数据采集与融合技术实践作业四
gitee链接:https://gitee.com/wei-yuxuan6/myproject/tree/master/作业4
作业①
selenium爬取股票实验
-
要求:
熟练掌握 Selenium 查找 HTML 元素、爬取 Ajax 网页数据、等待 HTML 元素等内容。
使用 Selenium 框架+ MySQL 数据库存储技术路线爬取“沪深 A 股”、“上证 A 股”、“深证 A 股”3 个板块的股票数据信息。
候选网站:东方财富网:
http://quote.eastmoney.com/center/gridlist.html#hs_a_board -
输出信息:MYSQL 数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
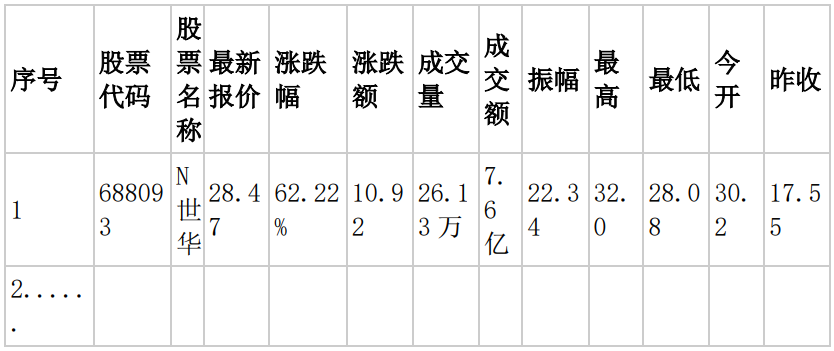
-
过程
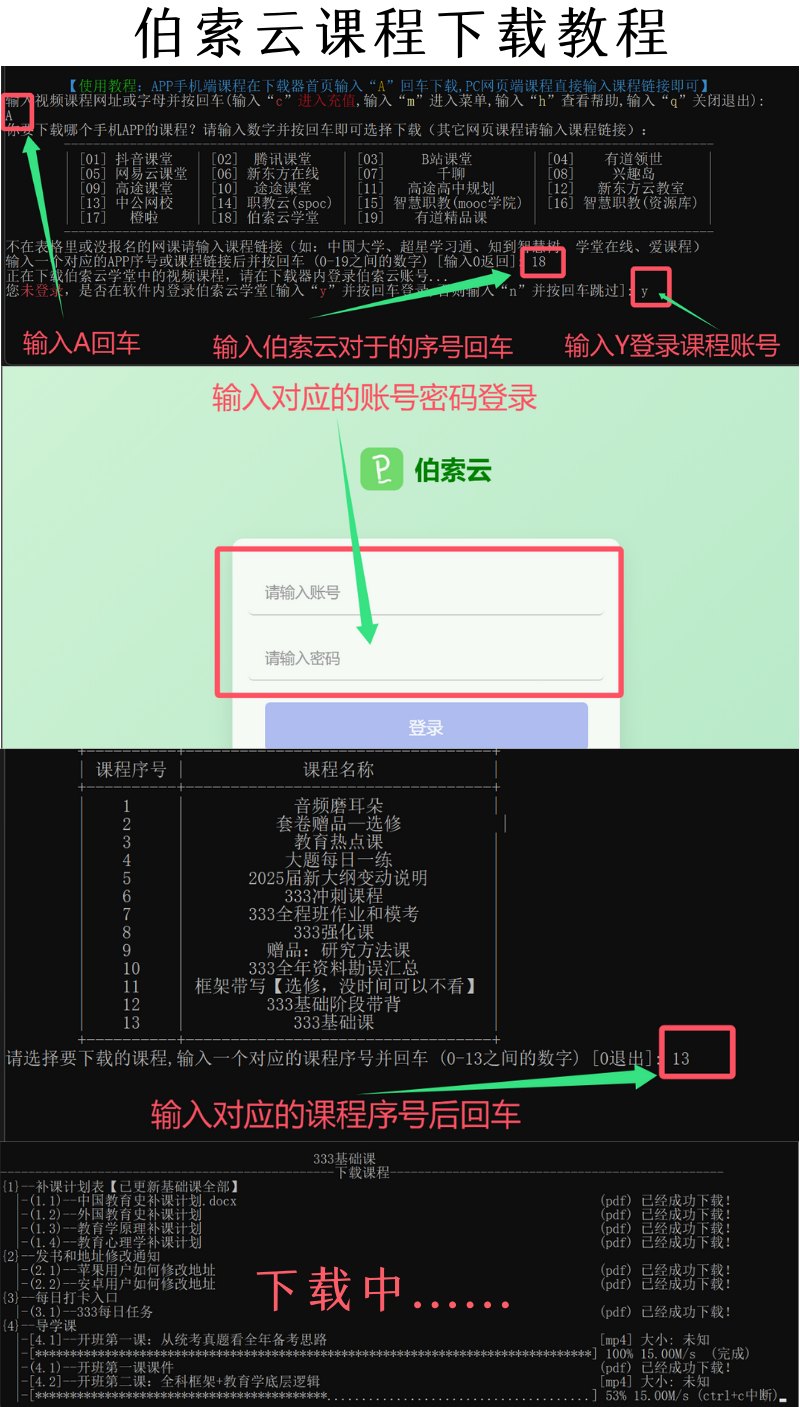
使用selenium模拟浏览器爬取不仅需要定位所需信息的位置,还需要定位按钮、文本框等位置
这里实现了爬取沪深京A股、上证A股、深圳A股3个板块各两页的股票数据
分析网页结构股票信息都在表格<tbody>中,每个股票在一个<tr>元素中,字段分别在不同的<td>中,需要找到自己需要的字段(如序号在第一个td中……)
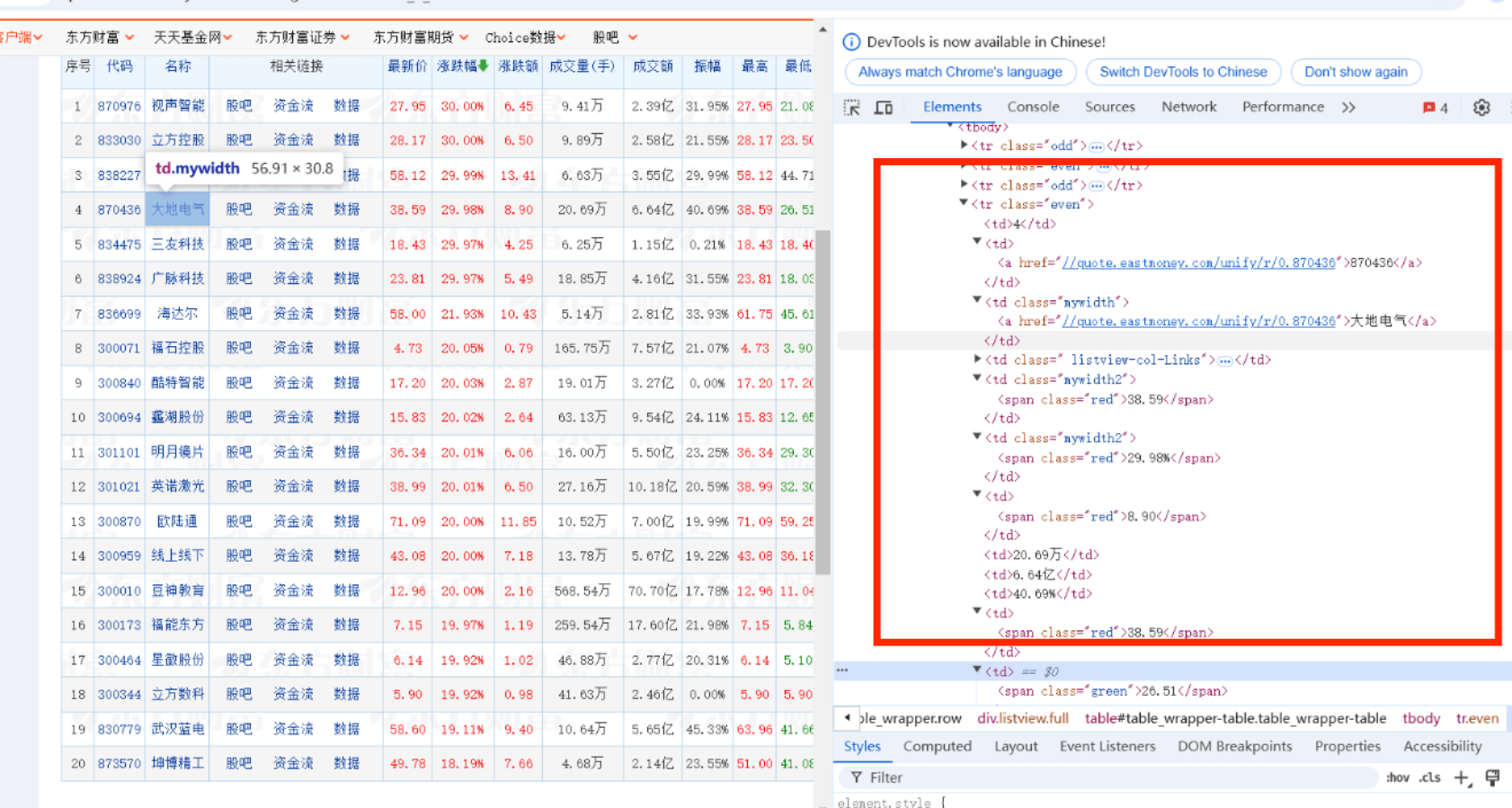
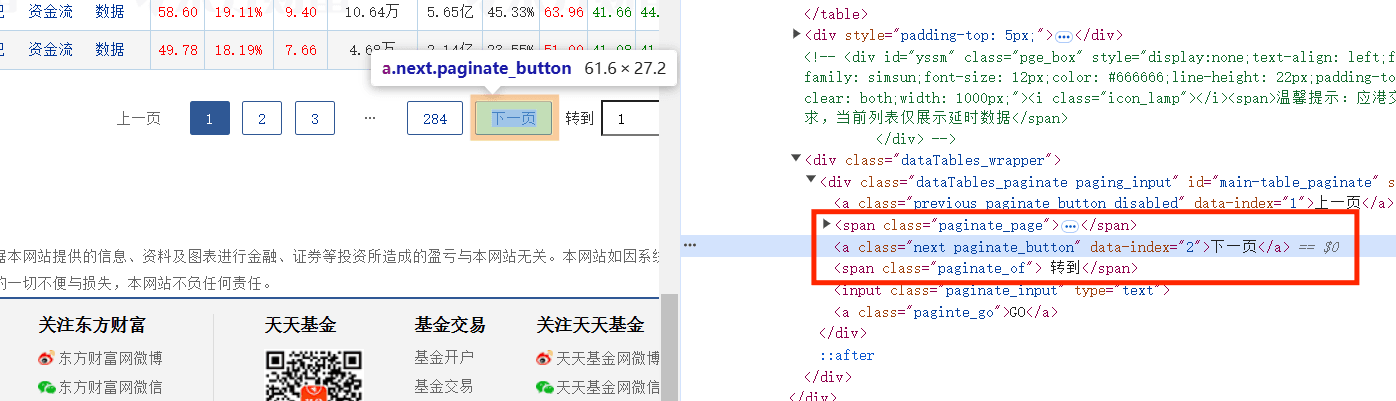
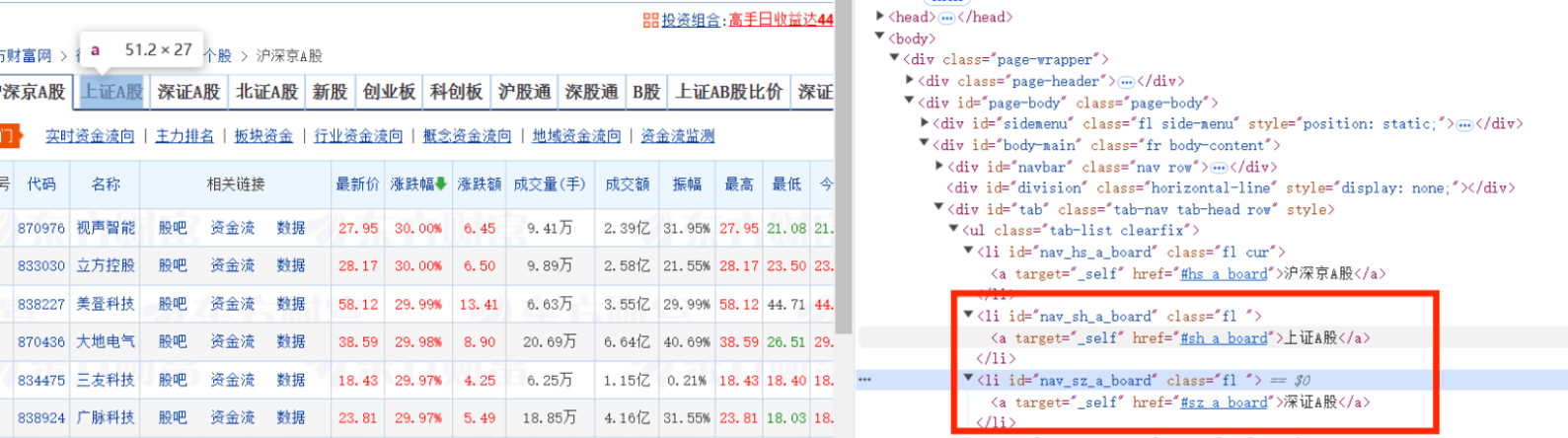
想要实现自动翻页就要模拟点击下一页按钮,按钮在class=next paginate_button的<a>标签中
实现selenium需要使用driver.find_element定位元素,然后模拟点击nextpage.click()
题目还要求跳转到上证A股和深证A股,但是这个不是按钮,而是在<a>标签的herf属性中有页面的链接,所以需要定位到这个元素后使用get_attribute("href")得到这两个页面的链接,并再次使用driver.get()发起请求
还有需要等待元素加载,这里使用了强制等待和隐性等待,强制等待用于点击按钮之后的等待(防止操作过快),隐性等待用于加载页面元素的等待,分别使用了time.sleep(1.5)和WebDriverWait(driver, 10, 0.5).until( EC.presence_of_element_located((By.XPATH, "//table[@id='table_wrapper-table']")))(等待表格元素出现)
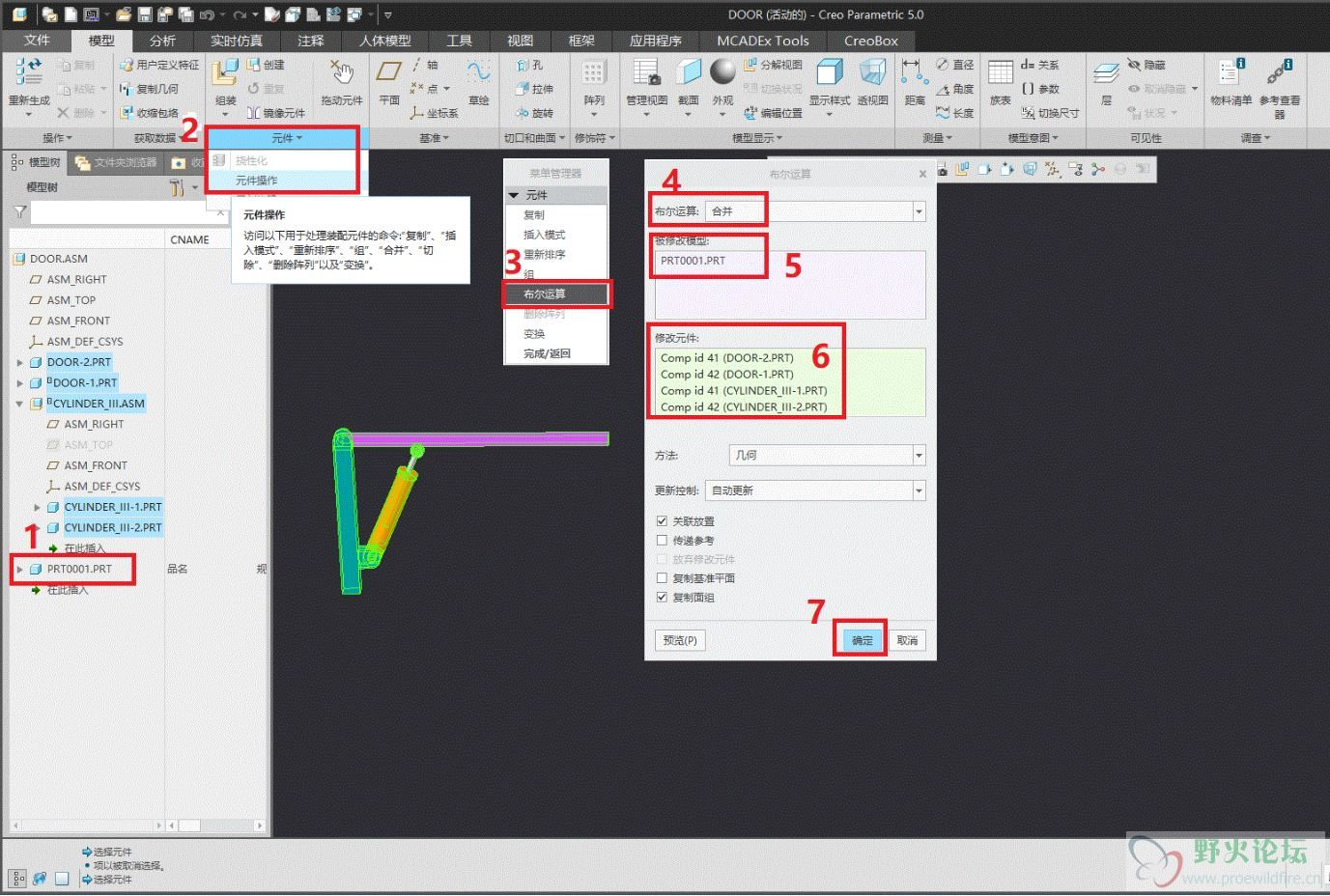
题目还要求了爬取到的数据存储到MySQL中,需要打开数据库、创建表、插入数据、关闭表等操作 -
部分代码
数据库的操作如下class StockDB:# 打开数据库连接并创建表格def openDB(self):# 连接到MySQL数据库self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="Tnt191123!", db="crawl",charset="utf8")# 创建一个游标,使用字典游标以便返回字典格式的数据self.cursor = self.con.cursor(pymysql.cursors.DictCursor)try:# 创建一个名为stocks2的表,包含多个字段self.cursor.execute("create table stocks2(no int,code varchar(32),name varchar(32),zxj varchar(32),zdf varchar(32),zde varchar(32),""cjl varchar(32),zf varchar(32),zg varchar(32),zd varchar(32),jk varchar(32),zs varchar(32))")except:# 如果表已存在,则清空表中的所有数据self.cursor.execute("delete from stocks2")# 关闭数据库连接并提交更改def closeDB(self):# 提交当前事务self.con.commit()# 关闭数据库连接self.con.close()# 向数据库插入一条记录def insert(self, no, code, name, zxj, zdf, zde, cjl, zf, zg, zd, jk, zs):try:# 插入数据到stocks2表self.cursor.execute("insert into stocks2(no,code,name,zxj,zdf,zde,cjl,zf,zg,zd,jk,zs) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,""%s,%s,%s)",(no, code, name, zxj, zdf, zde, cjl, zf, zg, zd, jk, zs))except Exception as err:# 捕捉并打印错误print(err)下面是获取每个页面的股票数据的代码,都使用了XPATH,使用position定位对应的
<td>元素,.text获取元素中的文本,每获取一条数据就插入数据库def stockinfo():# 等待表格元素加载WebDriverWait(driver, 10, 0.5).until(EC.presence_of_element_located((By.XPATH, "//table[@id='table_wrapper-table']")))# 查找股票元素items = driver.find_elements(By.XPATH, "//table[@id='table_wrapper-table']//tbody/tr")for item in items:# 提取股票信息并打印no = item.find_element(By.XPATH, ".//td[position()=1]").textcode = item.find_element(By.XPATH, ".//td[position()=2]").textname = item.find_element(By.XPATH, ".//td[position()=3]").textzxj = item.find_element(By.XPATH, ".//td[position()=5]").textzdf = item.find_element(By.XPATH, ".//td[position()=6]").textzde = item.find_element(By.XPATH, ".//td[position()=7]").textcjl = item.find_element(By.XPATH, ".//td[position()=8]").textzf = item.find_element(By.XPATH, ".//td[position()=10]").textzg = item.find_element(By.XPATH, ".//td[position()=11]").textzd = item.find_element(By.XPATH, ".//td[position()=12]").textjk = item.find_element(By.XPATH, ".//td[position()=13]").textzs = item.find_element(By.XPATH, ".//td[position()=14]").textprint("{:<5}{:<10}{:<12}{:<10}{:<10}{:<10}{:<10}{:<10}{:<10}{:<8}{:<8}{:<8}".format(no, code, name, zxj, zdf, zde, cjl, zf, zg, zd, jk, zs))# 将提取的股票信息插入数据库db.insert(no, code, name, zxj, zdf, zde, cjl, zf, zg, zd, jk, zs)# 等待1.5秒time.sleep(1.5)下面是翻页的代码,找到下一页按钮并点击,再次调用stockinfo函数抓取下一页的股票信息
def stock():# 调用stockinfo函数抓取当前页的股票信息stockinfo()# 查找下一页元素并点击nextpage = driver.find_element(By.XPATH, "//*[@id='main-table_paginate']/a[2]")nextpage.click()# 等待1.5秒time.sleep(1.5)# 再次调用stockinfo函数抓取下一页的股票信息stockinfo()创建WebDriver对象并设置浏览器选项
# 设置Chrome浏览器选项 chrome_options = Options() # 禁用GPU加速 chrome_options.add_argument("--disable-gpu") # 创建WebDriver对象 driver = webdriver.Chrome(options=chrome_options)下面是发送请求的代码,还有获取上证A股、深圳A股的链接并发送请求访问
try:# 打印表头print("{:<5}{:<10}{:<10}{:<8}{:<8}{:<10}{:<10}{:<8}{:<10}{:<8}{:<8}{:<8}".format("序号", "代码", "名称", "最新价", "涨跌幅", "涨跌额", "成交量", "振幅", "最高", "最低", "今开", "昨收"))# 访问东方财富网driver.get("http://quote.eastmoney.com/center/gridlist.html#hs_a_board")# 调用stock函数处理股票页面stock()# 获取上证A股链接shzag = driver.find_element(By.XPATH, "//*[@id='nav_sh_a_board']/a").get_attribute("href")print(shzag)# 访问上证A股链接driver.get(shzag)# 刷新当前页面driver.refresh()# 再次调用stock函数处理股票页面stock()# 获取深证A股链接szag = driver.find_element(By.XPATH, "//*[@id='nav_sz_a_board']/a").get_attribute("href")print(szag)# 访问深证A股链接driver.get(szag)# 刷新当前页面driver.refresh()# 再次调用stock函数处理股票页面stock() -
结果
gitee链接:https://gitee.com/wei-yuxuan6/myproject/blob/master/作业4/1.py
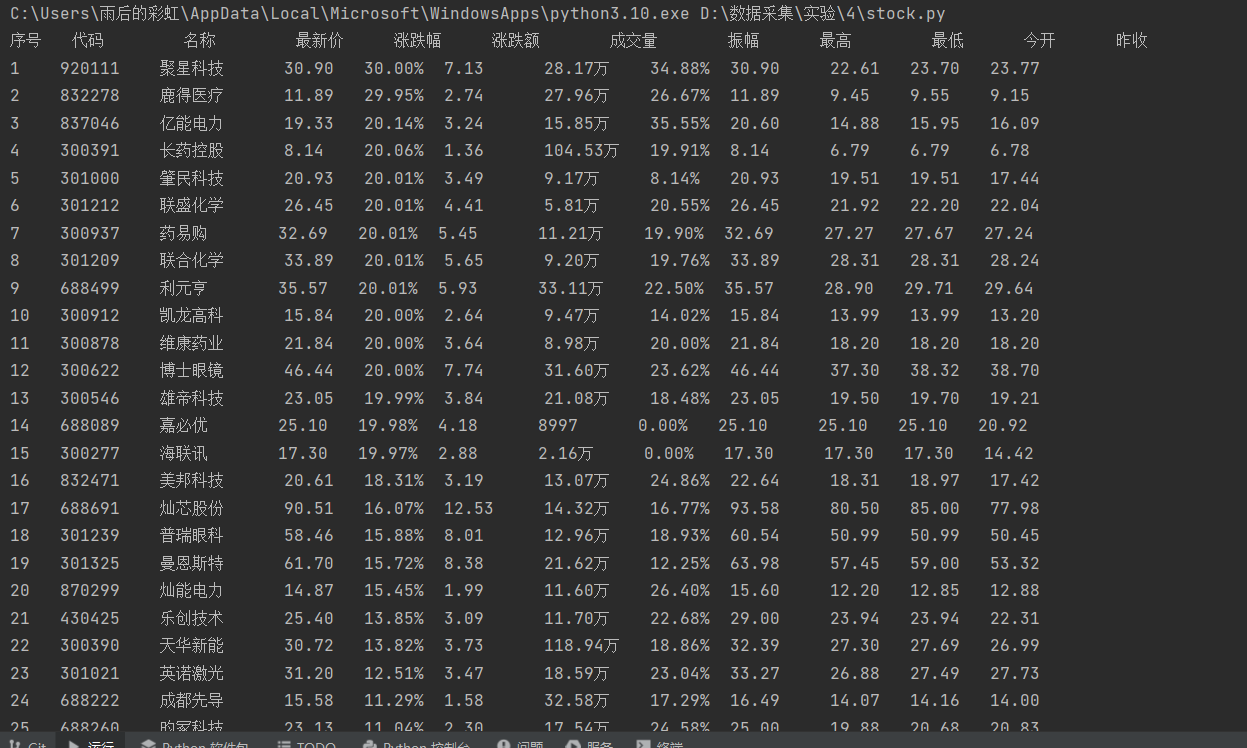
爬取结果
沪深京A股
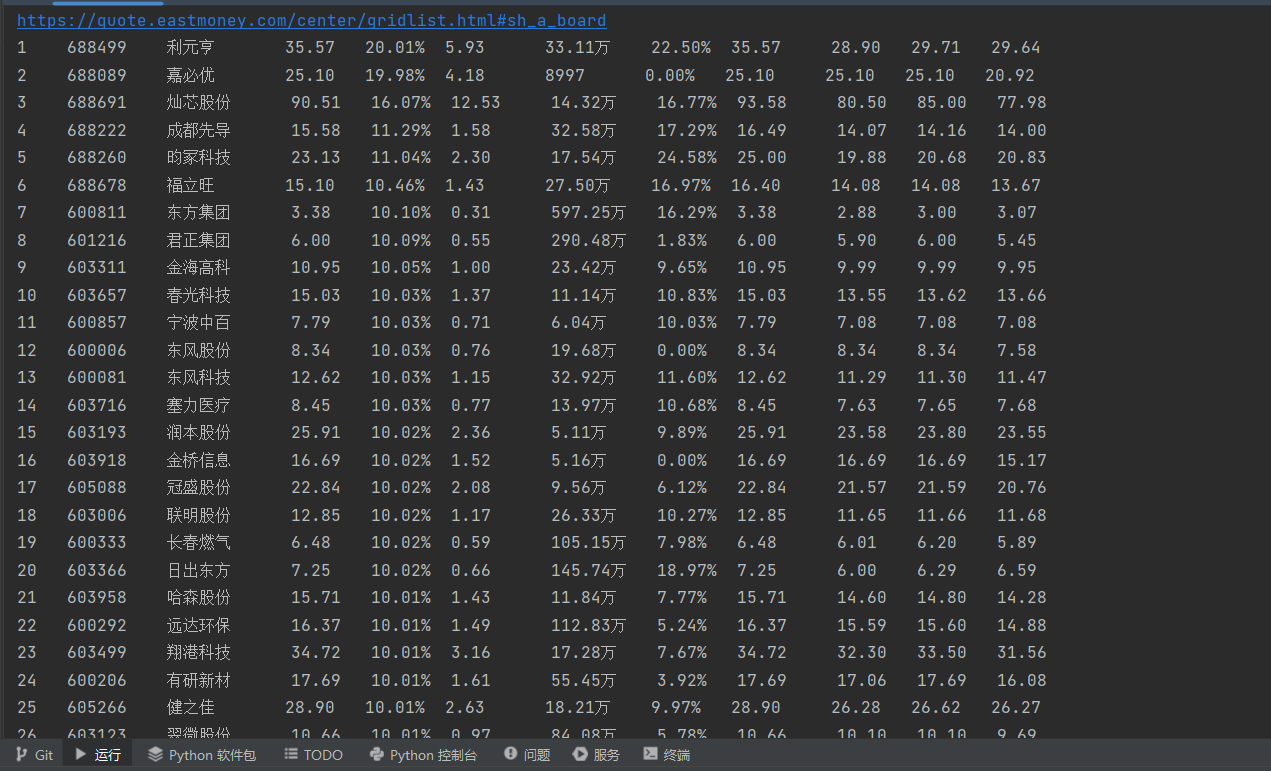
上证A股
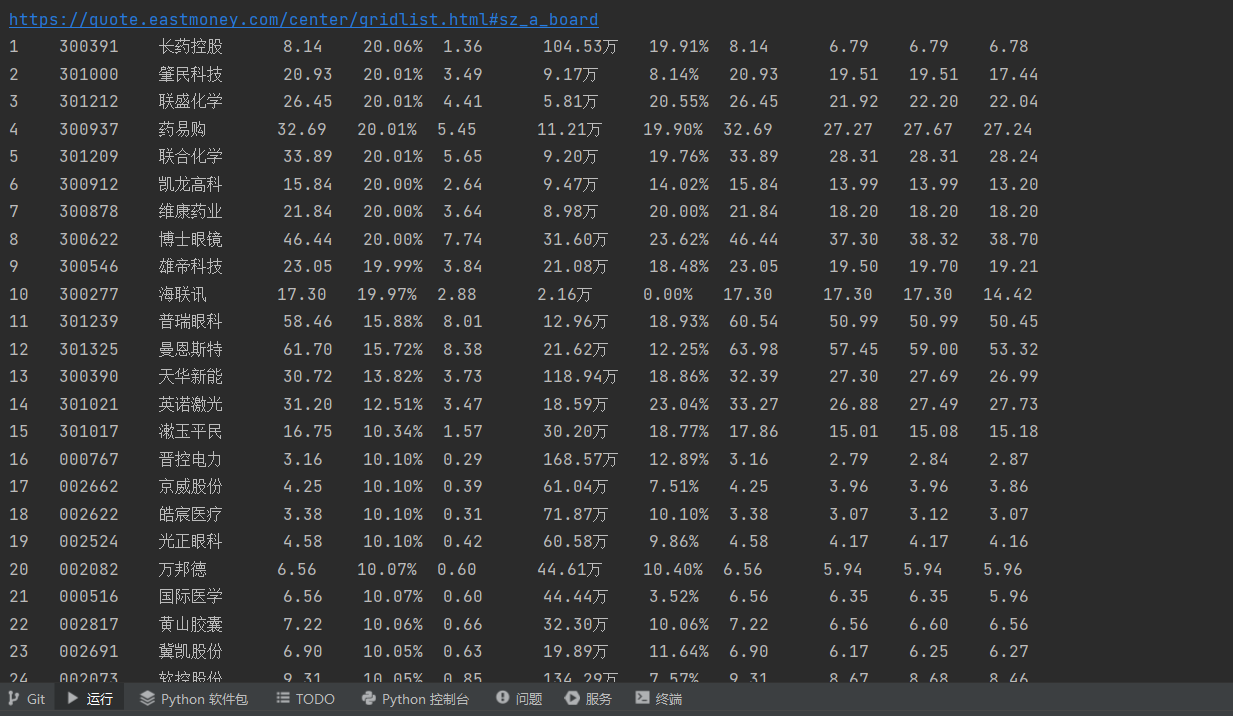
深圳A股
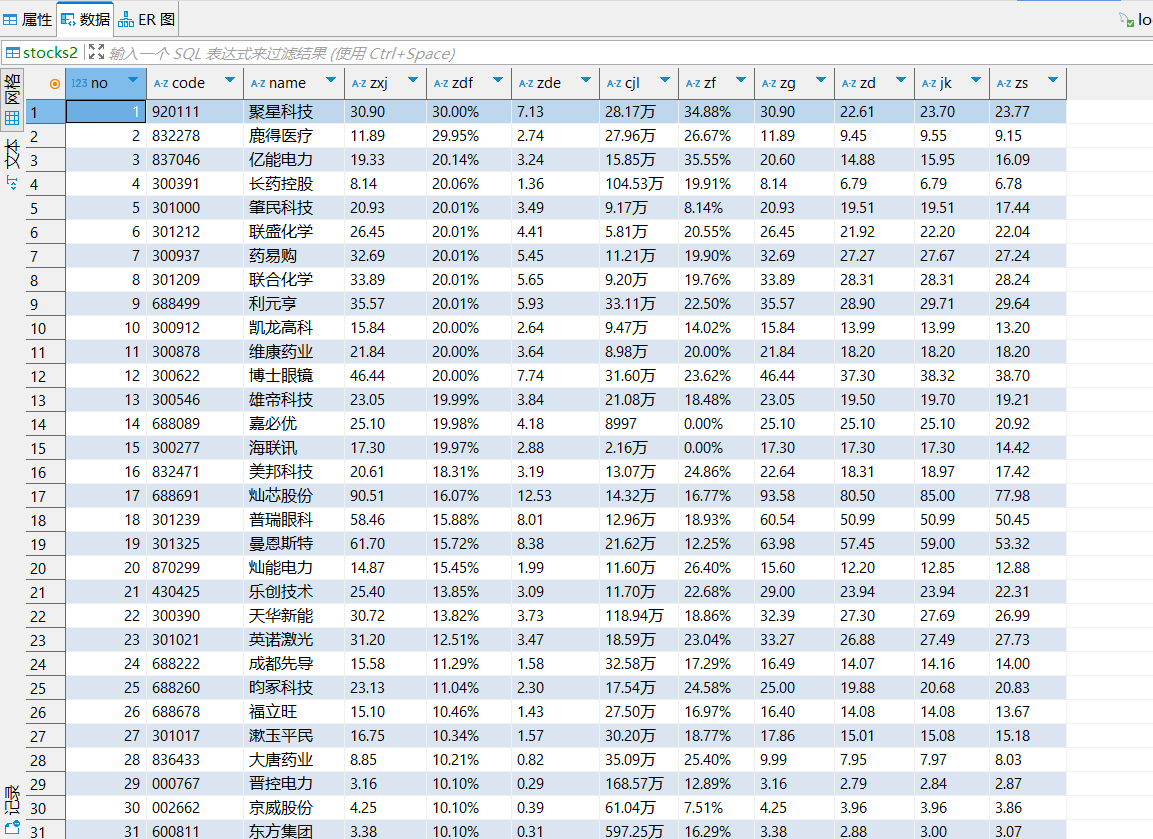
存储到数据库中的数据
心得体会
实践了使用selenium模拟用户点击和访问其他页面的过程,selenium可以获取动态加载之后的数据,还实践了将爬取到的数据存储到MySQL中,但是在完成这个实验的过程中出现了一个问题
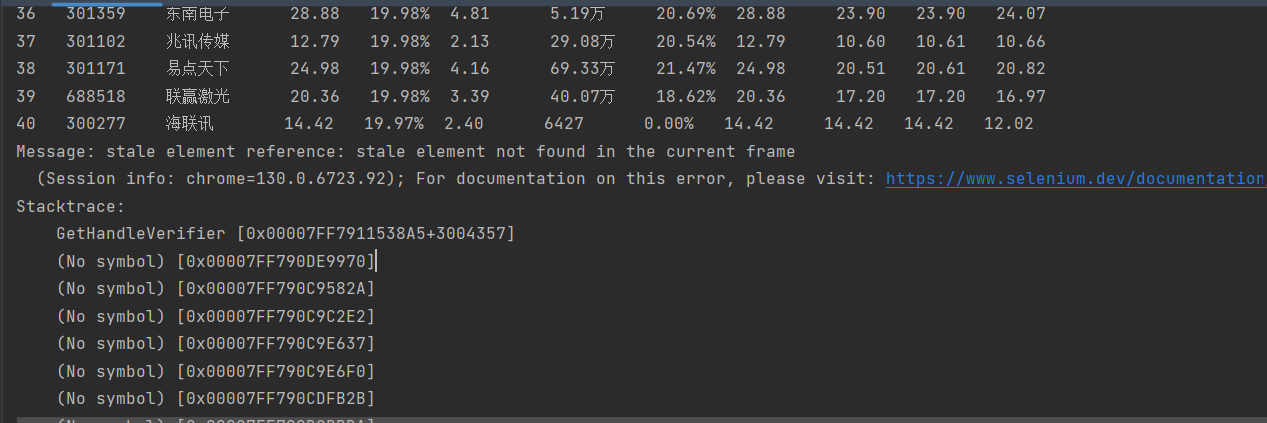
搜索得到错误是因为
这个错误是 Selenium WebDriver 在自动化测试中常见的一个异常,称为 StaleElementReferenceException,即“陈旧元素引用异常”。这个异常通常发生在以下情况:页面刷新或DOM变化:当你尝试与一个元素进行交互,但该元素已经不再存在于当前页面的DOM中,可能是因为页面被刷新了,或者DOM结构发生了变化(例如,通过JavaScript动态加载内容)。导航到其他页面:如果你导航到了一个不同的页面,之前页面中的元素引用就会变得无效。切换窗口或框架:如果你在不同的窗口、框架或iframe之间切换,之前页面中的元素引用也会失效。
可能是切换到另一个板块,不能仅从当前上下文中重新定位它,也不能切换回一个有效的上下文,可以使用refresh刷新页面重新加载数据
作业②
selenium获取mooc课程信息实验
-
要求:
熟练掌握 Selenium 查找 HTML 元素、实现用户模拟登录、爬取 Ajax 网页数据、等待 HTML 元素等内容。 -
使用 Selenium 框架+MySQL 爬取中国 mooc 网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
候选网站:中国 mooc 网:https://www.icourse163.org -
输出信息:MYSQL 数据库存储和输出格式
-
过程
题目要求实现登录,所以进入网站之后要找到登录按钮并模拟点击
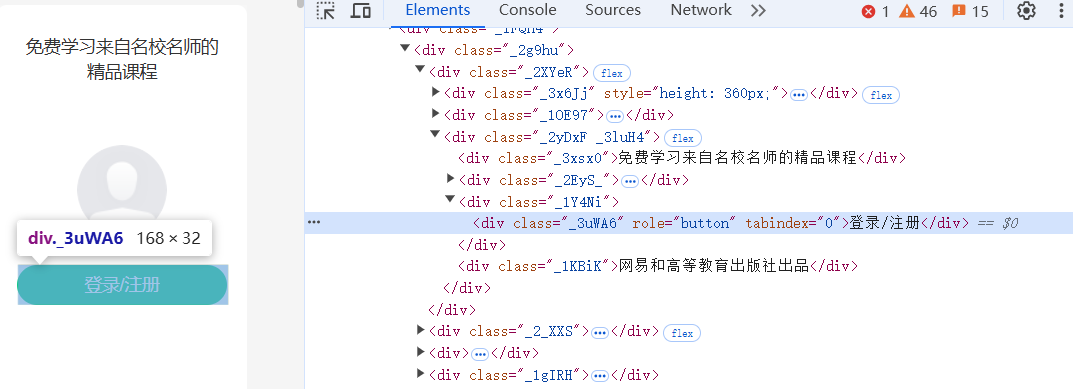
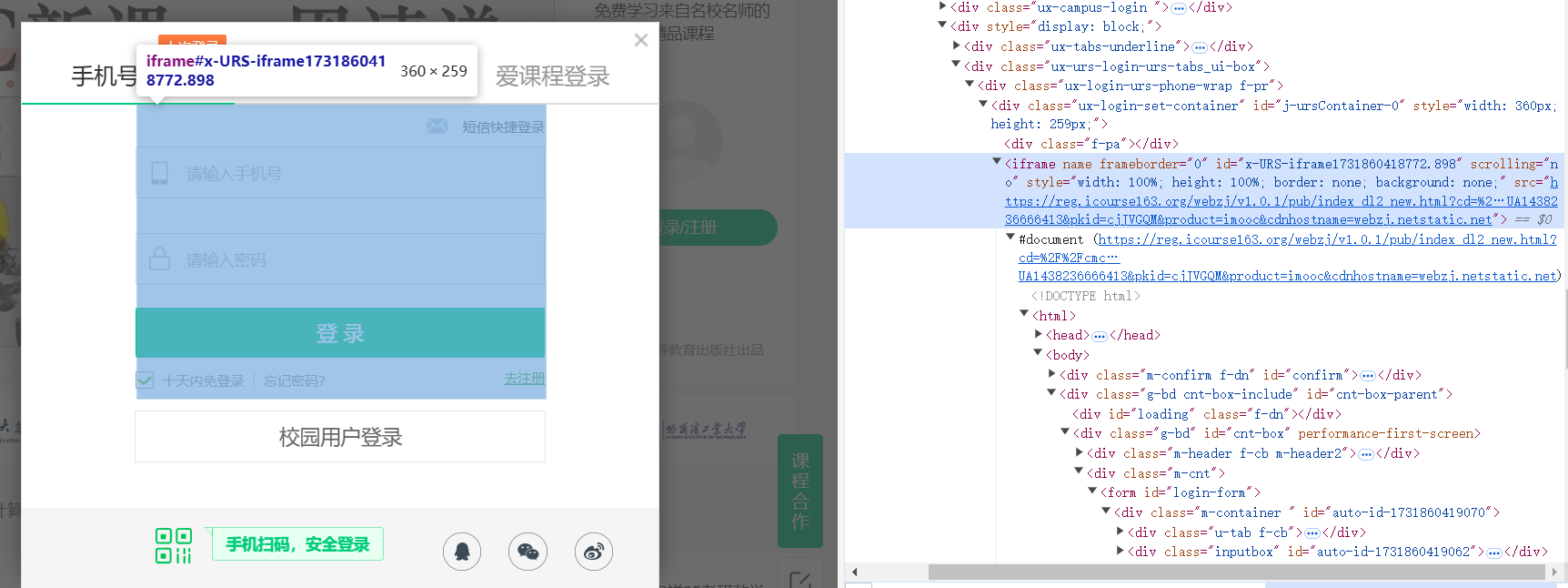
点击之后会跳出登录框,想要让selenium模拟用户输入手机号和密码自动登录,就要让selenium找到手机号和密码框,但是登录框不是在原来的页面上,需要使用driver.switch_to.frame(iframe),将焦点切换到登录框iframe中,就可以在里面输入和点击,使用.send_keys("")输入文本,登录成功之后还需要景焦点切换到原来的界面
登录之后,找到搜索框和搜索按钮,模拟输入想要查询的课程
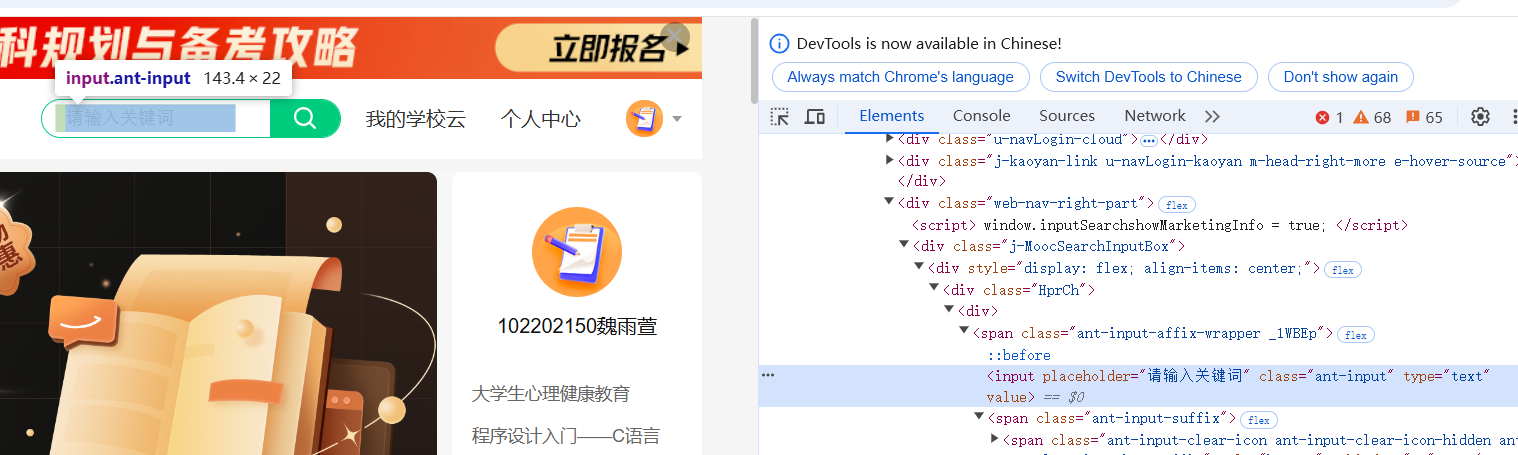
点击搜索按钮之后跳转到搜索到的课程页面,分析页面可得到对应课程的课程名称、学习、老师、参加人数,但是得不到完整的介绍和开课时间,所以需要再点击进去每一个课程进一步爬取
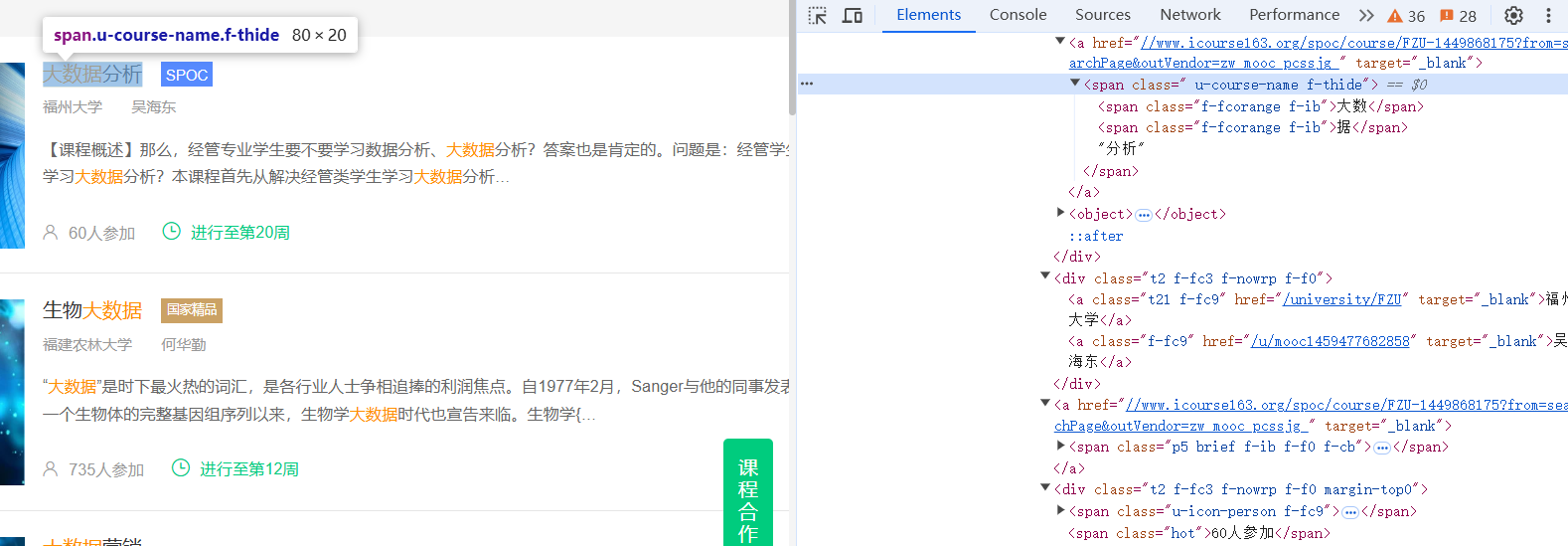
只需要点击每一个课程框就能跳转到课程详细页面
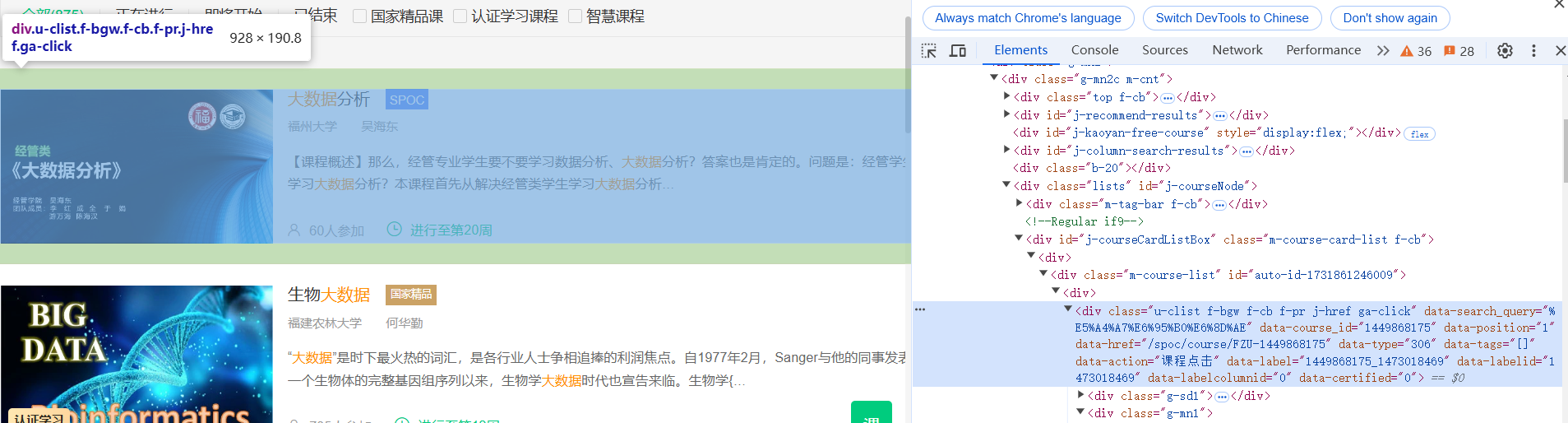
等位到开课时间和课程介绍,获取数据
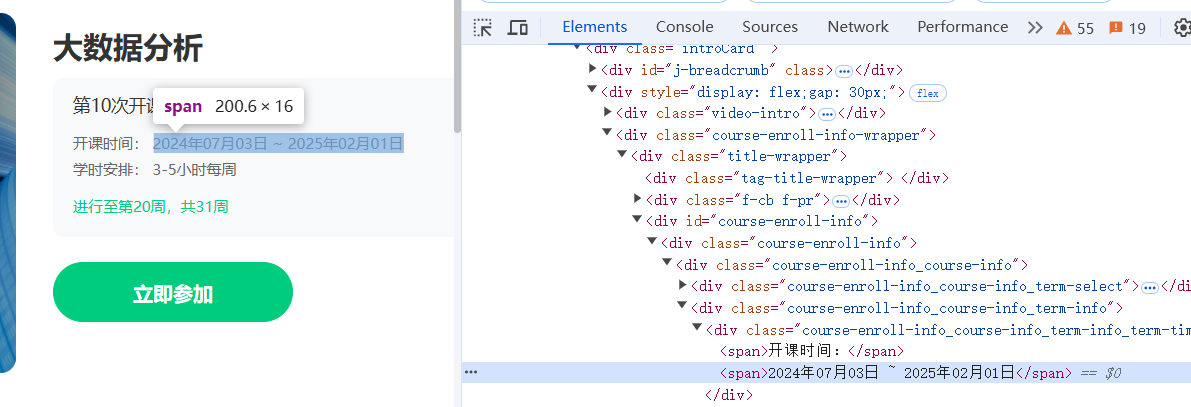
跳转到新的页面时需要使用driver.switch_to.window(driver.window_handles[-1]),将焦点切换到新的页面,爬取到对应数据后使用driver.close()将新打开的页面关闭,避免打开太多页面,再使用driver.switch_to.window(driver.window_handles[0])切换到原页面(即搜索到的课程页面)
同时在爬取的过程中需要很多等待操作,因为需要加载的页面比较多,也是使用了强制等待和隐性等待,强制等待用于点击按钮之后和输入文本之后的等待(防止操作过快),隐性等待用于加载页面元素的等待。 -
部分代码
数据库代码与第一个实验差不多这里就不展示
下面时登录的代码主要是焦点的切换def login():login = driver.find_element(By.XPATH, "//*[@id='app']/div/div/div[1]/div[3]/div[3]/div") # 查找登录按钮login.click() # 点击登录按钮"""iframe = WebDriverWait(driver, 15, 0.5).until(EC.presence_of_element_located((By.XPATH,"//*[@frameborder='0']")))driver.switch_to.frame(iframe)"""log=driver.find_element(By.TAG_NAME,"iframe")driver.switch_to.frame(log) # 切换到登录框WebDriverWait(driver, 15, 0.5).until(EC.presence_of_element_located((By.XPATH, "//*[@id='login-form']/div"))) # 等待登录框加载username = driver.find_element(By.XPATH, "//input[@id='phoneipt']")username.send_keys("13338313884") # 输入用户名time.sleep(1.5)password = driver.find_element(By.XPATH, "//div[4]/div[2]/input[2]")password.send_keys("wyx123456!") # 输入密码time.sleep(1.5)button = driver.find_element(By.XPATH, "//*[@id='submitBtn']")button.click() # 点击登录按钮time.sleep(1.5)driver.switch_to.default_content()time.sleep(5)搜索部分代码
def search():input = driver.find_element(By.XPATH,"//*[@id='j-indexNav-bar']/div/div/div/div/div[7]/div[1]/div/div/div/span/input")input.send_keys("大数据") # 输入搜索关键词time.sleep(1.5)button = driver.find_element(By.XPATH,"//*[@id='j-indexNav-bar']/div/div/div/div/div[7]/div[1]/div/div[1]/div[1]/span/span/span[2]")button.click() # 点击搜索按钮time.sleep(1.5) # 等待页面加载获取课程信息代码,主要也是焦点的切换,切换到新打开的窗口,还有就是授课教师部分,有的只有一个,有的有多个,只有一个时cTeacher和cTeam都是这个老师,有多个时选择第一个作为cTeacher,而且后面的老师在另一个标签元素中,所以cTeam需要分开讨论
def spider():items = driver.find_elements(By.XPATH,"//*[@class='m-course-list']//div[@class='u-clist f-bgw f-cb f-pr j-href ga-click']") # 查找课程元素i = 1for item in items:cCourse = item.find_element(By.XPATH, ".//span[@class=' u-course-name f-thide']").textcCollege = item.find_element(By.XPATH, ".//a[@class='t21 f-fc9']").textcTeacher = item.find_element(By.XPATH, ".//a[@class='f-fc9']").textteachers=item.find_elements(By.XPATH,".//span[@class='f-fc9']")if teachers!=[]:cTeam = cTeacher + item.find_element(By.XPATH, ".//span[@class='f-fc9']").textelse:cTeam = cTeachercCount = item.find_element(By.XPATH, ".//span[@class='hot']").textcClick = driver.find_element(By.XPATH,"//div[@class='u-clist f-bgw f-cb f-pr j-href ga-click'][" + str(i) + "]")cClick.click()time.sleep(5)driver.switch_to.window(driver.window_handles[-1])WebDriverWait(driver, 15, 0.5).until(EC.presence_of_element_located((By.XPATH, "//*[@id='g-body']/div[1]/div")))cProcess = driver.find_element(By.XPATH,"//div[@class='course-enroll-info_course-info_term-info_term-time']//span[2]").textcBrief = driver.find_element(By.XPATH, "//div[@class='course-heading-intro_intro']").textprint(str(i) + "\t" + cCourse + "\t" + cCollege + "\t" + cTeacher + "\t" + cTeam + "\t" + cCount + "\t" + cProcess + "\t" + cBrief)db.insert(i, cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief)i += 1time.sleep(1.5)driver.close()driver.switch_to.window(driver.window_handles[0])time.sleep(5)主函数,创建webdriver对象并发送请求
chrome_options = Options() # 创建Chrome选项对象 chrome_options.add_argument("--disable-gpu") # 禁用GPU加速 chrome_options.add_argument("--start-fullscreen") # 以全屏模式启动浏览器 driver = webdriver.Chrome(options=chrome_options) # 创建WebDriver对象 try:driver.get("https://www.icourse163.org/") # 访问中国大学MOOC网站WebDriverWait(driver, 10, 0.5).until(EC.presence_of_element_located((By.XPATH, "//*[@id='app']/div/div/div[1]")))login()WebDriverWait(driver, 15, 0.5).until(EC.presence_of_element_located((By.XPATH, "//*[@id='j-indexNav-bar']/div/div"))) # 等待页面加载search()WebDriverWait(driver, 15, 0.5).until(EC.presence_of_element_located((By.XPATH, "//*[@id='j-courseNode']")) )# 等待页面加载spider() -
结果
gitee链接:https://gitee.com/wei-yuxuan6/myproject/blob/master/作业4/2.py
selenium模拟输入和跳转,也可以实现翻页,因为跳转比较慢而且需要一个一个课程点入所以只爬取了一页的课程信息
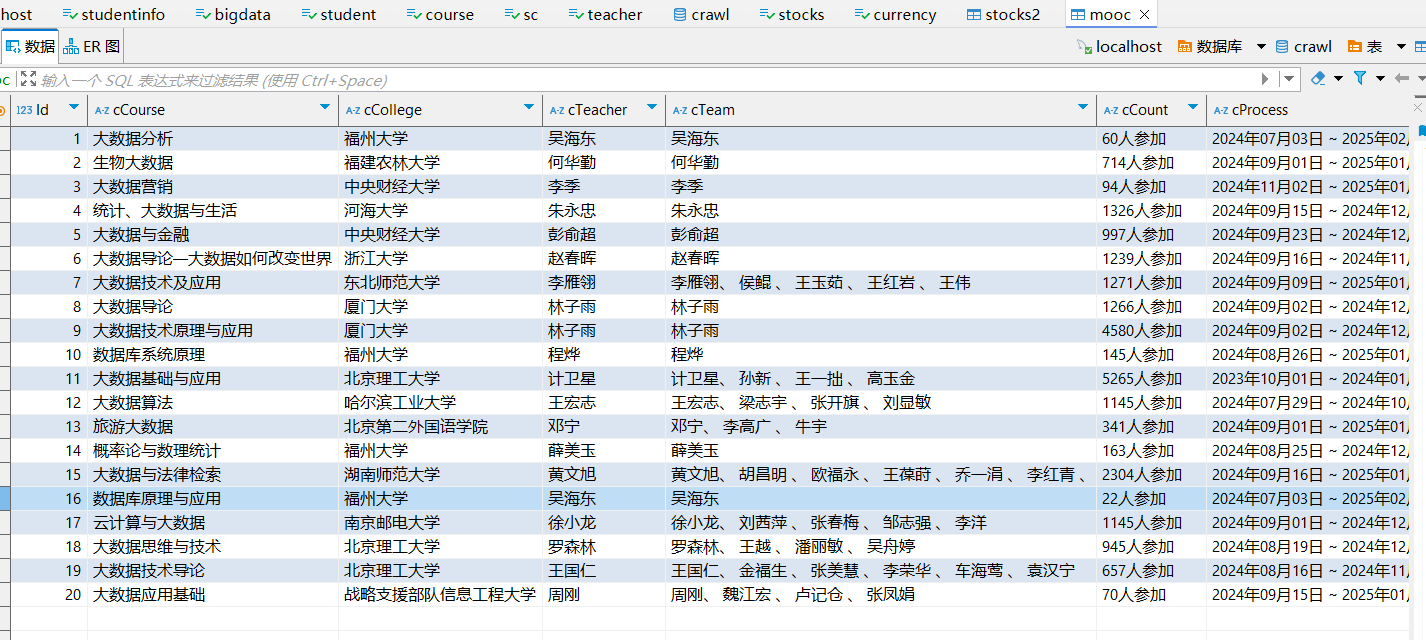
获取到的课程信息

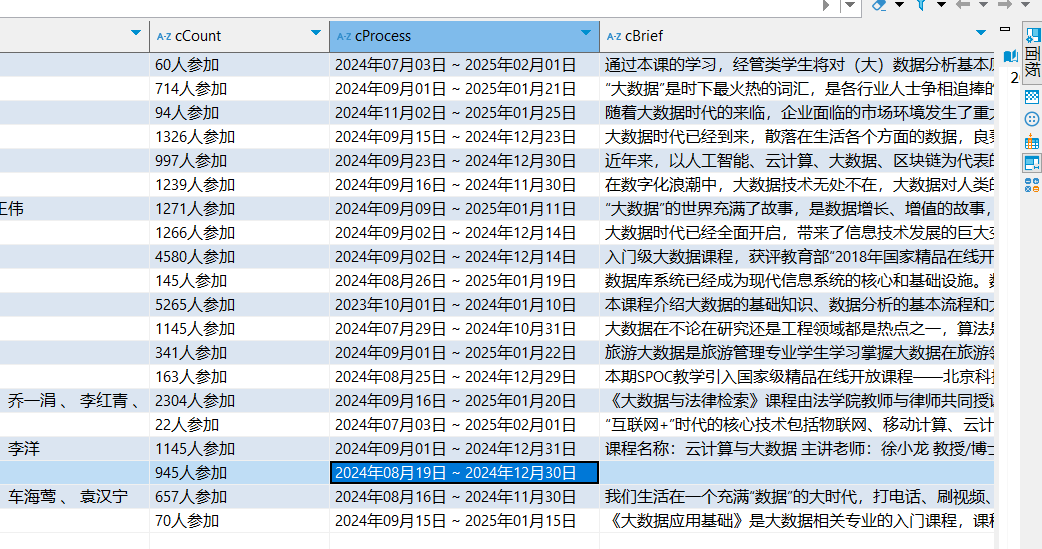
存储到数据库的课程信息
心得体会
通过这个实验我了解到了爬取时对于焦点的切换,切换到登录的frame和新跳转的页面,还有复习了实现用户模拟登录、爬取 Ajax 网页数据、以及等待 HTML 元素
完成这个实验用的时间比较多,主要是因为机房网络不好总是加载不出来,还有一开始不知道需要切换焦点一直调试又一直找不到,还有定位元素的时候要准确,可以直接使用浏览器”检查“的copy XPATH
作业③
华为云Flume日志采集实验
- 要求:
• 掌握大数据相关服务,熟悉 Xshell 的使用
• 完成文档 华为云_大数据实时分析处理实验手册-Flume 日志采集实验(部
分)v2.docx 中的任务,即为下面 5 个任务,具体操作见文档。
• 环境搭建:
·任务一:开通 MapReduce 服务
• 实时分析开发实战:
·任务一:Python 脚本生成测试数据
·任务二:配置 Kafka
·任务三: 安装 Flume 客户端
·任务四:配置 Flume 采集数据
输出:实验关键步骤或结果截图。 - 实验截图
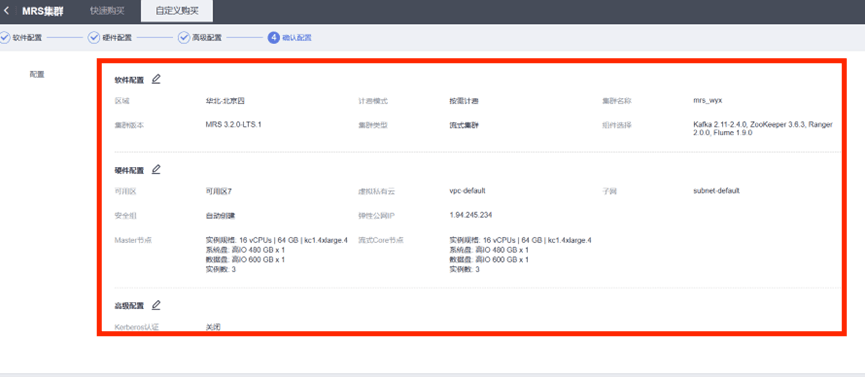
- 开通MapReduce服务,选择自定义购买
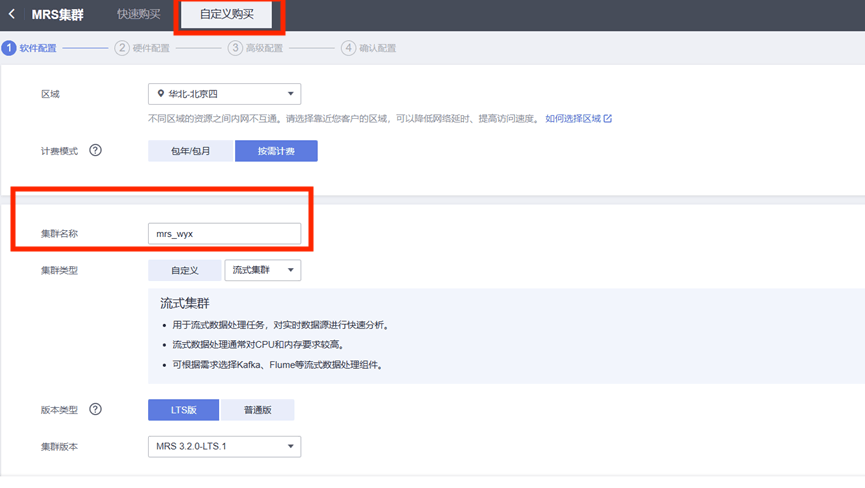
配置并购买
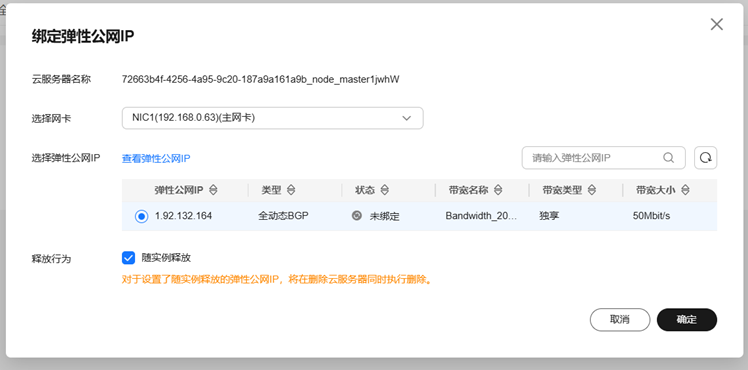
给集群的master节点绑定弹性IP
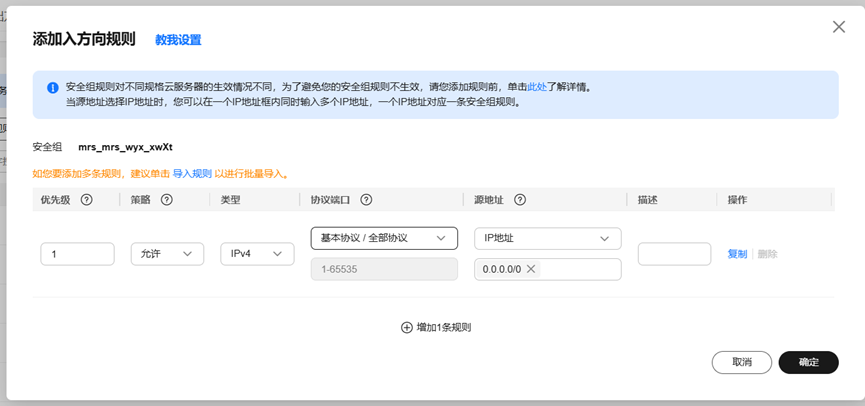
修改安全组规则
- Python脚本生成测试数据
进入PuTTY,使用master的弹性公网并登录master节点
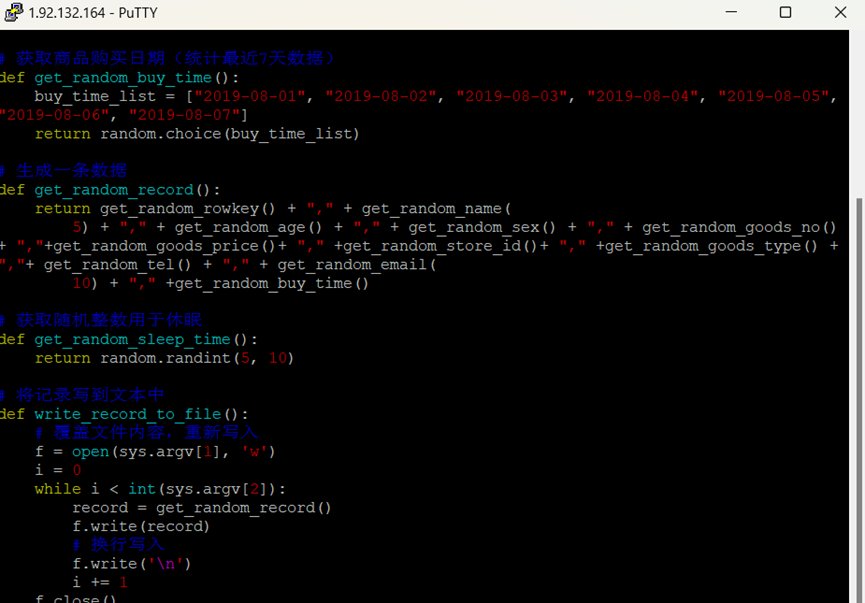
编写python脚本
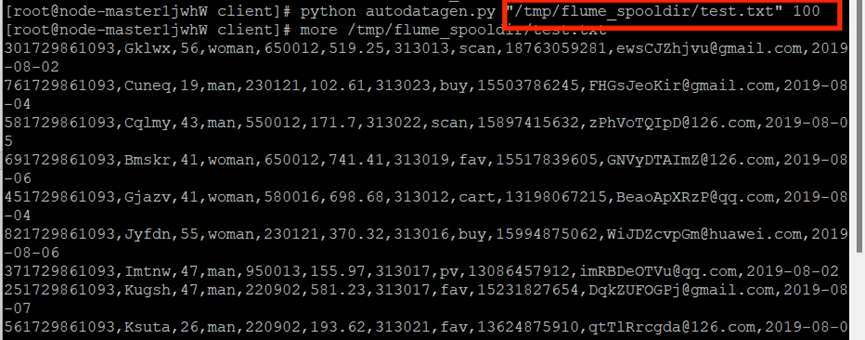
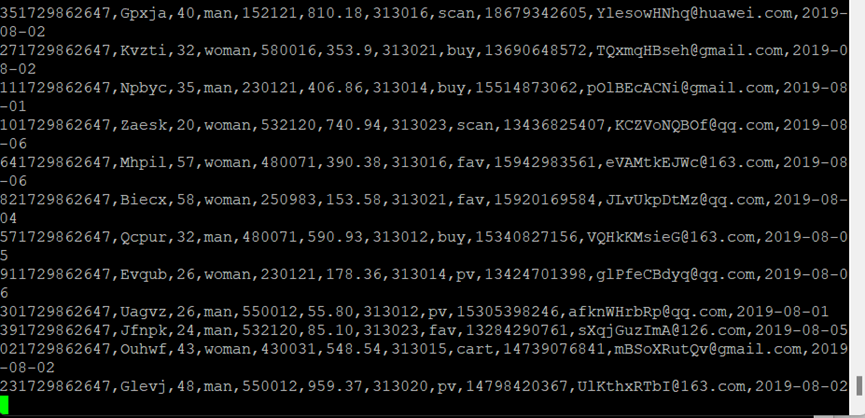
执行Python命令,测试生成100条数据并使用more命令查看生成的数据
- 配置Kafka
进入MRS Manager集群管理,在mrs概览中进入
下载kafka客户端
校验下载的客户端文件包,安装Kafka运行环境
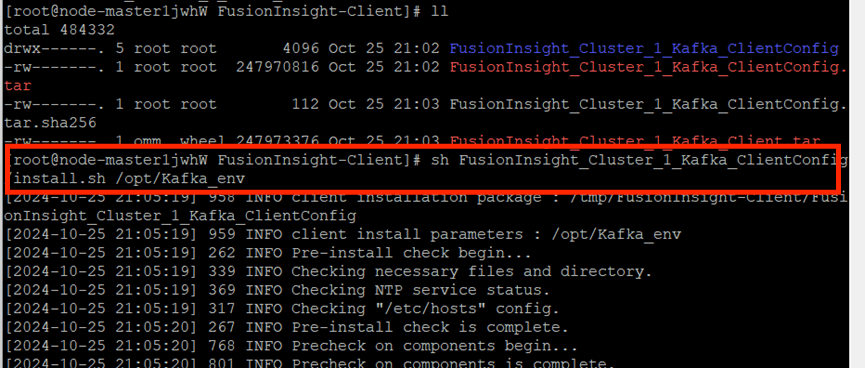
安装Kafka客户端,在kafka中创建topic

- 安装Flume客户端
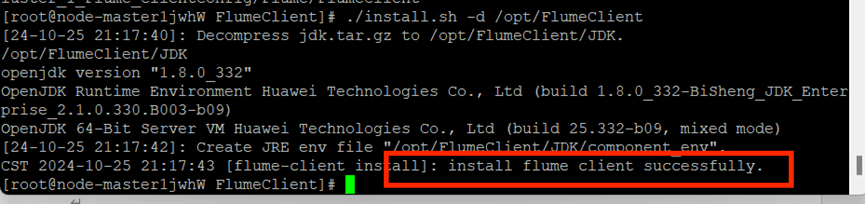
进入MRS Manager下载Flume客户端,校验下载的客户端文件包,安装Flume运行环境
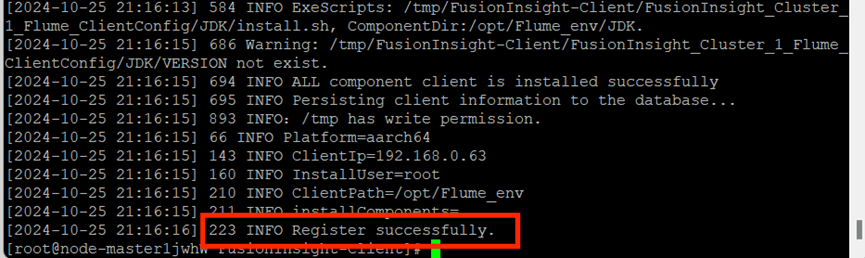
安装Flume客户端
- 配置Flume采集数据
进入Flume安装目录,在conf目录下编辑文件properties.properties
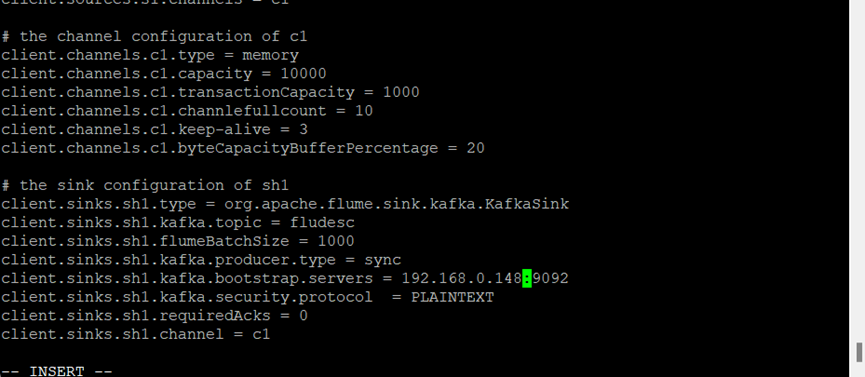
创建消费者消费kafka中的数据
执行命令
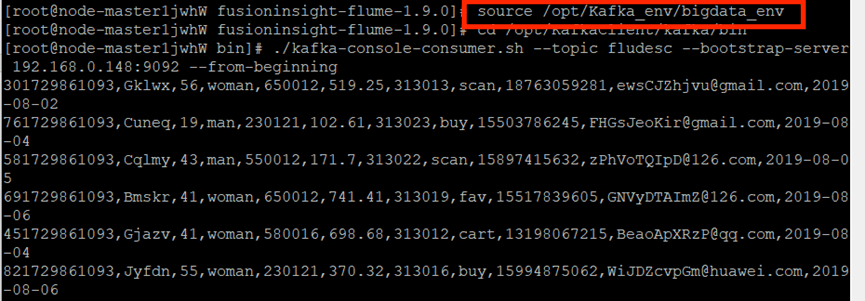
新建PuTTY窗口,进入Python脚本所在目录
执行python脚本,再生成一份数据,原窗口有数据产生
- 开通MapReduce服务,选择自定义购买
心得体会
通过本次学习初步认识了Flume,认识到Flume是一个分布式、可靠和高可用的海量日志聚合系统,可以用来收集、聚合和移动大量日志数据,支持数据的简单处理,并将其写入到各种数据接受方,它不仅仅是一个数据采集工具,它更是一个强大的数据处理平台,具有灵活性、可靠性和强大的数据处理能力。本次实验在华为云平台上实践了Flume日志采集,对该过程有了初步体会和认识。