尚硅谷Docker实战教程学习笔记
尚硅谷Docker实战教程学习笔记尚硅谷Docker实战教程学习笔记
我从没想过因为即将要学习dockerfile而激动,也因这激动而顿感羞愧。————20241029
- 尚硅谷Docker实战教程学习笔记
- 写在前面
- 1. Docker简介
- 2. Docker安装
- 3. Docker常用命令
- 4. Docker镜像
- 5. 本地镜像发布到阿里云
- 6. 本地镜像发布到私有库
- 7. Docker容器数据卷
- 8. Docker常规安装简介
- 9. Docker复杂安装说明
- 10. Dockerfile解析
- 11. Docker微服务实战
- 12. Docker网络
- 13. Docker-compose容器编排
- 14. Docker轻量级可视化工具Portainer
- 15. Docker容器监控之CAdvisor+InfluxDB+Granfana
写在前面
-
封面 | 摘要 | 关键词
尚硅谷Docker实战教程
docker 李英俊 尚硅谷 -
学习链接:尚硅谷Docker实战教程(docker教程天花板)
-
感想 | 摘抄 | 问题
-
什么是云原生:(我的理解)一切在云端,基于容器开发的都会打包push到registry中,然后pull下来进行使用
-
麒麟系统离线安装docker
-
开发流程:
graph LR 编码开发微服务-->上线部署容器化-->时时刻刻要监控-->devops -
面试题快速跳转:
- 谈谈docker虚悬镜像是什么?
- 谈谈docker exec和docker attach两个命令的区别?工作中用哪一个?
- 为什么Docker镜像要采用分层结构?
- 容器创建成功但是启不起来
- 用redis实现分布式存储的三种方式
-
1. Docker简介
-
是什么
-
为什么会有docker出现
系统平滑移植,容器虚拟化技术
Docker的出现使得Docker得以打破过去「程序即应用」的观念。透过镜像(images)将作业系统核心除外,运作应用程式所需要的系统环境,由下而上打包,达到应用程式跨平台间的无缝接轨运作。

-
docker的理念

-
Docker是基于Go语言实现的云开源项目
-
Docker的主要目标是:Build, Ship and Run Any App, Anywhere。也就是通过对应用组件的封装、分发、部署、运行等生命周期的管理,使用户的APP及其运行环境能够做到 一次镜像,处处运行
-
Docker解决了运行环境和配置问题的软件容器,方便做持续集成并有助于整体发布的容器虚拟化技术
-
-
容器与虚拟机比较
-
虚拟机(virtual machine)就是带环境安装的一种解决方案。
- 缺点:资源占用多,冗余步骤多,启动慢
-
由于前面虚拟机存在缺点,Linux发展出了另一种虚拟化技术:Linux容器(Linux Containers,LXC)。
-
Linux容器是与系统其他部分隔离开的一系列进程,从另一个镜像运行,并由该镜像提供支持进程所需的全部文件。容器提供的镜像包含了应用的所有依赖项,因而在从开发到测试再到生产的整个过程中,它都具有可移植性和一致性。
-
Docker容器是在操作系统层面上实现虚拟化,直接复用本地主机的操作系统,而传统虚拟机则是在硬件层面实现虚拟化。与传统的虚拟机相比,Docker优势体现为启动速度快,占用体积小。

-
-
总结
- 传统虚拟机技术是虚拟出一套硬件后,在其上运行一个完整的操作系统,在该系统上再运行所需应用进程;
- 容器内的应用进程直接运行于宿主的内核,容器内没有自己的内核且也没有进行硬件虚拟。因此容器要比传统虚拟机更为轻便;
- 每个容器之间互相隔离,每个容器有自己的文件系统,容器之间进程不会相互影响,能区分计算资源。
-
-
能干嘛
-
技术职级的变化:coder->programmer->software engineer->DevOps engineer
-
开发/运维(DevOps)新一代开发工程师
-
一次构建、随处运行
- 更快的应用交付和部署
- 更便捷的升级和扩缩容
- 更简单的系统运维
- 更高效的计算资源利用
-
Docker的应用场景

-
-
-
去哪儿下
- docker官网:http://www.docker.com/
- Docker Hub仓库:http://www.hub.docker.com/,安装docker镜像的仓库
2. Docker安装
-
前提说明
- Docker 并非是一个通用的容器工具,它依于已存在并运行的 Linux 内核环境。
- Docker 实质上是在已经运行的 Linux 下制造了个隔离的文件环境,因此它执行的效率几乎等同于所部署的 Linux 主机。
- 因此
Docker 必须部署在 Linux 内核的系统上,如果其他系统想部署 Docker 就必须安装一个虚拟 Linux 环境。 - 获取系统版本内核:
uname -r
-
docker的基本组成
-
镜像,image 类
Redis r1 = docker run 镜像类似鲸鱼背上的集装箱,就是一个容器实例
-
容器,container 实例
- 上述的 r1、r2、r3...多个实例
- 容器是用镜像创建的运行实例
- 可以看作是一个简易版的Linux环境(包括root用户权限、进程空间、用户空间和网络空间等)和运行在其中的应用程序。
-
仓库,repository 存放镜像的地方
- Maven仓库:放各种jar包
- Github仓库:放各种git项目
- Docker Hub:放各种镜像模板
-
小总结:image文件可以看作是容器的模板,Docker根据image文件生成容器的实例。同一个image文件,可以生成多个同时运行的容器实例。


- docker daemon:真正干活的,通过Socket连接从客户端访问,守护进程从客户端接收命令并管理运行在主机上的容器。
-
-
docker平台架构
-
docker是一个C/S模式的架构,后端是一个松耦合架构,众多模块各司其职

-
Docker运行的基本流程:
- 用户使用Docker Client与Docker Daemon建立通信,并发送请求给后者
- Docker Daemon作为Docker架构中的主体部分,首先提供Docker Server的功能,使其可以接收Docker Client的请求
- Docker Engine执行Docker内部的一系列工作,每一项工作都是以一个Job的形式存在
- Job的运行过程中,当需要容器镜像时,则从Docker Registry中下载镜像,并通过镜像管理驱动Graph driver将下载镜像以Graph的形式存储
- 当需要为Docker创建网络环境时,通过网络管理驱动Network driver创建并配置Docker容器网络环境
- 当需要限制docker容器运行资源或者执行用户指令等操作时,则通过Exec driver来完成
- Libcontainer是一项独立的容器管理包,Network driver以及Exec driver都是通过Libcontainer来实现具体对容器进行的操作
-
-
安装步骤
- 确定版本
- 卸载旧版本
- yum安装gcc相关
- 能上外网(CentOS7)
yum -y install gccyum -y install gcc-c++
- 安装需要的软件包
yum install -y yum-utils- 配置docker库:
yum-config-manager --add-repo https://xxx - 推荐使用阿里云的加速:
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo - 更新yum软件包索引:
yum makecache fast
- 安装docker:
yum install docker-ce docker-ce-cli containerd.io - 启动docker:
systemctl start docker - HelloWorld:
docker run hello-world、docker version- 本地没有hello-world,则会从远程库拉下来运行
- 卸载:
systemctl stop dockeryum remove docker-ce docker-ce-cli containerd.iorm -rf /var/lib/dockerrm -rf /var/lib/containerd
-
阿里云镜像加速
-
是什么:https://promotion.aliyun.com/ntms/act/kubernetes.html
-
注册账户,工具台,容器镜像服务,镜像工具,镜像加速器,获取加速器地址链接:https://cr.console.aliyun.com/cn-hangzhou/instances/mirrors
# 创建目录,将镜像配置反写回文件 sudo mkdir -p /etc/docker sudo tee /etc/docker/daemon.json <<-'EOF' {"registry-mirrors": ["https://[你自己的].mirror.aliyuncs.com"] } EOF# 重启docker sudo systemctl daemon-reload sudo systemctl restart docker
-
-
测试运行hello-world
-
docker run hello-world -
run到底干了什么

-
-
底层原理:为什么Docker会比VM虚拟机要快
-
docker有着比虚拟机更少的抽象层
由于docker不需要Hypervisor(虚拟机)实现硬件层面的虚拟化,运行在docker容器上的程序直接使用的都是实际物理机的硬件资源。因此在CPU、内存利用率上,docker将会在效率上有明显优势。
-
docker利用的是宿主机的内核,而不需要加载操作系统os内核
当新建一个容器时,docker不需要和和虚拟机一样重新加载一个操作系统内核。进而避免引寻、加载操作系统内核返回等比较费时费资源的过程,当新建一个虚拟机时,虚拟机软件需要加载OS,返回新建过程是分钟级别的。而docker由于直接利用宿主机的操作系统,则省略了返回过程,因此新建一个docker容器只需要几秒钟。

docker容器 虚拟机VM 操作系统 与宿主机共享OS 宿主机OS上运行虚拟机OS 存储大小 镜像小,便于存储与运输 镜像庞大(vmdk、vdi等) 运行性能 几乎无额外性能损失 操作系统额外的CPU、内存消耗 移植性 轻便、灵活,适用于Linux 笨重,与虚拟化技术耦合度高 硬件亲和性 面向软件开发者 面向硬件运维者 部署速度 快速,秒级 较慢,10s以上 -
3. Docker常用命令
-
帮助启动类命令
systemctl start docker:启动dockersystemctl stop docker:停止dockersystemctl restart docker:重启dockersystemctl status docker:查看docker状态systemctl enable docker:开机启动dockerdocker info:查看docker概要信息docker --help:查看docker总体帮助文档docker 具体命令 --help:查看docker命令帮助文档
-
镜像命令
-
docker images:列出本地主机上的镜像同一个仓库源可以有多个tag版本,代表这个仓库源的不同的版本,我们使用
REPOSITORY:TAG来定义不同的镜像。如果你不指定一个镜像的版本标签,例如你只使用 ubuntu,docker将默认使用 ubuntu:latest 镜像。REPOSITORY:表示镜像的仓库源 TAG:镜像的标签 IMAGE ID:镜像ID CREATED:镜像创建时间 SIZE:镜像大小OPTIONS说明:
-a:列出本地所有的镜像(含历史镜像层)-q:;只显示镜像ID
-
docker search 镜像名:默认是从hub.docker.com上检索镜像列表,一般选第一个官方认证过的,比较靠谱OPTIONS说明:
--limit:只列出N个镜像,默认25个,例如docker search --limit 5 redis
-
docker pull 镜像名:下载镜像,docker pull 镜像名字[:TAG],没有tag就下载最新版 -
docker system df:查看镜像/容器/数据卷所占的空间 -
docker rmi [-f] 镜像名/镜像ID:[强制]删除镜像- 删除多个镜像:
docker rmi -f id1 name2:tag2 - 删除全部镜像:
docker rmi -f $(docker images -qa)
- 删除多个镜像:
❓ 谈谈docker虚悬镜像是什么?
- 是什么:仓库名、标签都是
的镜像,俗称虚悬镜像 dangling image
📖 参考延申
虚悬镜像可能会在以下几种情况下产生:
- 构建过程中出现错误,导致镜像没有被正确标记。
- 用户忘记为新创建的镜像添加标签。
- 用户试图删除一个正在被使用的镜像,但该镜像仍有其他容器在使用。
虚悬镜像可能会带来一些问题:
- 无法找到正确的镜像版本:当用户试图运行一个虚悬镜像时,他们可能无法确定应该使用哪个版本的镜像。这可能导致应用程序运行在不同的环境中,或者在不同版本的代码上运行,从而导致兼容性问题。
- 无法进行有效的更新:虚悬镜像意味着用户无法对其进行更新。即使镜像内部的版本进行了升级,用户也无法通过简单地添加一个新标签来获取这个新版本的镜像。
- 占用存储空间:虽然虚悬镜像不会立即影响应用程序的运行,但是它们会一直占用存储空间,直到有人为它们添加标签。
如何解决虚悬镜像问题,我们可以采取以下几种方案:
- 检查并重新标记镜像:如果发现虚悬镜像,可以尝试查找出现问题的构建过程,并修复其中的错误。然后为镜像添加一个新的标签,以确保用户能够找到正确的版本。
- 使用Dockerfile:Dockerfile可以帮助我们自动化镜像的构建过程,并确保每次构建的镜像都是正确且可重复的。通过编写详细的Dockerfile,我们可以确保每次构建的镜像都带有正确的标签。
- 定期清理虚悬镜像:Docker提供了一些命令来帮助用户管理虚悬镜像,例如
docker rmi --force可以强制删除虚悬镜像。然而,最好的方法还是定期检查并清理这些无用的虚悬镜像,以节省存储空间。
-
-
容器命令
有镜像才能创建容器,这是根本前提
-
docker run 镜像名:新建+启动容器,启动交互式容器(前台命令行)--name=名字:容器新名字,为容器指定一个名称-d:后台运行容器并返回容器ID,启动守护式容器(后台运行)-i:以交互模式运行容器,通常与-t同时使用-t:为容器重新分配一个伪输入中断,通常与-i同时使用,也称交互式容器(前台有伪终端,等待交互)常用:docker run -it ubuntu /bin/bash(以交互模式启动一个容器,在容器内执行 /bin/bash 命令,退出:exit)-P:随机端口映射,大P-p:指定端口映射,小p。例:-p 6379:6379是指外面访问docker的6379服务(宿主机)被映射到容器内的6379服务(docker )
-
docker ps:列出当前所有正在运行的容器-a:列出当前所有正在运行的容器+历史上运行过的-l:显示最近创建的容器-n:显示最近n个创建的容器-q:静默模式,只显示容器编号
-
容器的退出
exit:run进去的容器,exit退出,容器停止(docker ps就没啦)ctrl+p+q:run进去的容器,ctrl+p+q,容器不停止
-
docker start 容器id/容器名:启动已经停止运行的容器 -
docker restart 容器id/容器名:重启容器 -
docker stop 容器id/容器名:停止容器 -
docker kill 容器id/容器名:强制停止容器 -
docker rm [-f] 容器id/容器名:[强制]删除容器一次性删除多个实例:
docker rm -f $(docker ps -a -q)docker ps -a -q | xargs docker rm
-
-
其他
-
启动守护式容器(后台服务器)
-
在大部分得场景下,我们希望docker的服务是在后台运行的,,我们可以通过
-d指定容器的后台运行模式 -
docker run -d 容器名问题:直接用
docker run 容器名启动后用docker ps -a进行查看发现容器已经退出了,需要注意很重要的一点是,Docker容器后台运行,就必须有一个前台进程。容器运行的命令如果不是那些一直挂起的命令(比如运行top,tail),就是会自动退出的。这是docker的机制问题,最佳的解决方案是:**将你要运行的程序以前台进程的形式运行,常见就是命令行模式
-it**,表示我还有交互操作,别中断。 -
以redis为例,用前台交互式的启动肯定不行:
docker run -it redis;所以要用后台守护式启动:docker run -d redis
-
-
docker log 容器id:查看容器日志 -
docker top 容器id:查看容器内运行的进程 -
docker inspect 镜像名/容器id:查看镜像配置/查看容器内部细节 -
进入正在运行的容器,并以命令行交互
docker exec -it 容器id bashShell- 重新进入还有一个命令:
docker attach 容器id
❓ 上述两个命令的区别?工作中用哪一个?
- attach直接进入容器启动命令的终端,不会启动新的进程,用exit退出,会导致容器的停止
- exec是在容器中打开新的终端,并且可以启动新的进程,用exit退出,不会导致容器的停止
推荐在工作中使用
docker exec命令,因为退出容器终端也不会导致容器的停止一般用
-d后台启动的程序,再用docker exec进入对应容器实例 -
docker cp 容器id:容器内路径 目的主机路径:从容器内拷贝文件到主机上 -
导入导出容器:
- export 导出容器的内容留作为一个tar归档文件[对应import命令]
- import 从tar包中的内容创建一个新的文件系统再导入为镜像[对应export]
- 案例
docker export 容器id > 文件名.tarcat 文件名.tar | docker import - 镜像用户/镜像名:镜像版本号,例如:cat abcd.tar | docker import - atguigu/ubuntu:3.7
☀️ docker save和docker export的区别
📖 docker知识点大全
docker save保存的是镜像(image),docker export保存的是容器(container);docker load用来载入镜像包,docker import用来载入容器包,但两者都会恢复为镜像;docker load不能对载入的镜像重命名,而docker import可以为镜像指定新名称。
-
-
小结

4. Docker镜像
-
是什么:镜像是一种轻量级、可执行的独立软件包,它包含运行某个软件所需的所有内容,我们把应用程序和配置依赖打包好形成一个可交付的运行环境(包括代码、运行时需要的库、环境变量和配置文件等),这个打包好的运行环境就是image镜像文件。
-
分层的镜像:UnionFS(联合文件系统),Union文件系统(UnionFS)是一种分层、轻量级并且高性能的文件系统,它支持对文件系统的修改作为一次提交来一层层的叠加,同时可以将不同目录挂载到同一个虚拟文件系统下(unite several directories into a single virtual filesystem)。Union 文件系统是 Docker镜像的基础。镜像可以通过分层来进行继承,基于基研镜像(没有父镜像),可以制作各和具体的应用镜像。
特性:一次同时加载多个文件系统,但从外面看起来,只能看到一个文件系统,联合加载会把各层文件系统叠加起来,这样最终的文件系统会包含所有底层的文件和目录
-
Docker镜像加载原理:docker的镜像实际上由一层一层的文件系统组成,这种层级的文件系统UnionFS。
bootfs(boot file system)主要包含bootloader和kernel, bootloader主要是引导加载kernel,Linux刚启动时会加载bootfs文件系统,在Docker镜像的最底层是引导文件系统bootfs。这一层与我们典型的Linux/unix系统是一样的,包含boot加载器和内核。当boot加载完成之后整个内核就都在内存中了,此时内存的使用权已由bootfs转交给内核,此时系统也会卸载bootfs。
rootfs (root file system),在bootfs之上,包含的就是典型 Linux 系统中的
/dev,/proc,/bin,/etc等标准目录和文件。rootfs就是各种不同的操作系统发行版,比如Ubuntu,Centos。
对于一个精简的OS,rootfs可以很小,只需要包括最基本的命令、工具和程序库就可以了,因为底层直接用Host和Kernel,自己只需要提供rootfs就行了。由此可见对于不同的linux发行版,bootfs基本是一致的,rootfs会有差别,因此不同的发行版可以公用bootfs。
❓ 为什么Docker镜像要采用分层结构?
镜像分层最大的一个好处就是共享资源,方便复制迁移,就是为了复用。
比如说有多个镜像都从相同的 base 镜像构建而来,那么 Docker Host 只需在磁盘上保存一份 base 镜像;同时内存中也只需加载一份 base 镜像,就可以为所有容器服务了。而且镜像的每一层都可以被共享。
-
重点理解
- Docker镜像层都是只读的,容器层是可写的
- 当容器启动时,一个新的可写层被加载到镜像的顶部。这一层通常被称作“容器层",“容器层"之下的都叫“镜像层”。
-
Docker镜像commit操作案例
-
docker commit提交容器副本,使之成为一个新的镜像 -
docker commit -m="提交的描述信息" -a="作者" 容器ID 要创建的目标镜像名称[:标签名]docker commit -m="vim cmd add ok" -a="huowang" de60078e6a9a huowang/myubuntu:1.0 docker images
-
-
小结
Docker中的镜像分层,支持通过扩展现有镜像,创建新的镜像。类似Java继承于一个Base基础类,自己再按需扩展。新镜像是从 base 镜像一层一层叠加生成的。每安装一个软件,就在现有镜像的基础上增加一层。

5. 本地镜像发布到阿里云
-
本地镜像发布到阿里云流程

-
镜像的生成方法
- 方法1:基于当前容器创建一个新的镜像,新功能增强:
docker commit [OPTIONS] 容器ID [REPOSITORY[:TAG]] - 方法2:Dockerfile
- 方法1:基于当前容器创建一个新的镜像,新功能增强:
-
将本地镜像推送到阿里云
-
选择控制台,进入容器镜像服务
-
选择个人实例
-
命名空间-创建命名空间
-
仓库名称-创建镜像仓库-选择命名空间-创建仓库名称-创建本地仓库-创建镜像仓库
-
进入管理界面获得脚本
-
将镜像推送到阿里云registry
# 登录 docker login --username=你的用户名 registry.cn.qingdao.aliyuncs.com # 输入密码,Login Succeeded就是登录成功 docker tag [ImageId,即镜像id] registry.cn.qingdao.aliyuncs.com/命名空间/仓库名:[镜像版本号] docker push registry.cn.qingdao.aliyuncs.com/命名空间/仓库名:[镜像版本号]
-
-
将阿里云上的镜像下载到本地
docker login --username=你的用户名 registry.cn.qingdao.aliyuncs.com docker pull registry.cn.qingdao.aliyuncs.com/命名空间/仓库名:[镜像版本号]
6. 本地镜像发布到私有库
-
是什么:官方是
hub.docker.com,国内一般选择阿里云,类似github,建立企业自己的github。Docker Registry 是官方提供的工具,用于构建私有镜像仓库。 -
将本地镜像推送到私有库
-
下载镜像 Docker Registry:
docker pull registry -
运行私有库 Registry,相当于本地有个私有的Docker Hub:
docker run -d -p 5000:5000 -v /主机路径:/容器路径 --privileged=true registry我的实践:
docker run -d -p 5005:5000 -v /mydocker:/tmp/registry --privileged=true registry,这里端口号试了下用5005做映射,看看好不好使-p 主机端口映射到容器端口
-v 将主机路径"/host/path"挂载到容器路径"/container/path",这样容器中的应用就可以访问"/container/path"目录,并且任何对这个路径的更改都会反映在主机的"/host/path"上
默认情况下,仓库被创建在容器的
/var/lib/registry目录下,建议自行用容器卷映射,方便宿主机联调 -
演示:创建一个新镜像,ubuntu安装ifconfig命令
apt install net-tools- 从Hub上下载ubuntu镜像到本地并成功运行
- 原始的Ubuntu镜像是不带着ifconfg命令的
- 外网连通的情况下,安装ifconfg命令并测试通过
- 安装完成后,commit我们自己的新镜像
- 启动我们的新镜像并和原来的对比
-
curl验证私服库上有什么镜像
- 根据上面的操作,pull并run了一个registry的容器;又打包了一个镜像,然后run,测试成功
curl -XGET http://...:5000/v2/_catalog- 我的实践:
curl -XGET http://...:5005/v2/_catalog
-
将新镜像修改符合私服规范的Tag
docker tag 镜像名称[:TAG] http://...:5000/镜像名称[:TAG]相当于把本机的镜像克隆了一份,按规范命名
我的实践:
- 先把容器commit成镜像:
docker commit -m="my ubuntu" -a="huowang" huowang huowang/myubuntu:1.0 - 再修改tag:
docker tag huowang/myubuntu:1.0 ...:5005/huowangos:1.0
- 先把容器commit成镜像:
-
修改配置文件使之支持http
-
vim /etc/docker/daemon.json,我们曾经在这里配置过阿里云的镜像"registry-mirrors": ["https://xxx.mirrors.aliyuncs.com"] -
后面再加一个:
"insecure-registries": ["你的registry ip地址:5000"] -
docker默认不允许http方式推送镜像,通过配置选项来取消这个限制。修改完如果不生效,建议重启docker
我的实践:
- 如果直接push,会报错:
GET ...: http: server gave HTTP response to HTTPS client - 所以需要在
daemon.json中增加对应的ip从而支持 HTTP - 然后重启docker
systemctl restart docker,注意,这步操作会把你所有的镜像给关了,很要命的,小心点。 - 最终push:
docker push ...:5005/huowangos:1.0
-
-
push推送到私服库:
docker push 镜像名称[:TAG],其实这里的镜像名称就是:http://...:5005/镜像名称[:TAG]- curl验证私服库上有什么镜像:
curl -XGET http://...:5005/v2/_catalog,应该就有啦
- curl验证私服库上有什么镜像:
-
pull到本地运行:
docker pull http://...:5005/镜像名称[:TAG]
-
7. Docker容器数据卷
-
🚫 坑:容器卷记得加入
--privileged=true否则,Docker挂载主机目录访问会出现
cannot open directory: Permission denied -
参数v:默认情况下,仓库被创建在容器的
/var/lib/registry目录下,建议自行用容器卷映射,方便宿主机联调 -
是什么
- 有点类似我们redis里面的rdb和aof文件
- 将docker容器内的数据保存进宿主机的磁盘中
- 运行一个带有容器卷存储功能的容器实例
卷是目录或文件,存在于一个或多个容器中,由docker挂载到容器,但不属于联合文件系统,因此能够绕过 Union File System 提供一些用于持续存储或共享数据的特性。卷的设计目的就是
数据的持久化,完全独立于容器的生存周期,因此Docker不会在容器删除时删除其挂载的数据卷docker run -it -privileged=true -v /宿主机绝对路径目录:/容器内目录 镜像名 -
能干嘛:将运用与运行的环境打包镜像,run后形成容器实例运行,但是我们对数据的要求希望是持久化的。Docker容器产生的数据,如果不备份,那么当容器实例删除后,容器内的数据自然也就没有了。为了能保存数据在docker中我们使用卷。
特点:
- 数据卷可在容器之间共享或重用数据
- 卷中的更改可以直接实时生效
- 数据卷中的更改不会包含在镜像的更新中
- 数据卷的生命周期一直持续到没有容器使用它为止
-
案例:
-
宿主vs容器之间映射添加容器卷,直接命令添加
-
docker run -it -privileged=true -v /宿主机绝对路径目录:/容器内目录 镜像名 -
查看数据卷是否挂载成功:可以在主机上看到
/mydocker,然后启动容器docker exec -it 容器id /bin/sh(因为没有bash),在容器的路径中看到/tmp/registry -
也可以用
docker inspect 容器id,查看mount字段中的内容"Mounts": [{"Type": "bind","Source": "/mydocker","Destination": "/tmp/registry","Mode": "","RW": true,"Propagation": "rprivate"},... ] -
注意:如果把容器
docker stop之后,在宿主机路径下增加文件,重启容器之后,容器内部依然能看到对应的文件增加
-
-
读写规则映射添加说明
- 读写(默认)
docker run -it --privileged=true -v /宿主机绝对路径目录:/容器内目录:rw 镜像名- rw为默认值
- 只读
- 容器实例内部被限制,只能读取不能写
docker run -it --privileged=true -v /宿主机绝对路径目录:/容器内目录:ro 镜像名- 宿主机写如内容可以同步给容器,容器可以读取到
- 读写(默认)
-
卷的继承和共享
- 容器1完成和宿主机的映射
- 容器2继承容器1的卷规则:
docker run -it --privileged=true --volumnes-from 父类容器 --name u2 ubuntu,其实这里的--volumnes就是-v - 实现:父容器、子容器、宿主机文件共享
- 简单来说,无论谁死都不影响文件传递,一主二从
-
8. Docker常规安装简介
-
总体步骤
- 搜索镜像
- 拉取镜像
- 查看镜像
- 启动镜像,服务端口映射
- 停止容器
- 移除容器
-
安装tomcat
- docker hub上查找tomcat镜像:
docker search tomcat - 从docker hub上拉去tomcat镜像到本地:
docker pull tomcat - docker images查看是否有拉取到的tomcat
- 使用tomcat镜像创建容器实例(也叫运行镜像):
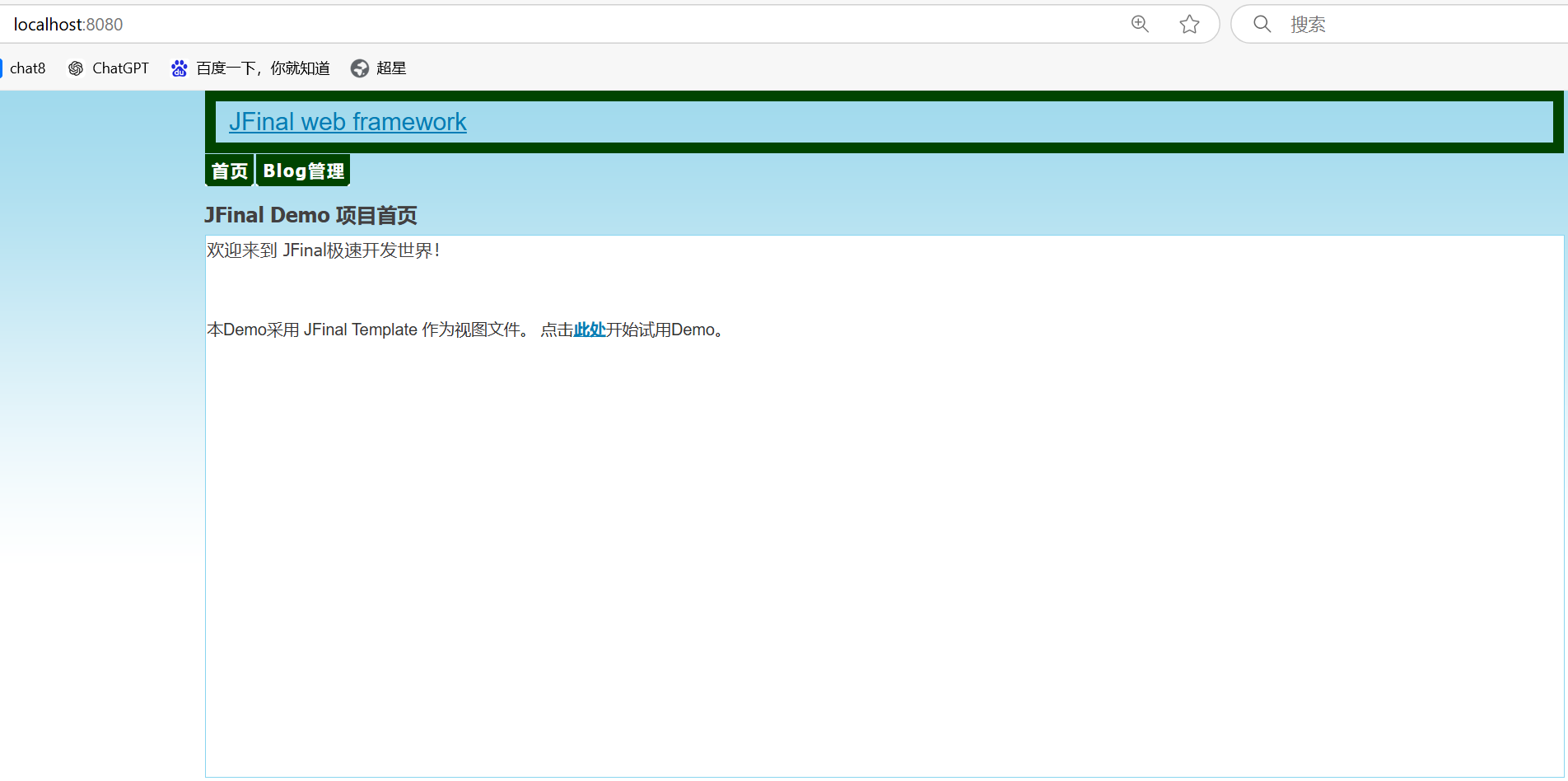
docker run -it -p 8080:8080 --name t1 tomcat - 访问 🐱 首页
- 问题:最后发现访问报错404异常
- 解决:
- 可能没有映射端口或者没有关闭防火墙
- 把webapps.dist目录换成webapps
- 先成功启动tomcat
- 查看webapps文件夹查看为空
- docker hub上查找tomcat镜像:
-
安装mysql
-
docker search mysql -
docker pull mysql:8.0.29 -
运行:
-
docker run -p 33061:3306 -e MYSQL_ROOT_PASSWORD=root -d mysql:8.0.29 -
docker exec -it 3ce95ebd240c bashbash-4.4# mysql -uroot -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 9 Server version: 8.0.29 MySQL Community Server - GPLCopyright (c) 2000, 2022, Oracle and/or its affiliates.Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners.Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sys | +--------------------+ 4 rows in set (0.00 sec)mysql> create database db01; Query OK, 1 row affected (0.00 sec)mysql> use db01; Database changed mysql> create table t1(id int, name varchar(32)); Query OK, 0 rows affected (0.01 sec)mysql> insert into t1 values(1, 'zhangsan')-> ; Query OK, 1 row affected (0.01 sec)mysql> select * from t1; +------+----------+ | id | name | +------+----------+ | 1 | zhangsan | +------+----------+ 1 row in set (0.00 sec)mysql> -
用工具连接也没问题
-
问题:
- 插入中文数据报错:docker上默认字符集编码隐患
- 删除容器之后,里面的mysql数据怎么办
-
-
mysql实战:
-
新建mysql容器实例:
docker run -d -p 33061:3306 --privileged=true -v /data/litian_test/mysql/log:/var/log/mysql -v /data/litian_test/mysql/data:/var/liv/mysql -v /data/litian_test/mysql/conf:/etc/mysql/conf.d -e MYSQL_ROOT_PASSWORD=root --name ltmysql mysql:8.0.29 -
在宿主机
/data/litian_test/mysql/conf新建my.cnf:通过容器卷同步给mysql容器实例[client] default_character_set = utf8 [mysqld] collation_server = utf8_general_ci character_set_server = utf8 -
重新启动mysql容器实例再重新进入并查看字符编码:
docker restart ltmysqlmysql> show variables like 'character%'; +--------------------------+--------------------------------+ | Variable_name | Value | +--------------------------+--------------------------------+ | character_set_client | utf8mb3 | | character_set_connection | utf8mb3 | | character_set_database | utf8mb3 | | character_set_filesystem | binary | | character_set_results | utf8mb3 | | character_set_server | utf8mb3 | | character_set_system | utf8mb3 | | character_sets_dir | /usr/share/mysql-8.0/charsets/ | +--------------------------+--------------------------------+ 8 rows in set (0.01 sec) -
结论:docker安装完MySQL并run出容器后,建议请先修改完字符集编码后再新建mysql库-表-插数据
-
-
删除容器后,里面的mysql数据怎么办:数据不丢失
-
-
安装redis
-
拉取redis镜像到本地
-
容器卷记得加
--privileged=true -
宿主机新建目录
/app/redis:mkdir -p /app/redis -
将一个
redis.conf文件模板拷贝进/app/redis目录下 -
/app/redis目录下修改redis.conf文件(默认出厂的原始是redis.conf)- 开启redis密码验证(可选):
requirepass 123 - 允许redis外地连接(必须):
bind 127.0.0.1 ::1和bind 127.0.0.1这两行的注释取消 - 注释
daemonize yes,或者设置daemonize no,因为该配置和docker run中 -d 参数冲突,会导致容器一直启动失败 - 开启redis数据持久化(可选):
appendonly yes - 开启外部访问链接(可选):
protected-mode no,关闭保护模式
- 开启redis密码验证(可选):
-
创建容器,运行镜像:
docker run -p 63791:6379 --name ltredis --privileged=true -v /app/redis/redis.conf:/etc/redis/redis.conf -v /app/redis/data:/data -d redis:6.0.8 redis-server /etc/redis/redis.conf注意:这里不是
bash了,而是redis-server xxx测试效果:
KAZ0VLGPT01:/app/redis # docker exec -it ltredis /bin/bash root@1843deb637b4:/data# redis-cli 127.0.0.1:6379> set k1 v1 OK 127.0.0.1:6379> get k1 "v1" 127.0.0.1:6379> ping PONG 127.0.0.1:6379> select 15 OK 127.0.0.1:6379[15]> -
验证redis是按照指定的conf启动的:
-
select 15的结果是ok的 -
退出后修改conf中
databases 16为databases 10 -
重启redis服务:
docker restart ltredis -
进入容器内测试是否超出index,则为修改成功
KAZ0VLGPT01:/app/redis # docker exec -it ltredis bash root@1843deb637b4:/data# redis-cli 127.0.0.1:6379> get k1 "v1" 127.0.0.1:6379> select 3 OK 127.0.0.1:6379[3]> select 15 (error) ERR DB index is out of range
-
-
-
安装nginx:见后续Portainer
9. Docker复杂安装说明
-
安装mysql主从复制
-
主从复制原理(跳过不讲)
-
做下一步之前的建议
-
👿 直接用mysql:5.7的镜像,会报错容器起不起来,这个问题在下面步骤中解释了,不再细说,但是我发现如果指定容器版本
mysql:5.7.29,就没有出现如下问题,更无需修复,所以建议在执行以下代码时,将所有5.9改为5.9.29 -
👿 在重启mysql容器之后,再进去,输入用户名和密码的时候发现:
ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (2)这个问题很玄学,先不要去百度,退出容器之后再进一次发现又好了,就很奇怪。。。最后是内存不够
-
👿 注意
my.cnf千万别写成my.conf,切记切记,血的教训
-
-
主从搭建步骤
-
新建服务器容器实例3307:
docker run -p 3307:3306 --name mysql-master --privileged=true -v /mydata/mysql-master/log:/var/log/mysql -v /mydata/mysql-master/data:/var/lib/mysql -v /mydata/mysql-master/conf:/etc/mysql -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7⚠️ 注意:在这一步可能会报错,容器创建成功但是启不起来,查看容器报错内容:
docker logs mysql-master发现:[ERROR] [Entrypoint]: mysqld failed while attempting to check configcommand was: mysqld --verbose --help --log-bin-index=/tmp/tmp.WHijR591XAmysqld: Can't read dir of '/etc/mysql/conf.d/' (Errcode: 2 - No such file or directory) mysqld: [ERROR] Fatal error in defaults handling. Program aborted!📖 原因分析:官方的配置文件已经不放在/etc/mysql底下了
⛵ 解决方案:
-
先创建一个简单的mysql容器实例:
docker run -p 3307:3306 --name mysql-master -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7 -
复制里面的
/etc/mysql文件夹:docker cp mysql-master:/etc/mysql/. /mydata/mysql-master/conf -
删除这个临时容器:
docker rm -f mysql-master -
重新启动原始命令
-
-
进入
/mydata/mysql-master/conf目录下新建my.conf,插入以下内容[mysqld] ## 设置server_id,同一局域网中需要唯一 server_id=101 ## 指定不需要同步的数据库名称 binlog-ignore-db=mysql ## 开启二进制日志功能 log-bin=mall-mysql-bin ## 设置二进制日志使用内存大小(事务) binlog_cache_size=1M ## 设置使用的二进制日志格式(mixed,statement,row) binlog_format=mixed ## 二进制日志过期清理时间。默认值为0,表示不自动清理。 expire_logs_days=7 ## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。 ## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致 slave_skip_errors=1062 -
修改完配置后重启master实例:
docker restart mysql-master -
进入mysql-master容器
KAZ0VLGPT01:/mydata/mysql-master/conf # docker exec -it mysql-master bash bash-4.2# mysql -uroot -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 2 Server version: 5.7.44 MySQL Community Server (GPL)Copyright (c) 2000, 2023, Oracle and/or its affiliates.Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners.Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.mysql> -
master容器实例内创建数据同步用户
# 新建用户 create user 'slave'@'%' identified by '123456'; # 授权 grant replication slave, replication client on *.* to 'slave'@'%'; -
新建从服务器容器实例3308
docker run -p 3308:3306 --name mysql-slave --privileged=true -v /mydata/mysql-slave/log:/var/log/mysql -v /mydata/mysql-slave/data:/var/lib/mysql -v /mydata/mysql-slave/conf:/etc/mysql -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7 -
进入
/mydata/mysql-slave/conf目录下新建my.conf,插入以下内容[mysqld] ## 设置server_id,同一局域网中需要唯一 server_id=102 ## 指定不需要同步的数据库名称 binlog-ignore-db=mysql ## 开启二进制日志功能,以备Slave作为其它数据库实例的Master时使用 log-bin=mall-mysql-slave1-bin ## 设置二进制日志使用内存大小(事务) binlog_cache_size=1M ## 设置使用的二进制日志格式(mixed,statement,row) binlog_format=mixed ## 二进制日志过期清理时间。默认值为0,表示不自动清理。 expire_logs_days=7 ## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。 ## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致 slave_skip_errors=1062 ## relay_log配置中继日志 relay_log=mall-mysql-relay-bin ## log_slave_updates表示slave将复制事件写进自己的二进制日志 log_slave_updates=1 ## slave设置为只读(具有super权限的用户除外) read_only=1 -
修改完配置后重启slave实例:
docker restart mysql-slave -
在主数据库中查看主从同步状态:
show master status;(👿 真的能看到,如果是empty set,看看是不是配置文件的名称或者内容有问题),并且也可以通过show variables like '%log_bin%';看log_in是否开启mysql> show master status; +------------------------------+----------+--------------+------------------+-------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +------------------------------+----------+--------------+------------------+-------------------+ | mall-mysql-slave1-bin.000001 | 154 | | mysql | | +------------------------------+----------+--------------+------------------+-------------------+ 1 row in set (0.01 sec) -
进入mysql-slave容器中:
docker exec -it mysql-slave bash -
在从数据库中配置主从复制
change master to master_host='10.10.102.111', master_user='slave', master_password='123456', master_port=3307, master_log_file='mall-mysql-bin.000001', master_log_pos=154, master_connect_retry=30;- master_host:主数据库的IP地址;
- master_port:主数据库的运行端口;
- master_user:在主数据库创建的用于同步数据的用户账号;
- master_password:在主数据库创建的用于同步数据的用户密码;
- master_log_file:指定从数据库要复制数据的日志文件,通过查看主数据的状态,获取File参数;重要,从master status中拿到的数据
- master_log_pos:指定从数据库从哪个位置开始复制数据,通过查看主数据的状态,获取Position参数;重要,从master status中拿到的数据
- master_connect_retry:连接失败重试的时间间隔,单位为秒
-
在从数据库中查看主从同步状态:
show slave status \G;mysql> show slave status \G; *************************** 1. row ***************************Slave_IO_State:Master_Host: 10.10.102.111Master_User: slaveMaster_Port: 3307Connect_Retry: 30Master_Log_File: mall-mysql-bin .000001Read_Master_Log_Pos: 154Relay_Log_File: mall-mysql-relay-bin.000001Relay_Log_Pos: 4Relay_Master_Log_File: mall-mysql-bin .000001Slave_IO_Running: NoSlave_SQL_Running: NoReplicate_Do_DB:Replicate_Ignore_DB:Replicate_Do_Table:Replicate_Ignore_Table:Replicate_Wild_Do_Table:Replicate_Wild_Ignore_Table:Last_Errno: 0Last_Error:Skip_Counter: 0Exec_Master_Log_Pos: 154Relay_Log_Space: 154Until_Condition: NoneUntil_Log_File:Until_Log_Pos: 0Master_SSL_Allowed: NoMaster_SSL_CA_File:Master_SSL_CA_Path:Master_SSL_Cert:Master_SSL_Cipher:Master_SSL_Key:Seconds_Behind_Master: NULL Master_SSL_Verify_Server_Cert: NoLast_IO_Errno: 0Last_IO_Error:Last_SQL_Errno: 0Last_SQL_Error:Replicate_Ignore_Server_Ids:Master_Server_Id: 0Master_UUID:Master_Info_File: /var/lib/mysql/master.infoSQL_Delay: 0SQL_Remaining_Delay: NULLSlave_SQL_Running_State:Master_Retry_Count: 86400Master_Bind:Last_IO_Error_Timestamp:Last_SQL_Error_Timestamp:Master_SSL_Crl:Master_SSL_Crlpath:Retrieved_Gtid_Set:Executed_Gtid_Set:Auto_Position: 0Replicate_Rewrite_DB:Channel_Name:Master_TLS_Version: 1 row in set (0.01 sec)Slave_IO_Running: No、Slave_SQL_Running: No表示还没开始 -
在从数据库中开启主从同步:
start slave; -
查看从数据库状态发现已经同步:
show slave status \G;Slave_IO_Running: Yes、Slave_SQL_Running: Yes表示成功👿 如果是发现Slave_IO为No,Slave_SQL为Yes
🚡 可能是
master_log_file文件名没写对,比如多了一个空格啥的 -
主从测试复制
- 主机新建库、使用库、新建表、插入数据
- 从机使用库、查看记录
结果表明:主机创建的表和数据,从机可以看到。
-
-
-
安装redis集群:cluster(集群)模式-docker版,哈希槽分区进行亿级数据存储
🦊 面试题:1-2亿数据需要缓存,请问如何设计这个存储案例
🏹 回答:单机单台100%不可能,肯定是分布式存储,用redis如何落地?(上述问题阿里P6-P7工程案例和场景设计类必考题目,一般业界有3种解决方案)
-
哈希取余分区
2亿条记录就是2亿个kv,我们单机不行必须要分布式多机,假设有3台机器构成一个集群,用户每次读写操作都是根据公式:$hash(key)%N$个机器台数,计算出哈希值,用来决定数据映射到哪一个节点上。

优点:简单粗暴,直接有效。只需要预估好数据规划好节点,就能保证一段时间的数据支撑。使用HASH算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求(并维护这些请求的信息),起到负载均衡+分而治之的作用。
缺点:扩缩容时比较麻烦,不管缩容还是扩容,都会比较麻烦,因为一旦机器数量发生了变化,原本key的映射关系就要全部重新计算,如果需要弹性扩容或者故障停机的情况下,原来的取模公式就会发生变化,这时取余的结果就会发生很大变化,所以会导致全部数据要重新洗牌。
-
一致性哈希算法分区
-
是什么:这个算法在1997年就被提出了,设计的目标就是为了解决分布式缓存数据变动和映射的问题。当服务器的个数发生变动时,尽量减少影响客户端到服务器的映射关系。
-
能干嘛:当服务器个数发生变动时,尽量减少影响客户端到服务器的映射关系。
-
3大步骤:
-
算法构建一致性哈希环
一致性哈希算法必然有个hash函数,并按照算法产生hash值,这个算法的所有可能哈希值会构成一个全量集,这个集合可以成为一个hash空间 [0, 2 ^ 32 -1],这是一个线性空间,但是在算法中,我们通过适当的逻辑控制将它首尾相连(0 = 2^32),这样让它在逻辑上形成了一个环形空间。它也是按照使用取模的方法,上一种方式的节点取模法是对节点数量进行取模。
而一致性哈希算法是对2^32取模,简单来说,一致性哈希算法将整个哈希值空间组织成一个虚拟的圆环,比如某哈希函数H的值空间为 0 ~ 2^32-1 (即哈希值是一个32位无符号整形),整个哈希环如下图:整个空间按照顺时针方向组织,圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2,3,4、... 直到
2^32-1,也就是说0点左侧的第一个点代表2^32-1,0和2^32-1在零点中方向重合,我们把这个有2^32个点组成的圆环称为哈希环。
-
服务器IP节点映射
将集群中各个机器的IP映射到环上的某一个位置,具体可以选择服务器的IP或主机名作为关键字进行哈希,这样每台机器就能确定自己在环上的位置。假如4个结点NodeA、B、C、D,经过IP地址的哈希函数计算(hash(ip)),使用IP地址哈希后在环空间的位置如下:

-
key落到服务器的落键规则
当我们需要存储kv键值对时,首先计算出key的hash值,
hash(key),将这个key使用相同的函数Hash计算出哈希值并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器,并将该键值对存储在该节点上。
-
-
目的:为了在节点数目发生改变时尽可能少迁移数据。将所有的存储节点排列在相接的hash环上,每个key在计算hash之后,会按照顺时针找到的存储节点存放。而当有节点加入或者退出时候,仅影响该节点在hash环上的顺时针相邻的后续节点。
-
优点:解决了容错性和扩展性的问题
加入和删除节点只会影响哈希环中顺时针方向相邻的节点,对其他节点无影响。
-
缺点:解决不了数据倾斜的问题
数据的分布和节点的位置有关,因为这些节点不是均匀地分布在哈希环上的,所以数据进行存储时候达不到均匀分布效果。可能就出现了数据倾斜问题。

-
-
哈希槽分区
-
是什么:因为一致性哈希算法的数据倾斜问题,为了解决这个问题。哈希槽实质上就是一个数组,数组[0,2^14-1]形成hash slot空间。
-
能干什么:解决均匀分配的问题,在数据和节点之间又加入了一层,把这一层称为哈希槽(slot),用于管理数据和节点之间的关系。现在就相当于节点上放的是槽,槽里面上的是数据。

槽解决的是粒度问题,相当于是把粒度变大了。这样便于数据移动。哈希解决的是映射问题,使用key的哈希值来计算所对应槽,便于数据分配。
-
多少个hash槽
一个集群中只能有16384个槽。编号为0--16383(0-2^14-1),这些槽会分配给集群中所有的主节点,分配策略没有要求。可以指定哪个编号的槽分配给哪个主节点。集群会记录节点和槽对应的关系。解决了节点和槽的关系后,接下来就需要对key进行hash值计算,然后对16384取余。余数是几,那么key就落入到对应的槽中。
slot=CRC16(key)%16384。以槽为单位移动数据,因为槽的数目是固定的,处理起来比较容器,这样数据迁移问题就解决了。❓ 为什么redis集群最大的槽数是16384个?
📖 精心整理了20道Redis经典面试题(珍藏版)
-
Redis 集群没有使用一致性 hash,而是引入了哈希槽的概念,Redis 集群有
16384个哈希槽,每个 key 通过CRC16校验后对 16384 取模来决定放置哪个槽,集群的每个节点负责一部分 hash 槽。 -
CRC16算法产生的hash值有16bit,该算法可以产生2^16=65536个值。如果槽位为65536,发送心跳信息的消息头达8k,发送的心跳包过于庞大。redis的集群主节点数量基本不可能超过1000个。对于节点数在1000以内的redis cluster集群,16384个槽位够用了。没有必要拓展到65536个。
-
-
哈希槽计算
Redis集群中内置了16384个哈希槽,Redis会根据节点数量大致均等地将hash槽映射到不同的节点。当需要在集群中放置一个k-v时,Redis先对key使用crc16算法算出一个结果,然后把结果对16834求余数。这样每个key都会对应一个编号,也就会映射到某个节点上。如下图:
简单来说:key -> crc16 -> %16384取余 -> 根据槽-redis服务器,找到对应存储位置

-
-
-
3主3从redis集群扩缩配置案例架构说明
-
redis集群配置

-
关闭防火墙+启动docker后台服务:
systemctl start docker -
新建6个docker容器实例:
docker run -d --name redis-node-1 --net host --privileged=true -v /data/redis/share/redis-node-1:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6381docker run -d --name redis-node-2 --net host --privileged=true -v /data/redis/share/redis-node-2:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6382docker run -d --name redis-node-3 --net host --privileged=true -v /data/redis/share/redis-node-3:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6383docker run -d --name redis-node-4 --net host --privileged=true -v /data/redis/share/redis-node-4:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6384docker run -d --name redis-node-5 --net host --privileged=true -v /data/redis/share/redis-node-5:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6385docker run -d --name redis-node-6 --net host --privileged=true -v /data/redis/share/redis-node-6:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6386注意:别瞎复制,要改3处,name、v、port。否则会报错:
Sorry, the cluster configuration file nodes.conf is already used by a different Redis Cluster node. Please make sure that different nodes use different cluster configuration files.
docker run:创建并运行docker容器实例--name redis-node-1:容器名字--net host:使用宿主机的IP和端口,默认--privileged=true:获取宿主机root用户权限-v /data/redis/share/redis-node-1:/data:容器卷,宿主机地址:docker内部地址redis:6.0.8:redis镜像和版本号--cluster-enabled yes:开启redis集群--appendonly yes:开启持久化--port 6386:redis端口号
-
进入容器
redis-node-1并为6台机器构建集群关系,这里的地址要改成自己的真实IP地址,运行后会自动进行两两配对redis-cli --cluster create 172.24.113.146:6381 172.24.113.146:6382 172.24.113.146:6383 172.24.113.146:6384 172.24.113.146:6385 172.24.113.146:6386 --cluster-replicas 1-
--cluster-replicas 1:表示为每个master创建一个slave节点 -
从下图结果也可以看出/证明:一共是16383个槽,这里分成了三份,并且分别建立映射关系
Master[0] -> Slots 0 - 5460 Master[1] -> Slots 5461 - 10922 Master[2] -> Slots 10923 - 16383 Adding replica 172.24.113.146:6385 to 172.24.113.146:6381 Adding replica 172.24.113.146:6386 to 172.24.113.146:6382 Adding replica 172.24.113.146:6384 to 172.24.113.146:6383
-
-
连接进入6381作为切入点,查看集群状态:
redis-cli -p 6381、cluster info、cluster nodes
-
-
主从容错切换迁移
-
数据读写存储
-
启动6机构成的集群并通过exec进入
-
对6381新增两个key
(base) root@L2010403019000# docker exec -it redis-node-1 bash root@L2010403019000:/data# redis-cli -p 6381 127.0.0.1:6381> set k1 v1 (error) MOVED 12706 172.24.113.146:6383 127.0.0.1:6381> get k1 (error) MOVED 12706 172.24.113.146:6383 127.0.0.1:6381> set k2 v2 OK 127.0.0.1:6381> set k3 v3 OK 127.0.0.1:6381> set k4 v4 (error) MOVED 8455 172.24.113.146:6382 127.0.0.1:6381>要用集群的命令,单机版的命令有些key存不进去
-
防止路由失效加参数
-c并新增两个key会根据存储的槽位自动跳转到对应的机器
root@L2010403019000:/data# redis-cli -p 6381 -c 127.0.0.1:6381> set k1 v1 -> Redirected to slot [12706] located at 172.24.113.146:6383 OK 172.24.113.146:6383> -
查看集群信息:
redis-cli --cluster check xxx:6381
-
-
容错切换迁移
-
主6381和从机切换,先停止主机6381
-
再次查看集群信息,6381的主机挂了,6384上位成了master

-
再启动6381,6381会变成从机slave,类似的再停6384,6381会成为master

-
-
-
主从扩容
-
需求分析:三主三从到四主四从,关键在于哈希槽的重新分配



-
新建6387、6388两个节点+新建后启动+查看是否8节点
docker run -d --name redis-node-7 --net host --privileged=true -v /data/redis/share/redis-node-7:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6387 docker run -d --name redis-node-8 --net host --privileged=true -v /data/redis/share/redis-node-8:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6388 -
进入6387容器实例内部,将新增的6387节点(空槽号)作为master节点加入原集群
docker exec -it redis-node-7 bash# 将新的6387作为master节点加入集群 redis-cli --cluster add-node xxx:6387 xxx:6381 # - 6387就是要作为master新增节点 # - 6381就是原来集群节点里面的领路人,相当于6387拜拜6381的码头从而找到组织加入集群
-
检查集群情况第1次:
redis-cli --cluster check 172.24.113.146:6381,可以看到6387已经整上了Master,但是没有槽位
-
重新分派槽号:
redis-cli --cluster reshard 172.24.113.146:6381
- 4096:16384/4,四个master每个拥有4096个槽
- node id:谁接收新分配的槽,6387的id
- all:全部洗牌
-
检查集群情况第2次:
redis-cli --cluster check 172.24.113.146:6381,每个node分一部分给新的节点
-
为什么6387是3个新的区间,以前的还是连续?
重新分配成本太高,所以前3个节点各自匀出来一部分,从 6381/6382/6383 三个旧节点分别匀出1364个坑位给新节点6387
已经有的key存了,再调整太麻烦了,每个node匀一点
-
-
为主节点6387分配从节点6388:
redis-cli --cluster add-node 172.24.113.146:6388 172.24.113.146:6387 --cluster-slave --cluster-master-id 23cbf2d9015841575a35df2e890821b1a13f075b
-
检查集群情况第3次:
redis-cli --cluster check 172.24.113.146:6383
-
-
主从缩容
-
需求分析:(目的:6387和6388下线)
- 先清除从节点6388
- 清出来的槽号重新分配
- 再删除6387
- 恢复成3主3从

-
检查集群情况1,获得6388节点ID:
redis-cli --cluster check 172.24.113.146:6381
-
将6388删除,从集群中将4号从节点6388删除:
redis-cli --cluster del-node 172.24.113.146:6388 d9dfd3dd02ffd346494a48e4db26a789de471df0检查一下发现,6388被删除了,只生下了7台机器:
redis-cli --cluster check 172.24.113.146:6381
-
将6387的槽号清空,重新分配(这里将清出来的槽号都给6381):
redis-cli --cluster reshard 172.24.113.146:6381这里要把6397的槽都给6381,因此后续参数分别是:
- 4096
- 6381的id
- 6387的id
- done

check一下可以看到,6387的4096全部给6381了

-
将6387从集群中删除:
redis-cli --cluster del-node 节点ip:端口 节点id
可以看到,6387的从点已经被删除了,此外三个Master槽分别是:8192、4096、4096
-
-
10. Dockerfile解析
-
是什么:
-
Dockerfile是用来构建Docker镜像的文本文件,是由一条条构建镜像所需的指令和参数构成的脚本。
-
解决什么问题:commit很麻烦,每次都要io。能不能一次性搞定?能不能给个清单,后续每次加入新的功能,直接在清单中写好。

-
官网:https://docs.docker.com/engine/reference/builder/
-
构建三步骤:
- 编写Dockerfile文件
- docker build命令构建镜像
- docker run依照镜像运行容器实例
-
-
Dockerfile构建过程解析
-
Dockerfile内容基础知识
- 每条保留字指令都 必须为大写字母 且后面要跟随至少一个参数
- 指令按照从上到下,顺序执行
- # 表示注释
- 每条指令都会创建一个新的镜像层并对镜像进行提交
-
Docker执行Dockerfile的大致流程
- docker从基础镜像运行一个容器
- 执行一条指令并对容器作出修改
- 执行类似docker commit的操作提交一个新的镜像层
- docker再基于刚提交的镜像运行一个新容器
- 执行dockerfile中的下一条指令知道所有指令都完成
-
总结:从应用软件的角度来看,Dockerfile、Docker镜像与Docker容器分别代表软件的三个不同阶段:
- Dockerfile是软件的原材料;
- Docker镜像是软件的交付品;
- Docker容器则可以认为是软件镜像的运行态,也即依照镜像运行的容器实例。
Dockerfile面向开发,Docker镜像成为交付标准,Docker容器则涉及部署与运维,三者缺一不可,合力充当Docker体系的基石。

- Dockerfile:需要定义一个Dockerfile,Dockerfile定义了进程需要的一切东西。Dockerfile涉及的内容包括执行代码或者是文件、环境变量、依赖包、运行时环境、动态链接库、操作系统的发行版、服务进程和内核进程(当应用进程需要和系统服务和内核进程打交道,这时需要考虑如何设计namespace的权限控制)等等;
- Docker镜像:在用Dockerfile定义一个文件之后,docker build时会产生一个Docker镜像,当运行Docker镜像时会真正开始提供服务;
- Docker容器:容器是直接提供服务的。
-
-
Dockerfile常用保留字指令

-
FROM:基本出现在第一行,代表新构建的镜像来在于哪儿,指定一个已经存在的镜像作为模板
-
MAINTAINER:镜像维护者的姓名和邮箱地址
-
RUN:
- 容器构建时需要运行的命令
- 两种格式:都可以,看你个人选择
- shell:类似在终端运行
RUN yum -y install vim - exec:
RUN ["./test.php", "dev", "offline"]类似于RUN ./test.php dev offline
- shell:类似在终端运行
- RUN是在docker build时运行
-
EXPOSE:当前容器对外暴露出的端口,类似p、P对端口的映射
-
WORKDIR:指定在创建容器后,终端默认登录进来的工作目录 ,一个落脚点(指定之后,后续run镜像的时候,进去的目录就是这个目录)
-
USER:指定该镜像以什么样的用户去执行,如果都不指定,默认是root(不考虑在镜像里面搞权限没什么意义)
-
ENV:用来在构建镜像过程中设置环境变量
比如
ENV MY_PATH /usr/mytest,这个环境变量可以在后续的任何RUN指令中使用,这就如同在命令前指定了环境变量前缀一样,也可以在其它指令中直接使用这些环境变量,比如WORKDIR $MY_PATH -
⭐ ADD:(一般用这个,比COPY强大些)将宿主机目录下的文件拷贝进镜像且会自动处理URL和解压tar压缩包
-
COPY:类似ADD,拷贝文件和目录到镜像中。将从构建上下文目录中<源路径>的文件/目录复制到新的一层的镜像内的<目标路径>位置
COPY src destCOPY ["src", "dest"]- 其中,src为源文件、源路径;dest为容器内的指定路径,该路径不用事先建好
-
VOLUME:容器数据卷,用于数据保存和持久化工作
-
CMD:指定容器启动后要干的事情
CMD指令的格式和RUN相似,也是两种格式:shell格式:CMD <命令>exec格式:CMD ["可执行文件", "参数1", "参数2", ...]- 参数列表格式:在指定了
ENTRYPOINT指令后,用CMD指定具体的参数
- 注意:
- Dockerfile中可以有多个CMD命令,但是只有最后一个生效,CMD会被docker run之后的参数替换(简单来说,
docker run -it ... bash,这行因为加了bash,因此相当于加了一行CMD ["bash"],那么原来最后一行CMD就运行不了)
- Dockerfile中可以有多个CMD命令,但是只有最后一个生效,CMD会被docker run之后的参数替换(简单来说,
- 和RUN的区别
- CMD是在docker run时运行
- RUN时在docker build时运行
-
ENTRYPOINT:也是用来指定一个容器启动时要运行的命令,类似CMD命令。但是ENTRYPOINT不会被docker run后面的命令覆盖,而且这些命令行参数会被当作参数送给ENTRYPOINT指令指定的程序
- 命令格式:
ENTRYPOINT ["执行的命令", "参数1", "参数2"...] - ENTRYPOINT可以和CMD一起用,
一般是变参才会使用CMD,这里的CMD等于是在给ENTRYPOINT传参 - 当指定了ENTRYPOINT后,CMD的含义就发生了变化,不再是直接运行其命令而是将CMD的内容作为参数传递给ENTRYPOINT指令,他两个组合会变成
<ENTRYPOINT> "<CMD>" - 这里可以简单理解为,结合时候的时候,cmd里的参数是默认参数,
docker run的时候不指定就是用默认的cmd里的,如果指定了就用指定的

- 命令格式:
-
-
案例
-
自定义镜像mycentosjava8
-
要求
- Centos7镜像具备vim+ifconfig+jdk8
- jdk下载镜像地址:
- 官网:https://www.oracle.com/java/technologies/downloads/#java8
- 镜像:https://mirrors.yangxingzhen.com/jdk/
-
编写:准备编写Dockerfile文件,大写字母D
FROM centos MAINTAINER litian<litian@whchem.com>ENV MYPATH /usr/local WORKDIR $MYPATH# 配置源 RUN cd /etc/yum.repos.d/ RUN sed -i 's/mirrorlist/#mirrorlist/g' /etc/yum.repos.d/CentOS-* RUN sed -i 's|#baseurl=http://mirror.centos.org|baseurl=http://vault.centos.org|g' /etc/yum.repos.d/CentOS-* RUN yum makecache RUN yum update -y# 安装vim编译器 RUN yum -y install vim # 安装ifconfig命令查看网络IP RUN yum -y install net-tools # 安装java8以及lib库 RUN yum -y install glibc.i686 RUN mkdir /usr/local/java # ADD 是相对路径jar。把jdk的gz添加到容器中,安装包必须要和Dockerfile文件在同一位置 ADD jdk-8u221-linux-x64.tar.gz /usr/local/java # 配置java环境变量 ENV JAVA_HOME /usr/local/java/jdk1.8.0_221 ENV JRE_HOME $JAVA_HOME/jre ENV CLASSPATH $JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib:$CLASSPATH ENV PATH $JAVA_HOME/bin:$PATHEXPOSE 80CMD echo $MYPATH CMD echo "success.......ok" CMD /bin/bashhttps://blog.csdn.net/SC_CSDN_L/article/details/140356006
注意:关于yum install,运行到这儿就没忘了,所以我们在Dockerfile中还要加入修改yum源的步骤:
# 在新镜像中运行命令,切换到 `/etc/yum.repos.d/` 目录 RUN cd /etc/yum.repos.d/# 使用sed命令在 `/etc/yum.repos.d/CentOS-*` 文件中,将所有包含 `mirrorlist` 的行替换为 `#mirrorlist`。注释掉原有的镜像源地址。 RUN sed -i 's/mirrorlist/#mirrorlist/g' /etc/yum.repos.d/CentOS-* # 使用sed命令在 `/etc/yum.repos.d/CentOS-*` 文件中,将 `#baseurl=http://mirror.centos.org` 替换为 `baseurl=http://vault.centos.org`。将镜像源地址改为CentOS Vault站点,用于访问旧版本软件包的站点。 RUN sed -i 's|#baseurl=http://mirror.centos.org|baseurl=http://vault.centos.org|g' /etc/yum.repos.d/CentOS-*# 更新YUM缓存,以便系统可以访问最新的软件包信息。 RUN yum makecache# 执行完整的系统更新,安装所有可用更新的软件包。 RUN yum update -y -
构建:
docker build -t centosjava8:1.5 .,注意这个点,是指当前目录构建,不要忘了 -
运行:
docker run -it centosjava8:1.5 bash,vim、ifconfig、java都可以用了
-
-
虚悬镜像
-
是什么:仓库名、标签名都是
<none>的镜像,俗称dangling image -
Dockerfile写一个:
-
vim Dockerfile
FROM ubuntu CMD echo 'action is success' -
docker build .
-
-
查看:
docker image ls -f dangling=true -
删除:
docker image prune
-
-
11. Docker微服务实战
一切在云端,处处皆镜像~
-
通过IDEA新建一个普通微服务模块
- 建Module,docker_boot
- 改POM
- 写YML
- 主启动
- 业务类
-
通过dockerfile发布微服务部署到dockerfile容器
-
IDEA工具里面搞定微服务jar包
-
编写Dockerfile
FROM java:8 MAINTAINER test VOLUME /tmp ADD docker_boot-0.0.1-SNAPSHOT.jar test.jar RUN bash -c 'tourch /test.jar' ENTRYPOINT ["java", "- jar", "/test.jar"] EXPOSE 6001 -
构建镜像:
docker build -t test:1.6 . -
运行容器:
docker run -d -p 6001:6001 test:1.6 -
访问测试
-
12. Docker网络
-
是什么:
-
docker不启动,默认网络情况
- ens33
- lo
- virbr0:在CentOS7的安装过程中如果有选择相关虚拟化的的服务安装系统后,启动网卡时会发现有一个以网桥连接的私网地址的virbr0网卡(virbr0网卡:它还有一个固定的默认IP地址192.168.122.1),是做虚拟机网桥的使用的,其作用是为连接其上的虚机网卡提供 NAT访问外网的功能。
-
docker启动后,网络情况
-
查看docker网络情况:
docker network ls -
默认创建的3大网络模式

-
-
-
常用基本命令:
- 创建:
docker network create mynet - 删除:
docker network rm mynet - 查看:
docker network inspect bridge
- 创建:
-
能干嘛
- 容器间的互联和通信以及端口映射
- 容器IP变动的时候可以通过服务名直接网络通信而不受到影响
-
网络模式
-
总体介绍
网络模式 简介 bridge 为每一个容器分配、设置IP等,并将容器连接到一个 docker0虚拟网桥,默认为该模式。host 容器将不会虚拟出自己的网卡,配置自己的Ip等,而是使用宿主机的IP和端口。 none 容器有独立的Network namespace,但并没有对其进行任何网络设置,如分配veth pari和网桥连接、IP等。 container 新创建的容器不会创建自己的网卡和配置自己的IP,而是和一个指定的容器共享IP、端口范围等。 bridge模式:使用
--network bridge指定,默认使用docker0host模式:使用
--network host指定none模式:使用
--network none指定container模式:使用
--network container:NAME或者容器ID指定 -
容器实例默认网络IP生产规则:docker容器内部的IP是有可能会发生改变的
-
案例说明:
-
bridge:
-
是什么
Docker服务默认会创建一个docker0网桥(其上有一个docker0内部接口),该桥接网络的名称为docker0,它在内核层连通了其他的物理或虚拟网卡,这就将所有容器和本地主机都放到同一个物理网络。Docker默认指定了docker0接口的IP地址和子网掩码,让主机和容器之间可以通过网桥相互通信。
-
案例
-
Docker使用Linux桥接,在宿主机虚拟一个Docker容器网桥(docker0),Docker启动一个容器时会根据Docker网桥的网段分配给容器一个IP地址,称为Container-IP,同时Docker网桥是每个容器的默认网关。因为在同一宿主机内的容器都接入同一个网桥,这样容器之间就能够通过容器的Container-IP直接通信。
-
docker run的时候,没有指定network的话默认使用的网桥模式就是bridge,使用的就是docker0。在宿主机ifconfig,就可以看到docker0和自己create的network eth0,eth1,eth2……代表网卡一,网卡二,网卡三……,lo代表127.0.0.1,即localhost,inet addr用来表示网卡的IP地址
-
网桥docker0创建一对对等虚拟设备接口:一个叫veth,另一个叫eth0,成对匹配。
- 整个宿主机的网桥模式都是docker0,类似一个交换机有一堆接口,每个接口叫veth,在本地主机和容器内分别创建一个虚拟接口,并让他们彼此联通(这样的一对接口叫 veth pair);
- 每个容器实例内部也有一块网卡,每个接口叫eth0;
- docker0上面的每个veth匹配某个容器实例内部的eth0,两两配对,一一匹配。
通过上述,将宿主机上的所有容器都连接到这个内部网络上,两个容器在同一个网络下,会从这个网关下各自拿到分配的ip,此时两个容器的网络是互通的。

-
代码验证
-
创建两个tomcat的容器:
docker run -d -p 8081:8080 --name tomcat81 billygoo/tomcat8-jdk8docker run -d -p 8082:8080 --name tomcat82 billygoo/tomcat8-jdk8 -
ip addr:查看宿主机地址
-
查看tomcat81的地址

这里的
5: eth0@if6跟宿主机的6: vetheb86a37@if5对应,即eth0跟veth对应 -
同样的,查看tomcat82的地址

7: eth0@if8跟宿主机的8: veth4b8beaa@if7对应
-
-
-
-
host
-
直接使用宿主机的IP地址与外界进行通信,不再需要额外进行NAT转换。
-
容器将不会获得一个独立的Network Namespace,而是和宿主机共用一个Network Namespace。容器将不会虚拟出自己的网卡而是使用宿主机的IP和端口。

-
案例:
-
docker run -d -p 8083:8080 --network host --name tomcat83 billygoo/tomcat8-jdkWARNING: Published ports are discarded when using host network mode 5973d8b28d71d8172b5097b98a9d6be5806725407aa91ac58eb36be3f8c58ec1会出现警告的内容,且
docker ps中可以看到 PORTS 那一栏为空。这是因为指定--network host之后,还指定-p映射端口将毫无作用,因为端口号会以主机端口号为主,重复时则递增。🤞 解决:使用其他网络模式,或者直接无视警告。
✔️ 正确:在用host模式的时候,不要指定端口映射。
-
用
ip addr可以看到没有之前的配对显示了,用docker inspect 容器ID可以看到容器实例内部的网关和地址的值为空字符串。 -
❓ 没有设置-p的端口映射了,如何访问启动的tomcat83?
直接:
http://宿主机IP:8080/在CentOs里面用默认的浏览器访问容器内的tomcat83看到访问成功,因为此时容器的IP借用主机的.
所以容器共享宿主机网络IP,这样的好处是外部主机与容器可以直接通信。
-
-
-
none
- 禁用网络功能,只有lo标识(就是127.0.0.1表示本地回环)
- 需要我们自己为Docker容器添加网络、配置IP等基本不用
-
container
-
新建的容器和已经存在的一个容器共享一个网络ip配置而不是和宿主机共享。新创建的容器不会创建自己的网卡,配置自己的IP,而是和一个指定的容器共享IP、端口范围等。同样,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的。

-
❗ 坑:以tomcat测试会报错,对外发布的端口和这种网络模式是不匹配的。
-
验证可得:
- 两个容器内
ip addr显示的eth0完全一样 - 关闭对应的容器之后,这种网络模式的容器的 eth0 将会消失
- 两个容器内
-
-
自定义网络
-
过时的link,可以通过自定义网络完成替代
-
问题:用原来的方式,按ip地址可以ping通,但是按照服务名无法ping通,
ping tomcat82 -
自定义网络怎么解决这个问题
-
自定义桥接网络:自定义网络默认使用的是桥接网络bridge
-
新建自定义网络:
docker network create lt_net -
以自定义网络启动tomcat:
docker run -d -p 8081:8080 --network lt_net --name tomcat81 billygoo/tomcat8-jdk8docker run -d -p 8082:8080 --network lt_net --name tomcat82 billygoo/tomcat8-jdk8 -
此时可以ping通服务名:
ping tomcat82
-
-
结论:自定义网络本身就维护好了主机名和ip的对应关系(ip和域名都能通)
-
-
-
13. Docker-compose容器编排
一键部署,一键启停。少量容器编排可以,大量就需要k8s了
-
是什么:Docker-Compose是Docker官方的开源项目,负责实现对Docker容器集群的快速编排。
Docker-Compose是Docker公司推出的一个开源工具软件,可以管理多个 Docker容器组成一个应用。用户需要定义一个YAML格式的配置文件
docker-compose.yml,写好多个容器之间的调用关系。然后,只要一个命令,就能同时启动/关闭这些容器(或者说能实现对Docker容器集群的快速管理,编排)
-
能干嘛:
Docker建议我们每一个容器中只运行一个服务,因为 Docker 容器本身占用资源极少,所以最好是将每个服务单独的分割开来。但是这样我们又面临了一个问题:
❓ 如果需要同时部署好多个服务,难道要每个服务单独写 Dockerfile 然后再构建镜像,构建容器?非常麻烦。
- 所以 Docker 官方给我们提供了 Docker-compose 多服务部署的工具。例如要实现一个 Web 微服务项目,除了 Web 服务容器本身,往往还需要再加上后端的数据库 MySQL 容器,Redis 服务器,注册中心 eureka,甚至还包括负载均衡容器等等...
- Compose 允许用户通过一个单独的 docker-compose.yml 模板文件(YAML 格式)来定义一组相关联的应用容器为一个项目(project)。
可以很容易地用一个配置文件定义一个多容器的应用,然后使用一条指令安装这个应用的所有依赖,完成构建。Docker-Compose 解决了容器与容器之间如何管理编排的问题。
-
去哪下:
-
官网:https://docs.docker.com/reference/compose-file/legacy-versions/
-
官网下载:https://docs.docker.com/compose/install/
-
下载和安装:docker-compose的具体安装可以看我之前研究的攻略:https://blog.csdn.net/qq_21579045/article/details/141718124
-
其实就是先从github上拉取docker-compose,保存到
/usr/local/bin/docker-compse路径:curl -SL https://github.com/docker/compose/releases/download/v2.30.1/docker-compose-linux-x86_64 -o /usr/local/bin/docker-compose -
然后赋予执行权限:
chmod +x /usr/local/bin/docker-compose -
查看搞好了没:
docker-compose --version
-
-
卸载:
sudo rm /usr/local/bin/docker-compose,直接把拷贝过去的 docker-compose 删了就行
-
-
Compose核心概念
- 一个文件:
docker_compose.yml - 两大要素:
- 服务(service):一个个应用容器实例,比如订单微服务、库存微服务、mysql容器、nginx容器或者redis容器
- 工程(project):由一组关联的应用容器组成的一个 完整业务单元,在docker-compose.yml文件中定义
- 一个文件:
-
Compose使用的三个步骤
- 编写Dockerfile定义各个微服务应用并构建出对应的镜像文件
- 使用docker-compose.yml定义一个完整的业务单元,安排好整体应用中的各个容器服务
- 最后,执行docker-compose up命令来启动并运行整个应用程序,完成一键部署上线(等价于一次性运行了多个
docker run命令)
-
Compose常用命令

-
Compose编排微服务
-
改造升级微服务工程docker_boot
-
不用compose编排服务有什么问题?
-
单独的mysql容器实例
- 新建mysql容器实例
- 进入mysql容器实例并新建库+新建表
docker run -p 3306:3306 --name mysql57 --privileged=true -v /mysql/conf:/etc/mysql/conf.d -v /mysql/logs:/logs -v /mysql/data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7- 我用windows的docker windows:
docker run -p 3306:3306 --name huazi-mysql --privileged=true -v D:\containers\mysql\conf:/etc/mysql/conf.d -v D:\containers\mysql\logs:/logs -v D:\cont ainers\mysql\data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7
-
单独的redis容器实例
docker run -p 6379:6379 --name redis608 --privileged=true -v /redis/redis.conf:/etc/redis/redis.conf -v /redis/data:/data -d redis:6.0.8 redis-server /etc/redis/redis.conf- 我用windos的docker windows:
docker run -p 6379:6379 --name huazi-redis --privileged -v D:\containers\redis\redis.conf:/etc/redis/redis.conf -v D:\containers\redis\data:/data -d re dis:6.0.8 redis-server /etc/redis/redis.conf
- 我用windos的docker windows:
-
微服务工程
-
上面三个容器实例依次顺序启动成功
-
但是有哪些问题:
- 先后顺序要求固定,先mysql+redis,才能微服务访问成功
- 多个run命令
- 容器间的启停或宕机,有可能导致IP地址对应的容器实例变化,映射出错,要么生产IP写死(可以但是不推荐),要么通过服务调用
-
-
使用compose编排微服务
-
服务编排,一套带走,安排
-
编写
docker-compse.yml文件 -
二次修改微服务工程 docker_boot
-
在yml文件路径执行
docker-compose up或者docker-compose up -d(后台启动) -
docker-compose config -q:检查配置文件是否有问题,没有输出就是没有问题 -
在 yml 的最后写网络配置,docker-compose会自动创建
路径_lt_net的docker网络,类似的创建服务的时候同样也会加上路径前缀,并不影响使用。如果yml中给服务起了名字,则会使用名字,而不是自动生成加上路径前缀的容器名networks:lt_net -
进入容器,建表建库,测试通过
-
关停:
docker-compose stop
-
-
14. Docker轻量级可视化工具Portainer
-
是什么:是一款轻量级的应用,它提供了图形化的界面,用于方便的管理Docker环境,包括单机环境和集群环境。(当然了,集群还是选k8s)
-
安装:
-
官网:https://www.portainer.io/
-
下载:https://docs.portainer.io/start/install-ce/server/docker/linux
-
步骤:
-
docker命令安装:
docker run -d -p 8000:8000 -p 9443:9443 --name portainer --restart=always -v /var/run/docker.sock:/var/run/docker.sock -v portainer_data:/data portainer/portainer-ce:2.21.4--restart=always:docker重启了,该容器实例也会跟着重启
我用windos的docker windows:docker run -d -p 8000:8000 -p 9000:9000 --name portainer --restart=always -v D:\containers\portainer\docker.sock:/var/run/docker.sock -v D:\containers\ portainer\data:/data portainer/portainer -
第一次登录需创建admin,访问地址:IP:9000
⚠️ 注意:这样创建不对,无法检测到本地的docker容器
如果使用windows的docker desktop还是得老老实实按官网给的方法来:https://docs.portainer.io/start/install-ce/server/docker/wsl
- First, create the volume that Portainer Server will use to store its database:
docker volume create portainer_data - Then, download and install the Portainer Server container:
docker run -d -p 8000:8000 -p 9443:9443 --name portainer --restart=always -v /var/run/docker.sock:/var/run/docker.sock -v portainer_data:/data portainer/portainer
可以发现当前版本 2.21.4 端口不是9000了,而是 9443,此外访问的时候要用https:
https://localhost:9443/ - First, create the volume that Portainer Server will use to store its database:
-
设置admin用户和密码后首次登录
-
选择local选项卡后本地docker详细信息展示 这样一进来就能看到,已经检测到本地的docker服务啦


这里面的stack就是docker-compose的编排情况
-
-
图像展示对应的命令:
docker system df
-
-
登录并演示介绍常用case

15. Docker容器监控之CAdvisor+InfluxDB+Granfana
比起上面的轻量级的Portainer,这个是重量级的
-
原生命令
-
操作:
docker stats
-
问题:通过
docker stats命令可以很方便的看到当前宿主机上所有容器的CPU,内存以及网络流量等数据,一般小公司够用了。但是,docker stats统计结果只能是当前宿主机的全部容器,资料是实时的,没有地方存储、没有健康指标过线预警等功能。
-
-
是什么:容器监控三剑客
-
一句话:CAdvisor监控收集+InfluxDB存储数据+Granfana展示图表

-
CAdvisor
-
CAdvisor是一个容器资源监控工具,包括容器的内存、CPU、网络I0、磁盘IO等监控,同时提供了一个WEB页面用于查看容器的实时运行状态。CAdvisor默认存储2分钟的数据,而且只是针对单物理机。
-
不过,CAdvisor提供了很多数据集成接口,支持lnfluxDB、Redis、Kafka、Elasticsearch等集成,可以加上对应配置将监控数据发往这些数据库存储起来。
-
CAdvisor功能主要有两点:
- 展示Host和容器两个层次的监控数据;
- 展示历史变化数据。
-
-
InfluxDB
- InfluxDB是用Go语言编写的一个开源分布式时序、事件和指标数据库,无需外部依赖。
- CAdvisor默认只在本机保存最近2分钟的数据,为了持久化存储数据和统一收集展示监控数据,需要将数据存储到InfluxDB中。InfluxDB是一个时序数据库,专门用于存储时序相关数据,很适合存储CAdvisor的数据。而且,CAdvisor本身已经提供了InfluxDB的集成方法,在启动容器时指定配置即可。
- InfluxDB主要功能:
- 基于时间序列,支持与时间有关的相关函数(如最大、最小、求和等);
- 可度量性:你可以实时对大量数据进行计算;
- 基于事件:它支持任意的事件数据。
-
Granfana
- Grafana是一个开源的数据监控分析可视化平台,支持多种数据源配置(支持的数据源包括InfluxDB、MySQL、Elasticsearch、OpenTSDB、Graphite等)和丰富的插件及模板功能,支持图表权限控制和报警。
- Granfana主要特性:
- 灵活丰富的图形化选项
- 可以混合多种风格
- 支持白天和夜间模式
- 多个数据源

-
-
compose容器编排,一套带走
-
新建目录:
mkdir /mydocker/cig -
新建3件套组合的
docker-compose.yml-
编辑内容:
# 新版docker-compose不需要定义版本了 # version: '3.1'volumes:grafana_data: {}services:influxdb:# tutum/influxdb 相比influxdb多了web可视化视图。但是该镜像已被标记为已过时image: tutum/influxdb:0.9 restart: alwaysenvironment:- PRE_CREATE_DB=cadvisorports:- "8083:8083" # 数据库web可视化页面端口- "8086:8086" # 数据库端口volumes:- ./data/influxdb:/datacadvisor:image: google/cadvisor:v0.32.0links:- influxdb:influxsrvcommand:- storage_driver=influxdb- storage_driver_db=cadvisor- storage_driver_host=influxsrv:8086restart: alwaysports:- "8080:8080"volumes:- /:/rootfs:ro- /var/run:/var/run:rw- /sys:/sys:ro- /var/lib/docker/:/var/lib/docker:rografana:image: grafana/grafana:8.5.2user: '104'restart: alwayslinks:- influxdb:influxsrvports:- "3000:3000"volumes:- grafana_data:/var/lib/grafanaenvironment:- HTTP_USER=admin- HTTP_PASS=admin- INFLUXDB_HOST=influxsrv- INFLUXDB_PORT=8086 -
检查语法:
docker-compse config -q,没有报错就是没有问题 -
启动docker-compose文件:
docker-compose up -
查看三个服务器是否启动
-
浏览cAdvisor收集服务,
http://ip:8080/,第一次访问的比较慢,稍微一等
-
浏览influxdb存储服务,
http://ip:8083/
-
浏览grafana展现服务,
http://ip:3000/,默认账户密码都是admin

配置步骤:
-
配置数据源:用服务名而不是ip,用户名和密码默认是root


-
保存并测试,看到 ✔️ 就成功啦

-
配置面板

-
-
-
-
- ☁️ 我的CSDN:
https://blog.csdn.net/qq_21579045/ - ❄️ 我的博客园:
https://www.cnblogs.com/lyjun/ - ☀️ 我的Github:
https://github.com/TinyHandsome/ - 🌈 我的bilibili:
https://space.bilibili.com/8182822/ - 🍅 我的知乎:
https://www.zhihu.com/people/lyjun_/ - 🐧 粉丝交流群:1060163543,神秘暗号:为干饭而来
碌碌谋生,谋其所爱。🌊 @李英俊小朋友