页查询 IPage<T> page(IPage<T> page, Wrapper<T> queryWrapper); // 无条件分页查询 IPage<Map<String, Object>> pageMaps(IPage<T> page); // 条件分页查询 IPage<Map<String, Object>> pageMaps(IPage<T> page, Wrapper<T> queryWrapper);
2.7统计数量count
// 查询总记录数 int count(); // 根据 Wrapper 条件,查询总记录数 int count(Wrapper<T> queryWrapper);//自3.4.3.2开始,返回值修改为long // 查询总记录数 long count(); // 根据 Wrapper 条件,查询总记录数 long count(Wrapper<T> queryWrapper);
2.8删除remove
// 根据 queryWrapper 设置的条件,删除记录 boolean remove(Wrapper<T> queryWrapper); // 根据 ID 删除 boolean removeById(Serializable id); // 根据 columnMap 条件,删除记录 boolean removeByMap(Map<String, Object> columnMap); // 删除(根据ID 批量删除) boolean removeByIds(Collection<? extends Serializable> idList);
可见直接在service提供的方法和mapper提供的方法名是做了区分的,有效避免了混淆。至于mapper提供的方法就不再赘述,因为这种是使用的最多的,详见基础。
3.复杂的条件构造
3.1 and or
比如现有一个查询条件,查询物料名称或编码包含输入的物料且药品名称包含输入的药品名称(参数均为单值),应该怎么做?
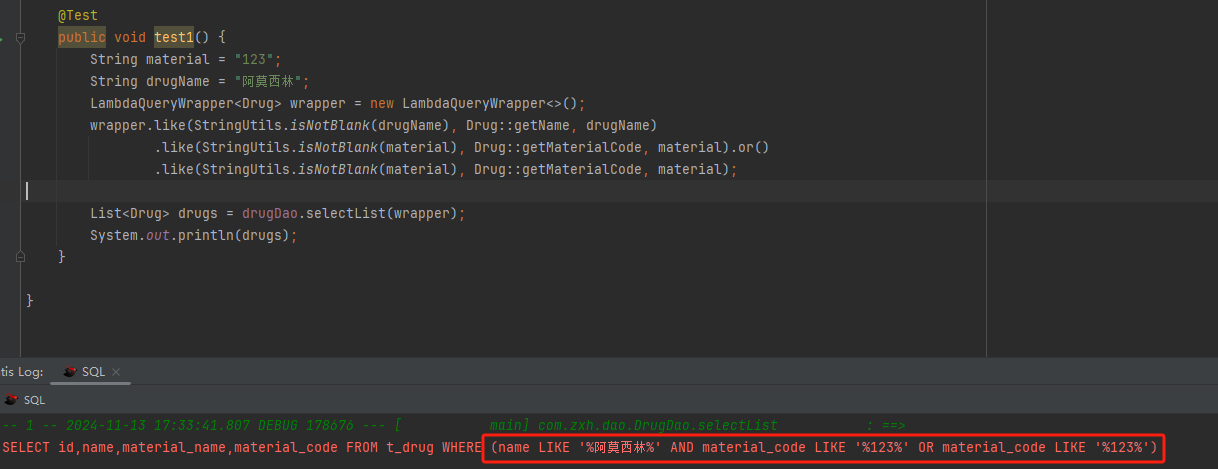
显然根据打印的sql可以看出,这种方式是错误的,这是就需要使用and和or结合,正确方法如下
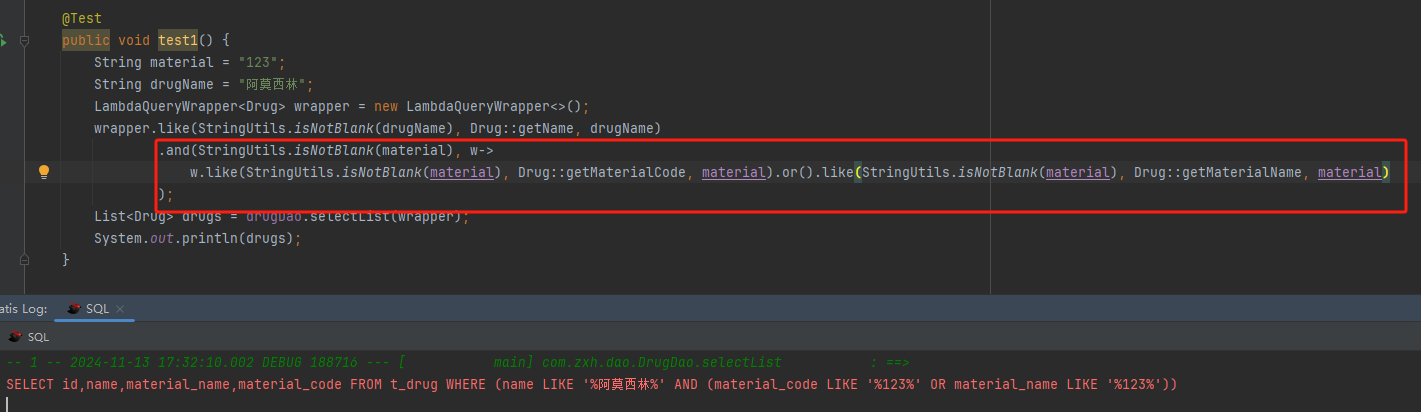
也就是说需要结合and实现同一条件查询,相当于用小括号将同时需要满足的条件括起来。
3.2 and for or
这也是上述的一种变种,非常使用。
比如现有一个查询条件,查询物料名称和物料编码等于前端传入的物料列表(参数为数组)且药品名称包含输入入的药品名称(参数为单值),应该怎么做?其实重点在于同时满足两个字段且是列表。正确方法如下
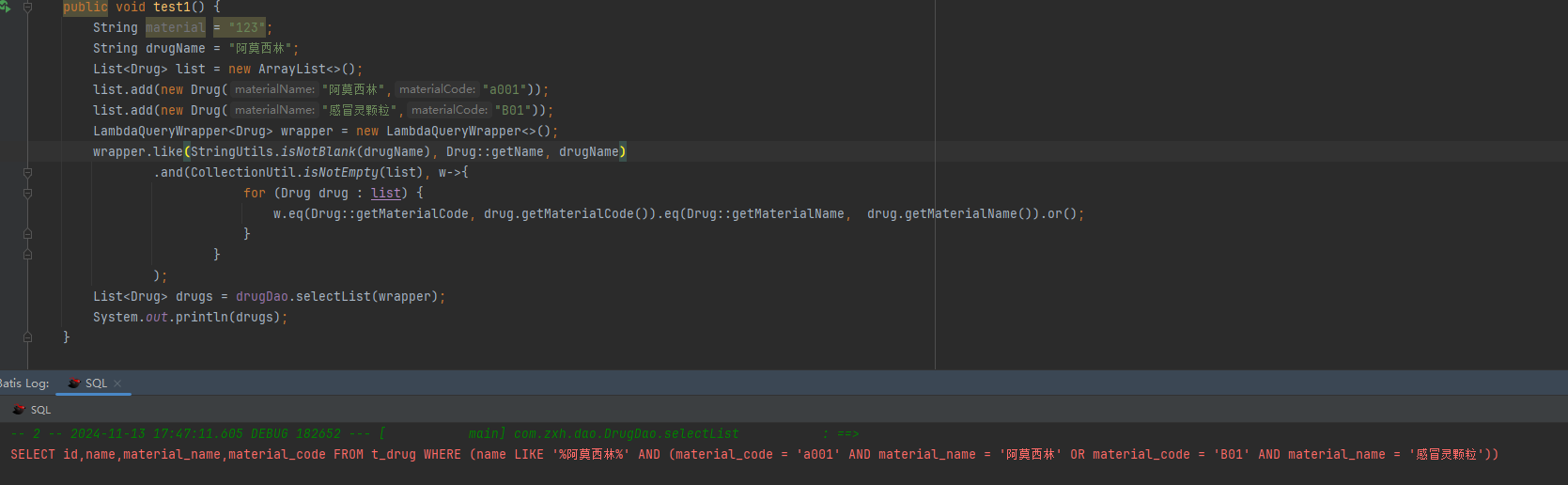
这种sql才是我们最终想要的结果。关键在于for循环的介入及and的使用。



![[Flask]SSTI 1](https://img2023.cnblogs.com/blog/3554714/202411/3554714-20241115101054177-86731220.png)