张晓攀+原创作品转载请注明出处+《Linux内核分析》MOOC课程https://mooc.study.163.com/course/1000029000
实验八——理解进程调度时机跟踪分析进程调度与进程切换的过程
一、理解Linux系统中进程调度的时机
在 Linux 内核中,schedule() 函数是核心的进程调度机制。它的主要作用是实现进程切换,即选择下一个要运行的进程并将 CPU 控制权转移给它。以下是 schedule() 函数的主要功能和执行流程:
1. 基本功能
-
选择下一个进程:
schedule()根据调度策略(如完全公平调度器 CFS)从就绪队列中选出下一个要运行的进程。 -
切换上下文:
如果选择的新进程与当前进程不同,schedule()会调用context_switch()函数,保存当前进程的上下文(CPU 寄存器、程序计数器等)并恢复新进程的上下文。
2. 函数执行流程
-
检查当前进程状态:
如果当前进程仍然可运行(TASK_RUNNING),它可能会重新被选中;否则,它会被放回等待队列。 -
调用调度策略:
调度器(如 CFS)通过运行特定策略函数来确定下一个进程。CFS 通过一个红黑树数据结构管理就绪进程,选择“最小虚拟运行时间”的进程。 -
执行上下文切换:
当下一个进程被选定后,schedule()会调用context_switch()执行实际的进程切换,包括:- 保存当前进程的 CPU 上下文(栈指针、寄存器等)。
- 加载新进程的上下文。
- 切换到新进程的内核栈。
3. 调用时机
schedule() 通常在以下情况下被调用:
- 当前进程的时间片用完。
- 进程进入阻塞状态(如等待 I/O)。
- 主动调用(如通过
yield()或sched_yield())。 - 中断处理或内核函数需要切换到更高优先级进程。
4. 与调度策略的关系
schedule() 函数本身并不直接决定如何选取下一个进程,而是依赖于具体的调度策略模块(如 CFS、实时调度器)。这些策略定义了如何对进程进行排序和选择。
5. 关键性
schedule() 是整个内核调度的核心接口,对系统的多任务处理和资源分配起到至关重要的作用。它确保了各进程能够公平、高效地共享 CPU 资源。
二、使用 gdb 跟踪分析一个 schedule()函数
1.下载更新menu代码
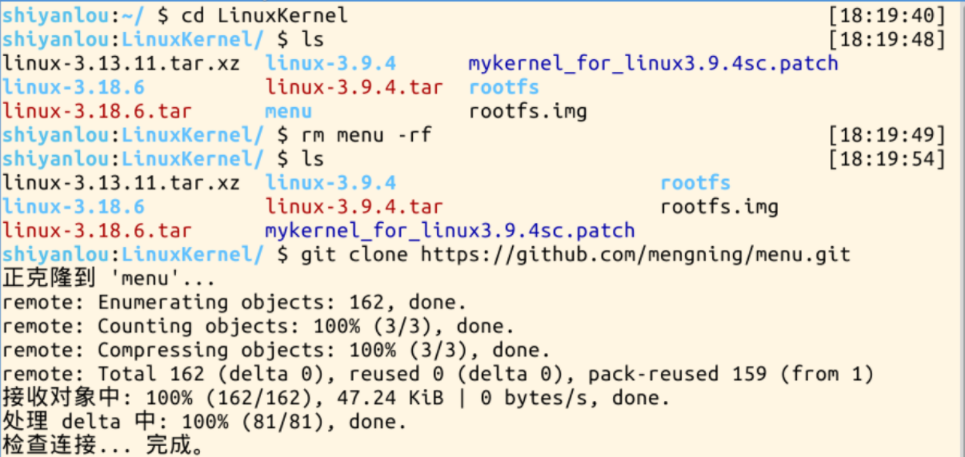
2.重新制作文件系统并进入系统内核调试
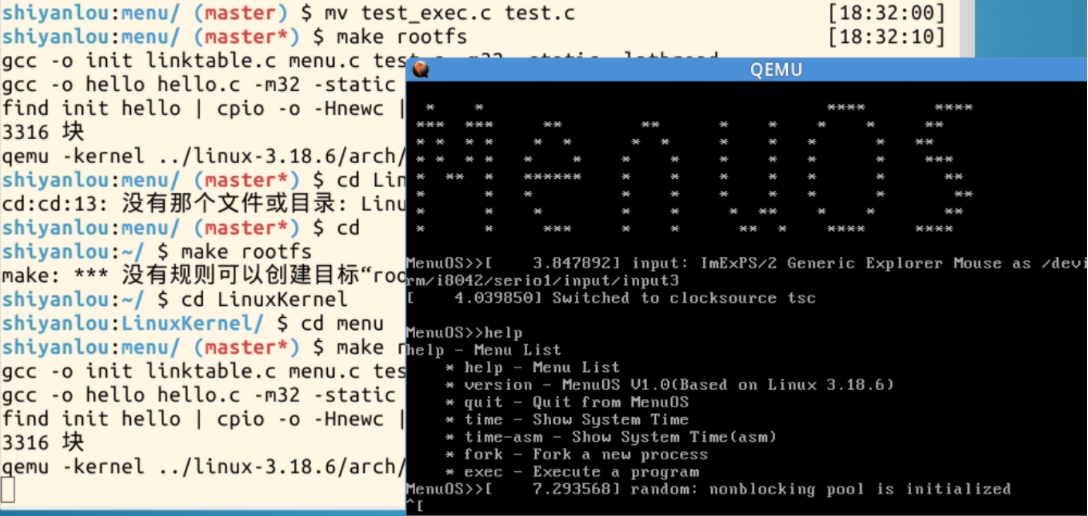
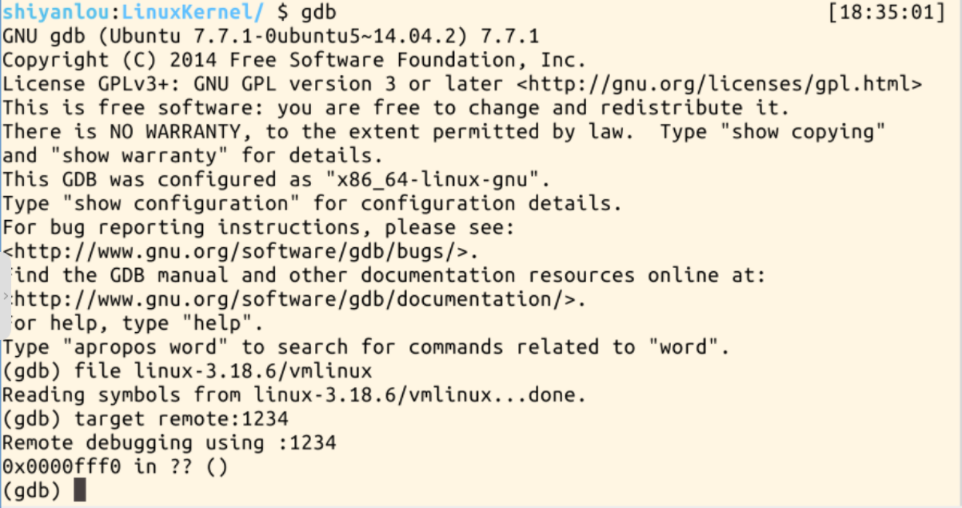
3.设置断点进行调试
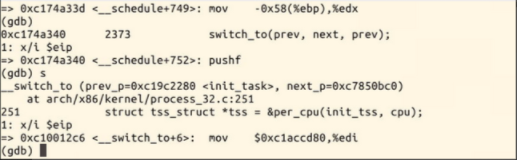
在内核函数schedule的入口处设置断点,接下来输入c继续执行,则系统即可停在该函数处,接下来我们就可以使用命令n或者s逐步跟踪,可以详细浏览pick_next_task,switch_to等函数的执行过程
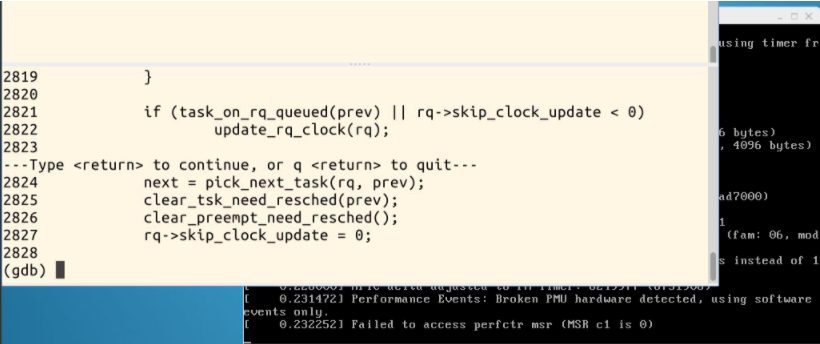
schedule()函数和__schedule()函数:
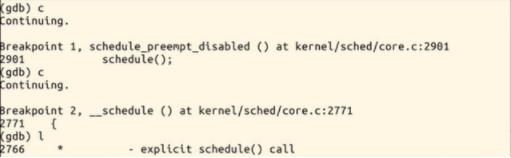
context_switch():
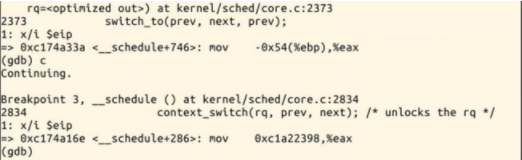
switch_to宏定义:
三、实验总结
进程调度和进程切换是 Linux 内核中多任务管理的核心,它们共同实现了多个进程在 CPU 上的交替执行。以下是两者的简要说明和执行过程:
1. 进程调度(Process Scheduling)
定义:
进程调度是从就绪队列中选择一个合适的进程来运行的过程。其目的是决定哪个进程可以使用 CPU。
调度流程:
- 时间片用尽或阻塞:当前进程因时间片耗尽或等待资源而无法继续运行。
- 调用调度函数:
内核调用schedule()函数,选择下一个进程。 - 选择下一个进程:
根据调度策略(如 CFS)从就绪队列中挑选优先级最高或最符合策略的进程。
2. 进程切换(Context Switch)
定义:
进程切换是将 CPU 从当前进程转移到另一个进程的过程,涉及保存和恢复进程的运行环境(上下文)。
切换流程:
-
保存当前进程的上下文:
- 保存 CPU 寄存器、程序计数器(PC)、堆栈指针(SP)等信息到当前进程的
task_struct。 - 确保当前进程可以在下次调度时从中断点继续运行。
- 保存 CPU 寄存器、程序计数器(PC)、堆栈指针(SP)等信息到当前进程的
-
加载新进程的上下文:
- 恢复新进程的 CPU 寄存器、程序计数器和堆栈指针。
- 将 CPU 控制权转移给新进程。
-
切换内核栈:
- 每个进程都有自己独立的内核栈。
- 切换过程中,需要将内核栈从当前进程切换到新进程的内核栈。
-
返回用户态:
- 当进程从内核态返回用户态时,新进程就开始在 CPU 上运行。
两者的关系
- 进程调度 是逻辑层面的选择:决定谁运行。
- 进程切换 是物理层面的执行:切换 CPU 的执行上下文。
它们共同确保了系统能够在多任务环境下高效、平衡地分配 CPU 资源。