高可用服务
读写分离
计算节点支持读写分离功能,并且支持配置读写分离权重
读写分离功能说明
要使用读写分离功能,需在数据节点中配置主备存储节点。
读写分离功能默认设置为关闭。开启读写分离功能,可在计算节点的配置文件server.xml中,将strategyForRWSplit属性设置为大于0的值。例如:
<property name="strategyForRWSplit">1</property>
strategyForRWSplit允许设置的值为0,1,2,3。
-
当设置为0时,读写操作都在主存储节点,也即关闭读写分离。
-
当设置为1时,代表可分离的读请求发往所有可用存储节点(包含主存储节点),写操作与不可分离的读请求在主存储节点上进行。
-
当设置为2时,代表可分离的读请求发往可用的备存储节点,写操作与不可分离的读请求在主存储节点上进行。当设置为3时,代表事务(非XA模式)中发生写前的读请求与自动提交的读请求发往可用的备存储节点。其余请求在主存储节点上进行。
server.xml中可以配置读写分离中可读从库最大延迟时间,参数名:maxLatencyForRWSplit,单位ms,默认配置的延迟时间为1秒。当存储节点数据同步延迟大于设置的延迟时间或者出现故障时计算节点会摘除该存储节点并阻止参与读操作,此时由其他正常存储节点承担可分离的读任务,直至延迟重新追上才将摘除的存储节点加回读集群。
当开启读写分离时,即使心跳未开启,也会强制进行延迟检测。延迟检测周期可在server.xml中通过参数latencyCheckPeriod配置。
计算节点读写分离对应用研发者和数据库管理员完全透明,不要求研发者在SQL执行时添加HINT或某些注解;当然,也支持使用HINT的方式显式指定读取主机或从机。
指定SQL语句在主存储节点上执行:
/*!hotdb:rw=master*/select * from customer;
指定SQL语句在从库存储节点上执行:
/*!hotdb:rw=slave*/select * from customer;
读写分离权重配置
计算节点支持读写分离的同时,可以通过server.xml中配置参数控制主从读的比例。进入计算节点的安装目录的conf目录下,并编辑server.xml,修改如下相关设置:
<property name="strategyForRWSplit">0</property><!-- 不开启读写分离:0;可分离的读请求发往所有可用数据源:1;可分离的读请求发往可用备数据源:2;事务中发生写前的读请求发往可用备数据源:3-->
<property name="weightForSlaveRWSplit">50</property><!-- 从机读比例,默认50(百分比),为0时代表该参数无效-->
-
读写分离策略strategyForRWSplit参数为0时读写操作都在主存储节点,也即关闭读写分离。
-
读写分离策略strategyForRWSplit参数为1时,代表可分离的读请求发往所有可用存储节点(包含主存储节点),写操作与不可分离的读请求在主存储节点上进行。strategyForRWSplit参数为1时可设置主备存储节点的读比例,设置备存储节点读比例后数据节点下的所有备存储节点均分该比例的读任务。例如:设置weightForSlaveRWSplit值为60%,假设节点为一主两从架构,则可分离的读中,主机读40%,剩余两从机各读30%;
-
读写分离策略strategyForRWSplit参数为2时,代表可分离的读请求发往可用的备存储节点,写操作与不可分离的读请求在主存储节点上进行。strategyForRWSplit参数为2时数据节点上的所有可分离的读任务会自动均分至该数据节点下的所有备存储节点上,若无备存储节点则由主存储节点全部承担。
-
读写分离策略strategyForRWSplit参数为3时,代表事务(非XA模式)中发生写前的读请求与自动提交的读请求发往可用的备存储节点。其余请求在主存储节点上进行。
注意
在未使用HINT做读写分离的情况下,
"可分离的读请求"主要指:自动提交的读请求与显式只读事务中的读请求。其余读请求均为"不可分离的读请求"。例如非自动提交事务中的读请求。
用户级别的读写分离
可通过管理平台创建数据库用户页面添加用户或编辑用户开启用户级别的读写分离。
使用用户级别的读写分离功能,需确保计算节点连接用户开启了用户
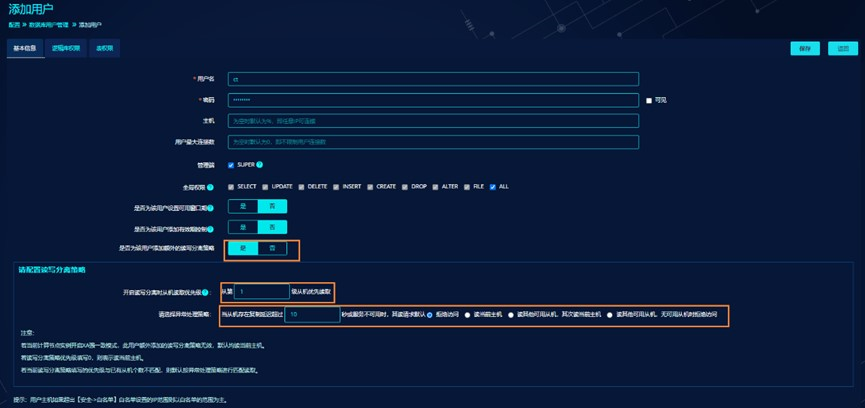
从库复制延迟不大于配置值
异常处理策略选择任意项,用户根据从机读取优先级设置的值读所有数据节点对应优先级的从库
如:自动分片表rw_b_yds分布于以下节点:
| dn_01 | dn_02 |
|---|---|
| 主库:192.168.210.136:3311 | 主库:192.168.210.136:3310 |
| 从库1:192.168.210.137:3311 | 双主备库:192.168.210.137:3310 |
| 从库2:192.168.210.137:3312 | |
| 从库3:192.168.210.137:3313 | |
| 从库优先级:从库1>从库2>从库3 |
从机读取优先级设置的值为1,执行SQL:
root@192.168.210.136:hotdb 5.7.25 10:08:24> select * from rw_b_yds;
+----+------+-----------+
| id | cid | a |
+----+------+-----------+
| 4 | 4 | chongqing |
| 5 | 5 | nanjing |
| 6 | 6 | zhengzhou |
| 1 | 1 | shanghai |
| 2 | 2 | beijign |
| 3 | 3 | tianjin |
+----+------+-----------+
6 rows in set (0.00 sec)
则读dn_01的从库1和dn_02的双主备库,dn_01从库1和dn_02备库的general.log如下:


从库不可用
从机读取优先级的值为1时,当从库不可用时,会根据异常处理策略设置的值匹配对应结果,以上述自动分片表rw_b_yds为例:
1.异常处理策略配置为拒绝访问:
dn_01的从库1或dn_02的备库有一个不可用或都不可用均会拒绝访问
yds@192.168.210.136:hotdb 5.7.25 02:16:07> select * from rw_c_yds;
ERROR 10254 (HY000): No matched readable datasource in node:1 for current user
2.异常处理策略配置为读当前主机:
| 只有dn_01从库1不可用 | 读dn_01主库,dn_02备库 |
|---|---|
| 只有dn_02备库不可用 | 读dn_01从库1,dn_02主库 |
| dn_01从库1和dn_02的备库都不可用 | 读dn_01和dn_02主库 |
3.异常处理策略配置为读其他可用从机,其次读当前主机:
| 只有dn_01从库1不可用 | 读dn_01从库2,dn_02备库 |
|---|---|
| 只有dn_02备库不可用 | 读dn_01从库1,dn_02主库 |
| dn_01的从库1和从库2都不可用 | 读dn_01从库3,dn_02备库 |
| dn_01所有从库和dn_02的备库都不可用 | 读dn_01和dn_02主库 |
4.异常处理策略配置为读其他可用从机,从机不可用时拒绝访问:
| 只有dn_02备库不可用 | 拒绝访问 |
|---|---|
| dn_01下所有从库均不可用 | 拒绝访问 |
| dn_01的从库1和从库2都不可用 | 读dn_01从库3,dn_02备库 |
从库复制延迟大于配置值
从库复制延迟大于配置时,跟上述中从库不可用的匹配结果一致,此处不再赘述
从库数量小于从机读取优先级的值
根据异常处理策略设置的值输出对应结果,以上述自动分片表rw_b_yds为例,假设从机读取优先级设置为10:
-
异常处理策略配置为拒绝访问时:拒绝访问
-
异常处理策略配置为读当前主机:读所有节点主库
-
异常处理策略配置为读其他可用从机,其次读当前主机:读dn_01优先级最高的可用从库和dn_02备库,若dn_01和dn_02下都没有可用从库,则读dn_01和dn_02主库
-
异常处理策略配置为读其他可用从机,从机不可用时拒绝访问:读dn_01优先级最高的可用从库和dn_02备库,若dn_01下没有可用从库或dn_02下备库不可用或dn_01、dn_02都没有可用从库/备库,拒绝访问
注意事项
-
用户级别的读写分离参数配置完成后,需要reload并重建session连接
-
从机读取优先级设置为0时,默认均读当前主库
-
从机读取优先级设置的值小于等于当前实际从库数量,读对应优先级的从库,对应优先级的从库不可用或复制延迟超出设置的值时,按异常处理策略选择项处理
-
从机读取优先级设置的值大于当前实际从库数量,按异常处理策略选择项处理
-
用户读写分离优先级高于全局的读写分离优先级。即用户开启读写分离的同时计算节点strategyForRWSplit参数也为开启状态,则以用户级的读写分离策略为准
-
多个从库优先级一致时,dsid最小的优先级最高
-
事务内写之前的读可正常分离,写之后的读全部发往主库
-
开启XA后的XA事务全部读主库,非XA事务可正常分离
-
单库开启用户级别的读写分离,按照从库全部不可用处理,即按异常处理策略选择项处理