NL-SLAM for OC-VLN: Natural Language Grounded SLAM for Object-Centric VLN
用于 OC-VLN 的 NL-SLAM:用于以对象为中心的 VLN 的基于自然语言的 SLAM
【NL-SLAM for OC-VLN: Natural Language Grounded SLAM for Object-Centric VLN 】
文章链接:[2411.07848] NL-SLAM for OC-VLN: Natural Language ...
项目主页:NL-SLAM for OC-VLN: Natural Language Grounded SLAM...
作者单位: 波士顿动力、西蒙·弗雷泽大学、宾夕法尼亚大学、密歇根大学
摘要:基于地标的导航(例如,走到木桌旁)和相对位置导航(例如,向前移动 5 米)是不同的导航挑战,现有的机器人导航方法以不同的方式解决。我们提出了一个新的数据集 OC-VLN,以便在执行基于地标的导航的方法中清楚地评估以地面对象为中心的自然语言导航指令。我们还提出了基于自然语言的 SLAM (NL-SLAM),这是一种将自然语言指令基于机器人观察和位姿的方法。我们积极执行 NLSLAM,以便遵循以对象为中心的自然语言导航指令。我们的方法利用预先训练的视觉和语言基础模型,不需要特定任务的培训。我们根据相关任务的最先进方法构建了两个强大的基线,即对象目标导航和视觉语言导航,并且我们表明,我们的方法 NLSLAM 在 OC-VLN 上的所有成功指标上都优于这些基线。最后,我们成功证明了 NL-SLAM 在波士顿动力 Spot 机器人上在现实世界中执行导航指令跟踪的有效性。 OC-VLN 数据集、代码和视频可在 sonia-raychaudhuri.github.io/nlslam 获取。
一、引言
人类通过使用地标来确定他们在世界上的位置来进行视觉导航。地标是场景中的独特地点,例如物体或拓扑特征(例如特定的树或建筑物)。虽然我们可以理解距当前位置的相对运动(例如,向前移动 5 米),但需要将这种空间理解建立在地标的基础上,才能理解我们的位置更大的区域(例如,现在我在前门旁边)[1]–[4]。为了遵循导航指令,人类将自然语言描述的地标与环境中观察到的真实地标关联起来,以同时了解它们在指令中和世界中的位置。
研究地图和导航的机器人专家已经开发出根据视觉观察创建地标地图并使用这些地图进行自主导航的方法[5]-[11]。事实上,这一领域的工作已经成熟到足以超越研究界。基于地标的地图和导航系统广泛应用于许多行业应用中的自主机器人操作,包括家用机器人真空吸尘器[12]、[13]和用于测量和检查的无人机[14]。随着大型语言和视觉语言模型[15]-[20]在自然语言理解方面的最新进展,下一个前沿是确定如何在这些成熟的机器人中准确地将自然语言导航指令与基于观察的自主决策能力结合起来。系统。
为了支持这个方向的研究,研究人员开发了评估自主代理在模拟中遵循自然语言导航指令的能力的基准,特别是 R2R [21]、RxR [22] 和 VLNCE [23]。这些基准由自然语言指令的数据集以及通过住宅内部扫描的 Matterport 3D 场景的相关路径组成 [24]。这些数据集包含两个不同的导航挑战。语言指令包含对地标的以对象为中心的引用和对当前代理位置的相对位置引用。例如,分别是“走到蓝色椅子上,然后左转并停在木桌前”与“向前移动并左转并停在走廊”。
在这项工作中,我们研究了以对象为中心的 arXiv:2411.07848v1 [cs.RO] 12 Nov 202 指令单独遵循的能力。解决这两个挑战具有重大价值。这个价值可以从认知科学和机器人学的角度来理解。神经科学研究人员发现,大脑的不同区域使人们能够使用观察到的场景对象执行基于地标的空间导航[1]。虽然成功的人工智能算法通常不会直接模仿人类神经功能,但机器人专家在管理基于地标的导航[25]和相对位置导航[26]-[28]方面也有着悠久的历史,方法论方法明显不同。生物系统和自主导航算法的这种区别促使我们考虑,这些不同类型的导航的成功语言基础也可以通过不同的方法来实现。
贡献。在这项工作中,我们提出了一个专门以对象为中心的导航指令跟随命令(OC-VLN)的视觉语言导航数据集。我们还提出基于自然语言的 SLAM (NL-SLAM),将自然语言导航指令基于机器人的观察和位姿。我们提出了一种新颖的导航策略来主动执行 NL-SLAM,以便遵循 OC-VLN 上的自然语言指令。我们的新颖方法利用预先训练的视觉和语言基础模型,不需要针对特定任务的培训。最后,我们展示了 NL-SLAM 在 Boston Dynamics Spot 机器人上执行现实世界导航指令的可行性。
二.相关工作
地标自然语言基础。最近,人们对将 2D 基础模型的信息融合到 3D 场景表示中产生了浓厚的兴趣。许多方法使用显式表示(例如点云[29]-[35])或隐式神经表示[36]-[47]来表示每像素语义特征。对于规划对象而不是密集特征的方法,与以对象为中心的表示相比,此类场景表示需要额外的存储和计算。与我们的方法更相似的是,其他方法 [48]、[49] 使用 3D 场景图 (3DSG),其中节点和边分别表示对象和对象间关系。然而,与我们不同的是,这些方法在构建 3DSG 时没有考虑带来的不确定性。
Kimera [9] 是一种 SLAM 方法,可创建分层场景表示,包括动态场景图。他们从度量语义网格构建这个场景图,这是场景表示的基础。我们的方法 NLSLAM 更加轻量级,因为我们只建图与任务相关的对象,而不是场景的完整几何形状。与这些方法不同,NL-SLAM 还结合了从导航指令获得的场景布局的先验知识。视觉语言导航。在视觉和语言导航(VLN)任务[21]-[23]中,机器人遵循密集的自然语言指令描述的路径。这些指令涉及采取诸如转身以及提及物体或区域等动作。两个相关的室内任务 REVERIE [50] 和 SOON [51] 提供了要定位的特定对象的描述。这些任务都描述最终位置而不是完整路径。相比之下,我们的任务 OC-VLN 以对象为中心的方式描述了整个路径,支持基于地标的导航的重点研究。
VLN 和 OC-VLN 的一个基本挑战是如何将密集的自然语言指令与现实世界中的路径对齐。经过训练的方法可以直接从图像观察中发现这种对齐方式[52],或更常见的是,通过利用基于地图的方法[53][57]。然而,这些方法在现实世界中运行的少数情况下一直在努力解决模拟传输问题[58]、[59]。最近,许多 VLN 研究都集中在探索大型语言模型(LLM)和视觉语言模型(VLM)的研究进展对用零样本方法解决 VLN 的能力的影响 [60]-[68]。一些零样本 VLN 方法在现实世界中展示了结果 [62]、[68],它们在模拟中的表现优于经过训练的方法,并取得了良好的结果。最近的一些方法 [65]、[66] 构建拓扑图来存储导航历史和有关观察环境的信息,以支持基于 LLM 的规划器。与这些方法不同,我们的 NL-SLAM 不使用 LLM 作为直接规划器,而是根据指令生成推断位姿图,使我们能够利用机器人技术的现有技术根据观察到的环境调整该推断位姿图同时使用它来遵循指定的路径。
三.数据集
我们引入了以对象为中心的 VLN (OC-VLN) 任务,其中机器人需要按照以对象为中心的指令进行导航以到达目标。我们的任务类似于 VLN [21] 和 VLN-CE [23],其中代理遵循细粒度的指令来到达目标(“沿着走廊走,然后右转。一旦你到达右边的长凳”在地毯上。”)。然而,我们关注将对象指定为地标的指令(例如,以对象为中心的指令)。我们使用与 VLN-CE 相同的代理实施例和任务设置。
数据集生成。我们使用 Habitat 模拟器 [70] 中的 HM3DSem [69] 的真实 3D 扫描生成我们的剧集。 Goat-Bench [71] 是最近引入的一个数据集,其中代理的任务是导航到通过类别名称、图像或语言描述指定的一系列开放词汇对象。我们使用该数据集中的轨迹通过 GPT4 [15] 生成细粒度指令。首先,我们使用一个预言机代理,它遵循真实轨迹并在每一步保存 RGB 图像。接下来,我们继续生成一条导航指令,使代理能够从轨迹的起点到达终点。我们分两个阶段进行:阶段 1:我们使用轨迹第一帧和最后一帧的 RGB 图像提示 GPT4,并要求它提取关键对象;阶段 2:然后,我们提示 GPT-4 提供为轨迹收集的所有连续图像以及阶段 1 中的对象名称,并要求它生成细粒度的以对象为中心的指令。
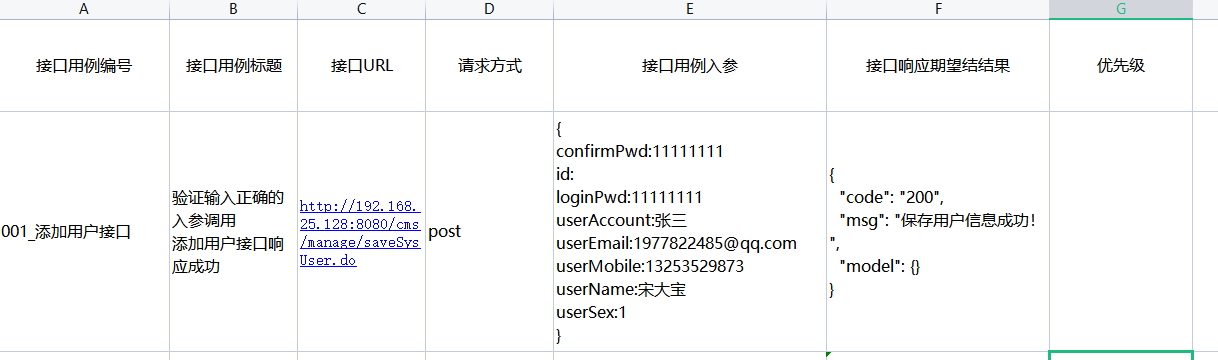
统计数据。 OC-VLN 包含跨度约 7m 的片段,并具有开放词汇语言指令(图 2),平均包含 29 个单词、8 个子指令和 8 个对象。我们支持连续环境和 2DoF 动作空间,类似于 VLN-CE(表 I)。虽然我们的路径长度较短,但与 VLNCE 相比,指令仍然更长,这表明我们的指令对于每个路径有更多的信息(以对象为中心)
表 I:数据集比较。 OC-VLN数据集支持2DoF动作空间的连续环境中的运动,平均指令长度为29个字。


图 2:OC-VLN 指令包含各种常见的家用物品(左)和操作指令(右)。
四.方法
我们的 NL-SLAM 方法源于一个关键见解:语言指令不仅指导机器人的导航,还对有关环境布局的关键空间信息进行编码。即使在进行任何观察之前,这些指令也可以让机器人对环境地图有初步的了解,尽管存在很大的不确定性。例如,指令“向前移动,直到看到椅子”。意味着相对于机器人当前位置沿 x 轴(向前方向)的某处存在椅子。通过将这种空间信息表示为因子图,我们可以将其作为先验集成到传统的基于因子图的 SLAM 系统中。当机器人观察说明中提到的地标时,与这些地标相关的不确定性大大减少。这种不确定性的减少有助于机器人在导航过程中根据指令进行定位,有效地弥合语言指导和空间意识之间的差距。我们的方法的概述如图 1 所示。

图 1:我们提出了 OC-VLN 数据集,其中包含以对象为中心的自由形式语言指令(左),以及 NL-SLAM 将自然语言指令转化为机器人观察结果,并主动遵循指令执行导航(右)。
A. 从语言指令推断建图先验
我们将语言指令转换为语言推断图,即因子图 [72],它对从语言输入导出的环境建图的先验分布进行编码。该图包括两种类型的随机变量节点:(1) 路点节点 W = {wi ∈ SE(2)},表示机器人应导航到的推断但未知的路点,以及 (2) 地标节点 L = { lj ∈ R2} 表示机器人预计沿其路径观察的物体的未知位置。例如,考虑一下指令:“向前走到钢琴处,然后右转并停在桌子处。”。由此产生的推断图如图 4 所示,包括四个路点节点:w0,起始点; w1,位于钢琴处; w2,代表右转;和w3,牌桌上的最后一站。此外,还有两个标志性节点:l0 代表钢琴,l1 代表桌子。

图 4:从指令“向前走到钢琴,然后右转并停在桌子处”的指令得出的语言推断因子图。请参阅文本了解更多详细信息。
根据指令中描述的几何关系,推断图表示航路点和地标的以下联合分布:

其中 R = Rww ∪ Rwl 是指令中所有预定义几何关系的集合,包括航路点间关系 Rww = {rww i,i+1} 和航路点-地标关系 Rwl = {rwl ij }。该图包括两种类型的因子:航点间因子 p(Rww|W ) = Q i p(rww i,i+1|wi, wi+1) 和地标航点因子 p(Rwl|W, L) = Q ij p (rwl ij |wi, lj )。
航路点间因子 p(rww i,i+1|wi, wi+1) 基于动作动词捕获连续航路点之间的几何关系。对于“前进”,相对位姿 rww 01 在 SE(2) 中被建模为高斯,平均值 rww 01 = (x > 0, y = 0, θ = 0) 表示向前运动。由于距离模糊,x 分量具有高方差,而 y 和 θ 具有低方差。这种方法扩展到其他动作,其手段和差异源自相应的动词。
地标航路点因子 p(rwl ij |wi, lj) 表示航路点与说明中提到的对象之间的空间关系。在我们的示例中,航路点 w1 和钢琴地标 l0 被建模为接近:p(rwl 10 |w1, l0) ∼ N (0, Σ),其中零均值表示没有偏移,小 Σ 对角线元素表示较低的位置不确定性。
推断图的说明文本。我们利用大型语言模型 (LLM) 将自由格式的文本指令转换为语言推断图。我们使用 GPT-4 [15] 通过以下提示将指令解码为路径点、地标及其关系的有序序列:“您是引导家庭导航机器人的专家。机器人想要遵循详细的语言指令到达目标目的地。为了成功完成此任务,您将分解输入的“指令”以输出“航点”、“地标”、“航点到航点过渡动作”和“航点到地标空间关系”的列表。”我们进一步提供了包含 10 个示例的列表以及提示。图 3 显示了示例输出。接下来,我们使用“路点”列表中的路点节点(wi)、“地标”列表中的地标节点(li)、“路点到路点转换动作”中的路点间因子以及来自“航点-地标空间关系”的地标-航路点因素。对于这两种因子类型,我们使用 x 和 y 中的平均位移 2m 来初始化高斯。平均值的初始值取决于过渡动作的类型和地标-航路点关系。

图 3:使用 LLM,我们提取航点、地标、航点-航点动作以及地标-航点关系。
B. 具有推断地图先验的 SLAM
我们的框架将语言推断地图先验集成到传统的基于对象的 SLAM 导航系统中。由于语言描述固有的模糊性和缺乏直接的感官信息,先前的地图最初具有很高的不确定性。当机器人导航时,它同时在这个不确定的地图中定位自己,同时通过观察完善地图,逐渐将模糊的语言描述转化为精确的空间表示。
主要目标是找到机器人位姿 X、观察到的地标 O、语言推断的路点 W 和地标 L 上的关节分布的最大后验 (MAP) 估计,以所有传感器观察 Z 和之间关系的语言描述为条件。形式上,这表示为: X*, O*, W*, L* = argmaxX,O,W,L p(X, O, W, L| Z, R) 可以分解为两个组成部分:

第一项 p(X, O| Z) 是传统的基于地标的 SLAM 问题,可以使用最先进的 SLAM 算法有效地解决[10]、[11]、[72]。第二项 p(W, L|X, Z, R) 包含语言推断的建图:

这里,p(R|W, L) 是我们在等式中推断的因子图。 (1) 和 p(Z|L, X) = Q ik p(zjk|lj, xk) 是地标观测似然因子,其中 zjk 是当机器人处于姿态 xk 时与推断地标 lj 相关的观测值。这些因素对于减少推断地标的不确定性至关重要,从而提高准确性并减少相关航路点的不确定性。使用标准因子图 SLAM 包(例如 [73])可以有效地优化用地标观测因子增强的推断图,从而使我们能够利用已建立的 SLAM 解决方案,同时将我们新颖的语言通知先验与真实的感官观察相集成。
C. 推断地标和观测值的数据关联
创建等式中的地标观测因子 p(zjk|lj, xk)。 (2)、我们必须在推断的地标和观测值之间进行数据关联。在这种情况下,一个地标可能有多个候选观察匹配,并且一个观察可能与多个地标匹配。虽然这个数据关联问题可以使用期望最大化(EM)[74]、[75]或离散连续因子图[76]上的混合推理来解决,但我们选择了一种更简单的方法。我们的方法将地标与观察值配对,选择其 CLIP [18] 文本特征之间余弦相似性的最佳匹配:

其中 Ft(.) 通过对推断图中的地标名称进行编码来提供文本特征,Fo(.) 给出观察的文本特征。如果相似度低于阈值,则不进行关联。这种方法提供了有效性和计算效率之间的平衡。系统的未来迭代可能会探索更复杂的数据关联技术来处理不明确的情况。
D. 导航策略
在语言推断的地图中定位机器人可以实现简单的导航策略:机器人通过顺序移动到推断的路径点进行导航,在每个路径点的 0.5m 范围内进行转换,并在最后一个路径点停止。然而,航路点位置的高度不确定性可能导致导航不准确。在这些情况下,机器人应该切换到探索模式,寻找地标以减少即将到来的航路点的不确定性。
为了平衡探索和利用,我们采用以下策略进行航路点选择:

该方程选择推断的航路点 wj,最小化两个因素:航路点与当前机器人位姿之间的距离 (||wj ⊖ xi||2),以及航路点的不确定性,由其信息矩阵 Λ = 的迹表示Σ−1。权重常数 α 平衡了向附近航路点移动的愿望与减少不确定性的需要。
为了确定精确的导航目标,我们进一步从 w* 周围的可导航区域内的后验分布 p(w*) 中采样一个点。最初,航路点的后验分布具有很高的不确定性,促进了探索。当机器人收集观察结果时,不确定性就会减少,从而完善导航目标。这种自适应方法使机器人能够高效导航,同时不断提高其空间理解能力。
五.实验
指标。我们使用VLN常用的评估指标[21]、[77]、[78],例如成功率(SR)、按逆路径长度加权的成功率(SPL)、Oracle成功率(OSR)和归一化动态-时间扭曲 (nDTW)。前三个指标根据机器人到达目标物体的能力来衡量机器人的性能,而 nDTW 则衡量机器人遵循指令的程度。
执行。我们在 Habitat 模拟器 [70] 中以零样本方式评估 OC-VLN 上的 NL-SLAM。我们使用预先训练的开放词汇对象检测管道来进行地标识别。给定 RGB 图像,我们使用 RAM [79] 来识别图像中的对象,使用 Grounding-Dino [19] 来预测边界框,最后使用 Segment-Anything (SAM) [20] 来获得语义分割。对于导航器,我们使用在 HM3D [81] 场景上预训练的 PointNav 策略 [80]。我们将我们的方法与两个基线进行比较,这两种基线都是针对现实世界中成功的相关任务的 SOTA 零样本导航方法。
Seq-VLFM 基线。 VLFM [82] 是一种对象-目标导航方法,我们按顺序执行。我们使用 GPT4 [15] 从指令中提取对象,然后运行 VLFM 按顺序转到每个对象。使用 BLIP-2 [83],VLFM 创建可能的对象位置的值图,指导基于边界的探索 [84] 有效地查找对象。 InstructNav 基线。 InstructNav [85] 是一种用于一般导航指令的方法,它评估对象目标导航、VLN 和需求驱动的导航任务。 InstructNav 使用法学硕士将导航指令分解为一系列配对的动作和地标。然后,它计划如何使用值图的组合到达每个地标,这些值图代表有关环境及其与机器人的关系的关键信息,例如语义信息、动作、轨迹历史和法学硕士的直觉。他们在每个决策步骤中与法学硕士一起重新规划,以更好地使计划适应观察到的环境。
六.结果
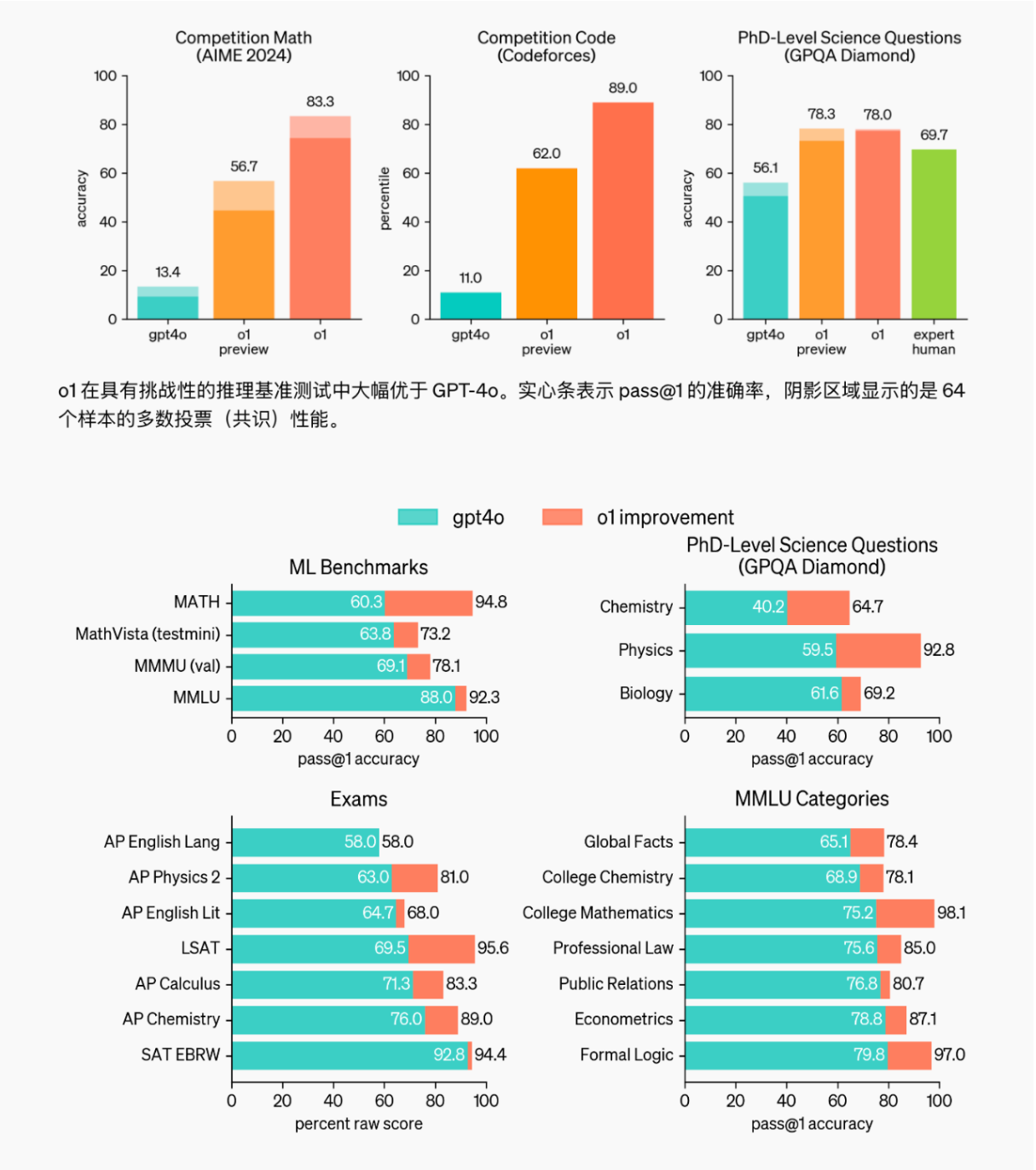
基准结果。表 II 显示 NL-SLAM 在所有指标上都优于基线方法。我们在 nDTW 指标 (48%) 上的表现明确表明我们的方法能够比其他方法更好地遵循指令。这是直观的,因为我们的方法将指令转换为图形,然后用于执行导航,而 Seq-VLFM 则通过从指令中提取对象来搜索对象,从而忽略编码到其中的动作和关系。能够遵循说明还使 NL-SLAM 能够按照 SR 和 SPL 指标的性能所指示的建议路径成功到达目标对象。 OSR指标反映了代理是否已经接近目标对象并且未能停止。我们发现所有方法都在数据集上实现了合理的 OSR。然而,与其他方法相比,NL-SLAM 的 SR 和 OSR 之间的差距较小(20%)(Seq-VLFM 中为 42%,InstructNav 中为 43%),这表明我们的方法能够更频繁地正确调用停止操作与其他人相比。
表二:性能。 NL-SLAM 在所有指标上都显着优于 Seq-VLFM 和 InstructNav。

定性分析。在图 5 中,我们可视化了代理在单个情节上随时间的表现。在剧集开始时 (t = 1),当智能体尚未对世界进行观察时,地标节点 (li = {l1 = “brown couch”, l2 = “fireplace”}) 和航路点节点(wi = {w2, w3}) 具有很大的不确定性(可视化为椭圆)。随着情节的进展,智能体在 t = 20 时进行第一次观察,并根据 l1 和 w1,从而确定它们的位置。在 t = 50 时,代理观察到 l2,从而减少了推断图中所有节点的不确定性。最后,当代理位于图中最后一个航路点 w2 0.5m 范围内时,代理会生成“停止”操作。为了比较 NL-SLAM 和 Seq-VLFM,我们将不同场景的智能体轨迹可视化(图 6),并观察到与 Seq-VLFM 相比,NL-SLAM 中的智能体更好地遵循指令。从我们方法中代理路径与真实路径的匹配程度可以明显看出这一点。

图 5:NL-SLAM 的实际应用。通过一个情节可视化我们的代理的进度,显示了语言推断图如何随着时间 t 得到优化,从而成功完成。
(左)显示检测到的物体; (右)显示当前的机器人姿态、地面实况轨迹(绿色)、推断的路径点(黄色)和地标(蓝色)。

图 6:比较。我们的智能体(右)轨迹与地面实况轨迹的一致性比 Seq-VLFM(左)更好,表明指令跟踪能力更好。代理轨迹为蓝色,地面实况路径为绿色,目标对象为红色。
消融。我们对 NL-SLAM 中的不同模块(表 III)进行消融,以了解每个模块的贡献。对于对象检测器和导航器,我们发现使用 Oracle 的效果最好,正如预期的那样。 Oracle 检测器+导航器的成功率提高了 +12%,SPL 提高了 +13%,nDTW 提高了 +10%,这表明我们方法的性能受到检测器和导航器的选择的限制,可以通过进一步改善。
表 III:消融。 Oracle 版本的对象检测器和导航器的性能优于预训练模型,表明 NL-SLAM 的改进范围。

故障分析。我们注意到两个主要的失败案例:(a)存在同一对象类别的多个实例; (b) 对象的错误分类。在第一种情况下,当有多个门时,“穿过一扇打开的门”的指令(图 7)使得智能体很难找出正确的“门”。第二种情况是限制对象检测器错误地将“电视”识别为“壁炉”,导致错误的数据关联。真实世界的演示。我们在 Boston Dynamics 的 Spot 机器人上部署了 NL-SLAM,以展示其在现实世界中的有效性。我们使用 Boston Dynamics Spot SDK 替换了 PointNav 策略作为将机器人移动到航路点的导航器。我们使用 RTAB-Map 来获取机器人的坐标和参考系中的观测值。我们使用 YOLOv7 [86] 来代替我们的对象检测管道,以实现更快的实时执行。我们在一个有椅子、桌子、盆栽等常见物体的办公空间中运行了 NLSLAM,并证明我们的方法能够在这项任务中表现良好。

图 7:失败案例。 NLSLAM 中两个常见的失败案例是:(上)同一地标存在多个实例,例如'门'; (底部)一个对象被错误分类,例如“电视”被识别为“壁炉”。
七.结论
我们提出了 OC-VLN,这是一个用于以对象为中心的视觉和语言导航的数据集,使我们能够研究基于对象的导航指令跟踪的独特挑战。为了解决这个任务,我们提出了 NL-SLAM,它使用位姿图将指令中的对象稳健地接地到环境中的观察。 NL-SLAM 使用 LLM 根据指令创建推断位姿图,从而将相关信息合并为位姿图的先验信息。与两个基线 Seq-VLFM [82] 和InstructNav [85] 在相关任务上表现良好,表明 NL-SLAM 在所有指标上都优于它们。
当存在多个相同类别的对象时,NL-SLAM 可能很难识别相关对象。这可以通过结合场景布局先验来预测尚未观察到的地标的可能位置,从而确定整个路径的有希望的方向来解决。主动选择位姿以获得物体的多个良好视图,或许从主动 SLAM 中汲取灵感,是解决 NL-SLAM 失败的另一个重要原因(即物体错误分类)的一种途径。更复杂的数据关联技术也可以减轻这些限制。
虽然以对象为中心的视觉和语言导航作为一个独特的问题还远未得到解决,但未来的工作还应该进行模块化研究,包括 VLN 中存在的更多方面。例如,区域作为地标和对象。