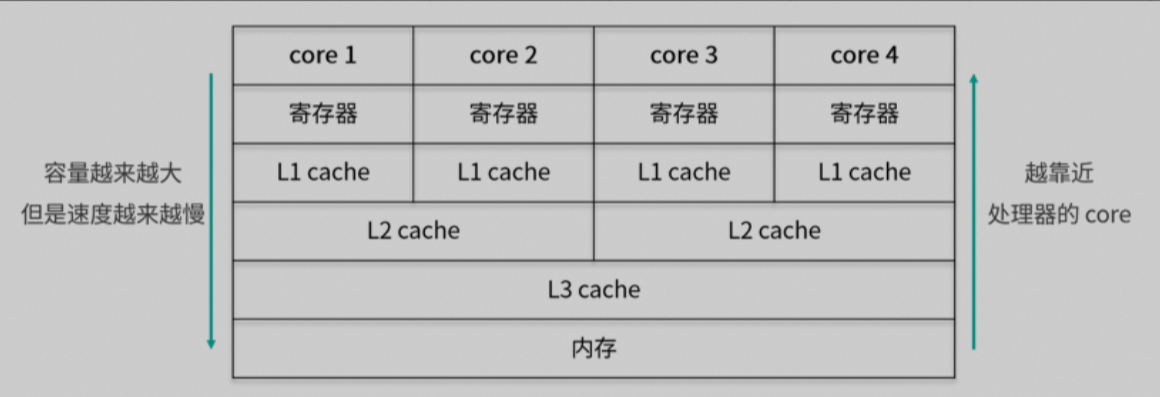
今天的博客来自 JuiceFS 云服务用户 Jerry,他们通过使用 JuiceFS snapshot 功能,创新性地实现了数据的版本控制。Jerry,是一家位于北美的科技公司,利用人工智能和机器学习技术,简化用户购买汽车和家庭保险的比较及购买流程。
在软件开发领域,严格的测试和受控发布已经成为几十年来的标准做法。但如果我们能将这些原则应用到数据库和数据仓库中会怎样?想象一下,能够为数据基础设施定义一套带有测试用例的标准,自动应用于每个新的"发布",以确保客户始终看到准确和一致的数据。这将会极大改善数据质量。
01 挑战:为什么端到端测试在数据管理中并不常见
这个想法看似直观,但端到端测试在数据管理中并不常见,因为它需要数据库或数据仓库具备克隆或快照的功能,而大多数数据系统都不提供这一功能。
现代数据仓库本质上是随时间变化的有组织的可变存储,我们通过数据管道对其进行操作。数据通常在生成后立即对最终客户可见,没有"发布"的概念。当没有这个发布概念,对数据仓库进行端到端测试就没有多大意义。因为无法确保测试所看到的内容就是客户将看到的内容,这些数据在不断因为数据管线的修改而变化。
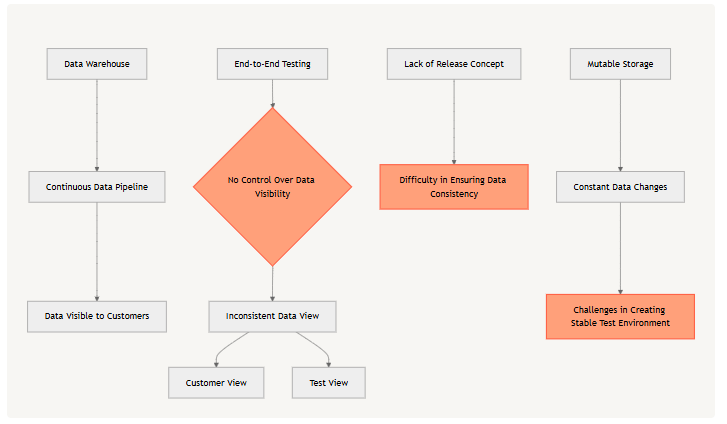
所以问题的核心,就是要在实现一种数据发布的机制,这种机制能够把某一个时刻数据仓库的状态提取成一个“快照“,并且控制这个”快照“对最终用户的可见性。这样,这个快照就成为一个”发布工件“,我们控制它什么条件、什么时间最终可以让用户看见。
02 现有方法及其局限性
一些团队在数据仓库之上开发了版本控制系统。他们不直接修改最终用户查询的表,而是为变更创建新版本的表,并使用原子交换操作来"发布"表。虽然这种方法在某种程度上有效,但它带来了重大挑战:
- 高效实施"创建和交换"模式并不容易;
- 确保涉及多个表的一致性(例如,验证订单表中的每一行在价格表中都有对应行)需要将多个表的变更"打包"成一个"事务",这也具有挑战性,不仅仅实现这种模式是困难的,这种模式也要求数据管线被相对严格的编排。
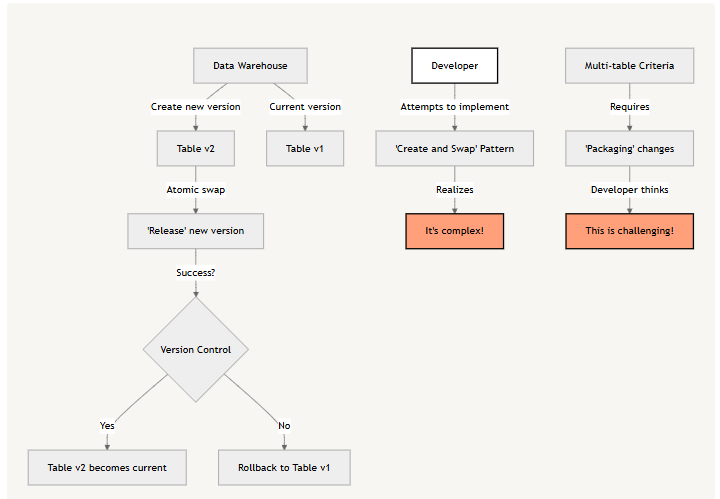
03 解决方案:由 JuiceFS 支持的 ClickHouse 数据库克隆
我们开发了一个系统,利用 JuiceFS snapshot 功能将 ClickHouse 数据库"克隆"为副本。这种方法在我们早前的文章 "低成本读写分离:Jerry构建主从ClickHouse架构" 中有详细介绍。
它的工作原理如下:
- 我们在 JuiceFS 上运行 ClickHouse 数据库,JuiceFS 是一个由对象存储服务(OSS)支持的 POSIX 兼容共享文件系统。
- JuiceFS 提供了一个实现 git 分支语义的"快照"功能。
- 使用简单的命令如
juicefs snapshot src_dir des_dir,我们可以创建 src_dir 在那一刻的克隆。
这种方法使我们能够轻松地从运行中的实例复制/克隆 ClickHouse 实例,创建一个可以被视为"发布工件"的冻结快照。
04 使用数据库克隆实施端到端测试
有了这种机制,我们可以对 ClickHouse 副本运行端到端测试,并根据测试结果控制其可见性。
现在可以使用常见的单元测试框架(我们使用 pytest )开发、组织和迭代数据端到端测试。这种方法使我们能够将数据可用性和可靠性的基础设施和业务标准编码成数据测试。
一个典型的测试是表大小测试,它有助于防止由意外或临时表损坏导致的数据问题。还可以定义业务标准,以保护数据报告和分析免受数据管道中可能导致数据错误的意外更改的影响。例如,用户可以在一列或一组列上强制唯一性以避免重复——这在计算营销成本时是一个关键因素。
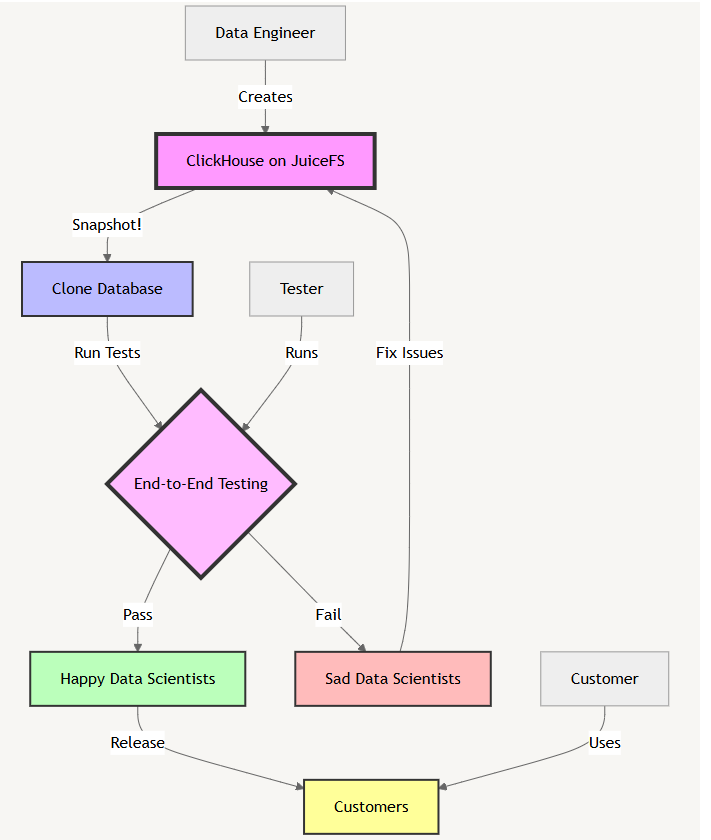
在 Jerry,这种架构在近几个季度中发挥了至关重要的作用,有效防止了几乎所有可能暴露给最终客户的 P0 级数据问题。
这种方法不仅限于 ClickHouse。如果在 JuiceFS 之上运行任何类型的数据湖或湖仓,采纳本文描述的发布机制可能会更容易。
05 结论
通过将现代软件开发实践引入数据管理世界,我们可以显著提高数据质量、可靠性和一致性。数据库克隆和端到端测试的结合为确保客户始终看到正确的数据提供了强大的工具集,就像他们期望在经过充分测试的软件发布中看到正确的功能一样。
下图展示了我们的数据库发布和端到端测试过程的工作流程。
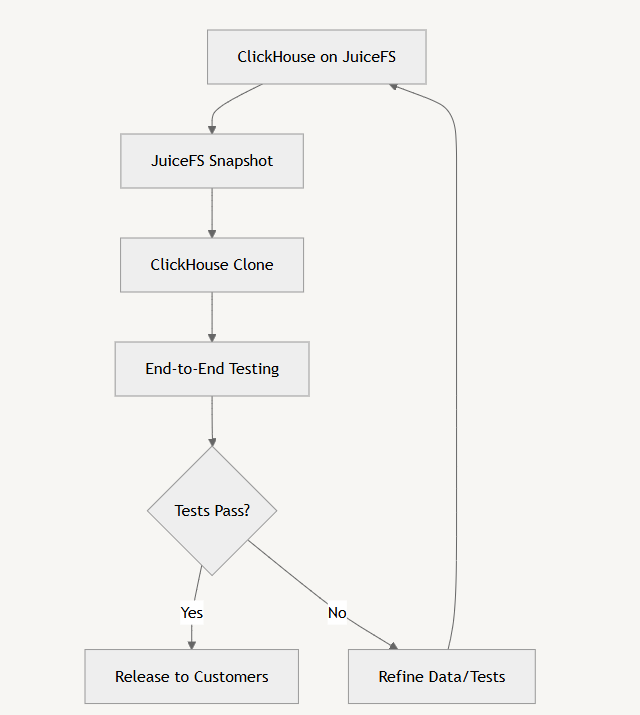
这个架构的诞生标志着我们在缩小软件开发与数据管理之间的差距方面迈出了重要一步,为数据领域的创新和质量保障开辟了全新的可能性。
希望这篇内容能够对你有一些帮助,如果有其他疑问欢迎加入 JuiceFS 社区与大家共同交流。