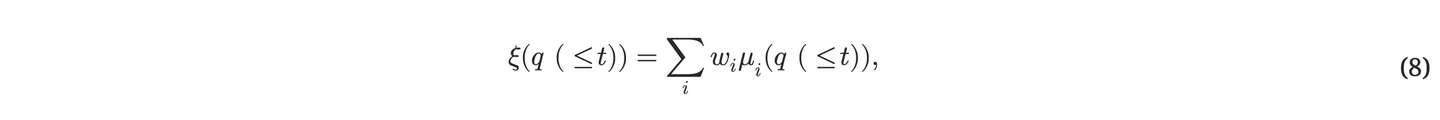【淘汰9成NLP工程师的常识题】多头注意力相对于多头注意力有什么优势?
重要性:★★★ 💯
这是我常用的一个面试题。看似简单的基础常识题,但在面试中能准确回答的不足10% 。
常识题的错误反而会让人印象深刻,反而会暴露面试者对算法模型理解不够深入。
此题的关键主要是考察面试者对软性注意力的理解程度,类似的思想在很多场景都有应用,如门控机制、模型量化等。
Transformer原文中使用了 8 个“scaled dot-product attention”,在同一“multi-head attention”层中,输入均为“KQV”,同时进行注意力的计算,彼此之前参数不共享,最终将结果拼接起来,这样可以允许模型在不同的表示子空间里学习到相关的信息。简而言之,就是希望每个注意力头,只关注最终输出序列中一个子空间,互相独立。
其核心思想在于,多头注意力相比单头注意力是更软的注意力机制,对每个词蕴含的不同语义维度给予不同的权重。
实例:以 All is well 这句话为例,假设我们需要计算 well 的自注意力值。以此为实例来理解多头注意力层的作用。
在计算相似度分数后,我们得到单词 well 的自注意力值:
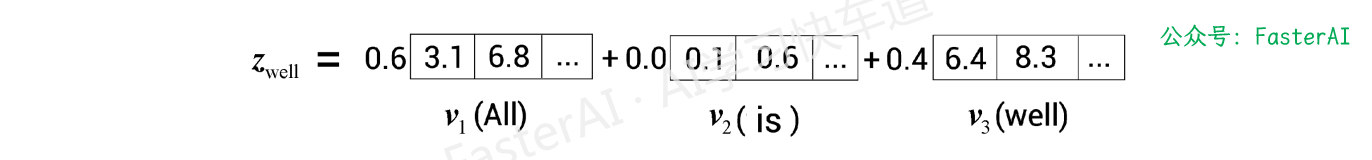
从图中可以看出,well 的自注意力值是分数加权的值向量之和,并且它实际上是由 All 主导的。也就是说,将 All 的值向量乘以 0.6,而 well 的值向量只乘以了0.4。这意味着 zwell 将包含 60%的 All 的值量,而 well 的值向量只有 40%。
因此,如果某个词实际上由其他词的值向量控制,只使用1个头的注意力,就会将关注词所有嵌入维度(不同语义维度)设置为统一的权重,这样反而会引入噪声。
为了确保结果准确,我们不能依赖单一的注意力矩阵,而应该计算多个注意力矩阵,对不同的嵌入维度设置不同的权重,并将其结果串联起来。使用多头注意力的逻辑是这样的:使用多个注意力矩阵,而非单一的注意力矩阵,可以提高注意力矩阵的准确性。。
多头注意力矩阵,公式如下所示:

本文由mdnice多平台发布