DateHistogram 用于根据日期或时间数据进行分桶聚合统计。它允许你将时间序列数据按照指定的时间间隔进行分组,从而生成统计信息,例如每小时、每天、每周或每月的数据分布情况。Elasticsearch 就支持 DateHistogram 聚合,在关系型数据库中,可以使用 GROUP BY 配合日期函数来实现时间分桶。但是当数据基数特别大时,或者时间分桶较多时,这个聚合速度就非常慢了。如果前端想呈现一个时间分桶的 Panel,这个后端接口的响应速度将非常感人。于是我决定用 Flink 做一个实时的 DateHistogram。
DateHistogram 用于根据日期或时间数据进行分桶聚合统计。它允许你将时间序列数据按照指定的时间间隔进行分组,从而生成统计信息,例如每小时、每天、每周或每月的数据分布情况。Elasticsearch 就支持 DateHistogram 聚合,在关系型数据库中,可以使用 GROUP BY 配合日期函数来实现时间分桶。但是当数据基数特别大时,或者时间分桶较多时,这个聚合速度就非常慢了。如果前端想呈现一个时间分桶的 Panel,这个后端接口的响应速度将非常感人。于是我决定用 Flink 做一个实时的 DateHistogram。
- Flink 实战之 Real-Time DateHistogram
- Flink 实战之从 Kafka 到 ES
DateHistogram 用于根据日期或时间数据进行分桶聚合统计。它允许你将时间序列数据按照指定的时间间隔进行分组,从而生成统计信息,例如每小时、每天、每周或每月的数据分布情况。
Elasticsearch 就支持 DateHistogram 聚合,在关系型数据库中,可以使用 GROUP BY 配合日期函数来实现时间分桶。但是当数据基数特别大时,或者时间分桶较多时,这个聚合速度就非常慢了。如果前端想呈现一个时间分桶的 Panel,这个后端接口的响应速度将非常感人。
我决定用 Flink 做一个实时的 DateHistogram。
实验设计
场景就设定为从 Kafka 消费数据,由 Flink 做实时的时间分桶聚合,将聚合结果写入到 MySQL。
源端-数据准备
Kafka 中的数据格式如下,为简化程序,测试数据做了尽可能的精简:
testdata.json
{"gid" : "001254500828905","timestamp" : 1620981709790
}
KafkaDataProducer 源端数据生成程序,要模拟数据乱序到达的情况:
package org.example.test.kafka;import java.io.InputStream;
import java.nio.charset.StandardCharsets;
import java.util.Properties;
import java.util.Random;
import java.util.Scanner;import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;import com.alibaba.fastjson.JSONObject;public class KafkaDataProducer {private static final String TEST_DATA = "testdata.json";private static final String GID = "gid";private static final String TIMESTAMP = "timestamp";// 定义日志颜色public static final String reset = "\u001B[0m";public static final String red = "\u001B[31m";public static final String green = "\u001B[32m";public static void main(String[] args) throws InterruptedException {Properties props = new Properties();String topic = "trace-2024";props.put("bootstrap.servers", "127.0.0.1:9092");props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");Producer<String, String> producer = new KafkaProducer<String, String>(props);InputStream inputStream = KafkaDataProducer.class.getClassLoader().getResourceAsStream(TEST_DATA);Scanner scanner = new Scanner(inputStream, StandardCharsets.UTF_8.name());String content = scanner.useDelimiter("\\A").next();scanner.close();JSONObject jsonContent = JSONObject.parseObject(content);int totalNum = 2000;Random r = new Random();for (int i = 0; i < totalNum; i++) {// 对时间进行随机扰动,模拟数据乱序到达long current = System.currentTimeMillis() - r.nextInt(60) * 1000;jsonContent.put(TIMESTAMP, current);producer.send(new ProducerRecord<String, String>(topic, jsonContent.toString()));// wait some timeThread.sleep(2 * r.nextInt(10));System.out.print("\r" + "Send " + green + (i + 1) + "/" + totalNum + reset + " records to Kafka");}Thread.sleep(2000);producer.close();System.out.println("发送记录总数: " + totalNum);}
}
目标端-表结构设计
MySQL 的表结构设计:
CREATE TABLE `flink`.`datehistogram` (`bucket` varchar(255) PRIMARY KEY,`count` bigint
);
bucket 列用于存储时间分桶,形如 [09:50:55 - 09:51:00],count 列用于存储对应的聚合值。
实现
maven 依赖:
<dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-runtime-web</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc</artifactId><version>3.1.2-1.17</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-statebackend-rocksdb</artifactId><version>${flink.version}</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.27</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.72</version></dependency>
</dependencies>
BucketCount 类用于转换 Kafka 中的数据为时间分桶格式,并便于聚合:
package org.example.flink.data;import java.time.Instant;
import java.time.LocalDateTime;
import java.time.ZoneId;
import java.time.format.DateTimeFormatter;public class BucketCount {private long timestamp;private String bucket;private long count;public BucketCount(long timestamp) {this.timestamp = timestamp;this.bucket = formatTimeInterval(timestamp);this.count = 1;}public BucketCount(String bucket, long count) {this.bucket = bucket;this.count = count;}/*** 将时间戳格式化为时间区间格式* * @param time* @return 例如 [11:28:00 — 11:28:05]*/private String formatTimeInterval(long time) {// 定义输出的日期时间格式DateTimeFormatter outputFormatter = DateTimeFormatter.ofPattern("HH:mm:ss");// 将时间戳转换为 LocalDateTime 对象LocalDateTime dateTime = Instant.ofEpochMilli(time).atZone(ZoneId.systemDefault()).toLocalDateTime();// 提取秒数并计算区间开始时间int seconds = dateTime.getSecond();int intervalStartSeconds = (seconds / 5) * 5;// 创建区间开始和结束时间的 LocalDateTime 对象LocalDateTime intervalStartTime = dateTime.withSecond(intervalStartSeconds);LocalDateTime intervalEndTime = intervalStartTime.plusSeconds(5);// 格式化区间开始和结束时间为字符串String startTimeString = intervalStartTime.format(outputFormatter);String endTimeString = intervalEndTime.format(outputFormatter);// 返回格式化后的时间区间字符串return startTimeString + "-" + endTimeString;}// 省略Getter, Setter
}
RealTimeDateHistogram 类完成流计算:
package org.example.flink;import java.time.Duration;import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.contrib.streaming.state.EmbeddedRocksDBStateBackend;
import org.apache.flink.streaming.api.datastream.DataStreamSink;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.triggers.ProcessingTimeTrigger;
import org.example.flink.data.BucketCount;import com.alibaba.fastjson.JSONObject;public class RealTimeDateHistogram {public static void main(String[] args) throws Exception {// 1. prepareConfiguration configuration = new Configuration();configuration.setString("rest.port", "9091");StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);env.enableCheckpointing(2 * 60 * 1000);// 使用rocksDB作为状态后端env.setStateBackend(new EmbeddedRocksDBStateBackend());// 2. Kafka SourceKafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers("127.0.0.1:9092").setTopics("trace-2024").setGroupId("group-01").setStartingOffsets(OffsetsInitializer.latest()).setProperty("commit.offsets.on.checkpoint", "true").setValueOnlyDeserializer(new SimpleStringSchema()).build();DataStreamSource<String> sourceStream = env.fromSource(source, WatermarkStrategy.noWatermarks(),"Kafka Source");sourceStream.setParallelism(2); // 设置source算子的并行度为2// 3. 转换为易于统计的BucketCount对象结构{ bucket: 00:00, count: 200 }SingleOutputStreamOperator<BucketCount> mapStream = sourceStream.map(new MapFunction<String, BucketCount>() {@Overridepublic BucketCount map(String value) throws Exception {JSONObject jsonObject = JSONObject.parseObject(value);long timestamp = jsonObject.getLongValue("timestamp");return new BucketCount(timestamp);}});mapStream.name("Map to BucketCount");mapStream.setParallelism(2); // 设置map算子的并行度为2// 4. 设置eventTime字段作为watermark,要考虑数据乱序到达的情况SingleOutputStreamOperator<BucketCount> mapStreamWithWatermark = mapStream.assignTimestampsAndWatermarks(WatermarkStrategy.<BucketCount>forBoundedOutOfOrderness(Duration.ofSeconds(60)).withIdleness(Duration.ofSeconds(60)).withTimestampAssigner(new SerializableTimestampAssigner<BucketCount>() {@Overridepublic long extractTimestamp(BucketCount bucketCount, long recordTimestamp) {// 提取eventTime字段作为watermarkreturn bucketCount.getTimestamp();}}));mapStreamWithWatermark.name("Assign EventTime as Watermark");// 5. 滚动时间窗口聚合SingleOutputStreamOperator<BucketCount> windowReducedStream = mapStreamWithWatermark.windowAll(TumblingEventTimeWindows.of(Time.seconds(5L))) // 滚动时间窗口.trigger(ProcessingTimeTrigger.create()) // ProcessingTime触发器.allowedLateness(Time.seconds(120)) // 数据延迟容忍度, 允许数据延迟乱序到达.reduce(new ReduceFunction<BucketCount>() {@Overridepublic BucketCount reduce(BucketCount bucket1, BucketCount bucket2) throws Exception {// 将两个bucket合并,count相加return new BucketCount(bucket1.getBucket(), bucket1.getCount() + bucket2.getCount());}});windowReducedStream.name("Window Reduce");windowReducedStream.setParallelism(1); // reduce算子的并行度只能是1// 6. 将结果写入到数据库DataStreamSink<BucketCount> sinkStream = windowReducedStream.addSink(JdbcSink.sink("insert into flink.datehistogram(bucket, count) values (?, ?) "+ "on duplicate key update count = VALUES(count);",(statement, bucketCount) -> {statement.setString(1, bucketCount.getBucket());statement.setLong(2, bucketCount.getCount());},JdbcExecutionOptions.builder().withBatchSize(1000).withBatchIntervalMs(200).withMaxRetries(5).build(), new JdbcConnectionOptions.JdbcConnectionOptionsBuilder().withUrl("jdbc:mysql://127.0.0.1:3306/flink").withUsername("username").withPassword("password").build()));sinkStream.name("Sink DB");sinkStream.setParallelism(1); // sink算子的并行度只能是1// 执行env.execute("Real-Time DateHistogram");}
}
几个关键点
window
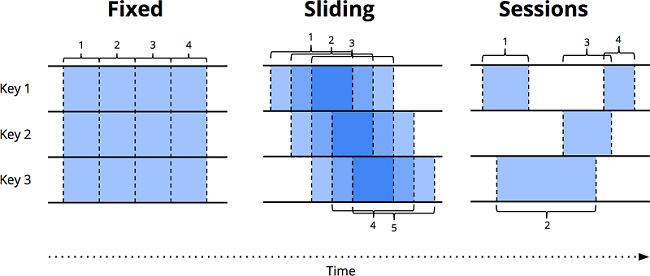
Flink 的 window 将数据源沿着时间边界,切分成有界的数据块,然后对各个数据块进行处理。下图表示了三种窗口类型:
-
固定窗口(又名滚动窗口)
固定窗口在时间维度上,按照固定长度将无界数据流切片,是一种对齐窗口。窗口紧密排布,首尾无缝衔接,均匀地对数据流进行切分。 -
滑动窗口
滑动时间窗口是固定时间窗口的推广,由窗口大小和窗口间隔两个参数共同决定。当窗口间隔小于窗口大小时,窗口之间会出现重叠;当窗口间隔等于窗口大小时,滑动窗口蜕化为固定窗口;当窗口间隔大于窗口大小时,得到的是一个采样窗口。与固定窗口一样,滑动窗口也是一种对齐窗口。 -
会话窗口
会话窗口是典型的非对齐窗口。会话由一系列连续发生的事件组成,当事件发生的间隔超过某个超时时间时,意味着一个会话的结束。会话很有趣,例如,我们可以通过将一系列时间相关的事件组合在一起来分析用户的行为。会话的长度不能先验地定义,因为会话长度在不同的数据集之间永远不会相同。
EventTime
数据处理系统中,通常有两个时间域:
- 事件时间:事件发生的时间,即业务时间。
- 处理时间:系统发现事件,开始对事件进行处理的时间。
根据事件时间划分窗口 的方式在事件本身的发生时间备受关注时显得格外重要。下图所示为将无界数据根据事件时间切分成 1 小时固定时间窗口:
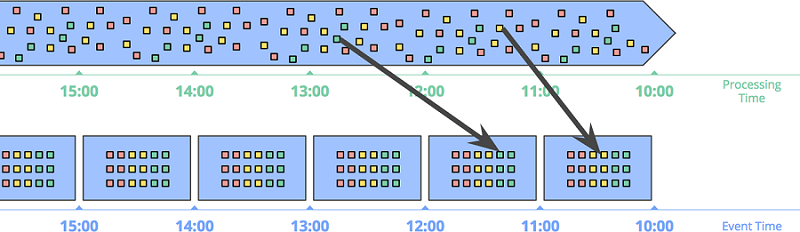
要特别注意箭头中所示的两个事件,两个事件根据处理时间所在的窗口,跟事件时间发生的窗口不是同一个。如果基于处理时间划分窗口的话,结果就是错的。只有基于事件时间进行计算,才能保证数据的正确性。
当然,天下没有免费的午餐。事件时间窗口功能很强大,但由于迟到数据的原因,窗口的存在时间比窗口本身的大小要长很多,导致的两个明显的问题是:
- 缓存:事件时间窗口需要存储更长时间内的数据。
- 完整性:基于事件时间的窗口,我们也不能判断什么时候窗口的数据都到齐了。Flink 通过 watermark,能够推断一个相对精确的窗口结束时间。但是这种方式并不能得到完全正确的结果。因此,Flink 还支持让用户能定义何时输出窗口结果,并且定义当迟到数据到来时,如何更新之前窗口计算的结果。
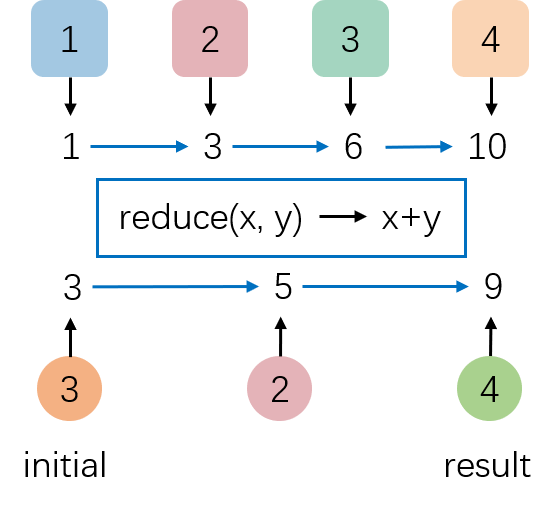
reduce
Reduce 算子基于 ReduceFunction 对集合中的元素进行滚动聚合,并向下游算子输出每次滚动聚合后的结果。常用的聚合方法如 average, sum, min, max, count 都可以使用 reduce 实现。
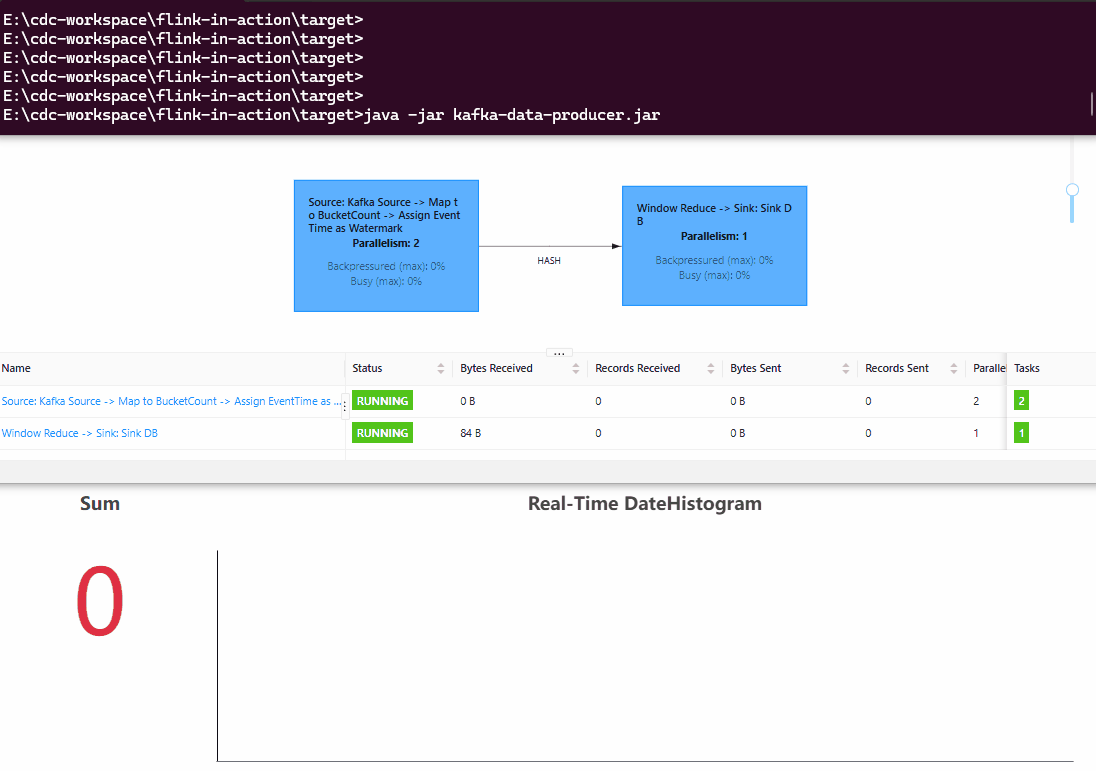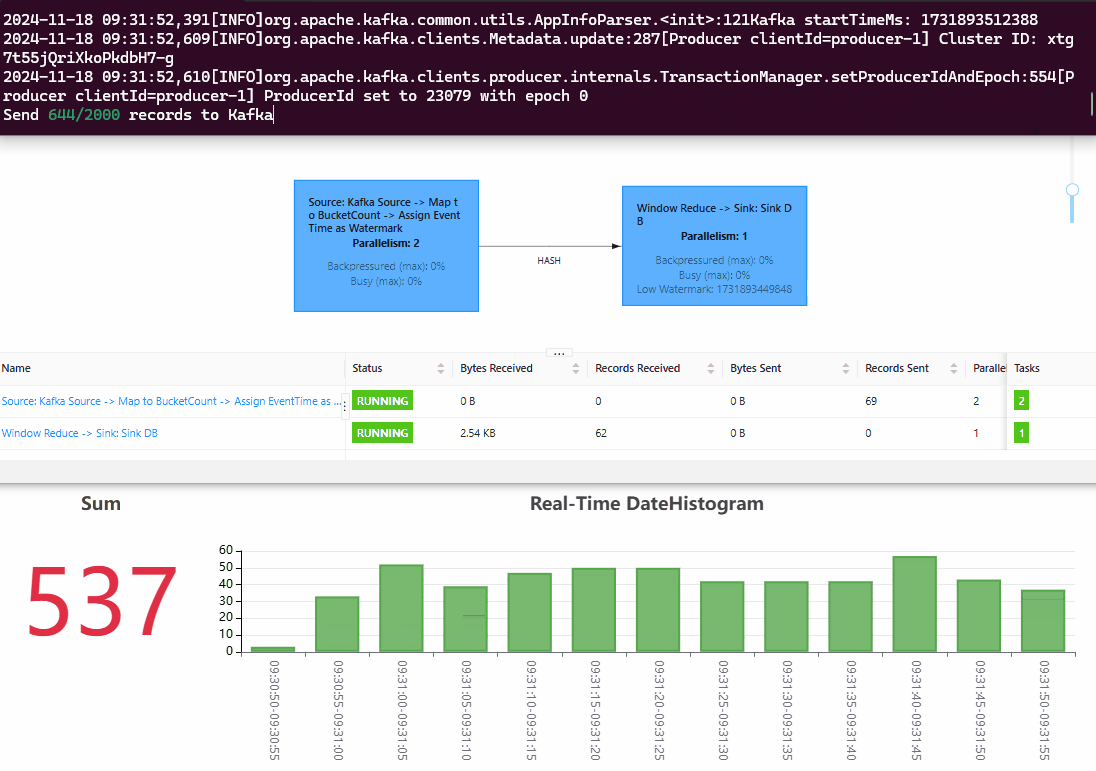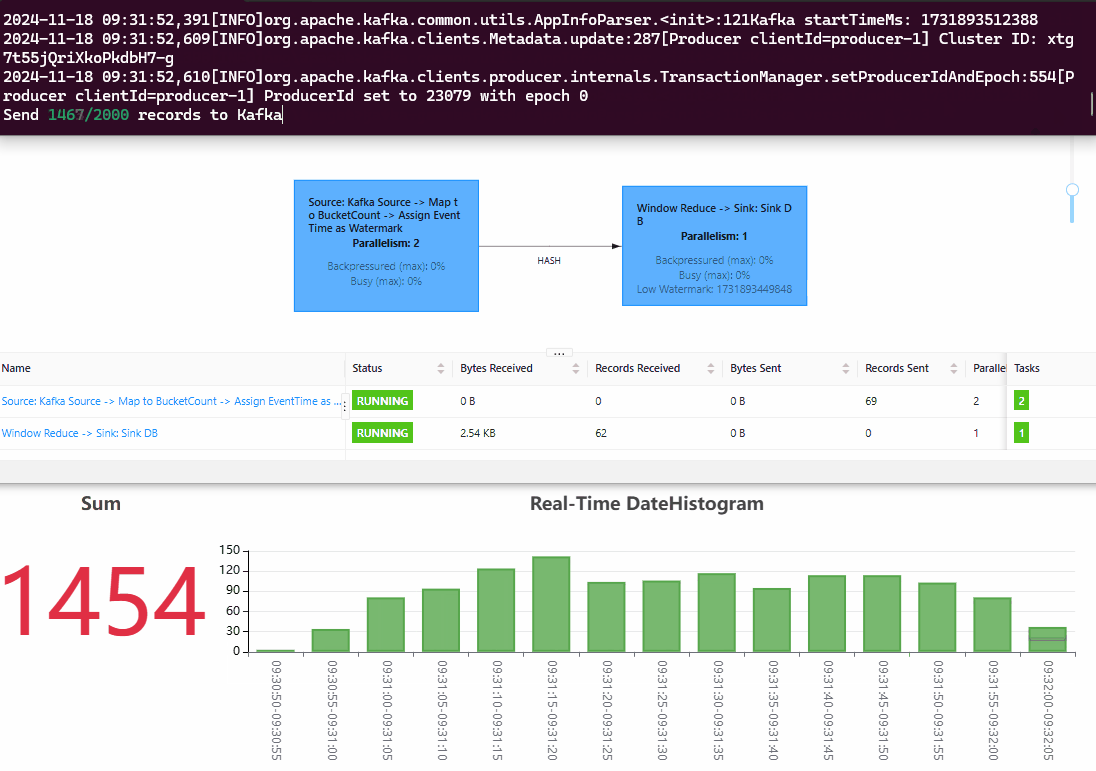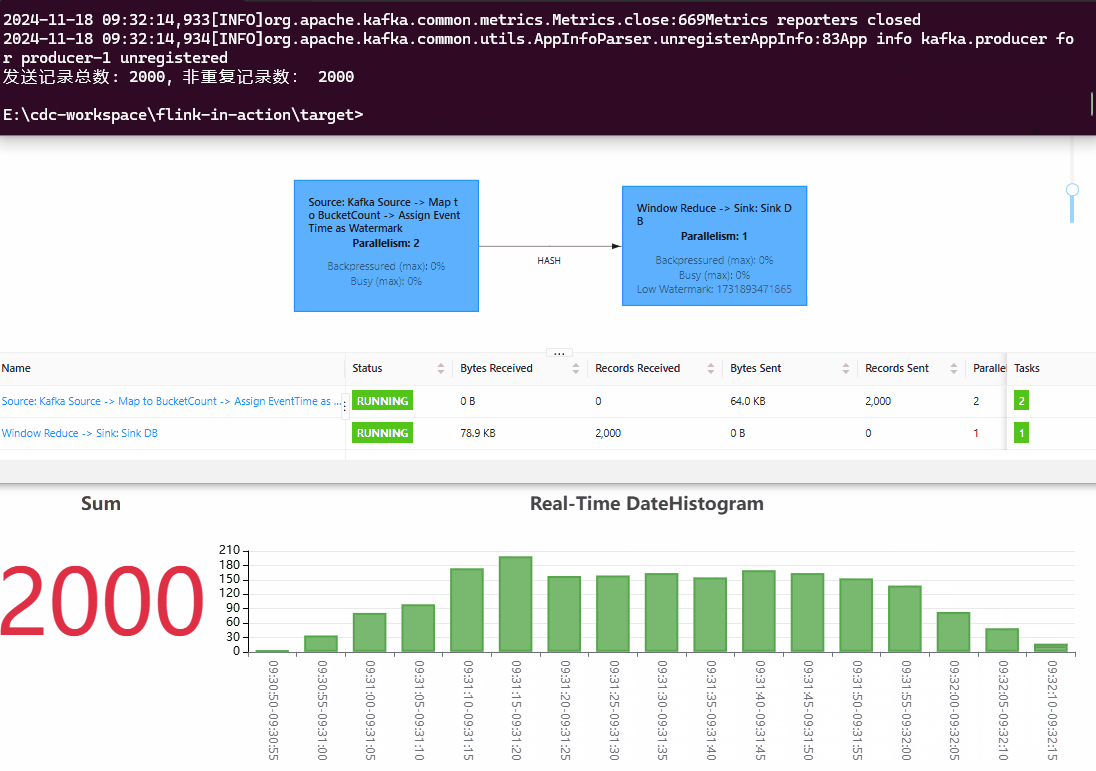
效果预览
从效果图中可以看出,Sum Panel 中的 stat value(为 DateHistogram 中每个 Bucket 对应值的加和)和 Kafka 端的数据跟进的非常紧,代表 Flink 的处理延迟非常低。向 Kafka 中总计压入的数据量和 Flink 输出的数据总数一致,代表数据的统计结果是准确的。此外,最近一段时间的柱状图都在实时变化,代表 Flink 对迟到的数据按照 EventTime 进行了准确处理,把数据放到了准确的 date bucket 中。