【USparkle专栏】如果你深怀绝技,爱“搞点研究”,乐于分享也博采众长,我们期待你的加入,让智慧的火花碰撞交织,让知识的传递生生不息!
一、需求背景
开放大世界渲染中,地形的渲染占比较重,包括开发投入、表现效果及性能开销等。而地形Shader部分的性能优化已经做过多版了,但Mesh的部分还是老旧的Unity内置技术。这种CPU创建、分块、LOD、剔除、提交渲染等对于新设备,特别是高性能端游用户非常不友好。这是因为CPU这些年单核提升幅度放缓,引擎的渲染部分很难抽出大量并行的多线程,而高端GPU的算力隔代提升幅度更大。所以这类本身也适合GPU计算的部分,就有迁移的趋势了。《刺客信条》或《Farcry》系列都有这个趋势的分享。所以决定用GPUDriven技术重写这套地形。
主要参考来自《Farcry5》的一篇文章,但是它涉及流式加载等,感觉不够简单清晰。所以介绍下我自己的做法(85%一致),和他文章内没提到的细节处理。如果经验很丰富的开发者可以直接看这篇就足够了。
GDC Vault - Terrain Rendering in 'Far Cry 5'
因为技术细节比较多,所以先放下最终收益图,加点掌握这套的动力。
9700+3080设备下(1080p):
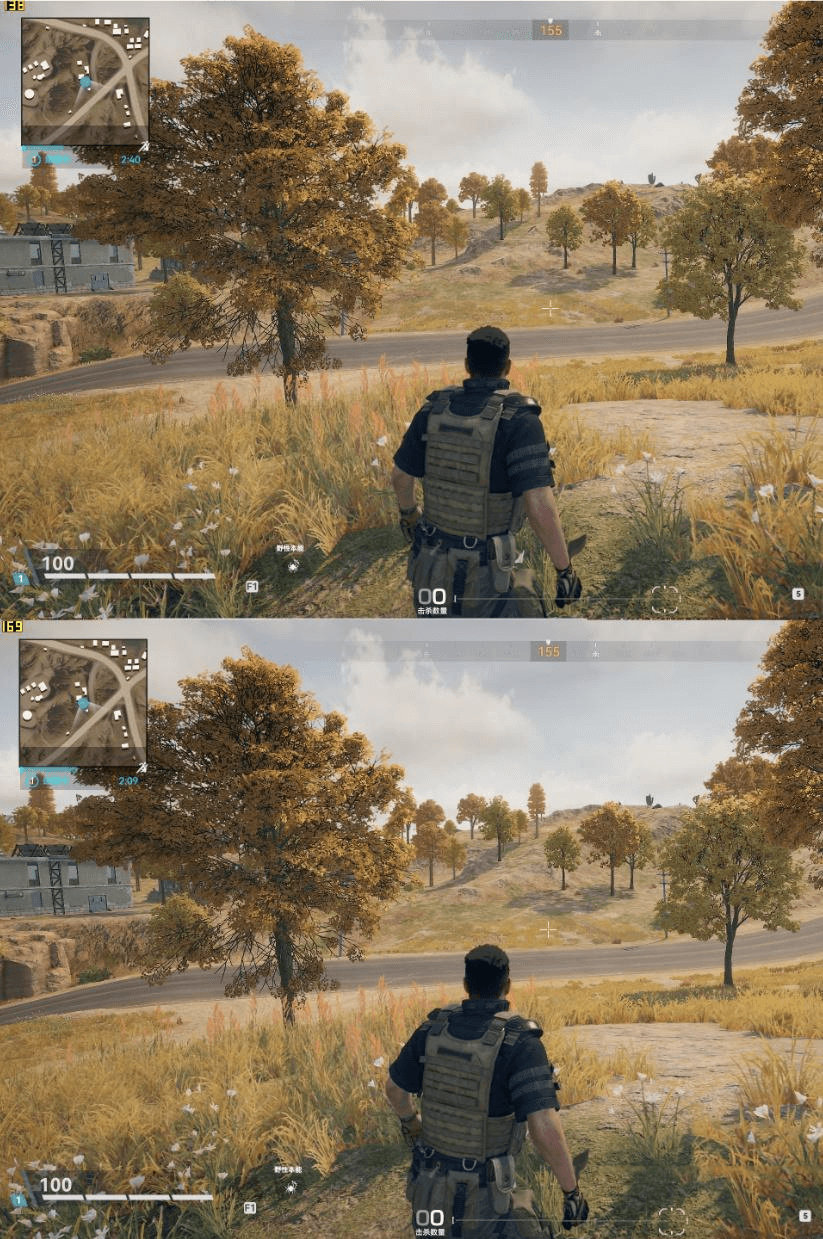
上图:Unity Terrain 下图:GPU Terrain

改造前任务分配
改造后任务分配
二、参数与名称
- 精度为0.5米一个单位,为了方便都不说实际距离(米),都用单位:
- 场景为8192x8192(4096x4096米)
- 高度图为8192x8192 16位精度
- 全图一个四叉树,不分多个四叉树(前面几级数量少浪费不了多少)
- Tile:每512x512一个Tile,Tile是裁剪开始的等级,如果从四叉树根节点查询,层级太多性能不好
- Sector:每128x128一个Sector,Sector是Lod的计算的划分尺度,也就是同一个Sector内部都是相同LOD等级
- Patch:每16x16一个Patch,Patch是最小渲染单位,就是少于16单位后不再细分,逐个判断子节点,直接作为渲染元素
解释下为什么需要Patch:我一开始自己想的一套是用一个正方形4个顶点,来作为最小渲染单位的(DrawMeshInstancedIndirect API的Mesh)。这样可以剔除地最干净,但是这样缺点非常多,比如4个顶点一个格子,顶点比例为4,如果采用16x16,那么会有15x15格子,顶点比例接近1。这是因为同一个Mesh内的顶点可以复用,Mesh实例之间,顶点无法复用导致,另一个方面是如果四叉树需要细分到1x1,内存消耗非常大,大几百MB,而选16x16为最小节点,只要5MB,具体可选8x8或16x16,根据具体项目平衡这个值。
四叉树只记录每个单位的x、z,最小高度,最大高度和LODBias。因为ComputeShader传值最小用int,所以xz可以写成一个Index,但为了可读性,还是用x和z。又因为采用完整四叉树,所以每个子对象都可以根据自己位置算出来。如果不想计算这个也可以直接用C#算好。
三、四叉树数据
四叉树每个node有以下数据:coneDir和coneDot,是做背面裁剪用的,地形背面裁剪效果不大,离线计算比较慢所以这版不开始这功能。

node 数据
这是CPU端为了各自功能预计算方便的格式,会有部分冗余,真正存储到硬盘和给ComputeShader运行时计算的数据结构很小,而到了渲染时,渲染Shader需要的结构更小。
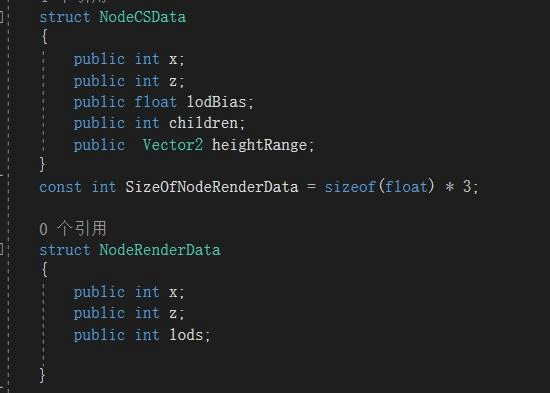
CS计算结构与Shader计算结构
最关键的是一个创建四叉树节点的Insert函数和一个分级迭代更新AABB和LODBias函数,LODBias标准用方差做但差别不大就选简单的DOT了。
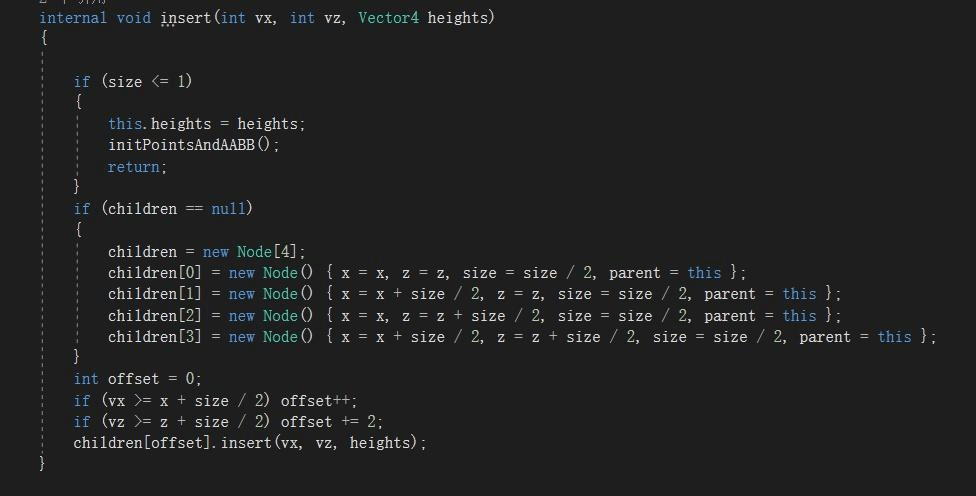
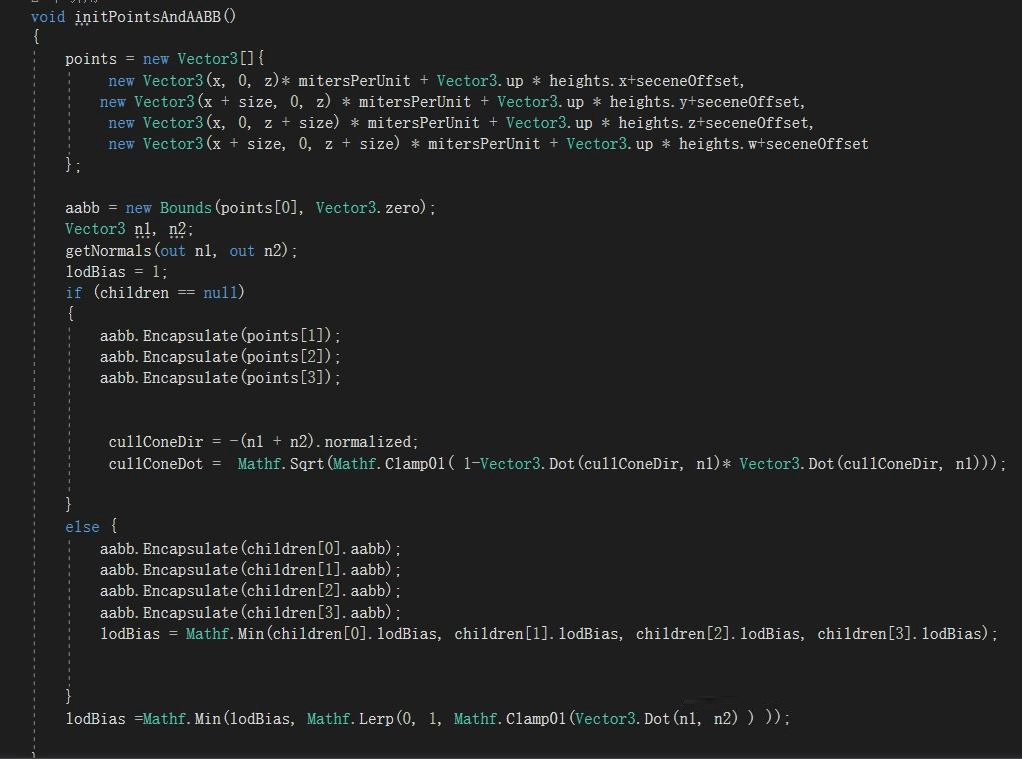
因为在阴影存储的时候写过四叉树工具所以比较简单拿来直接用了,完整功能可以看这里:
Shader内实现四叉树压缩贴图
这个链接里提到的基本压缩方式,就是当4个Child内容非常接近时,可以删除4个Child,用Parent表示整个区域的数据。这样在实时计算LOD,准备细分子对象时,遇到空子对象就不需要细分了,无论数据量还是剔除次数都有更高性能,很适合有大量平地、海水底部大量平面的项目。
四、循环裁剪
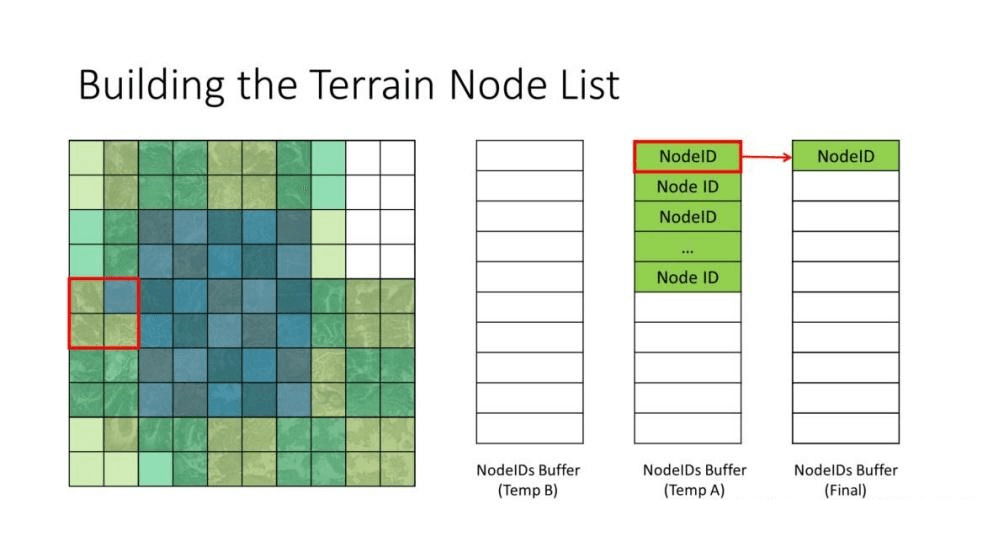
循环裁剪示意图
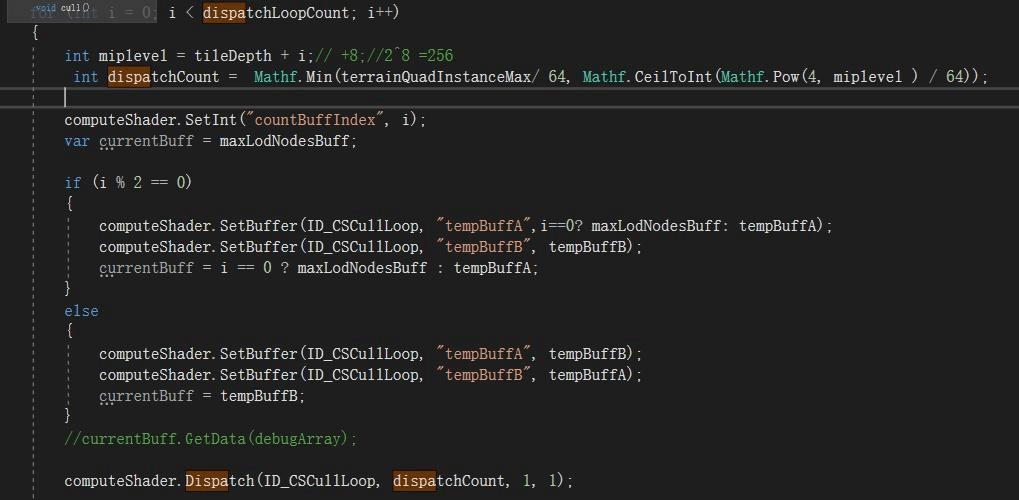
这部分完全采用《Farcry5》文章的做法。C#每次Dispatch只裁剪一层四叉树,第一次是所有的Tile(Size=512),并判断Tile是否需要剔除(视锥、遮挡、距离等)。如果不需要剔除则计算LOD,看看自己是否需要细分为4个子节点(Size=256),如果不需要细分,那么进入FinalBuferr列表,如果需要细分,则进入TempB。然后C#交换设置下TempA和TempB与ComputeShader的绑定,调用下一次裁剪。这样ComputeShader就可以每次都把TempA当输入列表,TempB与Final当输出列表。这个循环的代码大概这样,每次交换TempA与TempB,但第一次用Tile那层。在DispatchCount这里,我用了每级最高可能值来做。我见过另一种做法,是利用实际TempA表长度来做,但是这样做性能并不好,因为这个数量不能回读CPU,而是用Indirect方式让GPU内部自己共享这个Count,这样NumThreads必须为[1,1,1],因为引擎会调用Count次,不会调用Count/64次(假如用NumThreads为[64,1,1]),这样会导致性能差些。
视锥裁剪
HIZ裁剪
五、高度图
高度图精度在大部分项目内是约定俗成的16bit,否则会不足或浪费,但是Unity 5.6没有提供这个类型,于是要找一个容量一样的来存,就是ARGB16(API里叫R4G4B4A4)。但是我们需要把一个高度float写入一个RGBA4通道的图,那么用Built-in的EncodeFloatRGBA是不行的,它是假设R8G8的格式下正确处理,所以需要自己封装2个函数为R4G4B4A4用。
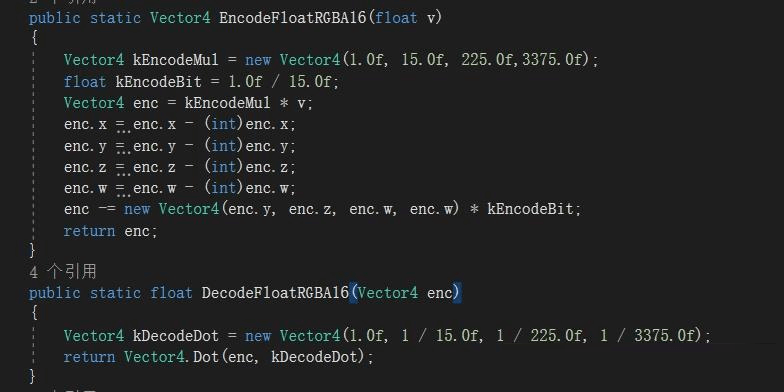
高度float与R4G4B4A4的转换

ARGB16高度图存储方式
六、LOD计算
每个四叉树节点单独计算LOD是不行的,这是因为不同LOD衔接处要处理接缝。这需要获取相邻的LOD,而四叉树多次查询性能不足,所以需要更快地查找周围的方式 ,那自然就是把LOD写成贴图,然后根据位置对应到uv直接查询。
我先后尝试过2种实现方式性能差不多。
第一种是把所有Sector,也就是四叉树节点的Size为128的那一批,单独调用一个ComputeShader并写到RT,如下图:


但是这样会多一次Dispatch,而每次Dispatch都是有额外开销的。
所以我采用不单独计算LOD的方式,而是边裁剪边计算。因node的Size是从TileSize开始的(Tile作为第一批裁剪的节点),所以只要裁剪的size==sectorSize时,写入下LODRT即可。但是如果,还没到这个Size,比如Tile自己就被提前剔除了,这个LOD留空这么办,这里不需要做任何处理,因为如果一个方块区域被剔除不可见,那么所有与它相链接的顶点也都是不可见的,否则就是剔除错了。既然那些点不可见就不处理了, 但如果,没有被剔除而是LOD计算出来比较低,直接没降到Sector大小就进入Final作为渲染单位了呢? 这里就需要用for写入多个像素了,而比SectorSize更新Size的node 就不需要再自己计算LOD了,直接取LODRT图里自己所在Sector对应的LOD,因为一个Sector只能一个LOD。
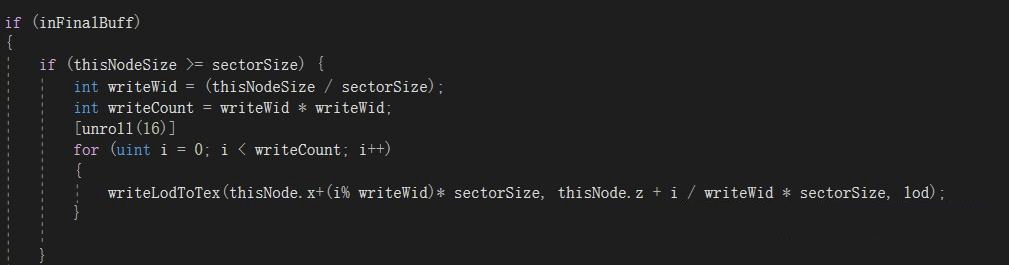
LOD接缝问题
《Farcry5》文章里讲这个比较简单,把网格数量多的那个没对应顶点的中间点直接拉到有对应点的地方,然后高度用新位置的xz采样高度图高度,但是这样采样出来,还是会有接缝。因为若uv相同但LOD不同,采样的高度图会得到不同的高度,就出现接缝,这里需要把处于边线的点,取Max(蓝色块LOD,红色块LOD)。但即便如此,还是有一个问题,文章也没提到。
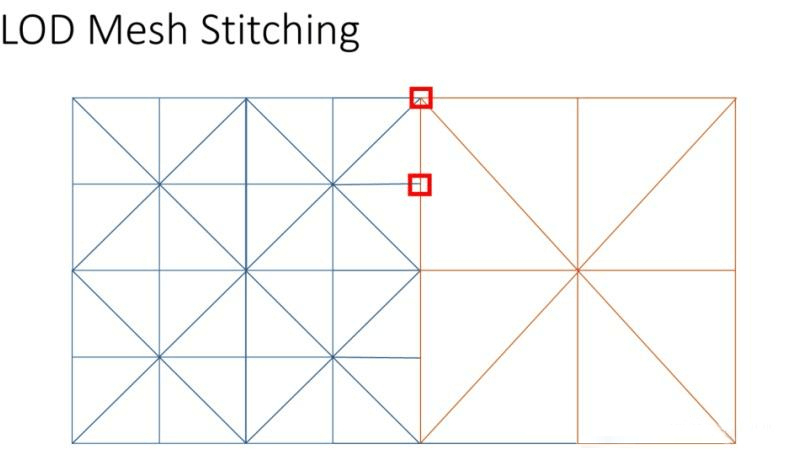
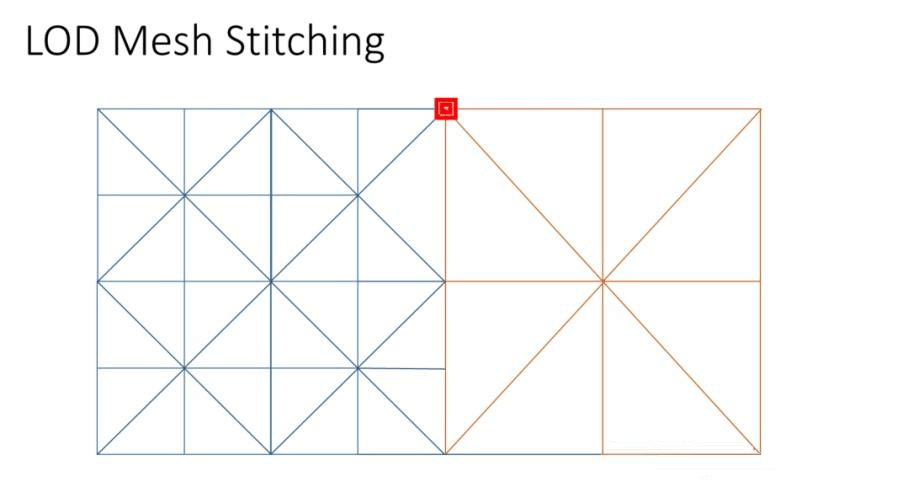
角点接缝
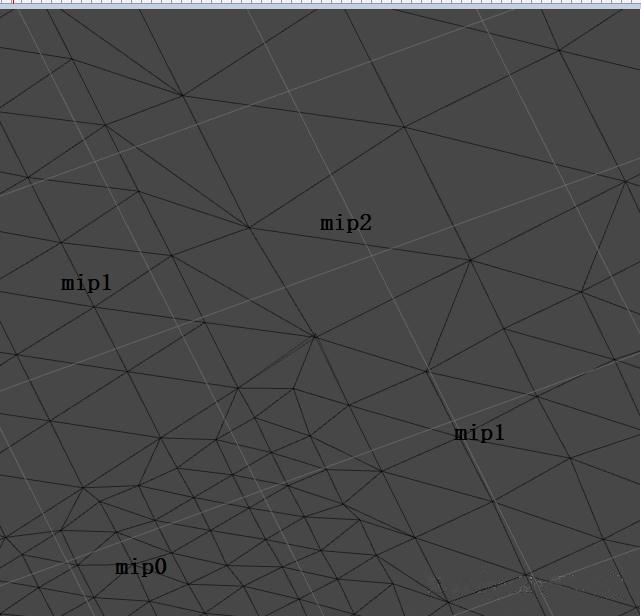
就是Mip0与2个Mip1衔接的边移动好了位置,并且也取了Max(0,1),用1来做高度图采样的LOD了,但是,因为两个Mip1也用了同样的逻辑与修正,导致它们有2个边采用了 Max(1,2)的2来作为LOD采样了,这些处理各自不相干涉,但在Mip0、Mip1、Mip2公共的那个点上,就出了问题。那个位置的点,有的用LOD1,有的用LOD2,就又对不上了。具体的解决办法有3个:
- 大家都采样高度图LOD0,牺牲点远处的缓存,反正这是vs内场景,顶点又不会太挨着所以缓存本来也没多少命中。
- 除了记录边界LOD,也记录对角LOD,取(自己,相邻,对角)最大值。
- 对高度图的Mipmap做特殊生成方式,然后采用子LOD结果与LOD0相同,效果与1一样只是多了缓存浪费了Mipmap内存。
七、关于HIZ剔除扩展部分
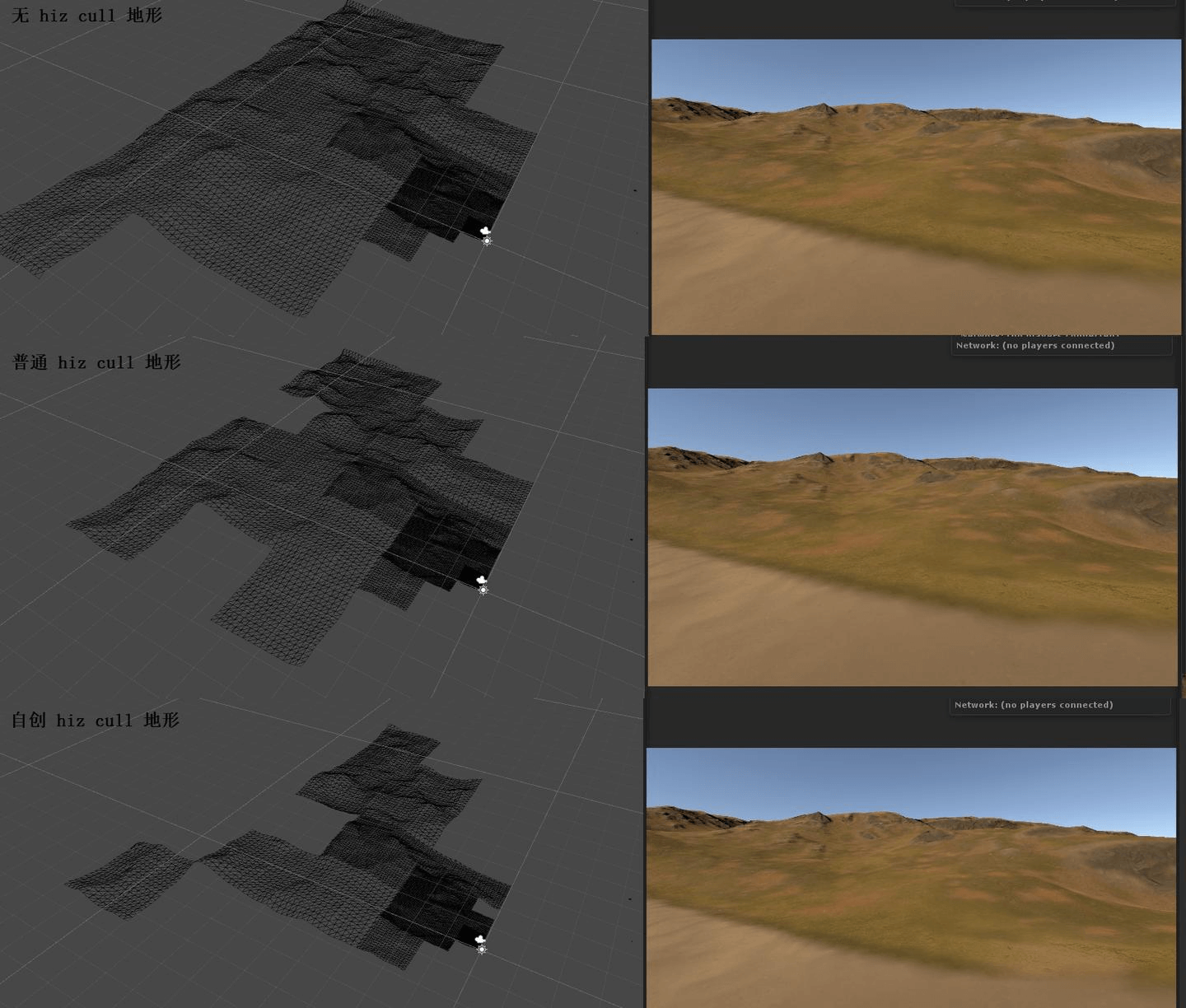
改造的HIZ裁剪
普通的视锥剔除HIZ剔除非常常见,这里不再重复讲。但是关于我自己对于常规算法的改造,是比较想分享的。不熟悉HIZ常规算法的需要先了解下,为了方便讲解,这里假设屏幕与HIZ Depth都是1024x1024的正方形。
假设现在一个地形Patch在屏幕上比较扁平(地形的特殊性导致大量投影到屏幕后扁平),比如18x68像素,根据普通算法需要找到128x128屏幕对于一个像素的Depth MipLevel,连续的判断2x2个,也就是256x256像素内都要遮挡才会剔除。这个太过保守了。扁平的AABB,最后去找正方形的深度像素比对,等于浪费了短边的信息,和68x68大小的AABB结果无差了。所以思路是避免扁平,避免的办法比较简单我想的是 在长的方向上切割成2个AABB,这里就是2个18x34的AABB了,这样来查询是分别寻找2x2个64x64,这样是查找2个128x128,比一个256x256少了一半,所以可以更多的剔除。这对于没有开发prez的项目非常有用,因为这种GPU剔除的渲染方式很难高性能做排序,如果重叠PS的开销巨大,无法有效利用EarlyZ,如果强行要用GPU排序,这里经过测试,推荐GitHub上的双调排序:

拆分扁平AABB 分别判断遮挡
这是侑虎科技第1713篇文章,感谢作者jackie 偶尔不帅供稿。欢迎转发分享,未经作者授权请勿转载。如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群:793972859)
作者主页:https://www.zhihu.com/people/jackie-93-85-85
再次感谢jackie 偶尔不帅的分享,如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群:793972859)




![LeetCode 2769[找出最大的可达成数字]](https://img2024.cnblogs.com/blog/3512406/202411/3512406-20241119101006624-607476152.png)