import fitz # PyMuPDF
import pandas as pd
import os# 获取当前文件夹中所有的PDF文件
pdf_files = [f for f in os.listdir('.') if f.endswith('.pdf')]# 提取目录信息的函数
def extract_toc(toc, toc_list, level=0):for item in toc:# 确保目录项至少包含标题if len(item) > 1 and item[1]:title = item[1]# 确保页码是数字类型page = item[2] if len(item) > 2 and isinstance(item[2], int) else Noneif page is not None:# 添加条目到列表toc_list.append({'Title': title,'Page': page})# 如果有子条目,递归提取if len(item) > 3 and item[3]: # 子条目在索引3extract_toc(item[3], toc_list, level + 1) # 传递level + 1# 遍历所有PDF文件
for pdf_file in pdf_files:# 打开PDF文件document = fitz.open(pdf_file)# 获取PDF的目录toc = document.get_toc(simple=False)# 初始化toc_list以存储新的PDF文件的目录信息toc_list = []# 提取目录信息extract_toc(toc, toc_list)# 关闭PDF文件document.close()# 将列表转换为DataFrametoc_df = pd.DataFrame(toc_list)# 将DataFrame输出到CSV文件,文件名与PDF文件同名output_filename = pdf_file.rsplit('.', 1)[0] + '.csv' # 正确地获取文件名并添加.csv扩展名toc_df.to_csv(output_filename, index=False, encoding='utf-8') # 确保CSV文件被正确写入批量提取当前文件夹pdf书籍目录
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.hqwc.cn/news/835323.html
如若内容造成侵权/违法违规/事实不符,请联系编程知识网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
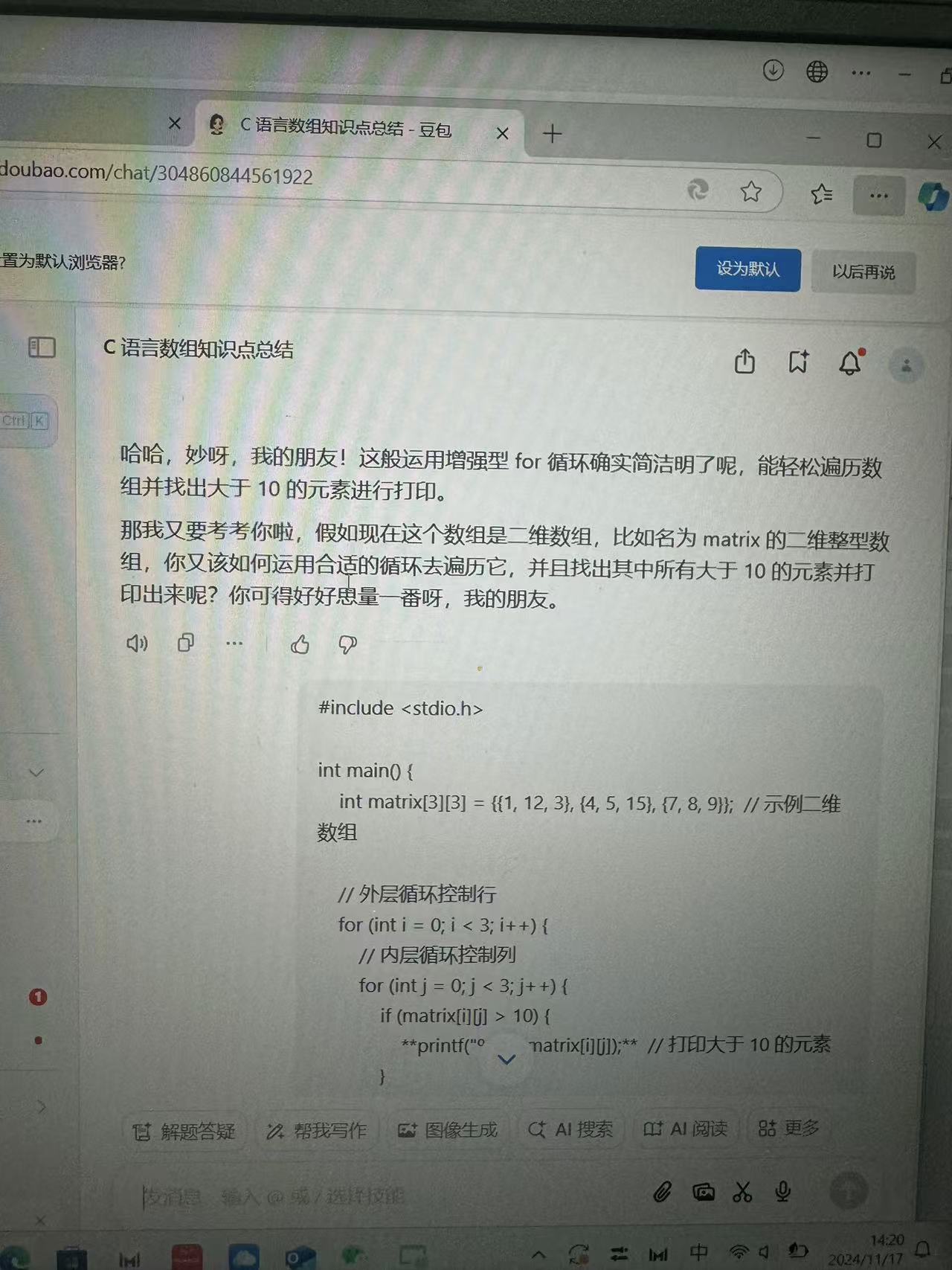
学期2024-2025-1 学号20241421 《计算机基础与程序设计》第8周学习总结
作业信息
|这个作业属于哪个课程|https://edu.cnblogs.com/campus/besti/2024-2025-1-CFAP|
|这个作业要求在哪里|https://www.cnblogs.com/rocedu/p/9577842.html#WEEK08|
|这个作业的目标|功能设计与面向对象设计,面向对象设计过程,面向对象语言三要素,汇编、编译、解释、…

QObject,QMainWindpw,QWidget,QDialog介绍
QObject
QObject 的角色和特点
在 Qt 框架中,QObject 是整个对象模型的核心基类,它为 Qt 对象树 和 信号-槽机制 提供了基础支持。很多 Qt 的类(包括 QWidget、QDialog、QMainWindow)都直接或间接继承自 QObject。
QObject 的核心功能对象树管理(Object Tree)QObject 提供…

2024-2025-1 20241329 《计算机基础与程序设计》第八周学习总结
作业信息
作业归属课程:https://edu.cnblogs.com/campus/besti/2024-2025-1-CFAP
作业要求:https://www.cnblogs.com/rocedu/p/9577842.html#WEEK08
作业目标:功能设计与面向对象设计;面向对象设计过程;面向对象语言三要素;汇编、编译、解释、执行
作业正文:https://www…
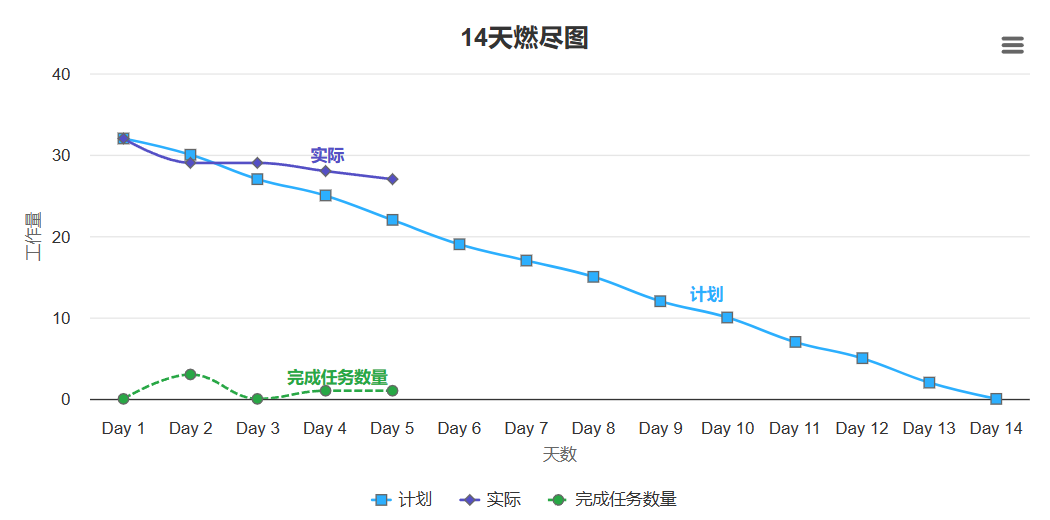
Alpha冲刺(4/14)——2024.11.15
目录一、团队成员分工与进度二、成员任务问题及处理方式三、冲刺会议内容记录会议内容四、GitHub签入记录及项目运行截图GitHub签入记录五、项目开发进展及燃尽图项目开发进展燃尽图六、团队成员贡献表
一、团队成员分工与进度成员
完成的任务
完成的任务时长
剩余时间施靖杰
完…


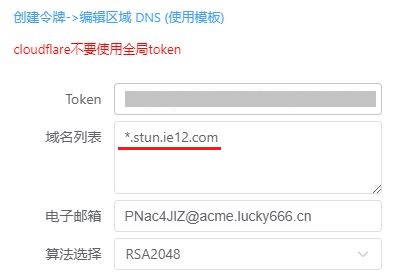
「LUCKY STUN穿透」使用Cloudflare的页面规则固定和隐藏网页端口
关于本教程
索引
│
├─关于本教程
│
├─在STUN穿透环境中使用WEB服务
│ ├─动态端口带来的麻烦
│ ├─“隐藏端口”和固定端口
│ └─可用的解决方法
│ ├─使用邮件进行通知端口变化
│ └─使用HTTP重定向
│
├─网络环境优化和STUN穿透规则设…

企业集成模式-第十二章
十二、中场演练:系统管理示例管理控制台:显式所有组件的工作状态(下图一)
贷款中介的服务质量:监视请求响应时间
验证信用机构的操作:周期性地发送测试消息,希望确信该服务在正常运行(下图二)
信仰机构的故障恢复:如果信仰机构出现故障,希望把信用请求消息临时重定向…

平板电视从入门到精通
先来看一道大家基本都能默写出来的题目:
您需要写一种数据结构(可参考题目标题),来维护一些数,其中需要提供以下操作:插入一个数 \(x\)。
删除一个数 \(x\)(若有多个相同的数,应只删除一个)。
定义排名为比当前数小的数的个数 \(+1\)。查询 \(x\) 的排名。
查询数据结…

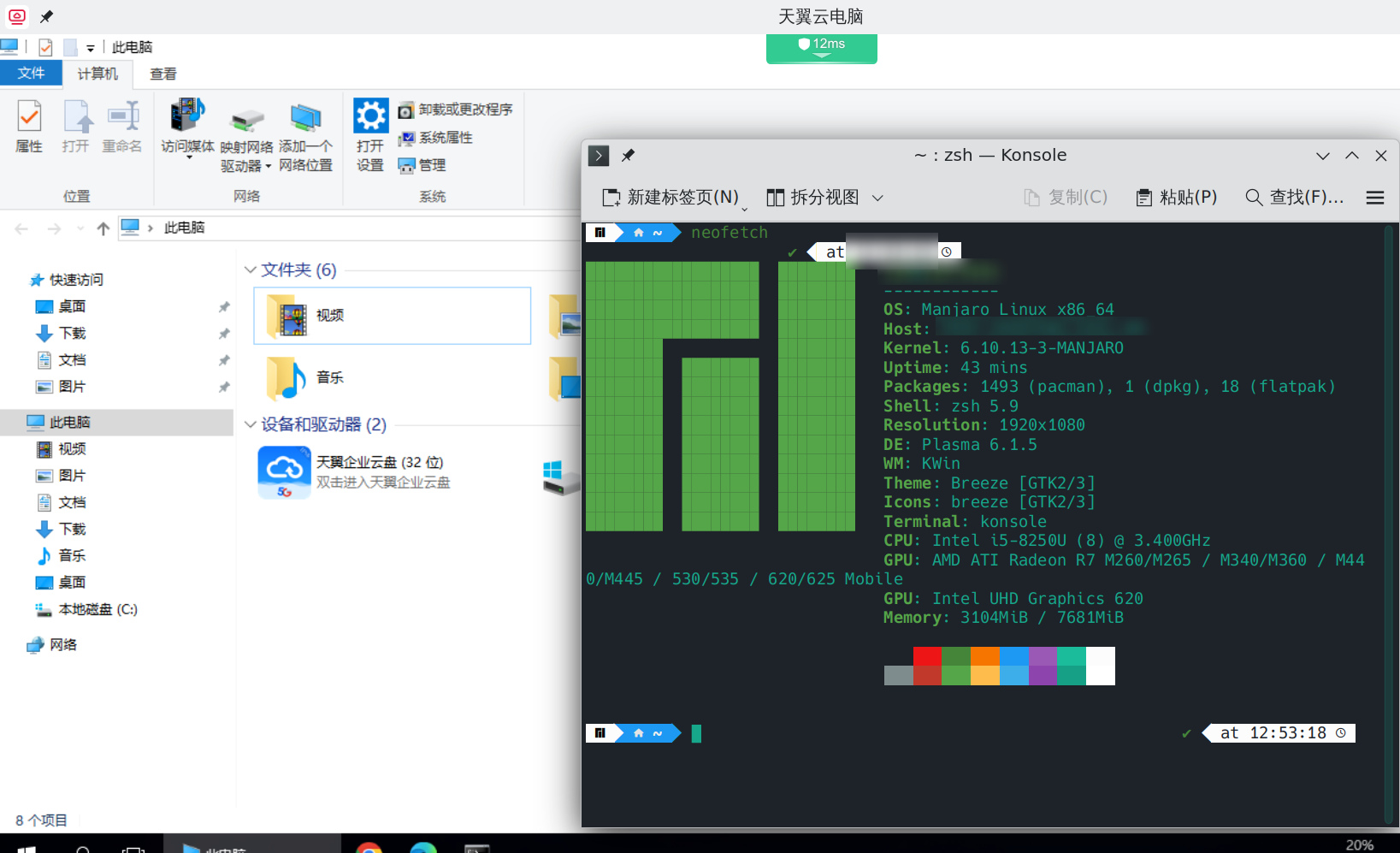
Manjaro/Arch用怎么安装天翼云电脑(Ctyun-cloud-desk)?感谢信创,感谢国家
最近微信出了linux版,用vmware装linux不过瘾,把一台闲置的笔记本装上了Manjaro KDE Plasma,经过一段时间的发展,Linux桌面可用性大大提高。
Kindle->Kindle Mate->Anki这条路在linux下
我用
Kindle ->KindleVocab ->Anki这么代替了之后,
其他软件都能凑合用,…